圖論
題目
97. 小明逛公園
本題是經典的多源最短路問題。
在這之前我們講解過,dijkstra樸素版、dijkstra堆優化、Bellman算法、Bellman隊列優化(SPFA) 都是單源最短路,即只能有一個起點。
而本題是多源最短路,即求多個起點到多個終點的多條最短路徑。
Floyd 算法對邊的權值正負沒有要求,都可以處理。
Floyd算法核心思想是動態規劃。
例如我們再求節點1 到節點9 的最短距離,用二維數組來表示即:grid[1][9],如果最短距離是10 ,那就是 grid[1][9] = 10。
那節點1 到節點9 的最短距離是不是可以由節點1 到節點5的最短距離 + 節點5到節點9的最短距離組成呢?即 grid[1][9] = grid[1][5] + grid[5][9]
節點1 到節點5的最短距離是不是可以有節點1 到節點3的最短距離 + 節點3 到節點5 的最短距離組成呢? 即 grid[1][5] = grid[1][3] + grid[3][5]
以此類推,節點1 到節點3的最短距離可以由更小的區間組成。
那么這樣我們是不是就找到了,子問題推導求出整體最優方案的遞歸關系呢。
是不是 要選一個最小的,畢竟是求最短路。此時我們已經接近明確遞歸公式了。之前在講解動態規劃的時候,給出過動規五部曲:
- 確定dp數組(dp table)以及下標的含義
- 確定遞推公式
- dp數組如何初始化
- 確定遍歷順序
- 舉例推導dp數組
具體講解
1. Dp 數組表示當前節點 i 到節點 j 以 [1,...,k] 集合節點為中間節點的最短距離grid[i][j][k] = m
節點i 到 節點j 的最短距離為m,這句話可以理解,但 以[1...k]集合為中間節點就理解不了。
節點i 到節點j 的最短路徑中一定是經過很多節點,那么這個集合用[1...k] 來表示。
你可以反過來想,節點i 到節點j 中間一定經過很多節點,那么你能用什么方式來表述中間這么多節點呢?所以這里的k不能單獨指某個節點,k 一定要表示一個集合,即 [1...k] ,表示節點1 到節點k 一共k個節點的集合。
2. 確定遞推公式,我們分兩種情況:
1. 節點i 到節點j 的最短路徑經過節點k
2. 節點i 到節點j 的最短路徑不經過節點k
對于第一種情況,grid[i][j][k] = grid[i][k][k - 1] + grid[k][j][k - 1]
節點i 到節點k 的最短距離是不經過節點k,中間節點集合 [1...k-1],表示為 grid[i][k][k - 1]
節點k 到 節點j 的最短距離也是不經過節點k,中間節點集合[1...k-1],表示為 grid[k][j][k - 1]
第二種情況,grid[i][j][k] = grid[i][j][k - 1]
如果節點i 到 節點j的最短距離 不經過節點k,中間節點集合[1...k-1],表示為 grid[i][j][k - 1]
因為我們是求最短路,對于這兩種情況自然是取最小值。
即: grid[i][j][k] = min(grid[i][k][k - 1] + grid[k][j][k - 1], grid[i][j][k - 1])
3. Dp 數組初始化
grid[i][j][k] = m,表示 節點i 到 節點j 以[1...k] 集合為中間節點的最短距離為m。
剛開始初始化k 是不確定的。例如題目中只是輸入邊(節點2 -> 節點6,權值為3),那么grid[2][6][k] = 3,k需要填什么呢?把k 填成1,那如何上來就知道 節點2 經過節點1 到達節點6的最短距離是多少 呢。所以 只能 把k 賦值為 0,本題 節點0 是無意義的,節點是從1 到 n。
這樣我們在下一輪計算的時候,就可以根據 grid[i][j][0] 來計算 grid[i][j][1],此時的 grid[i][j][1] 就是節點i 經過節點1 到達節點j 的最小距離了。
grid數組是一個三維數組,那么我們初始化的數據在 i 與 j 構成的平層,如圖: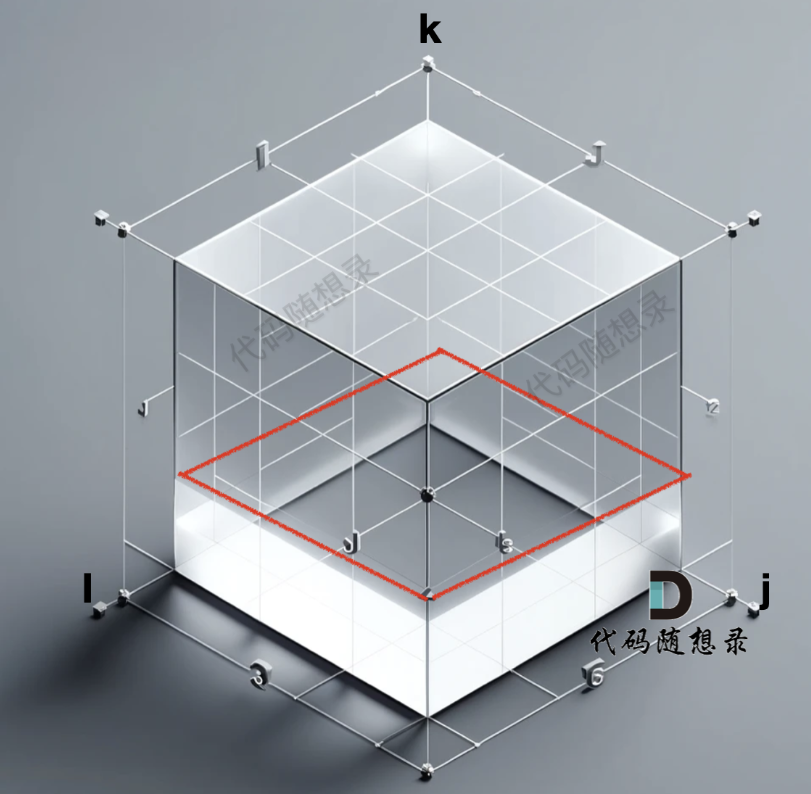
有初始化代碼
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005))); // C++定義了一個三位數組,10005是因為邊的最大距離是10^4for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;grid[p1][p2][0] = val;grid[p2][p1][0] = val; // 注意這里是雙向圖
}
grid數組中其他元素數值應該初始化多少呢?
本題求的是最小值,所以輸入數據沒有涉及到的節點的情況都應該初始為一個最大數。
這樣才不會影響,每次計算去最小值的時候 初始值對計算結果的影響。
所以grid數組的定義可以是:
// C++寫法,定義了一個三位數組,10005是因為邊的最大距離是10^4
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005)));
- 遍歷順序
從遞推公式:grid[i][j][k] = min(grid[i][k][k - 1] + grid[k][j][k - 1], grid[i][j][k - 1])可以看出,我們需要三個for循環,分別遍歷i,j 和k
而 k 依賴于 k - 1, i 和j 的到 并不依賴與 i - 1 或者 j - 1 等等。
那么這三個for的嵌套順序應該是什么樣的呢?我們來看初始化,我們是把 k =0 的 i 和j 對應的數值都初始化了,這樣才能去計算 k = 1 的時候 i 和 j 對應的數值。這就好比是一個三維坐標,i 和j 是平層,而k 是垂直向上的。遍歷的順序是從底向上一層一層去遍歷。所以遍歷k 的for循環一定是在最外面,這樣才能一層一層去遍歷。如圖: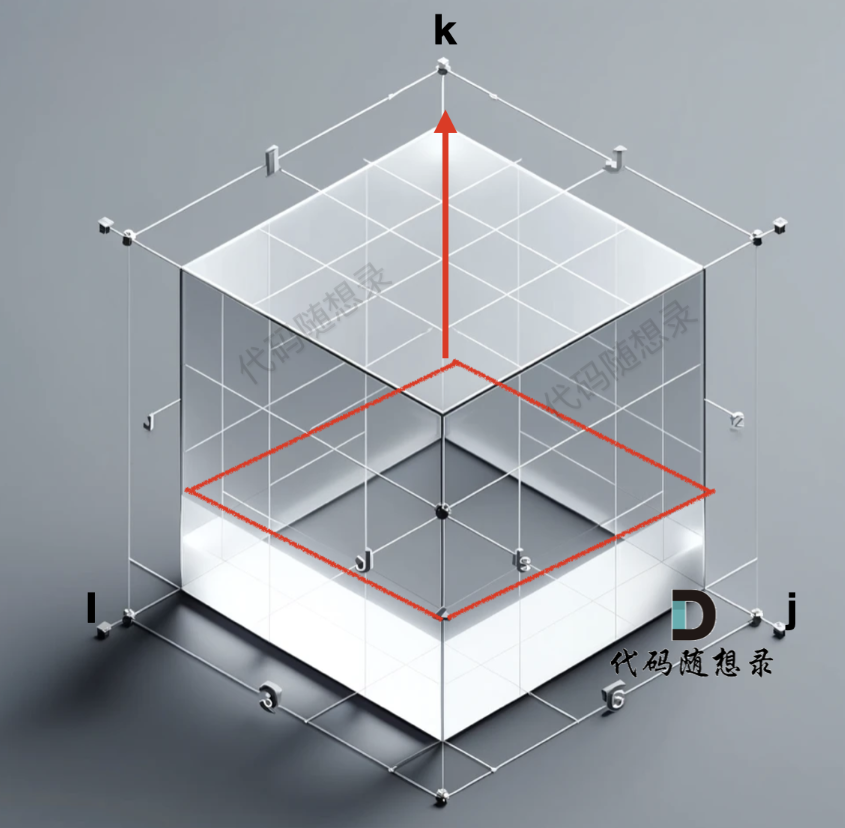
其他情況:[代碼隨想錄](https://www.programmercarl.com/ka其他情況:
5. 打印 dp 數組
#include <iostream>
#include <vector>
#include <list>using namespace std;int main() {int n, m, x, y, val;cin >> n >> m;// 構建dp數組 最大邊距離為nvector<vector<vector<int>>> grid(n+1, vector<vector<int>>(n+1, vector<int>(n+1, 10001)));// 初始化dp數組for (int i = 0; i < m; ++i) {cin >> x >> y >> val;grid[x][y][0] = val;grid[y][x][0] = val;}// foryd開始for (int k = 1; k <= n; ++k) {for (int i = 1; i <= n; ++i) {for (int j = 1; j <= n; j++) {// 遞推公式grid[i][j][k] = min(grid[i][j][k-1], grid[i][k][k-1] + grid[k][j][k-1]);}}}// 輸出結果int q, start, end;cin >> q;while (q--) {cin >> start >> end;if (grid[start][end][n] == 10001) cout << -1 << endl;else cout << grid[start][end][n] << endl;}
}// 空間優化版本
#include <iostream>
#include <vector>using namespace std;int main() {int n, m, x, y, val;cin >> n >> m;// 使用二維數組更新 dp數組定義表明x到y直接距離最近的路徑點vector<vector<int>> grid(n+1, vector<int>(n+1, 10001));// 初始化dp數組for (int i = 0; i < m; ++i) {cin >> x >> y >> val;grid[x][y] = val;grid[y][x] = val;}// forydfor (int k = 1; k <= n; ++k) {for (int i = 1; i <= n; ++i) {for (int j = 1; j<= n; ++j) {// 遞推公式grid[i][j] = min(grid[i][j], grid[i][k] + grid[k][j]);}}}int q, start, end;cin >> q;while (q--) {cin >> start >> end;if (grid[start][end] == 10001) cout << -1 << endl;else cout << grid[start][end] << endl;}
}#include <iostream>
#include <vector>using namespace std;int main() {int n, m, x, y, val;cin >> n >> m;// 使用二維數組更新 dp數組定義表明x到y直接距離最近的路徑點vector<vector<int>> grid(n+1, vector<int>(n+1, 10001));// 初始化dp數組for (int i = 0; i < m; ++i) {cin >> x >> y >> val;grid[x][y] = val;grid[y][x] = val;}// forydfor (int k = 1; k <= n; ++k) {for (int i = 1; i <= n; ++i) {for (int j = 1; j<= n; ++j) {// 遞推公式grid[i][j] = min(grid[i][j], grid[i][k] + grid[k][j]);}}}int q, start, end;cin >> q;while (q--) {cin >> start >> end;if (grid[start][end] == 10001) cout << -1 << endl;else cout << grid[start][end] << endl;}
}
感悟
將每個點作為中間點去更新
127. 騎士的攻擊
本題可以使用廣度優先搜索,每次有 8 種行動路徑,帶入廣度優先搜索,但是廣搜會超時
Astar 是一種 廣搜的改良版。 有的是 Astar是 dijkstra 的改良版。
其實只是場景不同而已 我們在搜索最短路的時候, 如果是無權圖(邊的權值都是1) 那就用廣搜,代碼簡潔,時間效率和 dijkstra 差不多 (具體要取決于圖的稠密)
如果是有權圖(邊有不同的權值),優先考慮 dijkstra。
而 Astar 關鍵在于啟發式函數,也就是影響廣搜或者 dijkstra 從容器(隊列)里取元素的優先順序。
以下,我用BFS版本的A * 來進行講解。
BFS中,我們想搜索,從起點到終點的最短路徑,要一層一層去遍歷 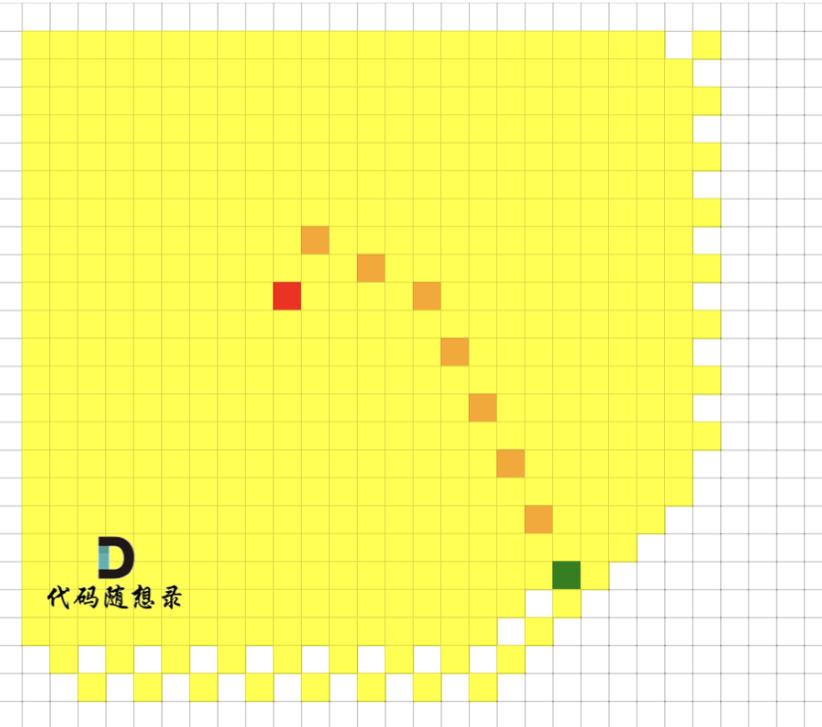
而使用 Astar 算法其搜索過程是這樣的,如圖,圖中著色的都是我們要遍歷的點
大家可以發現 **BFS 是沒有目的性的 一圈一圈去搜索, 而 A * 是有方向性的去搜索**。
看出 A * 可以節省很多沒有必要的遍歷步驟。 那么 A * 為什么可以有方向性的去搜索,它的如何知道方向呢?**其關鍵在于 啟發式函數**。
那么啟發式函數落實到代碼處,如果指引搜索的方向?
int m=q.front();q.pop();
int n=q.front();q.pop();
從隊列里取出什么元素,接下來就是從哪里開始搜索。所以 啟發式函數 要影響的就是隊列里元素的排序!
如何影響元素的選擇?
對隊列里節點進行排序,就需要給每一個節點權值,如何計算權值呢?
每個節點的權值為F,給出公式為:F = G + H
G:起點達到目前遍歷節點的距離
H:目前遍歷的節點到達終點的距離
起點達到目前遍歷節點的距離 + 目前遍歷的節點到達終點的距離 = 起點到達終點的距離。
本題的圖是無權網格狀,在計算兩點距離通常有如下三種計算方式:
1. 曼哈頓距離,計算方式:d = abs(x1-x2)+abs(y1-y2)
2. 歐氏距離(歐拉距離) ,計算方式:d = sqrt( (x1-x2)^2 + (y1-y2)^2 )
3. 切比雪夫距離,計算方式:d = max(abs(x1 - x2), abs(y1 - y2))
x1, x2 為起點坐標,y1, y2 為終點坐標,abs 為求絕對值,sqrt 為求開根號,
選擇哪一種距離計算方式也會導致 A * 算法的結果不同。
可以使用 優先級隊列 幫我們排好序,每次出隊列,就是F最小的節點。
實現代碼如下:(啟發式函數采用歐拉距離計算方式)
#include <iostream>
#include <vector>
#include <queue>
#include <cstring>using namespace std;// 棋盤網格大小
int moves[1001][1001];
// 可以走的方向
int dir[8][2] = {-1,2,-2,1,-2,-1,-1,-2,1,-2,2,-1,2,1,1,2};
int b1, b2;// F = G + H
// G = 從起點到該節點路徑消耗
// H = 該節點到終點的預估消耗struct Knight {int x,y;int g,h,f;bool operator< (const Knight& k) const {return k.f < f;}
};priority_queue<Knight> que;// 歐拉距離公式
int Eular(const Knight& k) {return (k.x - b1) * (k.x - b1) + (k.y - b2) * (k.y - b2);
}void Astar(const Knight& k) {Knight cur, next;que.push(k);while (!que.empty()) {cur = que.top();que.pop();if (cur.x == b1 && cur.y == b2) break;for (int i = 0; i < 8; ++i) {next.x = cur.x + dir[i][0];next.y = cur.y + dir[i][1];if (next.x < 1 || next.x > 1000 || next.y < 1 || next.y > 1000) continue;if (!moves[next.x][next.y]) {moves[next.x][next.y] = moves[cur.x][cur.y] + 1;// 計算F next.g = cur.g + 5; // 5 走日 1*1 + 2*2next.h = Eular(next);next.f = next.g + next.h;que.push(next);}}}
}int main() {int n, a1, a2;cin >> n;while (n--) {cin >> a1 >> a2 >> b1 >> b2;memset(moves, 0, sizeof(moves));Knight start;start.x = a1;start.y = a2;start.g = 0;start.h = Eular(start);start.f = start.g + start.h;Astar(start);while (!que.empty()) que.pop();cout << moves[b1][b2] << endl;}return 0;
}
Astar 缺點
大家看上述 A * 代碼的時候,可以看到我們想隊列里添加了很多節點,但真正從隊列里取出來的僅僅是靠啟發式函數判斷距離終點最近的節點。
相對了普通BFS,A * 算法只從隊列里取出距離終點最近的節點。那么問題來了,A * 在一次路徑搜索中,大量不需要訪問的節點都在隊列里,會造成空間的過度消耗。
IDA * 算法對這一空間增長問題進行了優化,關于 IDA * 算法,本篇不再做講解,感興趣的錄友可以自行找資料學習。
另外還有一種場景是 A * 解決不了的。
如果題目中,給出多個可能的目標,然后在這多個目標中選擇最近的目標,這種 A * 就不擅長了, A * 只擅長給出明確的目標然后找到最短路徑。
如果是多個目標找最近目標(特別是潛在目標數量很多的時候),可以考慮 Dijkstra ,BFS 或者 Floyd。
圖論總結
深度優先搜索廣度優先搜索
在二叉樹章節中,其實我們講過了 深搜和廣搜在二叉樹上的搜索過程。
在圖論章節中,深搜與廣搜就是在圖這個數據結構上的搜索過程。
深搜與廣搜是圖論里基本的搜索方法,大家需要掌握三點:
- 搜索方式:深搜是可一個方向搜,不到黃河不回頭。 廣搜是圍繞這起點一圈一圈的去搜。
- 代碼模板:需要熟練掌握深搜和廣搜的基本寫法。
- 應用場景:圖論題目基本上可以即用深搜也可用廣搜,無疑是用哪個方便而已
并查集
并查集相對來說是比較復雜的數據結構,其實他的代碼不長,但想徹底學透并查集,需要從多個維度入手,我在理論基礎篇的時候 講解如下重點:
- 為什么要用并查集,怎么不用個二維數據,或者set、map之類的。
- 并查集能解決那些問題,哪些場景會用到并查集
- 并查集原理以及代碼實現
- 并查集寫法的常見誤區
- 帶大家去模擬一遍并查集的過程
- 路徑壓縮的過程
- 時間復雜度分析
上面這幾個維度 大家都去思考了,并查集基本就學明白了。
其實理論基礎篇就算是給大家出了一道裸的并查集題目了,所以在后面的題目安排中,會稍稍的拔高一些,重點在于并查集的應用上。
例如 并查集可以判斷這個圖是否是樹,因為樹的話,只有一個根,符合并查集判斷集合的邏輯,題目:0108.冗余連接。
在 0109.冗余連接II 中對有向樹的判斷難度更大一些,需要考慮的情況比較多。
最小生成樹
最小生成樹是所有節點的最小連通子圖, 即:以最小的成本(邊的權值)將圖中所有節點鏈接到一起。
最小生成樹算法,有prim 和 kruskal。
prim 算法是維護節點的集合,而 Kruskal 是維護邊的集合。
在 稀疏圖中,用Kruskal更優。 在稠密圖中,用prim算法更優。
邊數量較少為稀疏圖,接近或等于完全圖(所有節點皆相連)為稠密圖
Prim 算法 時間復雜度為 O(n^2),其中 n 為節點數量,它的運行效率和圖中邊樹無關,適用稠密圖。
Kruskal算法 時間復雜度 為 O(nlogn),其中n 為邊的數量,適用稀疏圖。
關于 prim算法,我自創了三部曲,來幫助大家理解
- 第一步,選距離生成樹最近節點
- 第二步,最近節點加入生成樹
- 第三步,更新非生成樹節點到生成樹的距離(即更新minDist數組)
大家只要理解這三部曲, prim算法 至少是可以寫出一個框架出來,然后在慢慢補充細節,這樣不至于 自己在寫prim的時候 兩眼一抹黑 完全憑感覺去寫。
minDist數組 是prim算法的靈魂,它幫助 prim算法完成最重要的一步,就是如何找到 距離最小生成樹最近的點。
kruscal的主要思路:
- 邊的權值排序,因為要優先選最小的邊加入到生成樹里
- 遍歷排序后的邊
- 如果邊首尾的兩個節點在同一個集合,說明如果連上這條邊圖中會出現環
- 如果邊首尾的兩個節點不在同一個集合,加入到最小生成樹,并把兩個節點加入同一個集合
而判斷節點是否在一個集合 以及將兩個節點放入同一個集合,正是并查集的擅長所在。
所以 Kruskal 是需要用到并查集的。
拓撲排序
拓撲排序 是在圖上的一種排序。
概括來說,給出一個 有向圖,把這個有向圖轉成線性的排序 就叫拓撲排序。
同樣,拓撲排序也可以檢測這個有向圖 是否有環,即存在循環依賴的情況。
拓撲排序的一些應用場景,例如:大學排課,文件下載依賴 等等。
只要記住如下兩步拓撲排序的過程,代碼就容易寫了:
- 找到入度為0 的節點,加入結果集
- 將該節點從圖中移除
最短路徑總結
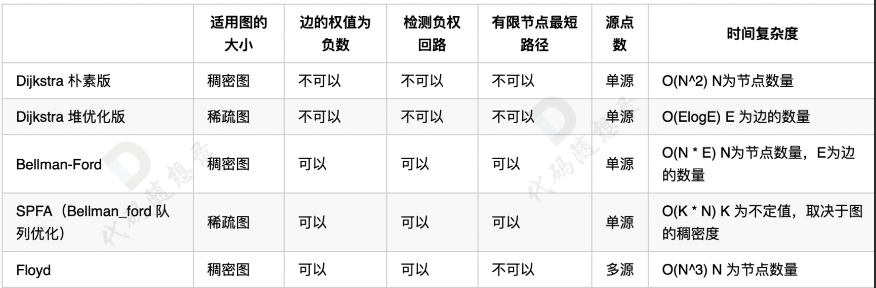
至此已經講解了四大最短路算法,分別是 Dijkstra、Bellman_ford、SPFA 和 Floyd。
針對這四大最短路算法,我用了七篇長文才徹底講清楚,分別是:
- Dijkstra 樸素版
- Dijkstra 堆優化版
- Bellman_ford
- Bellman_ford 隊列優化算法(又名 SPFA)
- Bellman_ford 算法判斷負權回路
- Bellman_ford 之單源有限最短路
- Floyd 算法精講
- 啟發式搜索:A * 算法
這里我給大家一個大體使用場景的分析:
如果遇到單源且邊為正數,直接 Dijkstra。
至于 使用樸素版還是堆優化版還是取決于圖的稠密度,多少節點多少邊算是稠密圖,多少算是稀疏圖,這個沒有量化,如果想量化只能寫出兩個版本然后做實驗去測試,不同的判題機得出的結果還不太一樣。
一般情況下,可以直接用堆優化版本。
如果遇到單源邊可為負數,直接 Bellman-Ford,同樣 SPFA 還是 Bellman-Ford 取決于圖的稠密度。
一般情況下,直接用 SPFA。
如果有負權回路,優先 Bellman-Ford,如果是有限節點最短路也優先 Bellman-Ford,理由是寫代碼比較方便。如果是遇到多源點求最短路,直接 Floyd。
除非源點特別少,且邊都是正數,那可以多次 Dijkstra 求出最短路徑,但這種情況很少,一般出現多個源點了,就是想讓你用 Floyd 了。
對于 A * ,由于其高效性,所以在實際工程應用中使用最為廣泛,由于其結果的不唯一性,也就是可能是次短路的特性,一般不適合作為算法題。
游戲開發、地圖導航、數據包路由等都廣泛使用 A * 算法。



)
![[免費]微信小程序網上花店系統(SpringBoot后端+Vue管理端)【論文+源碼+SQL腳本】](http://pic.xiahunao.cn/[免費]微信小程序網上花店系統(SpringBoot后端+Vue管理端)【論文+源碼+SQL腳本】)






)

—引言)



(訓練自己數據集)(Pycharm保姆級安裝教程)(lablme的使用)(GPU版))

