🚀 分布式ID生成器:Snowflake優化變種
一場訂單高峰,一次鏈路追蹤,一條消息投遞…你是否想過,它們背后都依賴著一個“低調卻關鍵”的存在——唯一ID。本文將帶你深入理解分布式ID生成器的核心原理與工程實踐,重點解構 Snowflake 及其優化變種,揭示高并發場景下的穩定“發號器”設計。
文章目錄
- 🚀 分布式ID生成器:Snowflake優化變種
- 1?? 為什么需要分布式ID?
- ? UUID 的問題
- ? 數據庫自增ID的局限
- ? 傳統方案對比
- 2?? Snowflake 原理詳解
- 🧱 Snowflake 結構(64位拆解)
- 💻 Java 實現(簡化版)
- 🎯 業務使用建議
- 🎯 特性總結
- 3?? 時鐘回撥問題與應對
- 🧩 常見解決策略:
- 1.拒絕服務法(默認做法):
- 2.時間等待法:
- 3.標記法 + 修正位:
- 4.雙保險機制:
- 5.解決方案對比
- 🧠 總結建議
- 4?? 美團 Leaf:號段模式 ID
- 🧱Segment 模式:
- 關鍵組件說明??:
- 🧱Snowflake 模式:
- 關鍵組件說明??:
- ?架構對比圖示
- 📌 對比總結
- 🧠 推薦選型建議
- 5?? 基于 Redis 的 ID 生成
- 通過 INCR 命令實現:
- ?優點
- ? 注意事項
- 6?? UUID 與數據庫自增ID對比
- 推薦做法:
- 7?? 跨機房部署策略
- 🧠 推薦策略:
- 8?? 實戰落地建議
- ? 部署建議:
- 🧩 總結與互動
1?? 為什么需要分布式ID?
在微服務系統中,訂單號、日志追蹤ID、消息投遞ID,都必須具備以下特性:
全局唯一(避免沖突)
趨勢遞增(數據庫分頁友好)
高性能生成(高并發不掉鏈子)
? UUID 的問題
UUID.randomUUID().toString();
// 輸出:550e8400-e29b-41d4-a716-446655440000- 無序,不適合做數據庫主鍵;
- 太長(36位字符),不利于存儲和傳輸;
- 不可讀,不利于排查和追蹤。
? 數據庫自增ID的局限
- 依賴單點,存在性能瓶頸與擴展困難;
- 分庫分表難協調;
- 難以保障全局唯一。
? 傳統方案對比
| 方案 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| UUID | 簡單,無中心化 | 無序,索引效率低 | 小規模系統 |
| 數據庫自增 | 簡單,有序 | 擴展性差,有單點風險 | 單機系統 |
| Redis自增 | 性能好 | 持久化風險,成本高 | 緩存層ID補充 |
性能對比??(單機每秒生成ID數):
數據庫自增:約5,000
UUID:約100,000
Snowflake:約1,000,000+
? 引出主角:Snowflake 算法!
2?? Snowflake 原理詳解
Snowflake 是 Twitter 開源的分布式高性能ID生成器,生成的是 64位長整型 ID,支持高并發下毫秒級唯一ID生成。
🧱 Snowflake 結構(64位拆解)
| 位數 | 含義 | 位寬 | 描述 |
|---|---|---|---|
| 1 | 符號位 | 1 | 固定為 0 |
| 2 | 時間戳 | 41 | 與自定義 epoch 相差的毫秒數 |
| 3 | 數據中心 ID | 5 | 可部署 32 個數據中心 |
| 4 | 機器 ID | 5 | 每個數據中心支持 32 臺機器 |
| 5 | 序列號 | 12 | 每毫秒可生成 4096 個 ID |
0 | 41 bits timestamp | 5 bits dataCenterId | 5 bits machineId | 12 bits sequence💻 Java 實現(簡化版)
public class SnowflakeIdGenerator {private final long epoch = 1609459200000L; // 自定義起始時間戳private final long dataCenterIdBits = 5L;private final long workerIdBits = 5L;private final long sequenceBits = 12L;private final long dataCenterIdShift = sequenceBits + workerIdBits;private final long timestampShift = sequenceBits + workerIdBits + dataCenterIdBits;private final long maxSequence = -1L ^ (-1L << sequenceBits);private long dataCenterId;private long workerId;private long lastTimestamp = -1L;private long sequence = 0L;public synchronized long nextId() {long current = System.currentTimeMillis();if (current == lastTimestamp) {sequence = (sequence + 1) & maxSequence;if (sequence == 0) {// 等待下一毫秒while (current <= lastTimestamp) {current = System.currentTimeMillis();}}} else {sequence = 0;}lastTimestamp = current;return ((current - epoch) << timestampShift)| (dataCenterId << dataCenterIdShift)| (workerId << sequenceBits)| sequence;}
}🎯 業務使用建議
- 趨勢遞增??:ID在業務中按時間排序,利于分頁
- 索引友好??:64位整數比UUID更節省空間
- ??雪崩風險??:避免在整點時刻集中觸發ID生成
- 業務編碼??:可在ID中嵌入業務類型前綴
🎯 特性總結
- 高性能:單機每毫秒可生成 4096 個 ID;
- 趨勢遞增:可用于索引、分表;
- 分布式無中心化。
3?? 時鐘回撥問題與應對
什么是時鐘回撥?
假設當前時間是 13:00,系統突然因為 NTP 同步變成 12:59,如果 Snowflake 用的是系統時間,那么后續生成的 ID 可能重復或異常遞減。
🧩 常見解決策略:
1.拒絕服務法(默認做法):
if (current < lastTimestamp) throw new RuntimeException("Clock moved backwards");2.時間等待法:
while (current < lastTimestamp) {current = System.currentTimeMillis();
}3.標記法 + 修正位:
增加標記字段表示回撥狀態,優先寫入緩存防止使用。
4.雙保險機制:
- 使用本地時鐘偏移記錄;
- 配合外部 NTP 校時同步;
- 多 ID 實現(Snowflake + Redis 組合備用)。
5.解決方案對比
| 方案 | 原理概述 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|---|
| ? 拒絕服務法 | 一旦發現當前時間小于上一次生成 ID 的時間,則直接拋異常 | 簡單暴力,避免產生錯誤 ID | 影響服務可用性,強依賴時間準確性 | 非核心服務、穩定時間環境 |
| ? 時間等待法 | 檢測到回撥則 sleep() 等待系統時間恢復 | 保證 ID 單調遞增,不拋錯 | 線程阻塞、吞吐下降;等待時間難以控制 | 容忍輕微等待場景,如異步寫單、批處理 |
| ? 標記法 + 修正位 | 檢測回撥后增加特殊標識位或偏移位標記異常時間段 | 保留生成能力,且可追蹤異常 ID | ID 結構更復雜,客戶端需識別異常時間段 | 高并發高可用服務,需自行處理異常標記 |
| ? 雙保險機制 | 除本地時間外,結合外部 NTP 同步/Redis記錄最大時間戳等機制 | 精度高、靈活、安全性強 | 系統復雜度增加,外部依賴(如 ZooKeeper/NTP) | 核心 ID 服務、訂單中心、支付系統 |
🧠 總結建議
| 項目類型 | 推薦方案 |
|---|---|
| 核心金融/支付系統 | 雙保險 + 標記機制 |
| 秒殺、日志等強一致 | 時間等待法 + 限流 |
| 弱一致服務 | 標記位/拒絕服務法 |
| 內部服務、低并發 | 拒絕服務法或 Redis校時 |
? 類比比喻:時鐘回撥就像員工誤調鬧鐘提前上班,記錄的工時會亂套。
4?? 美團 Leaf:號段模式 ID
Leaf 提供兩種模式:Segment 模式(數據庫號段) 和 Snowflake 模式。
🧱Segment 模式:
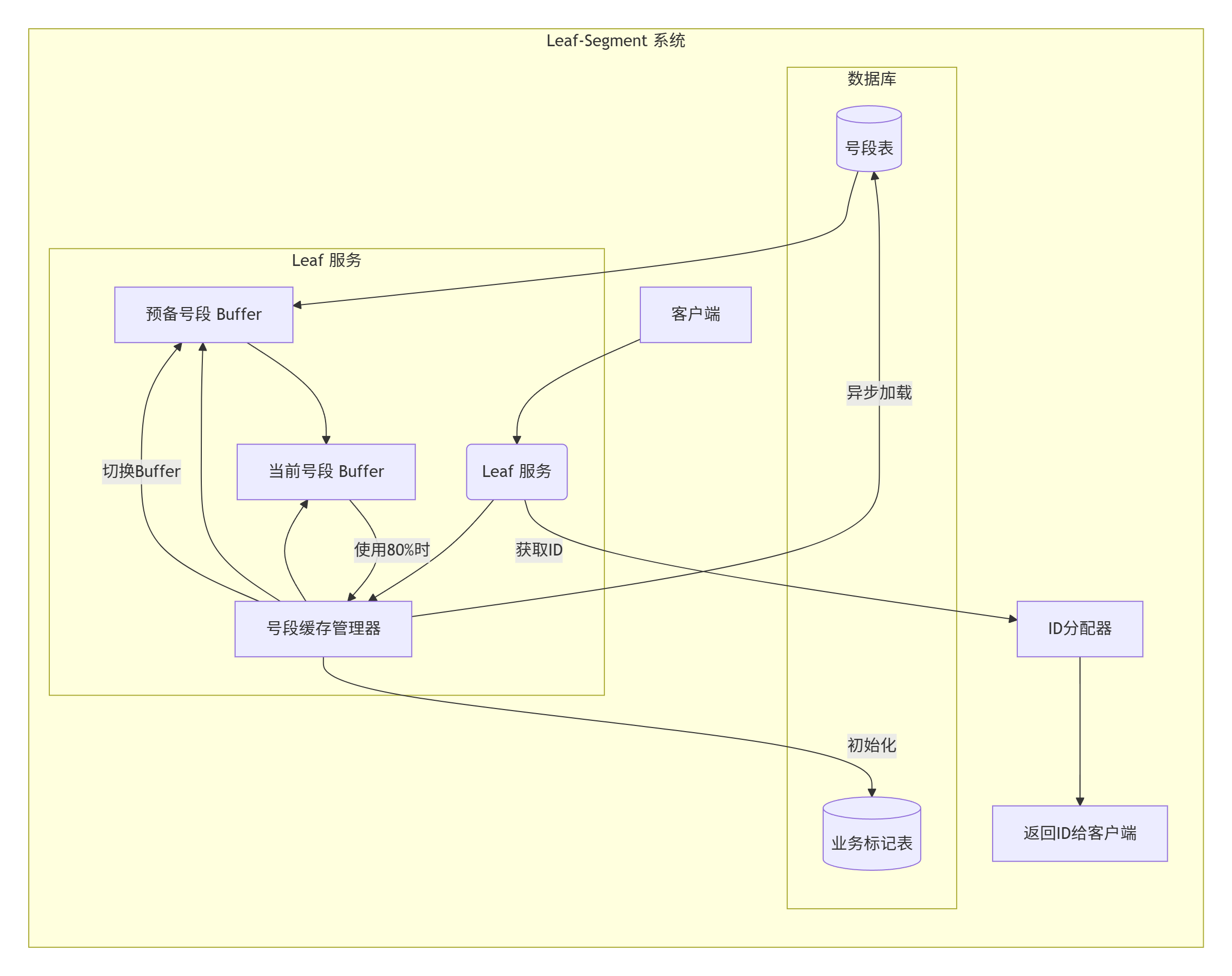
關鍵組件說明??:
- 號段緩存管理器??:管理兩個Buffer的切換
- ??當前號段Buffer??:正在使用的ID段
- ??預備號段Buffer??:預加載的備用ID段
- ??號段表??:存儲各業務的最大ID值
- ??業務標記表??:記錄各業務的號段配置
- ??ID分配器??:從當前Buffer分配ID
🧱Snowflake 模式:
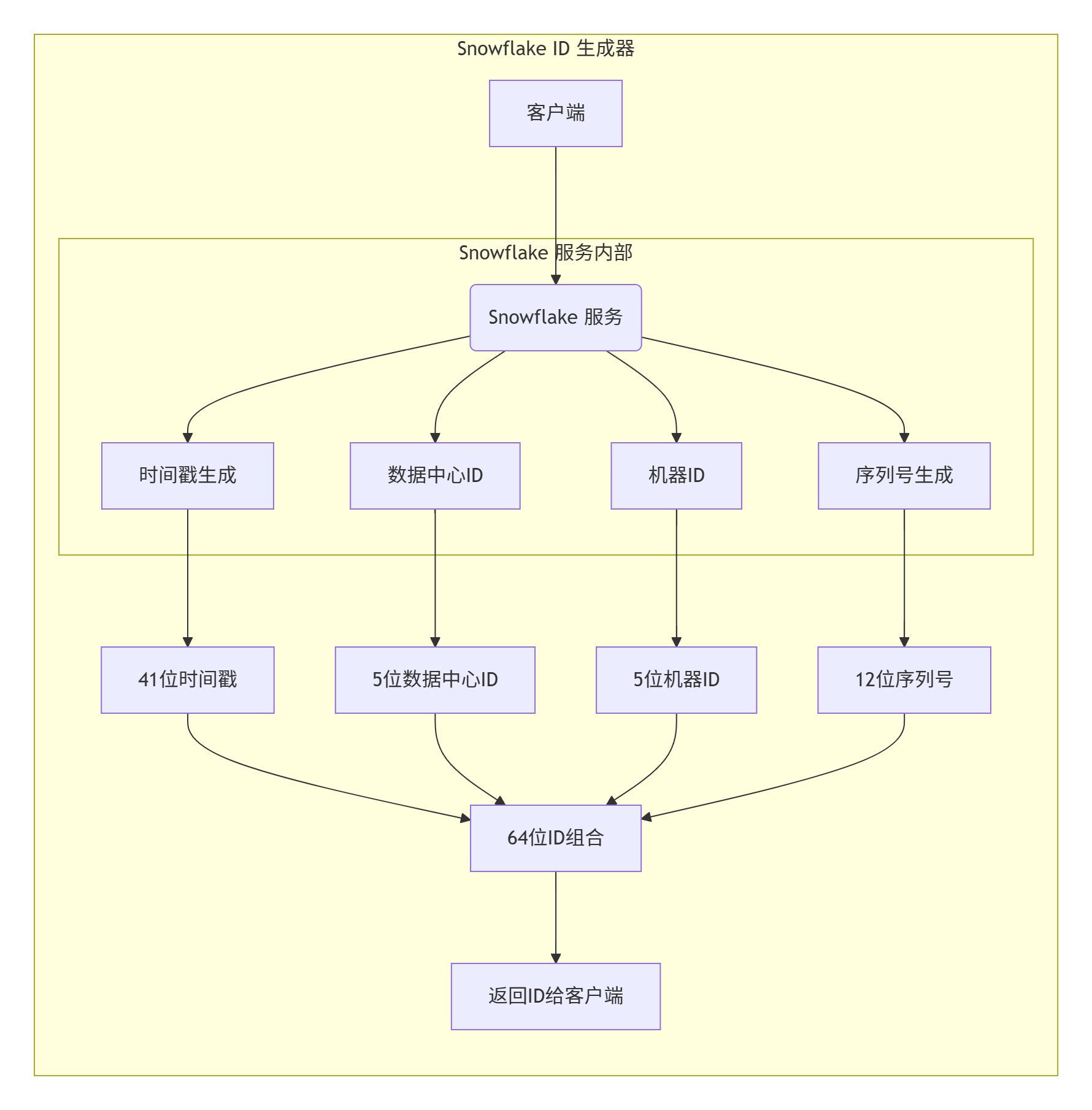
關鍵組件說明??:
- ??時間戳生成??:精確到毫秒的當前時間
- ????數據中心ID??:區分不同機房/區域
- ??機器ID??:區分同一機房的不同機器
- ??序列號??:解決同一毫秒內的并發沖突
- ????ID組合??:將四部分組合成64位整數
?架構對比圖示
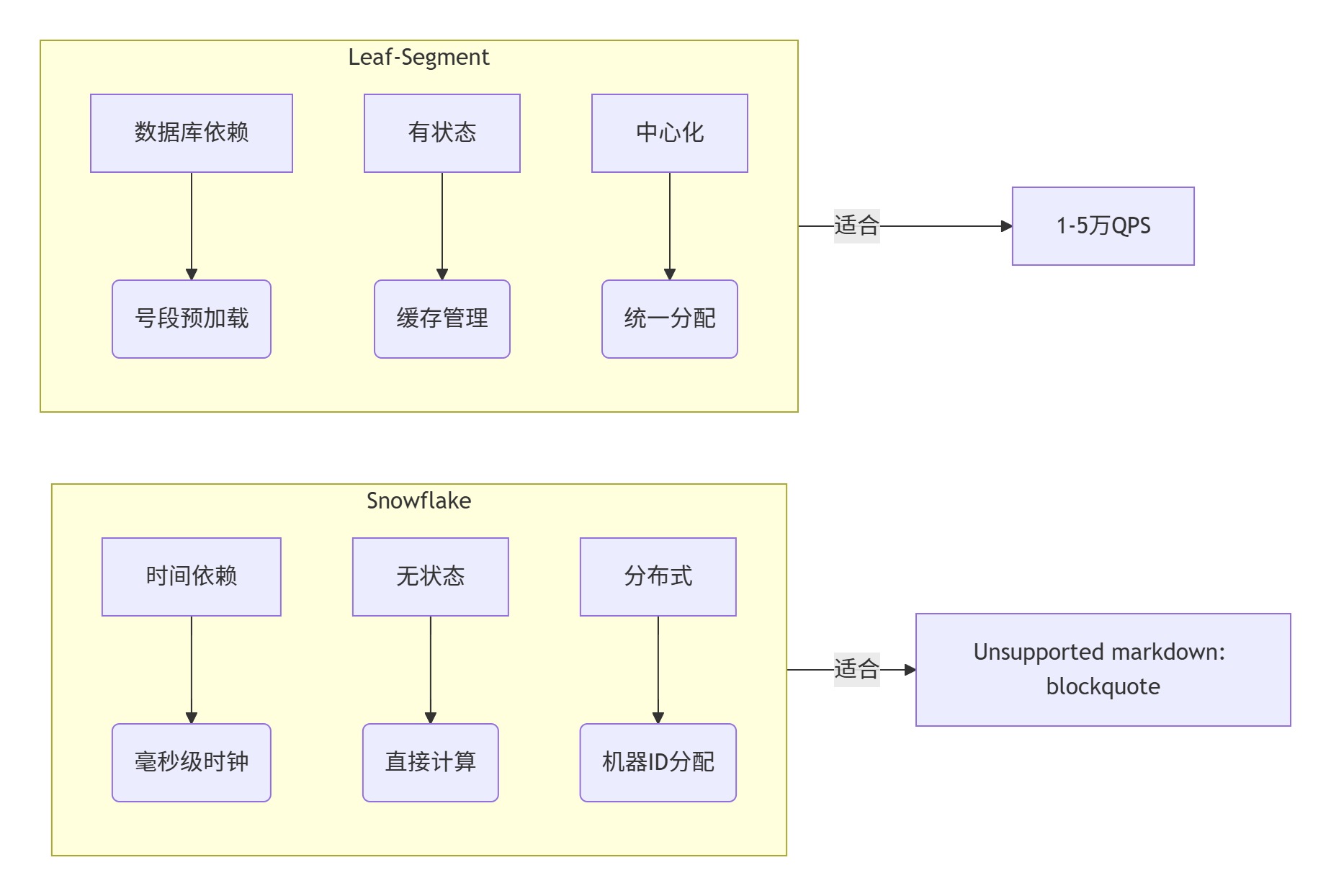
📌 對比總結
| 維度 | Segment 模式 | Snowflake 模式 |
|---|---|---|
| 中心化依賴 | ? 依賴 DB / Leaf Server | ? 去中心化,節點自生成 |
| 可用性(宕機影響) | ? Leaf Server 掛掉無法分配號段 | ? 節點獨立運行 |
| 時鐘安全性 | ? 不依賴系統時間 | ? 時鐘回撥將導致重復 ID |
| ID 有序性 | ? 單調遞增 | ? 趨勢遞增,但可能存在跳躍 |
| 實現難度 | ? 簡單,易擴展 | ? 需要位運算、時鐘安全等細節處理 |
| 跨語言支持 | ? Leaf 提供 HTTP 接口 | ? 需每種語言自行實現或提供 SDK |
| 最佳使用場景 | 單據號、訂單號、分頁要求有序的數據 | 日志鏈路、消息唯一標識、非強排序業務 |
🧠 推薦選型建議
| 業務場景 | 推薦方案 |
|---|---|
| 支付訂單、發票號等需單調遞增 | ? Segment 模式 |
| 日志追蹤ID、MQ消息ID等 | ? Snowflake 模式 |
| 全局 ID 服務、集群穩定性高 | ? Snowflake 模式 |
| 分布式系統中異地雙中心部署 | ? Segment + Redis |
5?? 基于 Redis 的 ID 生成
通過 INCR 命令實現:
String key = "order:20230715";
Long id = redisTemplate.opsForValue().increment(key);
String fullId = "ORD" + LocalDate.now().format(DateTimeFormatter.BASIC_ISO_DATE) + id;?優點
- 實現簡單;
- 自帶原子性;
- 支持 Redis 集群高可用。
? 注意事項
- Redis 持久化(AOF + RDB)開啟;
- 主從同步時 ID 不一致可能造成問題;
- 可以搭配 UUID/時間戳前綴降低沖突概率。
6?? UUID 與數據庫自增ID對比
| 特性 | UUID | 自增ID |
|---|---|---|
| 唯一性 | 高 | 本地唯一 |
| 可讀性 | 差(無語義) | 好 |
| 排序性 | 無序 | 有序 |
| 分布式支持 | 天生支持 | 不支持 |
| 索引性能 | 差(隨機分布) | 好(遞增) |
| 應用場景 | 分布式服務標識、業務追蹤 | 小型單體服務主鍵 |
推薦做法:
- 主鍵用分布式 Snowflake ID;
- 業務追蹤用 UUID;
- 索引字段避免用 UUID!
7?? 跨機房部署策略
在多 IDC、多區域部署時,應考慮 ID 生成器的:
- 數據中心ID 配置是否沖突;
- 時間戳是否同步;
- 網絡分區是否影響寫入。
🧠 推薦策略:
- 手動劃分 dataCenterId 區段;
- 使用 ZooKeeper 分配 workerId;
- Leaf 主數據中心提供服務,其他副本可降級使用 Redis 方案;
- ID 服務盡量內嵌 SDK 本地生成,減少跨機房通信。
8?? 實戰落地建議
| 場景 | 推薦方案 |
|---|---|
| 訂單、支付、日志鏈路 | Snowflake |
| 業務唯一編碼(人可讀) | Leaf + 前綴規則 |
| 用戶ID/設備ID | Redis + ID段緩存 |
| 高一致性服務下 ID | 數據庫號段/Leaf |
? 部署建議:
- 單獨部署 ID 生成服務(Leaf/ID Center);
- 對外以 RPC 接口形式暴露;
- 接入方 SDK 本地緩存 ID;
- 加入監控 + 限流機制防雪崩。
🧩 總結與互動
一個優秀的分布式 ID 方案,應滿足:
? 高可用,穩定生成;
? 趨勢遞增,適配數據庫;
? 跨服務、跨機房、跨時區都不重;
? 不受時鐘回撥影響;
💬 你在項目中用的是什么分布式 ID 方案?踩過哪些坑?歡迎評論區留言討論交流!


+Gitee實現自動化部署)







 來獲取調用棧?)


函數)


![[RAG system] 信息檢索器 | BM25 Vector | Pickle格式 | HybridRetriever重排序](http://pic.xiahunao.cn/[RAG system] 信息檢索器 | BM25 Vector | Pickle格式 | HybridRetriever重排序)


