Redis是一種基于內存的數據庫,對數據的讀寫操作都是在內存中完成,因此讀寫速度非常快,常用于緩存,消息隊列、分布式鎖等場景。
Redis 提供了多種數據類型來支持不同的業務場景,比如 String(字符串)、Hash(哈希)、 List (列表)、Set(集合)、Zset(有序集合)、Bitmaps(位圖)、HyperLogLog(基數統計)、GEO(地理信息)、Stream(流),并且對數據類型的操作都是原子性的,因為執行命令由單線程負責的,不存在并發競爭的問題。
Redis 與 Memcached 區別:
? Redis 支持的數據類型更豐富(String、Hash、List、Set、ZSet),而 Memcached 只支持最簡單的 key-value 數據類型;
? Redis 支持數據的持久化,可以將內存中的數據保持在磁盤中,重啟的時候可以再次加載進行使用,而 Memcached 沒有持久化功能,數據全部存在內存之中,Memcached 重啟或者掛掉后,數據就沒了;
? Redis 原生支持集群模式,Memcached 沒有原生的集群模式,需要依靠客戶端來實現往集群中分片寫入數據;
? Redis 支持發布訂閱模型、Lua 腳本、事務等功能,而 Memcached 不支持;
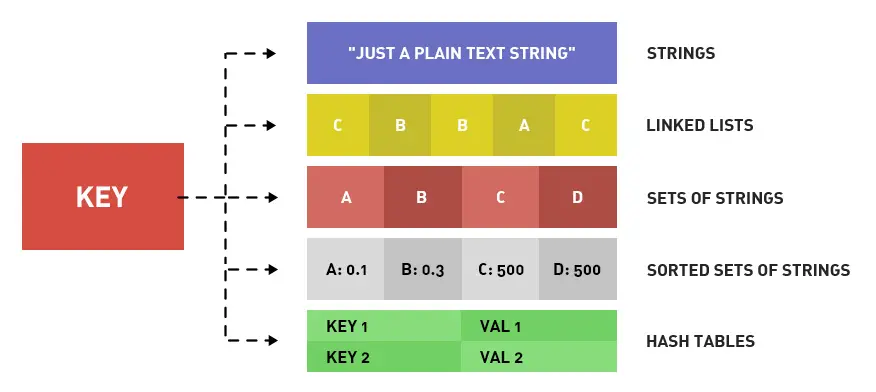
Redis 五種數據類型的應用場景:
? String 類型的應用場景:緩存對象、常規計數、分布式鎖、共享 session 信息等。
? List 類型的應用場景:消息隊列(但是有兩個問題:1. 生產者需要自行實現全局唯一 ID;2. 不能以消費組形式消費數據)等。
? Hash 類型:緩存對象、購物車等。
? Set 類型:聚合計算(并集、交集、差集)場景,比如點贊、共同關注、抽獎活動等。
? Zset 類型:排序場景,比如排行榜、電話和姓名排序等。Redis 后續版本又支持四種數據類型,它們的應用場景如下:
? BitMap(2.2 版新增):二值狀態統計的場景,比如簽到、判斷用戶登陸狀態、連續簽到用戶總數等;
? HyperLogLog(2.8 版新增):海量數據基數統計的場景,比如百萬級網頁 UV 計數等;
? GEO(3.2 版新增):存儲地理位置信息的場景,比如滴滴叫車;
? Stream(5.0 版新增):消息隊列,相比于基于 List 類型實現的消息隊列,有這兩個特有的特性:自動生成全局唯一消息ID,支持以消費組形式消費數據。
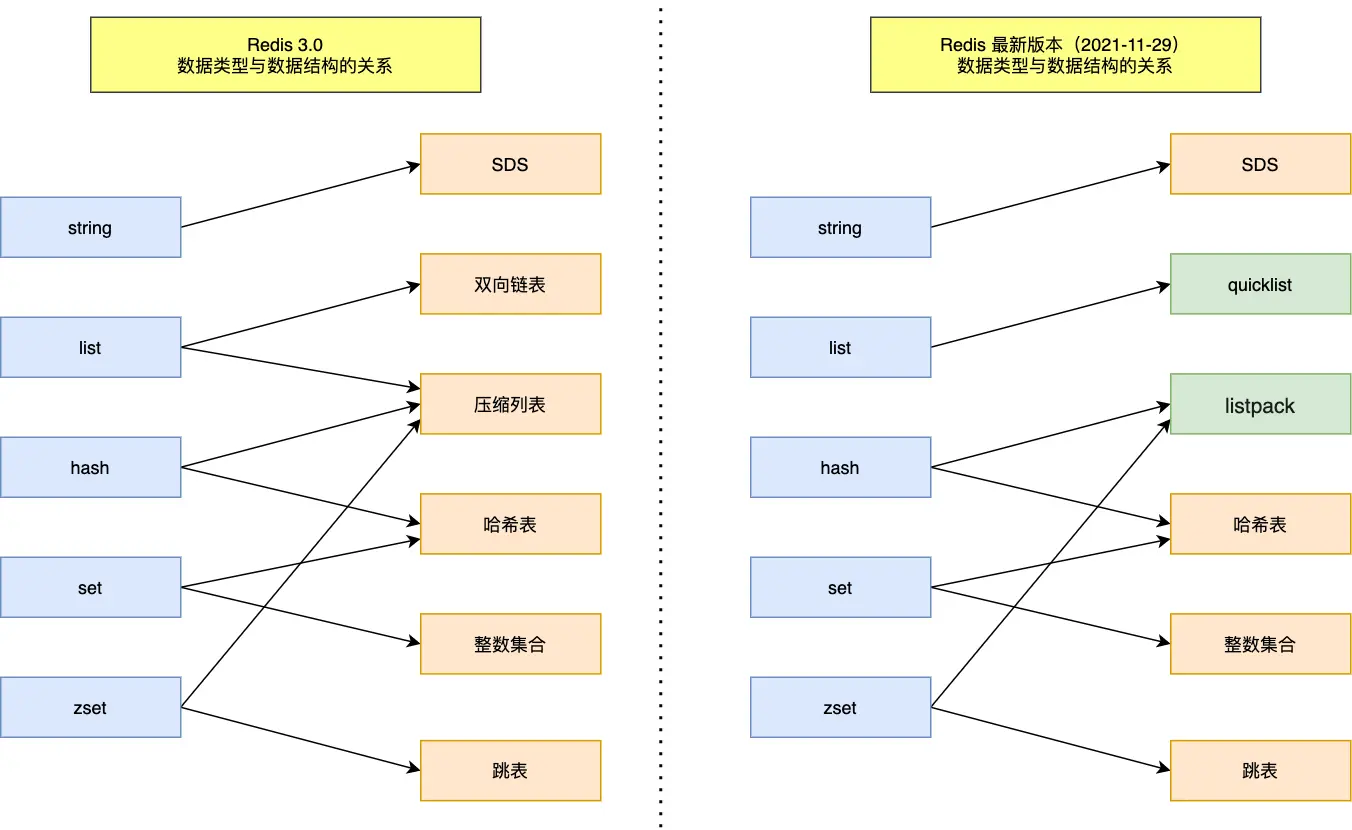
redis數據類型的實現
外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳
String 類型的底層的數據結構實現主要是 SDS(簡單動態字符串):
SDS 不僅可以保存文本數據,還可以保存二進制數據。
SDS 獲取字符串長度的時間復雜度是 O(1)。
Redis 的 SDS API 是安全的,拼接字符串不會造成緩沖區溢出。
redis線程模型
Redis 單線程指的是「接收客戶端請求->解析請求 ->進行數據讀寫等操作->發送數據給客戶端」這個過程是由一個線程(主線程)來完成的。
Redis 為「關閉文件、AOF 刷盤、釋放內存」這些任務創建單獨的線程來處理,是因為這些任務的操作都是很耗時的,如果把這些任務都放在主線程來處理,那么 Redis 主線程就很容易發生阻塞,這樣就無法處理后續的請求了。
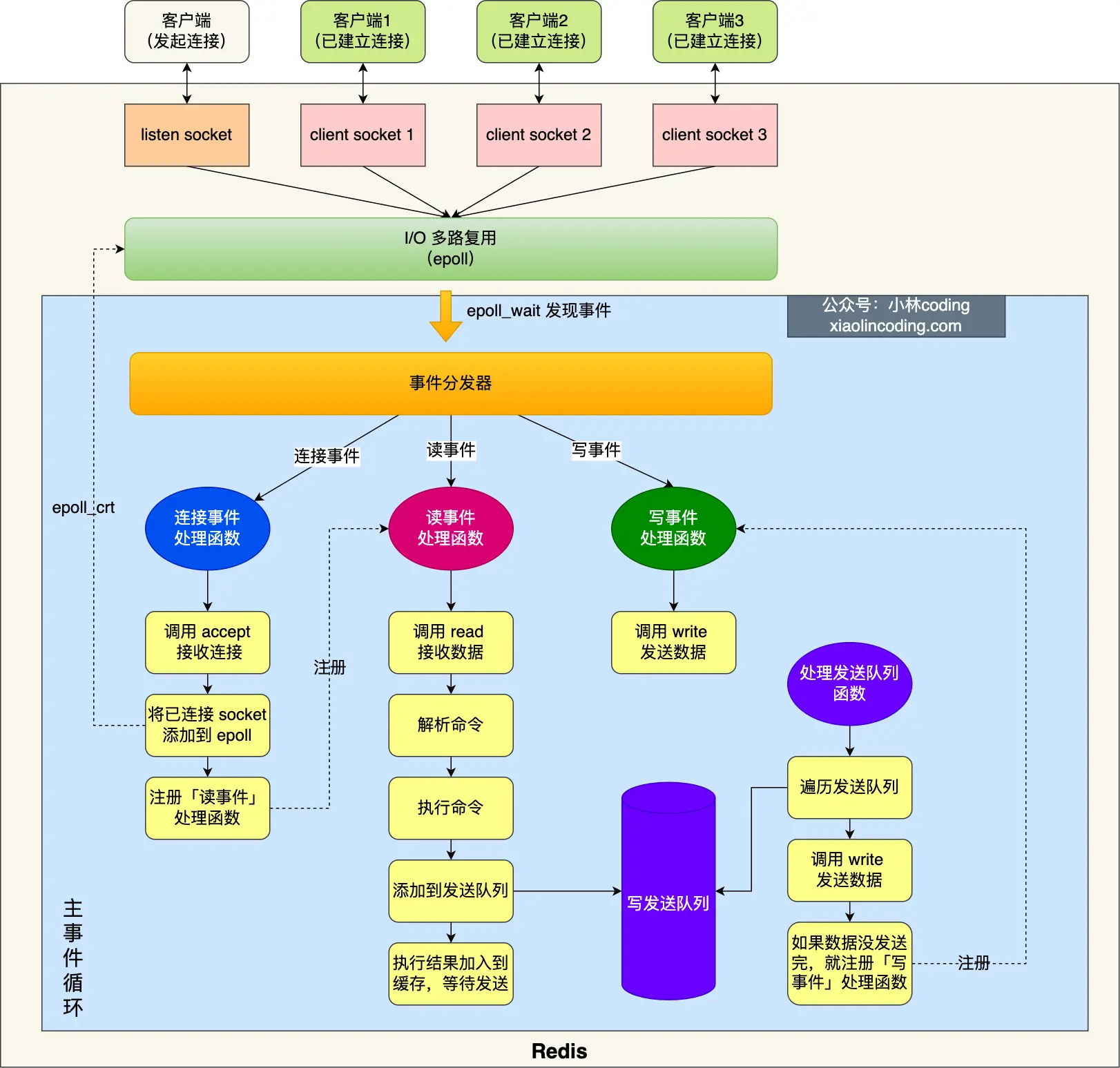
在 Redis 6.0 版本之后,也采用了多個 I/O 線程來處理網絡請求,這是因為隨著網絡硬件的性能提升,Redis 的性能瓶頸有時會出現在網絡 I/O 的處理上。
Redis 持久化
Redis 共有三種數據持久化的方式:? AOF 日志:每執行一條寫操作命令,就把該命令以追加的方式寫入到一個文件里;
? RDB 快照:將某一時刻的內存數據,以二進制的方式寫入磁盤;
? 混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RDB 的優點;
Redis 提供了 3 種寫回硬盤的策略,控制的就是上面說的第三步的過程。 在 Redis.conf 配置文件中的 appendfsync 配置項可以有以下 3 種參數可填:
? Always,這個單詞的意思是「總是」,所以它的意思是每次寫操作命令執行完后,同步將 AOF 日志數據寫回硬盤;
? Everysec,這個單詞的意思是「每秒」,所以它的意思是每次寫操作命令執行完后,先將命令寫入到 AOF 文件的內核緩沖區,然后每隔一秒將緩沖區里的內容寫回到硬盤;
? No,意味著不由 Redis 控制寫回硬盤的時機,轉交給操作系統控制寫回的時機,也就是每次寫操作命令執行完后,先將命令寫入到 AOF 文件的內核緩沖區,再由操作系統決定何時將緩沖區內容寫回硬盤。
| 特性 | AOF 緩沖區 | AOF 重寫緩沖區 |
|---|---|---|
| 用途 | 暫存所有寫命令,用于常規 AOF 刷盤 | 暫存 AOF 重寫期間的新命令,保證數據一致性 |
| 生命周期 | 持續存在,Redis 運行期間一直使用 | 僅在 AOF 重寫過程中存在 |
| 刷盤時機 | 由 appendfsync 控制 | 在重寫完成后一次性寫入新 AOF 文件 |
| 數據量 | 通常較小(取決于刷盤頻率) | 可能較大(取決于重寫耗時和寫命令頻率) |
RDB快照
RDB 快照就是記錄某一個瞬間的內存數據,記錄的是實際數據,而 AOF 文件記錄的是命令操作的日志,而不是實際的數據。
執行 bgsave 過程中,Redis 依然可以繼續處理操作命令的,也就是數據是能被修改的,關鍵的技術就在于寫時復制技術(Copy-On-Write, COW)。
如果主線程執行寫操作,則被修改的數據會復制一份副本,然后 bgsave 子進程會把該副本數據寫入 RDB 文件,在這個過程中,主線程仍然可以直接修改原來的數據。
混合持久化
為了集成了兩者的優點, Redis 4.0 提出了混合使用 AOF 日志和內存快照,也叫混合持久化,既保證了 Redis 重啟速度,又降低數據丟失風險。
redis集群
主從復制
主服務器可以進行讀寫操作,當發生寫操作時自動將寫操作同步給從服務器,而從服務器一般是只讀,并接受主服務器同步過來寫操作命令,然后執行這條命令。
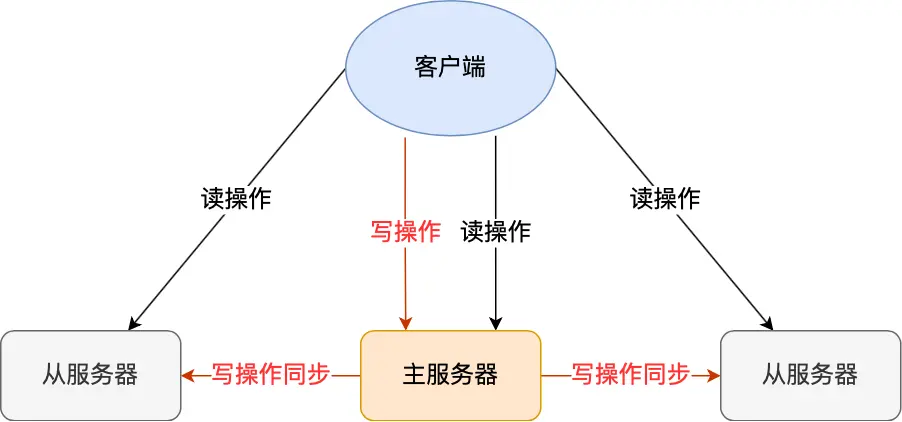
主從服務器之間的命令復制是異步進行的。具體來說,在主從服務器命令傳播階段,主服務器收到新的寫命令后,會發送給從服務器。但是,主服務器并不會等到從服務器實際執行完命令后,再把結果返回給客戶端,而是主服務器自己在本地執行完命令后,就會向客戶端返回結果了。如果從服務器還沒有執行主服務器同步過來的命令,主從服務器間的數據就不一致了。所以,無法實現強一致性保證(主從數據時時刻刻保持一致),數據不一致是難以避免的。
哨兵模式
在使用 Redis 主從服務的時候,會有一個問題,就是當 Redis 的主從服務器出現故障宕機時,需要手動進行恢復。為了解決這個問題,Redis 增加了哨兵模式(Redis Sentinel),因為哨兵模式做到了可以監控主從服務器,并且提供主從節點故障轉移的功能。
切片集群模式
當 Redis 緩存數據量大到一臺服務器無法緩存時,就需要使用 Redis 切片集群(Redis Cluster )方案,它將數據分布在不同的服務器上,以此來降低系統對單主節點的依賴,從而提高 Redis 服務的讀寫性能。Redis Cluster 方案采用哈希槽(Hash Slot),來處理數據和節點之間的映射關系。在 Redis Cluster 方案中,一個切片集群共有 16384 個哈希槽,這些哈希槽類似于數據分區,每個鍵值對都會根據它的 key,被映射到一個哈希槽中,具體執行過程分為兩大步:
? 根據鍵值對的 key,按照 CRC16 算法(opens new window)計算一個 16 bit 的值。
? 再用 16bit 值對 16384 取模,得到 0~16383 范圍內的模數,每個模數代表一個相應編號的哈希槽。
Redis 過期刪除與內存淘汰
每當我們對一個 key 設置了過期時間時,Redis 會把該 key 帶上過期時間存儲到一個過期字典(expires dict)中,也就是說「過期字典」保存了數據庫中所有 key 的過期時間。
Redis 使用的過期刪除策略是「惰性刪除+定期刪除」這兩種策略配和使用。
惰性刪除策略的做法是,不主動刪除過期鍵,每次從數據庫訪問 key 時,都檢測 key 是否過期,如果過期則刪除該 key。
定期刪除策略的做法是,每隔一段時間「隨機」從數據庫中取出一定數量的 key 進行檢查,并刪除其中的過期key。Redis 的定期刪除的流程:
-
從過期字典中隨機抽取 20 個 key;
-
檢查這 20 個 key 是否過期,并刪除已過期的 key;
-
如果本輪檢查的已過期 key 的數量,超過 5 個(20/4),也就是「已過期 key 的數量」占比「隨機抽取 key 的數量」大于 25%,則繼續重復步驟 1;如果已過期的 key 比例小于 25%,則停止繼續刪除過期 key,然后等待下一輪再檢查。可以看到,定期刪除是一個循環的流程。那 Redis 為了保證定期刪除不會出現循環過度,導致線程卡死現象,為此增加了定期刪除循環流程的時間上限,默認不會超過 25ms。
如何避免緩存雪崩、緩存擊穿、緩存穿透
通常我們為了保證緩存中的數據與數據庫中的數據一致性,會給 Redis 里的數據設置過期時間,當緩存數據過期后,用戶訪問的數據如果不在緩存里,業務系統需要重新生成緩存,因此就會訪問數據庫,并將數據更新到 Redis 里,這樣后續請求都可以直接命中緩存。
當大量緩存數據在同一時間過期(失效)時,如果此時有大量的用戶請求,都無法在 Redis 中處理,于是全部請求都直接訪問數據庫,從而導致數據庫的壓力驟增,嚴重的會造成數據庫宕機,從而形成一系列連鎖反應,造成整個系統崩潰,這就是緩存雪崩的問題。
將緩存失效時間隨機打散: 我們可以在原有的失效時間基礎上增加一個隨機值(比如 1 到 10 分鐘)這樣每個緩存的過期時間都不重復了,也就降低了緩存集體失效的概率。
設置緩存不過期: 我們可以通過后臺服務來更新緩存數據,從而避免因為緩存失效造成的緩存雪崩,也可以在一定程度上避免緩存并發問題。
我們的業務通常會有幾個數據會被頻繁地訪問,比如秒殺活動,這類被頻地訪問的數據被稱為熱點數據。如果緩存中的某個熱點數據過期了,此時大量的請求訪問了該熱點數據,就無法從緩存中讀取,直接訪問數據庫,數據庫很容易就被高并發的請求沖垮,這就是緩存擊穿的問題。
互斥鎖方案(Redis 中使用 setNX 方法設置一個狀態位,表示這是一種鎖定狀態),保證同一時間只有一個業務線程請求緩存,未能獲取互斥鎖的請求,要么等待鎖釋放后重新讀取緩存,要么就返回空值或者默認值。
不給熱點數據設置過期時間,由后臺異步更新緩存,或者在熱點數據準備要過期前,提前通知后臺線程更新緩存以及重新設置過期時間;
當用戶訪問的數據,既不在緩存中,也不在數據庫中,導致請求在訪問緩存時,發現緩存缺失,再去訪問數據庫時,發現數據庫中也沒有要訪問的數據,沒辦法構建緩存數據,來服務后續的請求。那么當有大量這樣的請求到來時,數據庫的壓力驟增,這就是緩存穿透的問題。
非法請求的限制:當有大量惡意請求訪問不存在的數據的時候,也會發生緩存穿透,因此在 API 入口處我們要判斷求請求參數是否合理,請求參數是否含有非法值、請求字段是否存在,如果判斷出是惡意請求就直接返回錯誤,避免進一步訪問緩存和數據庫。? 設置空值或者默認值:當我們線上業務發現緩存穿透的現象時,可以針對查詢的數據,在緩存中設置一個空值或者默認值,這樣后續請求就可以從緩存中讀取到空值或者默認值,返回給應用,而不會繼續查詢數據庫。? 使用布隆過濾器快速判斷數據是否存在,避免通過查詢數據庫來判斷數據是否存在:我們可以在寫入數據庫數據時,使用布隆過濾器做個標記,然后在用戶請求到來時,業務線程確認緩存失效后,可以通過查詢布隆過濾器快速判斷數據是否存在,如果不存在,就不用通過查詢數據庫來判斷數據是否存在,即使發生了緩存穿透,大量請求只會查詢 Redis 和布隆過濾器,而不會查詢數據庫,保證了數據庫能正常運行,Redis 自身也是支持布隆過濾器的。
常見的緩存更新策略共有3種:
? Cache Aside(旁路緩存)策略;
? Read/Write Through(讀穿 / 寫穿)策略;
? Write Back(寫回)策略;
)
)

)

![[藍橋杯]約瑟夫環](http://pic.xiahunao.cn/[藍橋杯]約瑟夫環)
架構的挑戰?)





)
)

)
)


)