文章目錄
- 引言
- 一、 Java 性能優化的核心思路
- 二、為什么要度量?
- 三、常用性能衡量指標詳解
- 3.1 吞吐量與響應速度
- 3.2 響應時間的具體度量:平均響應時間與百分位數
- 3.3 并發量
- 3.4 秒開率(頁面秒開)
- 3.5 正確性(功能可用性)
- 四、核心理論方法
- 4.1 木桶理論:找短板
- 4.2 基準測試與預熱:消除“假象”
- 五、性能測試與優化中的注意點
- 5.1 依據數據而非直覺
- 5.2 單次樣本數據不足信
- 5.3 不要過早優化、也不要過度優化
- 5.4 保持良好編碼習慣
- 六、小結

引言
隨著業務規模與用戶量的不斷增長,任何性能瓶頸都可能放大為損失。很多團隊在遇到性能問題時,往往依賴經驗盲猜和臨時補救,表面上解決了痛點,卻無法建立體系化方法論;缺乏工具與思路支撐的調優之路容易陷入重復救火的循環。
然而,日常開發偏重 CRUD 操作,對高并發場景缺乏真實體驗。面對高可用、高性能系統設計的高級任務,不少工程師無從下手。
一、 Java 性能優化的核心思路
- 系統性視角:性能優化不是孤立的代碼調整,而是編程語言、JVM、操作系統與中間件的協同優化。
- 工具驅動:基于指標(QPS、延遲、GC 停頓等)進行度量,借助 JMH、jconsole、jvisualvm 等多維度排查問題。
- 瓶頸定位:從大到小,先抓住短板資源(CPU、內存、I/O、鎖競爭),再做微觀級別的算法與結構優化。
- 平衡權衡:關注整體效果與可維護性,避免
switch vs if級別的偽優化帶來可讀性與擴展性損失。 - 場景適配:串行耗時場景與并行高吞吐場景對應不同優化策略,靈活選型是關鍵。
二、為什么要度量?
“性能”到底是什么?最簡定義是:用有限的資源,在有限的時間內完成工作。既然“時間”是核心,那么“度量”就是優化前后對比的重要依據。
- 避免盲目優化:如果只憑感覺去改代碼,往往會陷入修改一處、出問題一處的循環,最后連“有沒有真正提升”都沒弄清楚。
- 發現系統瓶頸:單憑主觀猜測,往往抓不準最關鍵的環節;而一旦度量指標清晰,就能找到“最短板”的部分優先優化。
- 為業務決策提供依據:運營團隊希望知道“我的頁面打開慢,是哪些環節拖累?數據庫慢?網絡慢?還是后端處理慢?”,只有量化數據才能給出準確建議。
三、常用性能衡量指標詳解
在高并發場景里,通常會圍繞“吞吐量”和“響應速度”展開討論,但其實性能指標并不止于此,還包括并發能力、用戶體驗層面的秒開率,以及最重要的“正確性”保障。
3.1 吞吐量與響應速度
-
概念對比
- 響應速度(Response Time):一次請求從發起到收到完整響應所花費的時間(時延)。
- 吞吐量(Throughput):單位時間內系統成功處理的請求數量,比如
QPS(Queries Per Second)、TPS(Transactions Per Second)、HPS(HTTP Requests Per Second)等。
-
交通十字路口類比
在繁忙的十字路口,紅綠燈放行時的單車通行時間,就是“響應時間”;而單位時間內通過的車輛數,就是“吞吐量”。如果頻繁切換紅綠燈,會讓單車通行時間降低(響應變快),但紅綠燈切換太多會導致每次綠燈放行的等待時間增多,單位時間通過的車輛反而減少(吞吐量降低)。- 優化響應速度:相當于減少每輛車等待+通行的時間,多從“串行”角度下手,例如減少信號燈切換時的固定等待。
- 優化吞吐量:相當于提升路口并行處理能力,比如增設額外車道、采用智能信號燈,使綠燈時間區間更合理。
-
何時關注哪個指標?
- 如果業務強調“單次響應必須在某個閾值內”,那么響應速度至關重要。
- 如果業務是“大批量異步操作”(比如批量導入、日志批量寫入),吞吐量更具參考價值。
- 對于大多數高并發應用,我們既要保證快速響應,也要盡可能高的吞吐,因此需要平衡二者:在保證99%請求響應在可接受范圍之內(TP90/95/99)時,再追求吞吐量最大化。
3.2 響應時間的具體度量:平均響應時間與百分位數
-
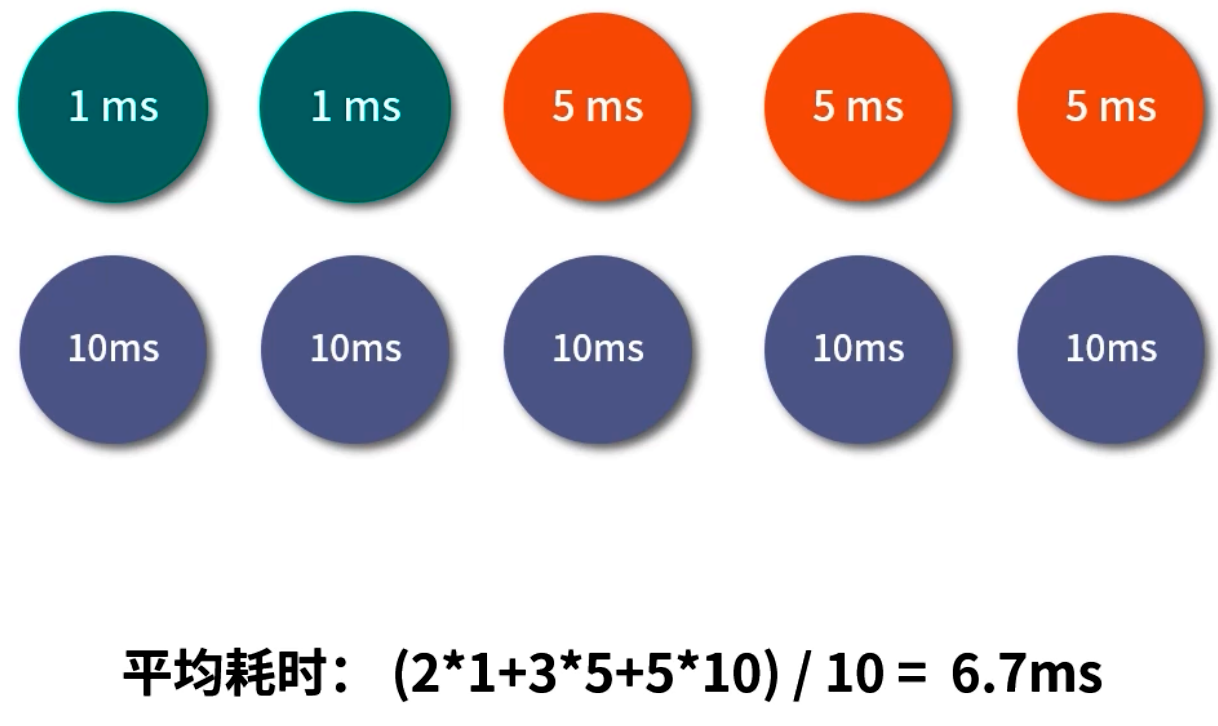
平均響應時間 (AVG Response Time)
計算方式:將周期內所有請求耗時相加,除以請求總數。例如:有 10 個請求,2 個耗時 1ms、3 個耗時 5ms、5 個耗時 10ms,則平均響應時間 = (2×1 + 3×5 + 5×10) / 10 = 6.7ms。- 優點:易于計算,能反映整體處理能力。
- 缺點:對長尾請求敏感度不足。少數非常慢的請求,很快被大量普通請求“稀釋”,導致平均值變化不明顯。
-
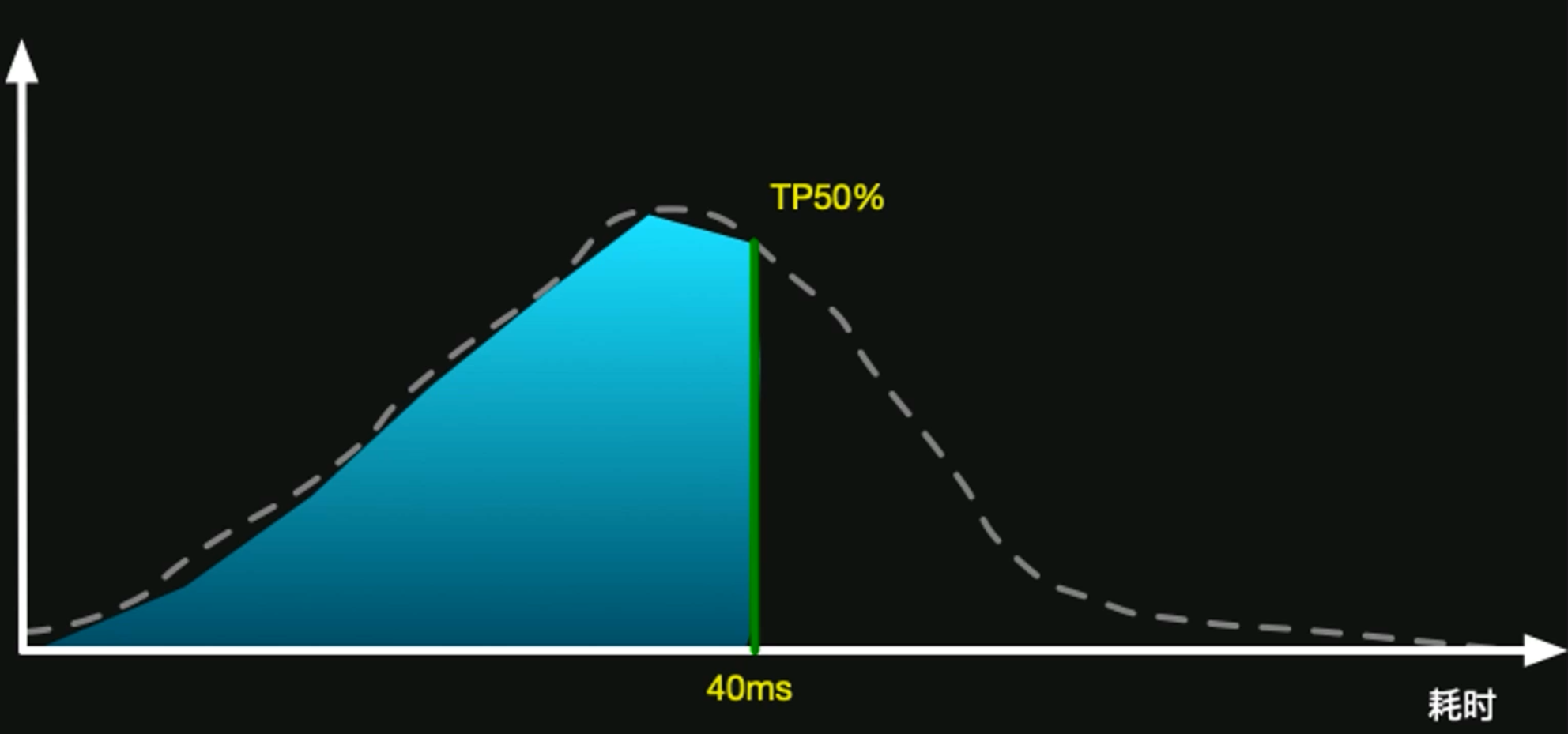
百分位數 (Percentile Response Time, 或稱 TP 值)
將每次請求的耗時排序之后,取排序后第 N% 位置的值作為 TP(N)。例如:TP90 = 50ms 意味著有 90% 的請求在 50ms 以內完成。- TP50:中位數,大約 50% 的請求都在這個耗時之內。
- TP90/TP95/TP99/TP99.9:常見關注維度,用于衡量長尾效應。如果某段時間發生一次長時間 GC,TP99 以上的值會突然升高,提示有極少數請求出現異常延遲。
- 應用場景:電商、金融、社交應用中,99% 的請求必須在可接受范圍內完成,否則會引發用戶體驗崩塌或交易失敗。
這個指標也是非常重要的,它能夠反映出應用接口的整體響應情況
我們一般分為 TP50、TP90、TP95、TP99、TP99.9 等多個段,對高百分位的值要求越高,對系統響應能力的穩定性要求越高。
在這些高穩定性系統中,目標就是要干掉嚴重影響系統的長尾請求。這部分接口性能數據的收集,我們會采用更加詳細的日志記錄方式,而不僅僅靠指標。比如,我們將某個接口,耗時超過 1s 的入參及執行步驟,詳細地輸出在日志系統中。
為什么要關注高百分位?
高并發場景下,絕大多數請求正常,但一旦出現長尾請求(如 GC 暫停、數據庫慢查詢),那就會影響一部分用戶體驗。TP90/95/99 可以幫助我們捕捉到“極端情況”的延遲,便于專項優化。
3.3 并發量
- 定義:系統在某一時刻能夠并發處理的請求數。
- 意義:
- 單純看吞吐量,只代表單位時間總處理量;但并發量更多體現系統在同一瞬間需要承受多少連接或請求。
- 在高并發場景下,如果并發數超過系統承載能力,就會出現線程爭用、線程池耗盡、連接池耗盡等問題,導致大量請求被拒絕或超時。
- 設計參考:
- 雖然“秒殺”系統的峰值并發可能上萬,但經過限流、降級、過濾等機制后,落到某個微服務節點的并發通常只有幾十到幾百。
- 只要你保證“響應時間”持續縮短,系統自然能夠支撐更多并發,因此我們通常將優化重心放在“響應時間優化”上,再關注“并發量瓶頸”。
3.4 秒開率(頁面秒開)
- 定義:對移動應用或 Web 頁面而言,若頁面能在 1 秒內加載完成,即可認為“秒開”。秒開率 = 在規定時間(如 1s)內完成加載的請求數 / 總請求數。
- 意義:在移動端與小程序場景下,用戶對首頁/關鍵頁面的“秒開”體驗非常敏感。例如,淘寶首頁需要在用戶點擊后1秒內完成首屏展示,否則就會大幅影響轉化率與用戶粘性。某些優秀團隊(如手淘)能夠保證超過80%以上頁面在1秒內打開。
- 度量方式:通常結合前端埋點,將“頁面白屏時間”、“首包響應時間”等指標發送到監控系統,再統計 1s 以內的比例。
3.5 正確性(功能可用性)
- 定義:除了“快”,我們更要“準”。如果接口返回的只是錯誤數據或固定降級內容,那么再快的響應也毫無意義。
- 案例警示:在壓測階段發現并發 20 時接口依然“很快”,便忽略了返回結果的正確性驗證;上線后才發現所有接口返回數據都是偽造或空數據,屬于典型“熔斷后只看吞吐忽視正確性”導致的事故。
- 度量方法:
- 在壓力測試或落地監測時,同時采集“錯誤率(Error Rate)”或“業務返回碼情況”。
- 當壓力增大觸發熔斷/限流/降級時,應判斷接口是否依然返回業務可用數據。
四、核心理論方法

4.1 木桶理論:找短板
-
原理:一只木桶能裝多少水取決于最短那塊木板,而非最長那塊。應用到系統性能,則取決于整體中最慢的那個組件(短板)。
-
舉例:
- 在典型的數據庫讀寫場景中,如果硬盤 I/O 讀寫耗時很大,那么即便 CPU 還有很大富余、內存也足夠,系統整體的 RPS(Requests Per Second)依舊被磁盤寫入速度拉垮。
- 在微服務架構下,如果某個下游接口延遲高達 200ms,又回過頭去優化上游只花 5ms 的代碼,收效甚微。
-
優化思路:先度量各環節消耗(網絡、CPU、GC、數據庫、緩存等),排查出“最慢一塊木板”,集中資源補齊它,再逐步向“第二短板”優化,形成閉環。
4.2 基準測試與預熱:消除“假象”
-
基準測試 (Benchmark):并不是簡單地跑壓力測試,而是測試某段代碼/某個組件在理想(或接近真實)環境下能夠達到的“最佳性能上限”。
-
預熱 (Warm-up):
- Java 應用在剛啟動或代碼第一次被執行時,會觸發 JIT(即時編譯)編譯過程,導致第一次請求變慢。
- 如果不進行預熱,測試時會拿到不準確的延遲數據。我們需要借助 JMH(Java Microbenchmark Harness)或自行編寫預熱邏輯,讓核心代碼在測量前先運行若干輪,觸發 JIT 編譯完成后再正式采集統計數據。
-
優勢:
- 消除 JVM “初期解釋執行”“編譯優化延遲”帶來的噪聲,讓測試指標更穩定。
- 在做算法、數據結構或小模塊優化時,能更精確地對比改動前后的差異。
五、性能測試與優化中的注意點

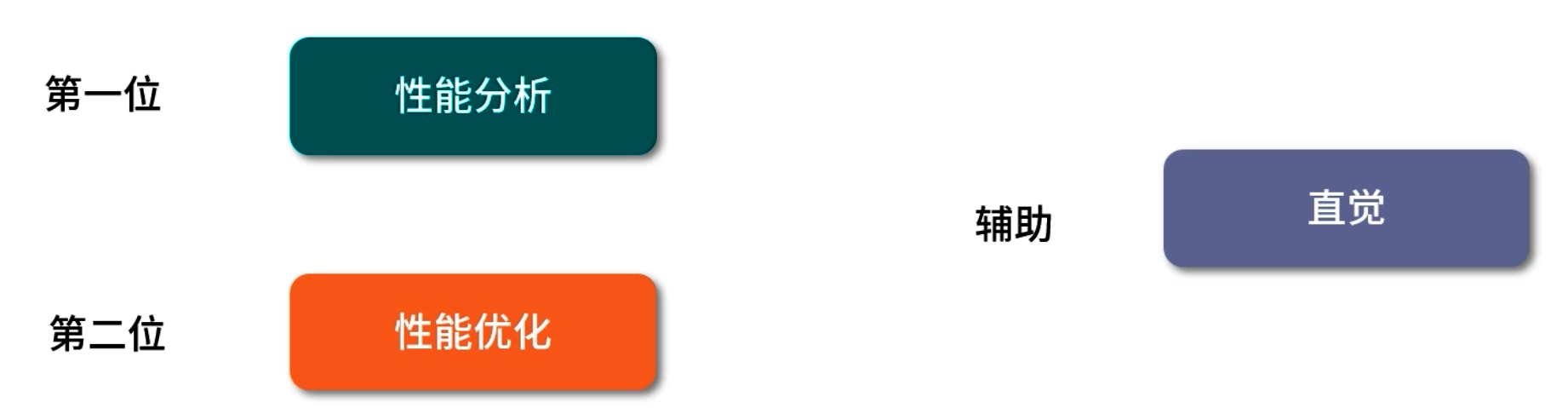
5.1 依據數據而非直覺
- 常見誤區:開發者往往對自己熟悉的業務場景“有感覺”,能猜到某個環節可能慢,但復雜系統往往影響因素多,一味聽“直覺”會丟失其他關鍵瓶頸。
- 正確做法:先做“性能分析”(Profiling / Monitoring),生成火焰圖、線程快照、GC 日志等,用數據確定短板,再進行代碼或架構層面的改造。
5.2 單次樣本數據不足信
-
誤區示例:只拿一個網絡請求的耗時來看“慢”或“不慢”,容易被網絡波動、客戶端環境等隨機因素干擾。
-
實踐建議:
- 收集大量請求數據,利用平均值、標準差、百分位數、直方圖等統計方式進行綜合分析。
- 將性能數據與業務維度(如請求入口、請求參數規模)結合起來看,才能判斷“慢”的真實原因。
5.3 不要過早優化、也不要過度優化
-
“過早優化”
- Donald Knuth 說過:“過早的優化是萬惡之源。”如果功能邏輯還未穩定,提前陷入各種微觀優化(比如手寫位運算、鉆研 switch vs. if 在微秒級的差別),往往會導致代碼難以維護。
- 正確時機:當整個應用架構、功能模塊基本穩定、核心業務流路徑已經明確后,再進行性能測量與優化。
-
“過度優化”
- 如果某段代碼的運行已經滿足業務需求,即使可以把延遲再縮 5ms,也要衡量成本與收益:更復雜晦澀的寫法,可能給后續維護帶來隱患。
- 舉例:某系統瓶頸在數據庫查詢,舍近求遠去優化計算邏輯,只能說是在“過度優化”。
5.4 保持良好編碼習慣
-
模塊化與解耦:
- 如果各個功能模塊職責清晰,性能問題才更容易定位。
- 例如,通過合理劃分 Service 層、DAO 層、Cache 層,讓你快速判斷“熱點在哪一層”。
-
日志與監控埋點:
- 在關鍵流程前后加上合理的日志(或 APM 打點),能提供足夠信息進行事后分析。
- 切忌對所有調用都打粗粒度日志,否則容易淹沒關鍵數據。
-
遵循編碼規范:
- 命名規范、一致的異常處理、合理使用集合(List/Set/Map)等,不僅提高可讀性,也有助于將來優化。
六、小結
-
為什么要度量?
- 只有做足數據,才能找到最關鍵的瓶頸點,而非“憑感覺改代碼”。
-
度量哪些指標?
- 吞吐量(QPS/TPS)、響應時間(AVG、TP90/95/99)、并發量、秒開率、正確性等,從多角度評估系統表現。
-
度量之后怎么做?
- 根據“木桶理論”,先找最短板(如磁盤 I/O、熱點鎖、慢 GC);
- 基準測試與預熱,排除 JIT 和初始噪聲對測量結果的影響;
- 在代碼/架構層面著手改進,但注意“不要過早”“不要過度”;
- 持續監控,收集更多請求樣本,不斷迭代優化。
掌握了這些指標與方法后,就擁有了“從定量度量到落地優化”的第一把利器。


)

















