嘿,各位AI愛好者!還記得那些機器人般毫無感情的合成語音嗎?或者那些只能完全模仿但無法創造的語音克隆?今天我要介紹的Spark-TTS模型,可能會讓這些問題成為歷史。想象一下,你可以讓AI不僅說出任何文字,還能控制它是用男聲還是女聲,高音還是低音,快速還是緩慢…聽起來很酷,對吧?那就跟我一起來看看這個語音合成界的"變聲大師"吧!
為什么我們需要一個新的TTS模型?
在深入了解Spark-TTS之前,讓我們先聊聊目前TTS(文本轉語音)技術面臨的幾個"小煩惱":
- 架構太復雜:現有的TTS系統經常需要多個模型協同工作,就像一個需要五六個廚師才能做出一道菜的餐廳
- 缺乏控制靈活性:大多數系統只能模仿現有聲音,但無法精確調整聲音特性,就像只能照搬食譜而不能調味
- 缺少統一的評估標準:沒有一個公認的"評分卡"來衡量不同TTS系統的好壞
Spark-TTS就是為了解決這些問題而生的。它不僅簡化了架構,還提供了前所未有的語音控制能力,同時還帶來了一個開放的數據集作為行業"評分卡"。
Spark-TTS的秘密武器:BiCodec
Spark-TTS最大的創新在于一個叫做BiCodec的組件。這是什么神奇的東西?簡單來說,BiCodec就像是一個超級高效的語音編碼器,它把語音分解成兩種互補的"代幣"(Token):
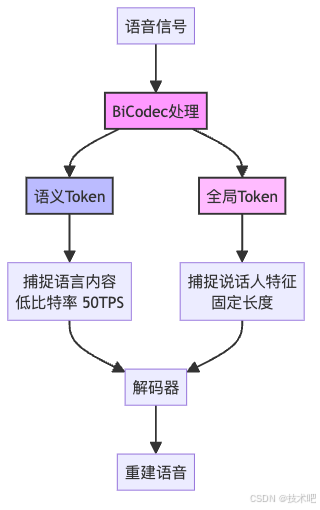
這兩種Token各司其職:
- 語義Token:記錄"說了什么",每秒50個Token,非常節省空間
- 全局Token:記錄"誰在說",包含說話人的音色、性別等固定特征
這種設計太聰明了!就像把一段語音拆成了"內容"和"聲音特征"兩部分,這樣我們就可以單獨控制每個部分。想要同樣的話用不同的聲音說出來?只需要換一下全局Token就行。想要不同的話用同樣的聲音說出來?只需要換一下語義Token就行。
Spark-TTS的統一架構:簡約而不簡單
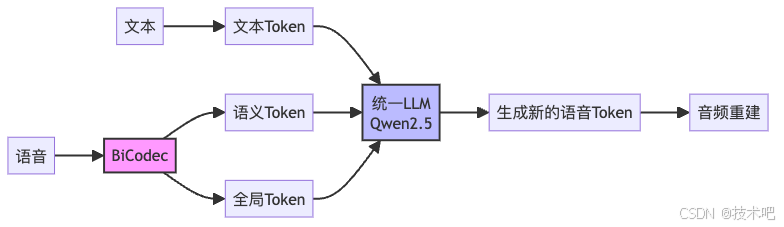
Spark-TTS的另一個亮點是它的統一架構。它把BiCodec產生的語音Token和普通的文本Token一起輸入到同一個LLM中(具體使用了Qwen2.5-0.5B模型)。這就像把"做飯"和"調酒"這兩項看似不同的技能交給同一個大廚處理,大大簡化了整個流程。
這種設計讓Spark-TTS可以像普通的文本生成模型一樣工作,只不過它生成的不是文字,而是可以轉換成語音的Token。想象一下,之前需要一個復雜的廚房才能完成的工作,現在只需要一個多才多藝的廚師就夠了!
想要什么聲音,就有什么聲音
Spark-TTS最讓人興奮的能力是它強大的語音控制能力。它支持兩種控制方式:
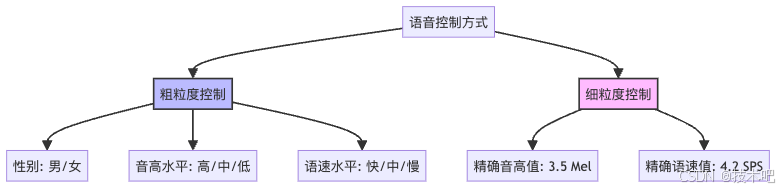
- 粗粒度控制:就像是告訴模型"我要一個高音快語速的女聲"
- 細粒度控制:就像是告訴模型"我要音高是3.5 Mel,語速是4.2 SPS的聲音"
這就像是從"我要一杯甜飲料"到"我要一杯加了3.5勺糖、4.2毫升檸檬汁的飲料"的精確跨越!更厲害的是,即使你只提供粗粒度控制,Spark-TTS也會通過"思維鏈"(Chain-of-Thought)機制自動推斷出合適的細粒度參數。
實驗結果顯示,Spark-TTS在性別控制上的準確率高達99.77%。這意味著,如果你要求它用女聲說話,幾乎可以100%確定它會用女聲說話,而不會突然冒出一個大叔的聲音!
VoxBox數據集:TTS界的"ImageNet"
為了推動整個TTS領域的發展,Spark-TTS的研究團隊還發布了一個名為VoxBox的開源數據集。這個數據集包含了超過10萬小時的中英文語音數據,每條數據都有詳細的屬性標注,包括性別、音高和語速,有些甚至還標注了年齡和情感。
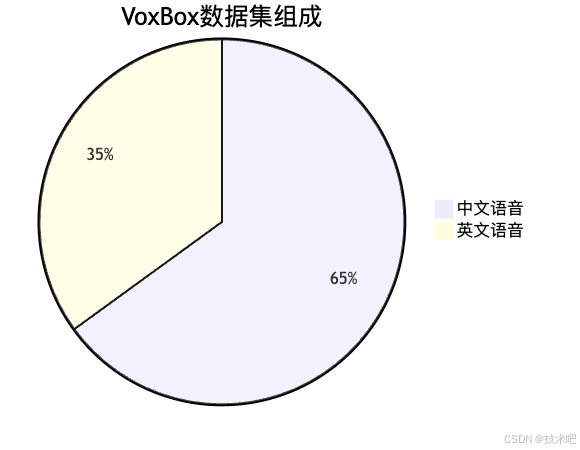
這就像是給TTS研究者們提供了一個"標準訓練場",讓大家可以在同一個"賽道"上比較不同模型的性能。在這個數據集的幫助下,TTS技術的發展可能會像計算機視覺在ImageNet數據集發布后那樣迅速加速!
Spark-TTS的性能:以小博大的效率冠軍
在性能方面,Spark-TTS也表現不俗:
- 低比特率,高質量:在低比特率(<1 kbps)下,BiCodec的語音重建質量達到了業界最高水平
- 高可懂度:在零樣本TTS測試中,Spark-TTS生成的語音在可懂度方面表現優異,中文錯誤率僅次于閉源模型Seed-TTS
- 輕量高效:使用僅0.5B參數和10萬小時訓練數據,Spark-TTS性能超過了參數量是它16倍(8B)、訓練數據是它2.5倍(25萬小時)的Llasa模型
這就像是一個體重只有對手一半的拳擊手,卻能打敗更高級別的對手!Spark-TTS證明了,有時候聰明的設計比簡單地堆砌更多資源更重要。
還有改進空間
當然,Spark-TTS也不是完美的。研究者指出,在零樣本TTS場景下,Spark-TTS在說話人相似度方面還有提升空間。簡單說,就是當它模仿某個人的聲音時,聽起來可能還不夠像。這可能是因為自回歸語言模型在生成過程中引入了一些隨機性,以及全局Token對音色的控制還不夠精確。
不過,研究團隊已經計劃在未來的版本中解決這個問題,主要方向是增強全局Token對音色的控制能力。
總結:語音合成的新時代
Spark-TTS通過創新的BiCodec技術和統一的LLM架構,為語音合成領域帶來了三大突破:
- 架構簡化:單一模型替代復雜的多階段系統
- 精確控制:前所未有的語音屬性精確控制能力
- 標準基準:VoxBox數據集為整個行業提供了標準評估基準
這些進步讓我們離"任意文本,任意聲音,任意風格"的理想TTS系統又近了一步。想象一下,未來你可能會有一個AI助手,它不僅能用你喜歡的聲音說話,還能根據場景自動調整語速和語調,激動時會提高音調,嚴肅時會放慢語速…這一切,都可能因為Spark-TTS這樣的技術突破而變為現實。
對于AI愛好者和開發者來說,Spark-TTS展示了如何通過巧妙的架構設計和數據表示方式,讓AI系統變得更加靈活和可控。即使你不直接從事TTS開發,這種思路也值得借鑒:有時候,改變數據的表示方式,比簡單地增加模型大小更能帶來突破性的進展。
你期待這樣的AI語音技術用在哪些場景呢?是個性化的有聲讀物,還是能模仿你聲音的數字助手?歡迎在評論區分享你的想法!



- 多實體建模拆圖案例)

)

![[藍橋杯C++ 2024 國 B ] 立定跳遠(二分)](http://pic.xiahunao.cn/[藍橋杯C++ 2024 國 B ] 立定跳遠(二分))




)
)

)

![[藍橋杯]約瑟夫環](http://pic.xiahunao.cn/[藍橋杯]約瑟夫環)
架構的挑戰?)
