目錄
前言:
一、進程與線程
二、線程初體驗
三、分頁式存儲管理初談
總結:
前言:
大家好啊,今天我們就要開始翻閱我們linux操作系統的另外一座大山:線程了。
對于線程,大體結構上我們是劃分為兩部分,一部分是線程的概念與控制,另外一部分是線程的同步與互斥的相關內容。
本篇文章我將會為大家介紹線程的一些基礎知識,加上對我們之前所學內容與線程之間的聯系。
一、進程與線程
我們之前學過進程。
當時我們說:進程是一個執行起來的程序,進程=內核數據結構+代碼與數據。
而什么是線程呢?
線程是一個執行流,執行粒度比進程更細,是進程內部的一個執行分支。
也就是說,一個進程可以包含多個線程,而這些線程共享進程的資源(如內存空間,我們后面會解釋),但各自擁有獨立的執行上下文(如棧、寄存器)
我們之前所說的進程,只有一個執行流,這種“單線程進程”其實是多線程模型的一種特例,如今更常見的是多線程程序,以提高并發性和資源利用率。
我們現在要更新一下對于線程進程的概念。
對于進程來說,進程是分配系統資源的基本實體。
對于線程來說,線程是OS調度的基本單位。
進程都需要被管理起來,那么比進程執行粒度更細的線程呢?
自然也要被管理起來,提到管理,就不得不說出那六個字:先描述,再組織!!
那我們就應該類似管理進程一樣,專門弄出一個類似于PCB的結構來管理線程?
那我們的操作系統未免也太復雜了吧。
所以,linux的設計者也考慮到了這一點,于是linux的設計者就決定,我們可不可以讓PCB(task_struct)近似的拿去管理線程呢?
所以線程,實際上也是通過PCB來進行管理的,沒錯,你沒有聽錯,線程,也是通過PCB來進行管理的。
一個程序是一個進程,但是這個進程不一定只有一個PCB,我們從來沒說過一個進程只能有一個PCB。所以有著多個PCB的進程,這多出來的,就是一個一個的執行流,就是一個一個的線程。線程也是task_struct描述起來的。
我們之前的模型,都是單線程進程,這唯一一個PCB,代表著這個進程的主執行流。
該進程唯一的?task_struct(PCB)即代表其主執行流,二者是等價的。此時?“進程”=“線程”,因為只有一個執行流,無需區分概念。
而我們之前講進程的PCB的時候說過,PCB中包含很多數據結構,包括頁表,mm_struct,vm_area_struct list。那現在的多線程進程中,我們有多個PCB,這里面的每一個PCB都有著這些結構嗎?
當然,要不然為什么他們都是由PCB管理起來的呢?
那他們的數據也是一樣的嗎?
是,也不是。
一個進程中可以含多個PCB,我們就以主執行流的PCB數據為準,其他執行流(線程)的PCB,里面的mm_struct,vm_area_struct list這些結構數據,其實是共享的,他們之間共享相同的地址空間和資源,但是他們的寄存器和用戶棧空間是每個線程各自獨立的:
struct task_struct {pid_t pid; // 線程ID(內核視角)pid_t tgid; // 線程組ID(用戶視角的進程ID)struct mm_struct *mm; // 指向共享的內存描述符// 每個線程有獨立的:struct thread_struct thread; // 寄存器狀態void *stack; // 內核棧
};
我們可以理解為每一個線程存儲的大部分數據都是一樣的,在執行代碼時,由于我們的執行上下文不同,各自維護獨立的執行狀態,所以我們可以并發的執行不同的代碼。
所以我們今天就有了更清楚的概念:一個PCB(task_struct)<= 進程
我們也不在區分執行流到底是線程還是進程,轉而把linux執行流統一稱為:輕量級進程(LWP)?
linux系統中沒有真正意義上的“線程”,只有?“共享資源的輕量級進程”。
值得提的是,Windows是真的有線程的專屬數據結構,所以它的內核代碼極其復雜。
二、線程初體驗
?我們接下來寫一下簡單的測試代碼,讓大家體驗一下線程的概念:
在linux中,我們一般用pthread_create函數來創建一個線程。

值得注意的是,這個函數并不是一個系統調用,而是我們glibc封裝的一個函數。
他有四個參數,第一個參數是一個指針,函數成功返回后,會將新線程的 ID 寫入該地址。所以我們在使用這個函數前,一般會創建一個pthread_t類型的id。
第二個參數指定線程的屬性(如棧大小、調度策略等),如果是NULL,則使用默認屬性。
第三個參數是一個函數指針,代表值這個線程將要執行的方法,而第四個參數表示傳遞給線程函數的參數。
#include <pthread.h>
#include <iostream>
#include <unistd.h>void* func(void *argv)
{while(true){std::cout<<"I am func pthread,my pid :"<<getpid()<<std::endl; sleep(1);}
}
int main()
{pthread_t tid;int i = 100;pthread_create(&tid, nullptr, func, (void *)i);while (true){std::cout << "I am main pthread,my pid :" << getpid() << std::endl;sleep(1);}return 0;
}在編譯這個代碼時應該注意,我們的編譯指令應該是?g++ test.cc -o test -lpthread?,因為我們需要需要鏈接?pthread 庫。
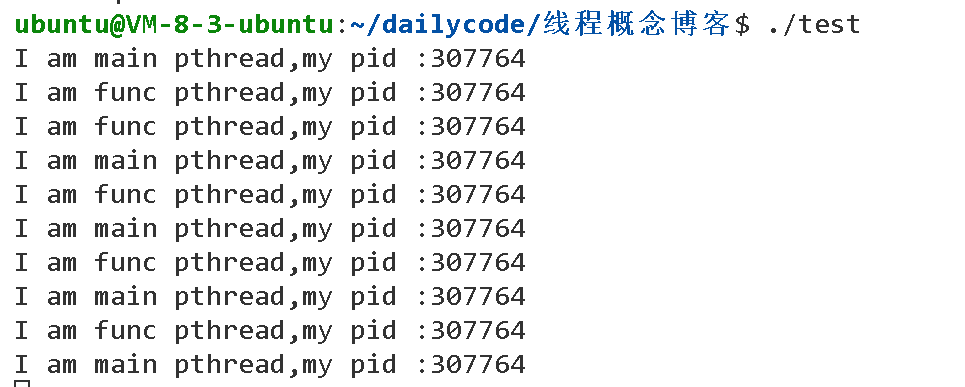
可以看見,如果只有一個執行流,是不能同時執行兩個while循環的。?
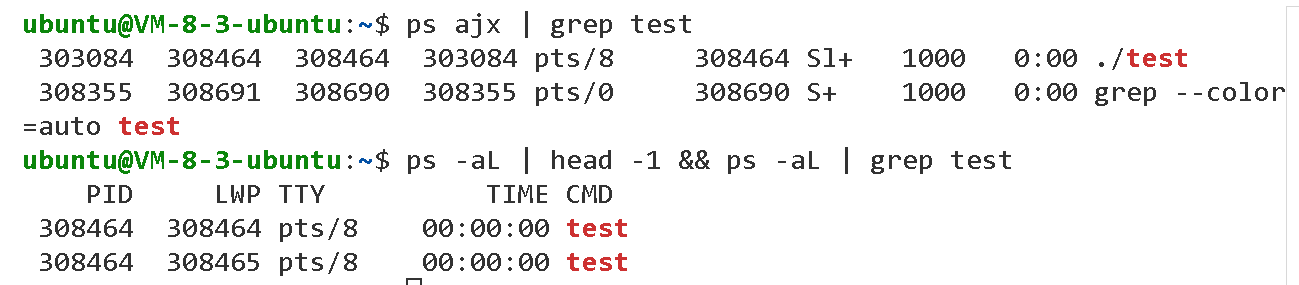 ?我們再次運行代碼,通過新的bash輸入以上兩個命令可以查看進程運行信息。
?我們再次運行代碼,通過新的bash輸入以上兩個命令可以查看進程運行信息。
可以看見,操作系統中叫做test的進程只有這一個,我們可以使用ps -aL來查看線程信息。
這里就多出來一個叫做LWP的東西。這個就是表示輕量級進程。
我們LWP與PID相同的,就是主執行流,如果光看PID的話,我們是區分不出來兩個執行流的。所以,我們可以通過LWP來區分執行流唯一性,我們的OS真實調度時,也是用的LWP而不是PID。
三、分頁式存儲管理初談
如果在沒有虛擬內存和分頁機制的情況下,每一個用戶程序在物理內存上所對應的空間必須是連續的,如下圖:
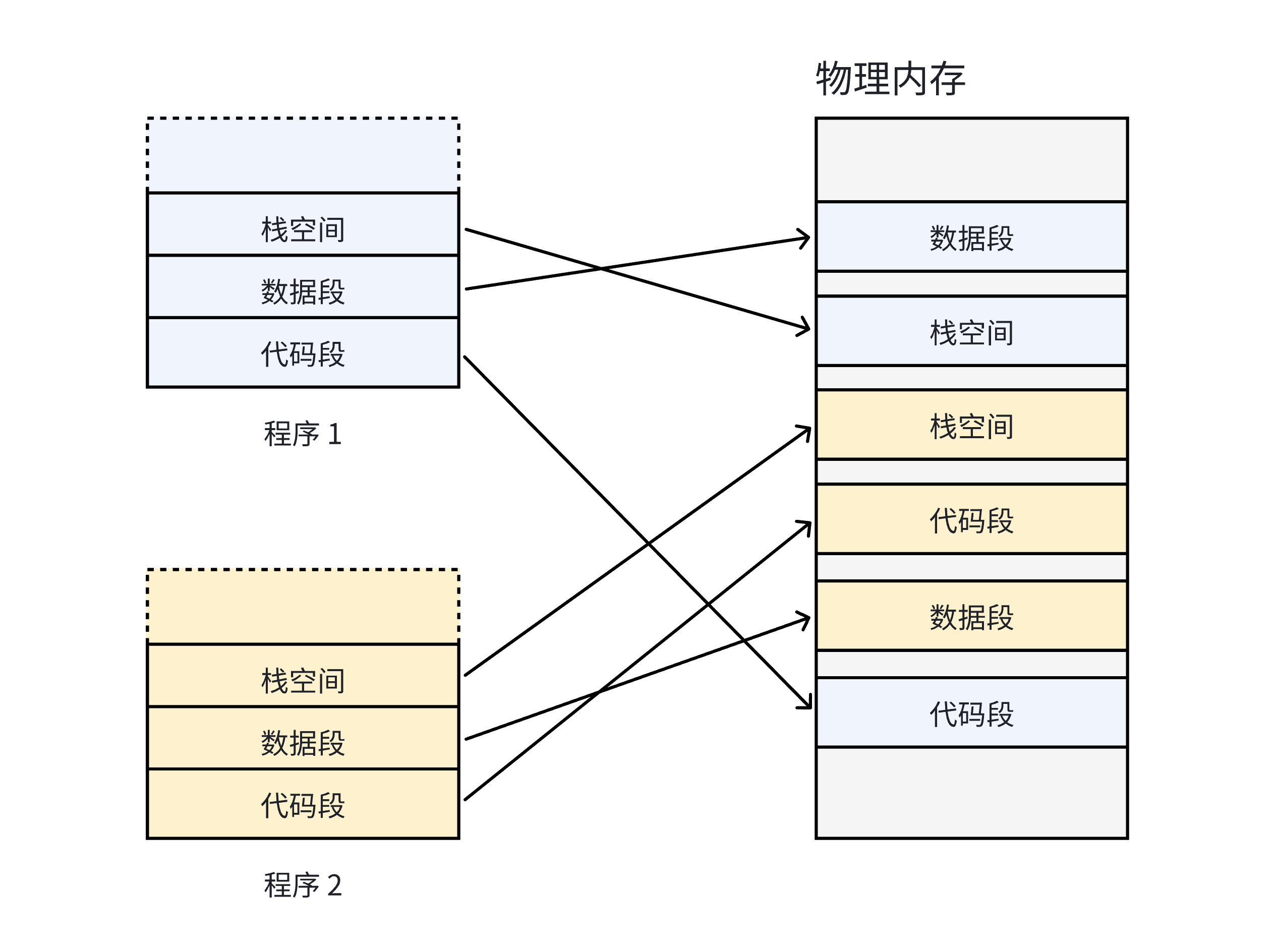
因為每一個程序的代碼、數據長度都是不一樣的,按照這樣的映射方式,物理內存將會被分割成各種離散的、大小不同的塊。結果一段時間運行后,有些程序會退出,那么他們占據的物理內存空間就會被回收,導致這些物理內存都是以很多碎片的形式存在的。
我們希望操作系統提供給用戶的空間必須是連續的,但是物理內存又不連續,該怎么辦呢?
所以此時虛擬內存與分頁就出現了。
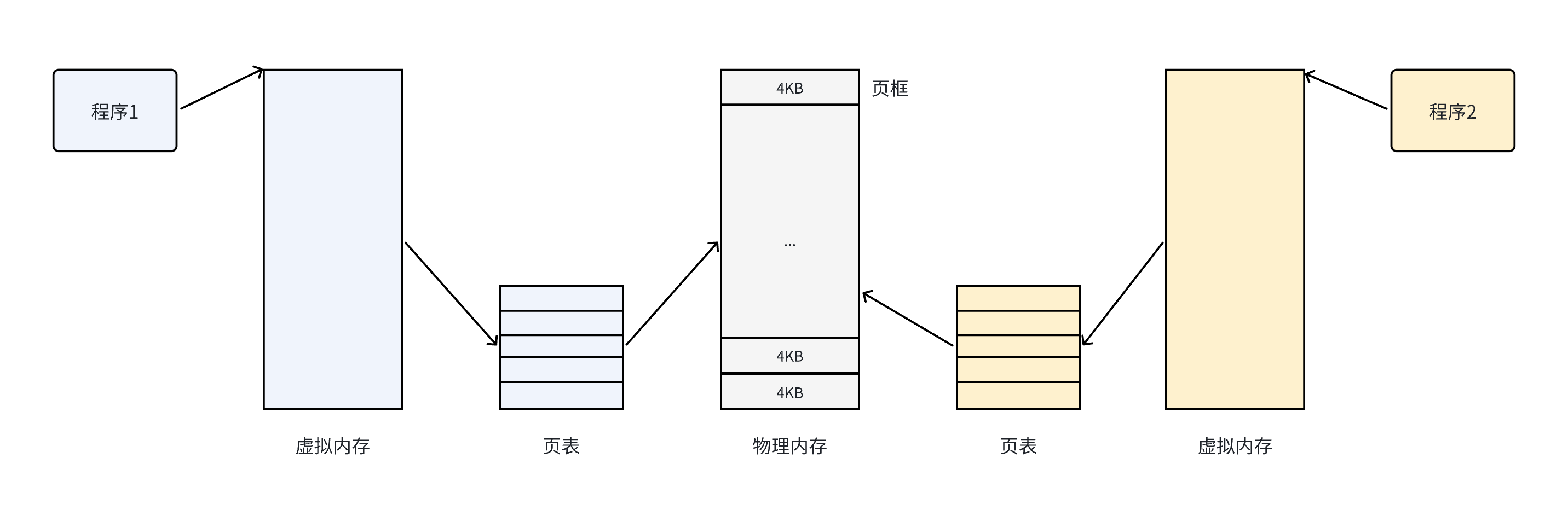
?我們這張圖中牽涉到了頁框的概念,那么什么是頁框呢?
同學們,還記得我們學過的物理內存管理嗎?
我們當時說過塊的概念,我們可以把一定數量的扇區,劃分為一個塊。一個塊的數據大小為4kb,也就是八個扇區。(ext2下)
我們說:塊是文件系統管理數據的最小單位,一個塊的大小是4kb。
這里的塊是文件系統讀寫磁盤的最小邏輯單位,類似的,我們的一個頁框的大小也是固定為4kb,他是操作系統管理物理內存的最小單位。
我們把物理內存按照一個固定的長度的頁框進行分割,有時候叫做物理頁。每一個頁框包含一個物理頁(page)。一個頁的大小等于頁框的大小,32位大多支持4kb,64為8kb。
我們需要區分頁與頁框:
頁是一個數據塊,可以存放在任何頁框或者磁盤中,而頁框是一個存儲區域!
有了這種機制,CPU便并非是直接訪問物理內存地址,而是通過虛擬地址空間來間接訪問物理內存地址。所謂的虛擬空間,是操作系統為每一個正在執行的進程分配的一個邏輯地址。操作系統將虛擬地址空間與物理內存地址之間建立映射關系,也就是頁表,這張表上記錄了每一頁和頁框的映射關系。
總結一下,其思想就是將虛擬內存下的邏輯地址空間分為若干頁,將物理內存空間劃分為若干頁框,通過頁表就能把連續的虛擬內存,映射到若干個不同的物理內存頁,就解決了碎片問題。
/* include/linux/mm_types.h */
struct page
{/* 原?標志,有些情況下會異步更新 */unsigned long flags;union{struct{/* 換出?列表,例如由zone->lru_lock保護的active_list */struct list_head lru;/* 如果最低為為0,則指向inode* address_space,或為NULL* 如果?映射為匿名內存,最低為置位* ?且該指針指向anon_vma對象*/struct address_space *mapping;/* 在映射內的偏移量 */pgoff_t index;/** 由映射私有,不透明數據* 如果設置了PagePrivate,通常?于buffer_heads* 如果設置了PageSwapCache,則?于swp_entry_t如果設置了PG_buddy,則?于表?伙伴系統中的階*/unsigned long private;};struct{ /* slab, slob and slub */union{struct list_head slab_list; /* uses lru */struct{ /* Partial pages */struct page *next;
#ifdef CONFIG_64BITint pages; /* Nr of pages left */int pobjects; /* Approximate count */
#elseshort int pages;short int pobjects;
#endif};};struct kmem_cache *slab_cache; /* not slob *//* Double-word boundary */void *freelist; /* first free object */union{void *s_mem; /* slab: first object */unsigned long counters; /* SLUB */struct{ /* SLUB */unsigned inuse : 16; /* ?于SLUB分配器:對象的數? */unsigned objects : 15;unsigned frozen : 1;};};};...};union{/* 內存管理?系統中映射的?表項計數,?于表??是否已經映射,還?于限制逆向映射搜索*/atomic_t _mapcount;unsigned int page_type;unsigned int active; /* SLAB */int units; /* SLOB */};...
#if defined(WANT_PAGE_VIRTUAL)/* 內核虛擬地址(如果沒有映射則為NULL,即?端內存) */void *virtual;
#endif /* WANT_PAGE_VIRTUAL */...
}系統啟動時,內核會根據檢測到的物理內存大小,為每個物理頁框(page frame)分配一個對應的 struct page 結構體。
在 Linux 內核中, struct page ?是用于管理物理內存頁(頁框)的核心數據結構,每個物理頁都對應一個這樣的結構體。該結構體包含幾個關鍵字段:
-
flags:這是一個多功能的標志位字段,用于記錄頁的各種狀態。每位代表一種獨立的狀態,可同時表示32種不同的狀態(定義在<linux/page-flags.h>中)。其中重要的標志位包括:
-
PG_locked:表示頁是否被鎖定在內存中
-
PG_uptodate:表示頁數據已從塊設備正確讀取
-
-
_mapcount:這個計數器記錄有多少個頁表項指向該物理頁,即頁的引用計數。當值為-1時,表示內核不再引用該頁,可以被重新分配使用。
-
virtual:存儲頁的虛擬地址。對于常規內存,這就是頁在虛擬地址空間中的映射地址;而對于高端內存(不永久映射到內核地址空間的部分),此字段為NULL,需要時再動態映射。
值得注意的是, struct page 描述的是物理頁而非虛擬頁。以典型的4KB頁大小和4GB物理內存為例,系統需要管理約1百萬個物理頁(4GB/4KB=1M)。假設每個 struct page 占用40字節,則總內存開銷約為40MB(1M*40B),僅占系統總內存的1%,這個管理開銷是相當合理的。
我們之所以扯到這里,主要是想幫助大家理解虛擬地址空間與線程之間的關系,同一進程的所有線程共享同一個 mm_struct(內存描述符),因此它們看到的是完全相同的虛擬地址空間.
我們可以把struct page當做數組來理解,Linux 內核通過一個名為?mem_map?的全局數組(元素類型為?struct page)管理所有物理頁。而當作數組,就有了下標,我們就可以快速轉化為物理地址,一個頁框是4kb,所以物理地址就等于=下標*4kb
總結:
由于時間原因,我們今天就講到這里。
但是我們的分頁式存儲管理還是沒有講完,我們還沒用深刻理解頁表的分級存儲。
所以明天我們將會講解頁表的分級存儲,之后會繼續講解線程的概念!





+Gitee實現自動化部署)







 來獲取調用棧?)


函數)


![[RAG system] 信息檢索器 | BM25 Vector | Pickle格式 | HybridRetriever重排序](http://pic.xiahunao.cn/[RAG system] 信息檢索器 | BM25 Vector | Pickle格式 | HybridRetriever重排序)