1. 查詢優化器
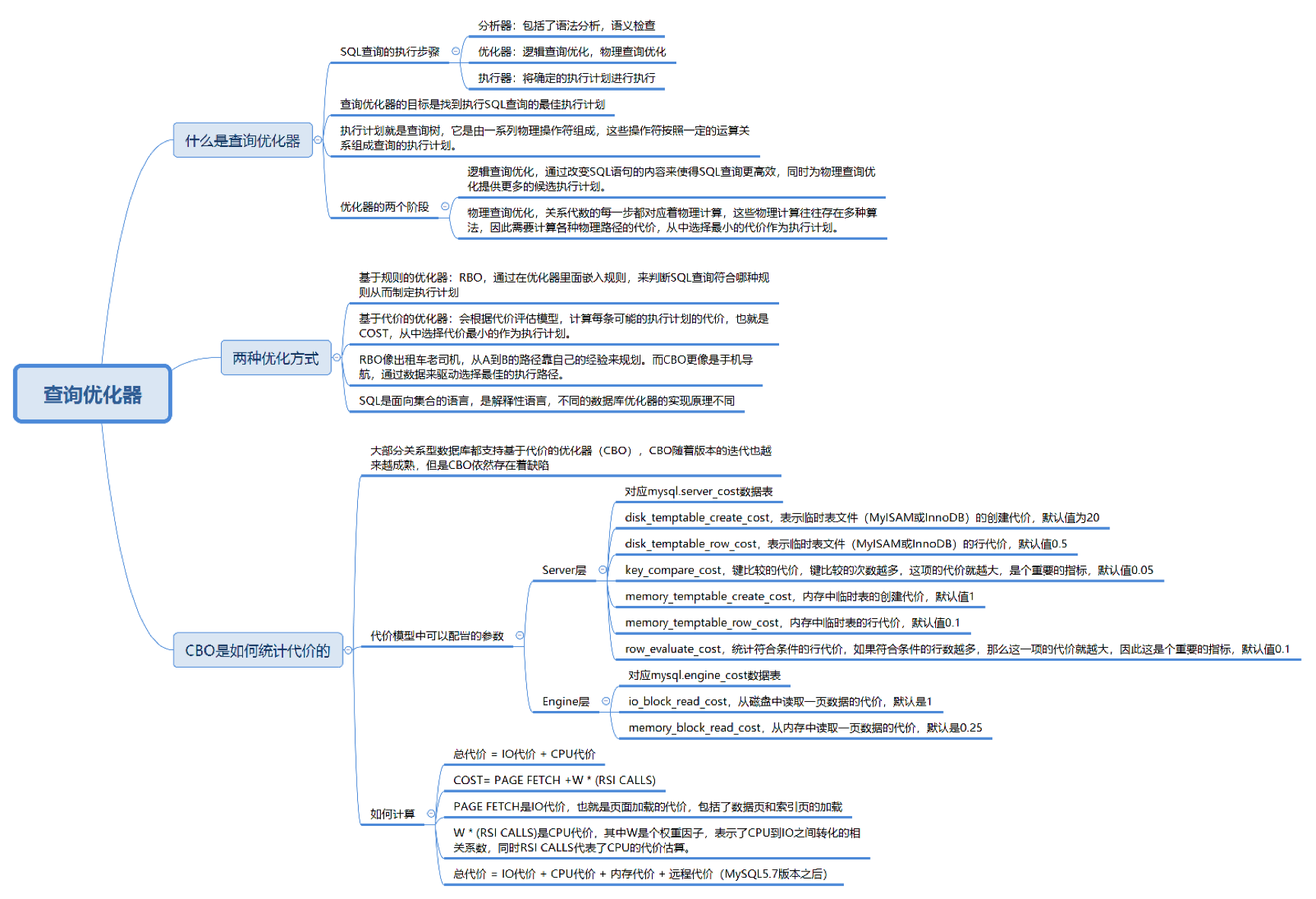
1.1. SQL語句執行需要經歷的環節
- 解析階段:語法分析和語義檢查,確保語句正確;
- 優化階段:通過優化器生成查詢計劃;
- 執行階段:由執行器根據查詢計劃實際執行操作。

1.2. 查詢優化器
查詢優化器的概念:
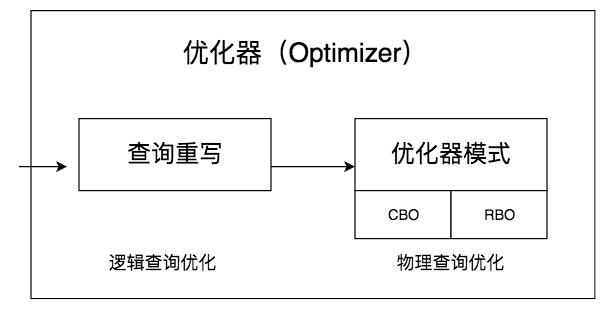
查詢優化器的作用是為 SQL 查詢生成最優的執行計劃。其內部通常分為兩個階段:
1. 邏輯優化:
- 基于關系代數進行等價重寫(如謂詞下推、連接重寫、視圖展開);
- 目的是生成多個邏輯上等價但執行效率不同的候選計劃。
2. 物理優化:
- 為邏輯計劃選擇具體的物理操作(如全表掃描 vs 索引掃描,嵌套循環連接 vs 哈希連接);
- 通過代價估算模型選出代價最小的執行路徑。
查詢優化器的兩種優化方式:
- 第一種是基于規則的優化器(RBO,Rule-Based Optimizer),規則就是人們以往的經驗,或者是采用已經被證明是有效的方式。通過在優化器里面嵌入規則,來判斷 SQL 查詢符合哪種規則,就按照相應的規則來制定執行計劃,同時采用啟發式規則去掉明顯不好的存取路徑。
- 第二種是基于代價的優化器(CBO,Cost-Based Optimizer),這里會根據代價評估模型,計算每條可能的執行計劃的代價,也就是 COST,從中選擇代價最小的作為執行計劃。相比于 RBO 來說,CBO 對數據更敏感,因為它會利用數據表中的統計信息來做判斷,針對不同的數據表,查詢得到的執行計劃可能是不同的,因此制定出來的執行計劃也更符合數據表的實際情況。
RBO 的方式更像是一個出租車老司機,憑借自己的經驗來選擇從 A 到 B 的路徑。而 CBO 更像是手機導航,通過數據驅動,來選擇最佳的執行路徑。
1.3. CBO 的代價估算機制
1. 代價模型
能調整的代價模型的參數:
MySQL 中的COST Model就是優化器用來統計各種步驟的代價模型,MySQL 會引入兩張數據表,里面規定了各種步驟預估的代價(Cost Value) ,我們可以從mysql.server_cost和mysql.engine_cost這兩張表中獲得這些步驟的代價:
SQL > SELECT * FROM mysql.server_cost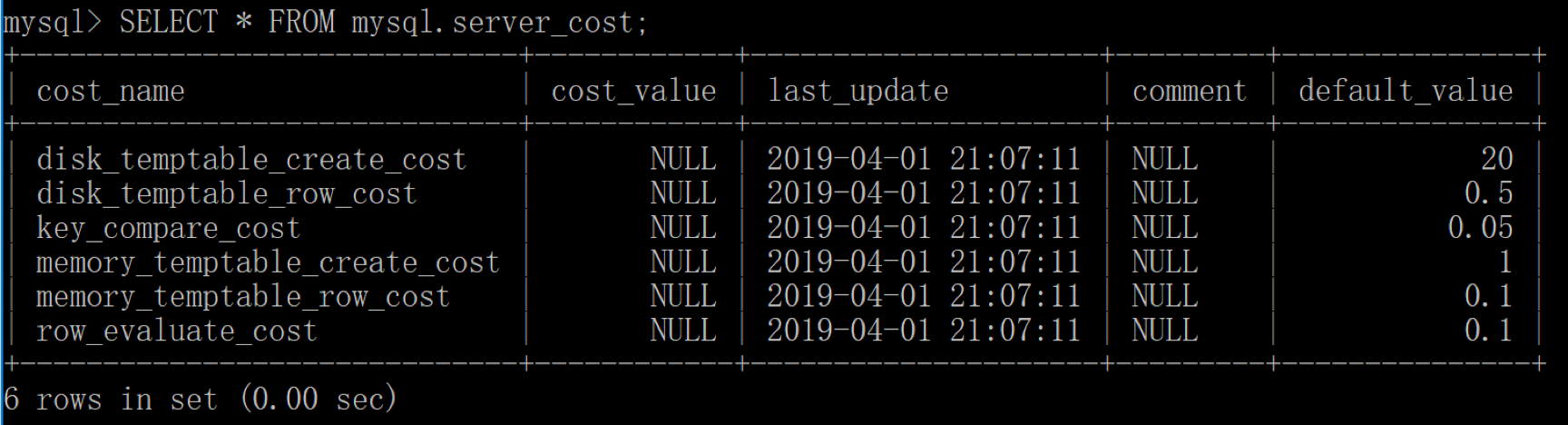
server_cost 數據表是在 server 層統計的代價,具體的參數含義如下:
disk_temptable_create_cost,表示臨時表文件(MyISAM 或 InnoDB)的創建代價,默認值為 20。disk_temptable_row_cost,表示臨時表文件(MyISAM 或 InnoDB)的行代價,默認值 0.5。key_compare_cost,表示鍵比較的代價。鍵比較的次數越多,這項的代價就越大,這是一個重要的指標,默認值 0.05。memory_temptable_create_cost,表示內存中臨時表的創建代價,默認值 1。memory_temptable_row_cost,表示內存中臨時表的行代價,默認值 0.1。row_evaluate_cost,統計符合條件的行代價,如果符合條件的行數越多,那么這一項的代價就越大,因此這是個重要的指標,默認值 0.1。
在存儲引擎層都包括了哪些代價:
SQL > SELECT * FROM mysql.engine_cost
engine_cost主要統計了頁加載的代價,一個頁的加載根據頁所在位置的不同,讀取的位置也不同,可以從磁盤 I/O 中獲取,也可以從內存中讀取。因此在engine_cost數據表中對這兩個讀取的代價進行了定義:
io_block_read_cost,從磁盤中讀取一頁數據的代價,默認是 1。memory_block_read_cost,從內存中讀取一頁數據的代價,默認是 0.25。
通過SQL語句調整以上參數:
MySQL 將這些代價參數以數據表的形式呈現給了我們,我們就可以根據實際情況去修改這些參數。因為隨著硬件的提升,各種硬件的性能對比也可能發生變化,比如針對普通硬盤的情況,可以考慮適當增加io_block_read_cost的數值,這樣就代表從磁盤上讀取一頁數據的成本變高了。當我們執行全表掃描的時候,相比于范圍查詢,成本也會增加很多。
將io_block_read_cost參數設置為 2.0,使用下面這條命令:
UPDATE mysql.engine_costSET cost_value = 2.0WHERE cost_name = 'io_block_read_cost';
FLUSH OPTIMIZER_COSTS;
我們對mysql.engine_cost中的io_block_read_cost參數進行了修改,然后使用FLUSH OPTIMIZER_COSTS更新內存,然后再查看engine_cost數據表,發現io_block_read_cost參數中的cost_value已經調整為 2.0。
專門針對某個存儲引擎,比如 InnoDB 存儲引擎設置io_block_read_cost,設置為 2:
INSERT INTO mysql.engine_cost(engine_name, device_type, cost_name, cost_value, last_update, comment)VALUES ('InnoDB', 0, 'io_block_read_cost', 2,CURRENT_TIMESTAMP, 'Using a slower disk for InnoDB');
FLUSH OPTIMIZER_COSTS;再查看一下mysql.engine_cost數據表:

2. 總代價計算方式
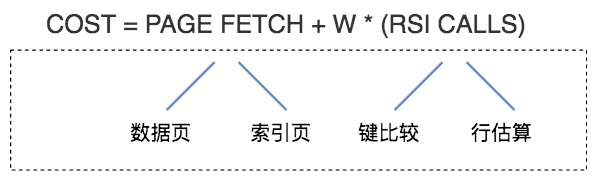
可以簡單地認為,總的執行代價等于 I/O 代價 +CPU 代價。在這里 PAGE FETCH 就是 I/O 代價,也就是頁面加載的代價,包括數據頁和索引頁加載的代價。W*(RSI CALLS) 就是 CPU 代價。W 在這里是個權重因子,表示了 CPU 到 I/O 之間轉化的相關系數,RSI CALLS 代表了 CPU 的代價估算,包括了鍵比較(compare key)以及行估算(row evaluating)的代價。
總代價 = I/O 代價 + CPU 代價 [+ 內存代價 + 遠程訪問代價]- I/O 成本:頁的加載,如索引頁和數據頁;
- CPU 成本:如行過濾、鍵比較等操作;
- W × RSI Calls:W 是 CPU/I/O 的權重因子,RSI Calls 是邏輯計算量。
2. 使用性能分析工具定位SQL執行慢的原因
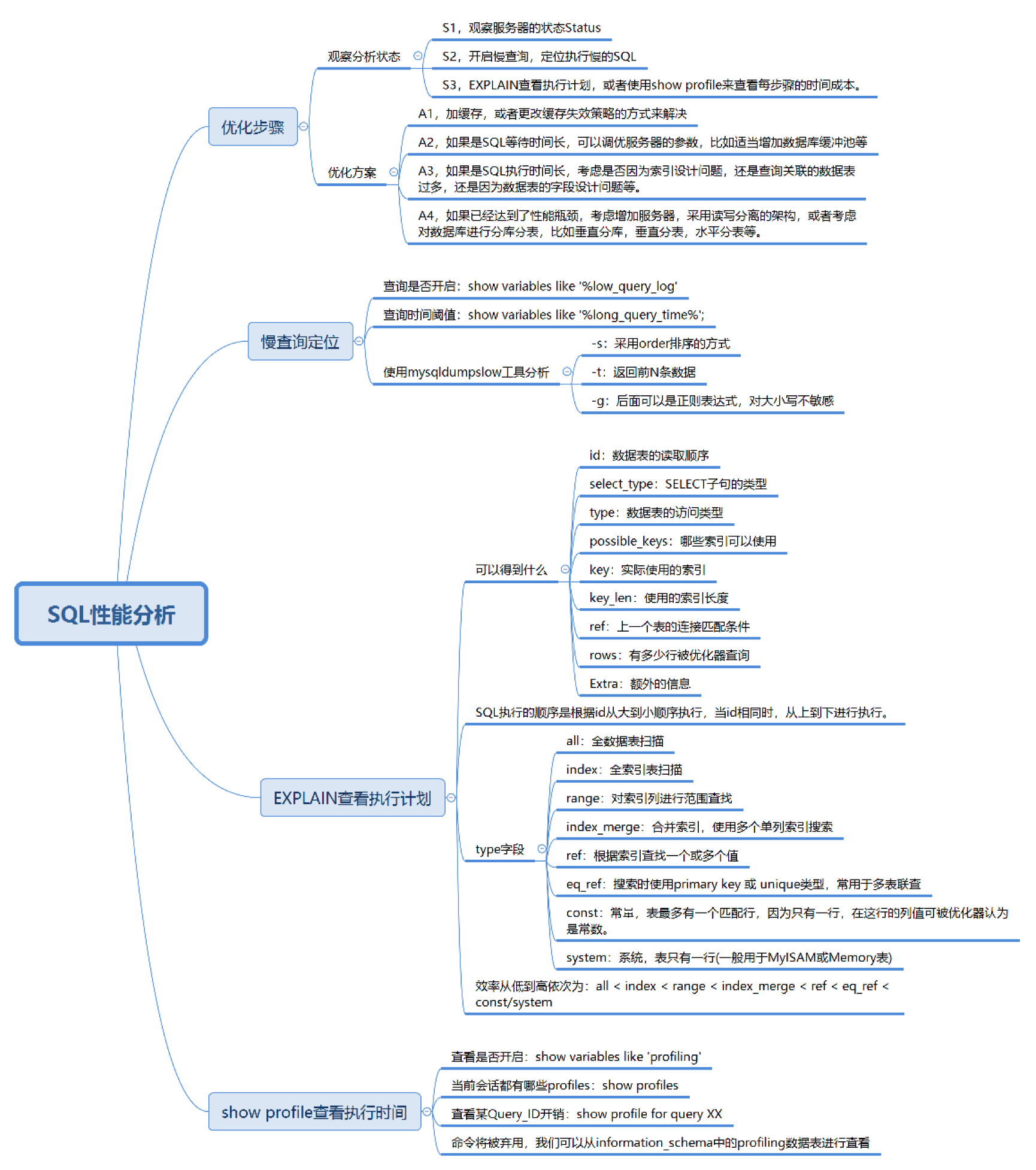
2.1. 數據庫服務器的優化步驟
整個流程劃分成了觀察(Show status)和行動(Action)兩個部分。字母 S 的部分代表觀察(會使用相應的分析工具),字母 A 代表的部分是行動(對應分析可以采取的行動)。
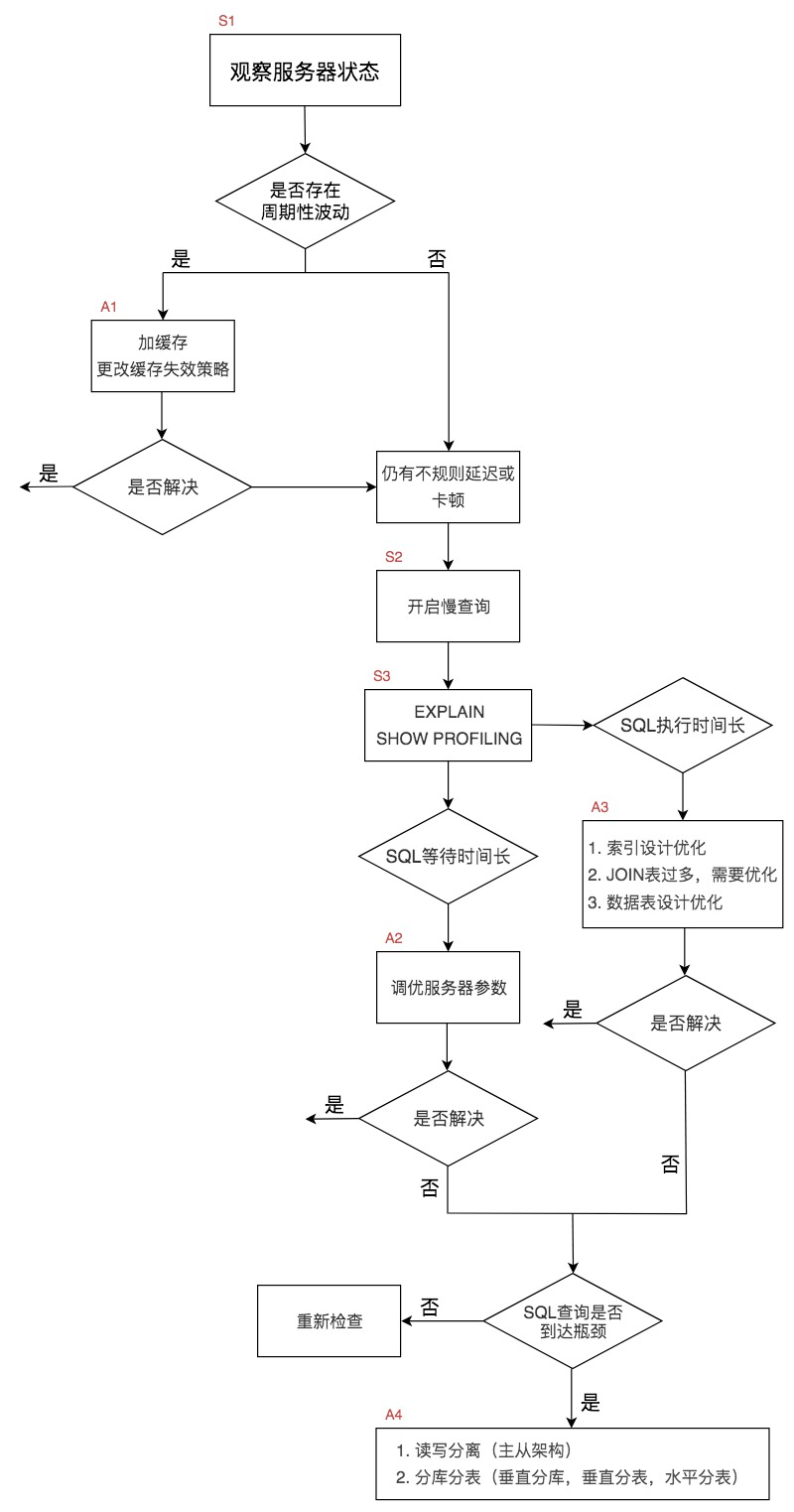
2.2. 三種性能分析工具
| 工具 | 功能 |
| 慢查詢日志 | 定位慢 SQL 語句 |
| EXPLAIN | 分析執行計劃與索引使用情況 |
| SHOW PROFILE | 分析執行過程中各步驟的時間開銷 |
1. 慢查詢日志分析(Slow Query Log)
????????1. 查看是否啟用慢查詢日志:
SHOW VARIABLES LIKE '%slow_query_log%';? ? ? ? 2. 啟用慢查詢日志:
SET GLOBAL slow_query_log = 'ON';- 查看/設置慢查詢時間閾值:
SHOW VARIABLES LIKE '%long_query_time%';
SET GLOBAL long_query_time = 3; -- 單位為秒? ? ? ? 3. 使用 mysqldumpslow 工具分析慢查詢日志:
perl mysqldumpslow.pl -s t -t 2 /路徑/slow.log| 參數 | 含義 |
|
| 排序方式(t:時間,c:次數,r:返回行數) |
|
| 顯示前幾條 |
|
| 正則匹配(不區分大小寫) |
? ? ? ? 4. 使用 EXPLAIN 分析 SQL 執行計劃
示例:
EXPLAIN SELECT ... FROM table JOIN table2 ON ...常見字段說明:
| 字段 | 含義 |
|
| 查詢執行順序,越大越早執行 |
|
| 查詢類型(SIMPLE、PRIMARY、SUBQUERY) |
|
| 正在訪問的表 |
|
| 訪問方式(越靠前越好) |
|
| 實際使用的索引 |
|
| 預估掃描行數 |
|
| 額外信息,如是否使用索引覆蓋、臨時表、排序等 |
數據表的訪問類型:

- 效率從低到高依次為 all < index < range < index_merge < ref < eq_ref < const/system。
2. 使用 SHOW PROFILE 分析查詢時間
? ? ? ? 1. 開啟 profiling:
SET profiling = 1;? ? ? ? 2. 執行要分析的 SQL:
SELECT * FROM ...;? ? ? ? 3. 查看分析結果:
SHOW PROFILES;
SHOW PROFILE FOR QUERY [query_id];| 步驟 | 說明 |
| SHOW PROFILES | 顯示最近查詢的耗時 |
| SHOW PROFILE FOR QUERY N | 顯示第 N 條查詢的各階段耗時 |
解決MySQL中長連接內存占用太大的問題:
- 定期斷開長連接。使用一段時間,或者程序里面判斷執行過一個占用內存的大查詢后,斷開連接,之后要查詢再重連。
- 如果你用的是 MySQL 5.7 或更新版本,可以在每次執行一個比較大的操作后,通過執行 mysql_reset_connection 來重新初始化連接資源。這個過程不需要重連和重新做權限驗證,但是會將連接恢復到剛剛創建完時的狀態。

- 多實體建模拆圖案例)

)

![[藍橋杯C++ 2024 國 B ] 立定跳遠(二分)](http://pic.xiahunao.cn/[藍橋杯C++ 2024 國 B ] 立定跳遠(二分))




)
)

)

![[藍橋杯]約瑟夫環](http://pic.xiahunao.cn/[藍橋杯]約瑟夫環)
架構的挑戰?)


