目錄
1.Pycharm的安裝和虛擬環境調用(已經安裝好的可以跳過此步驟)
1.1 下載pycharm軟件
?1.2 調用已創建虛擬環境(調用上一篇教程中創建好的虛擬環境)
2.標注自己數據集(已有數據集的這部分可跳過)
2.1配置標注軟件labelme
?2.2 標注自己數據集
2.3 制作自己數據集
3. 用YOLOv8訓練自己數據集
3.1 部署YOLOv8代碼
3.2 訓練自己數據集
3.3 推理數據集
4. 總結
?
文章主要詳細介紹如何標注自己數據集,然后從0開始利用YOLOv8訓練自己數據集,推理數據集等,本文的相關torch環境主要基于上一篇文章,如果還沒配置torch環境的可以閱讀上篇文章配置,希望大家多多點贊關注支持,后期還會繼續更新更多相關代碼復現和模塊替換等內容!!!
上一篇:從零配置torch深度學習環境詳細教程
1.Pycharm的安裝和虛擬環境調用(已經安裝好的可以跳過此步驟)
1.1 下載pycharm軟件
大家直接進入pycharm官網下載:Pycharm官網下載
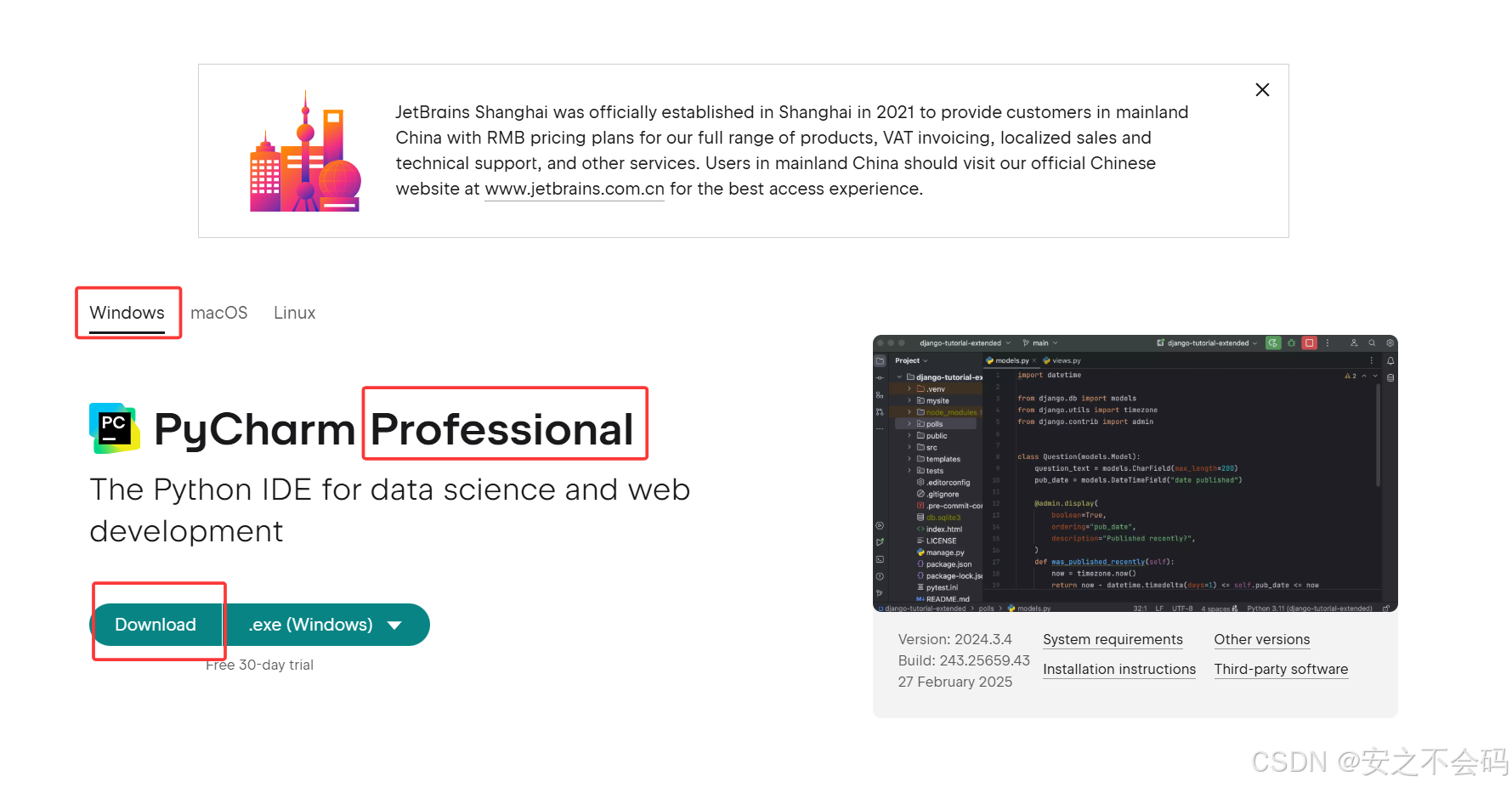
大家進入官網后記得選擇和自己相關系統的版本,然后我這邊用的是專業版(Professional),專業版前30天是免費的,后續要收費(如果大家是在讀學生的話可以申請自己學校的教育郵箱,然后教育郵箱可以免費使用Pycharm專業版),不過社區版也是可以的
壓縮包下載好之后,大家下載好之后直接雙擊運行安裝程序即可
下一步
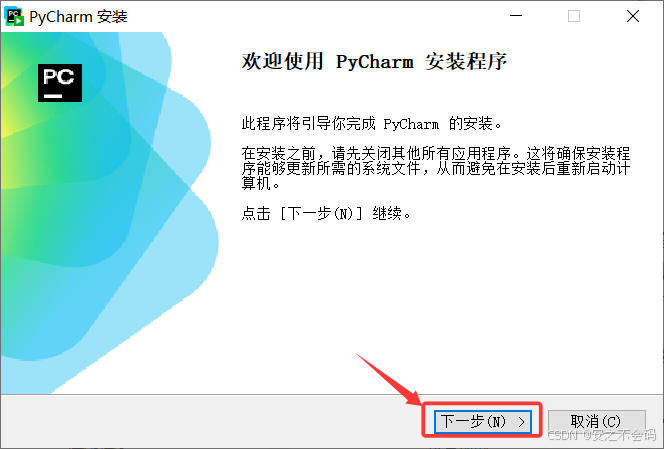
設置好自己的安裝路徑,然后點擊下一步
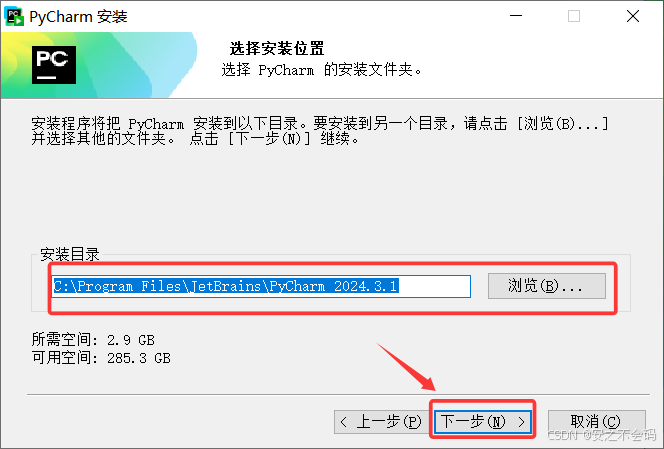
在這一步的時候,我推薦是把這幾個都選中,特別是添加將文件夾打開為項目,本人覺得還是很好用的,都選擇完畢后點擊下一步
然后繼續點擊下一步
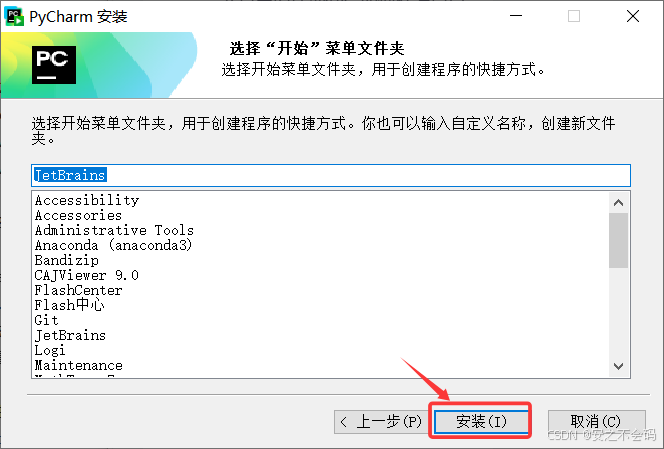
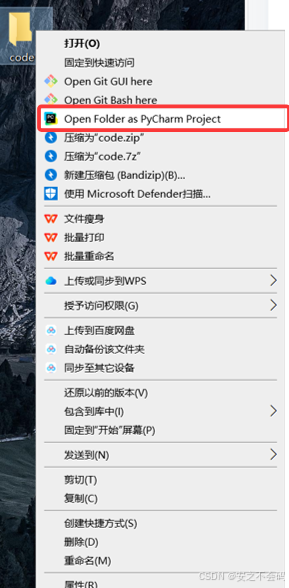
點擊安裝,最后成功安裝就可以了,安裝完成后桌面上就會有pycharm界面了,大家可以先創建一個文件夾(文件夾名稱不要帶中文),然后將該文件夾在pychram打開
打開后就是以下頁面
?1.2 調用已創建虛擬環境(調用上一篇教程中創建好的虛擬環境)
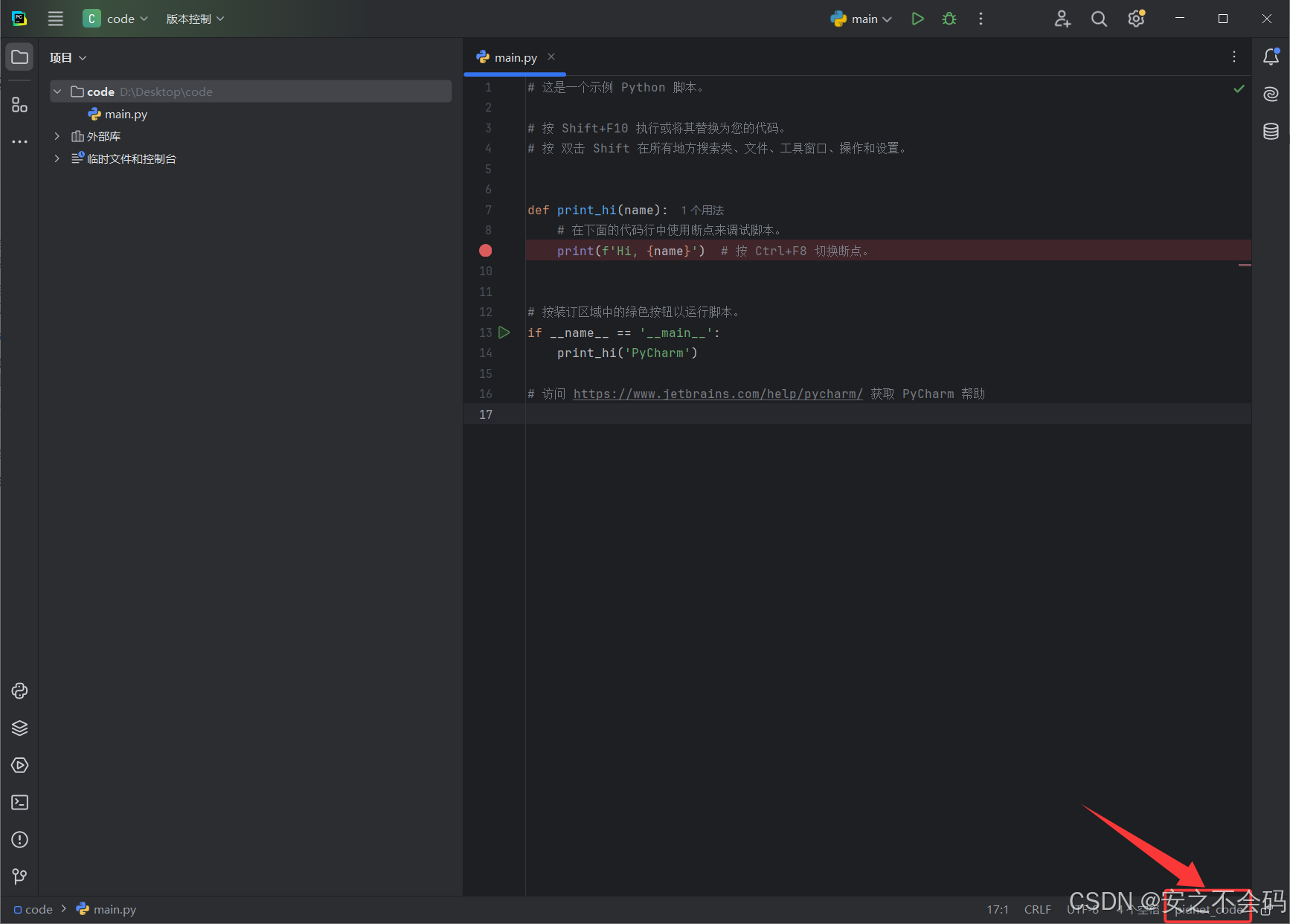
首先,點擊右下角的這個環境配置器部分,由于我之前配置過環境,所以顯示的是我的環境名稱(pidenet_code)大家不用在意,打開自己的就可以
?點擊之后,依次打開添加本地解釋器
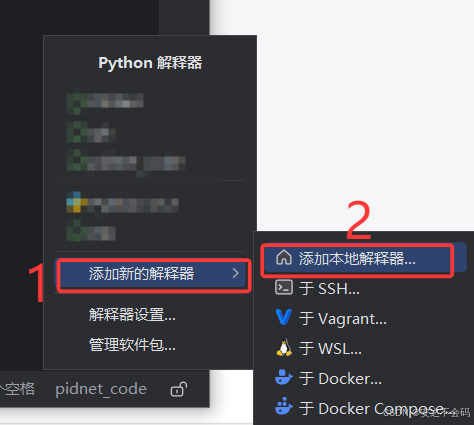
?大家打開之后,依次進行選擇現有,conda,然后環境的下拉鍵,就可以顯示出自己所建的虛擬環境,大家選擇自己在上一篇教程中建立的虛擬環境,然后點擊確定就可以進入所建環境了
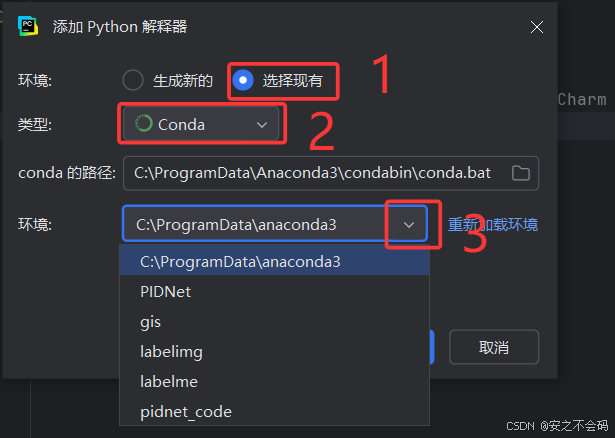
選擇確認之后,右下角出現自己所選擇環境名稱后,則表示成功進入虛擬環境(我的虛擬環境名稱是torch)?
2.標注自己數據集(已有數據集的這部分可跳過)
2.1配置標注軟件labelme
打開anaconda的終端,依次輸入以下指令,即可創建一個名為labelme的標注環境
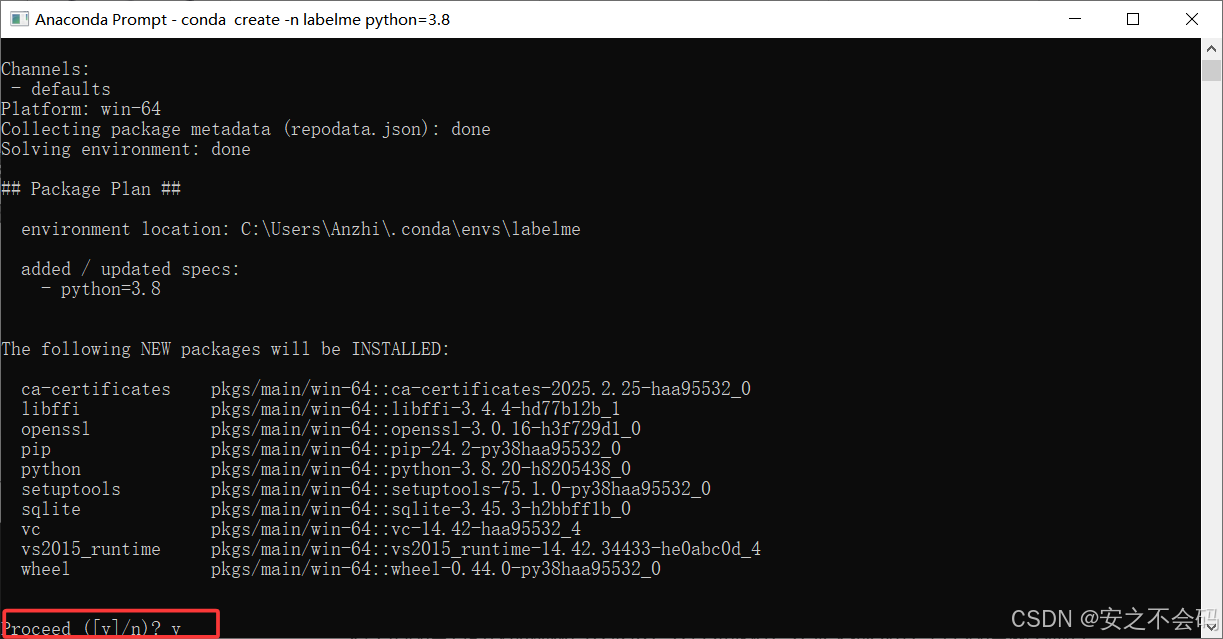
conda create -n labelme python=3.9然后輸入y ,回車
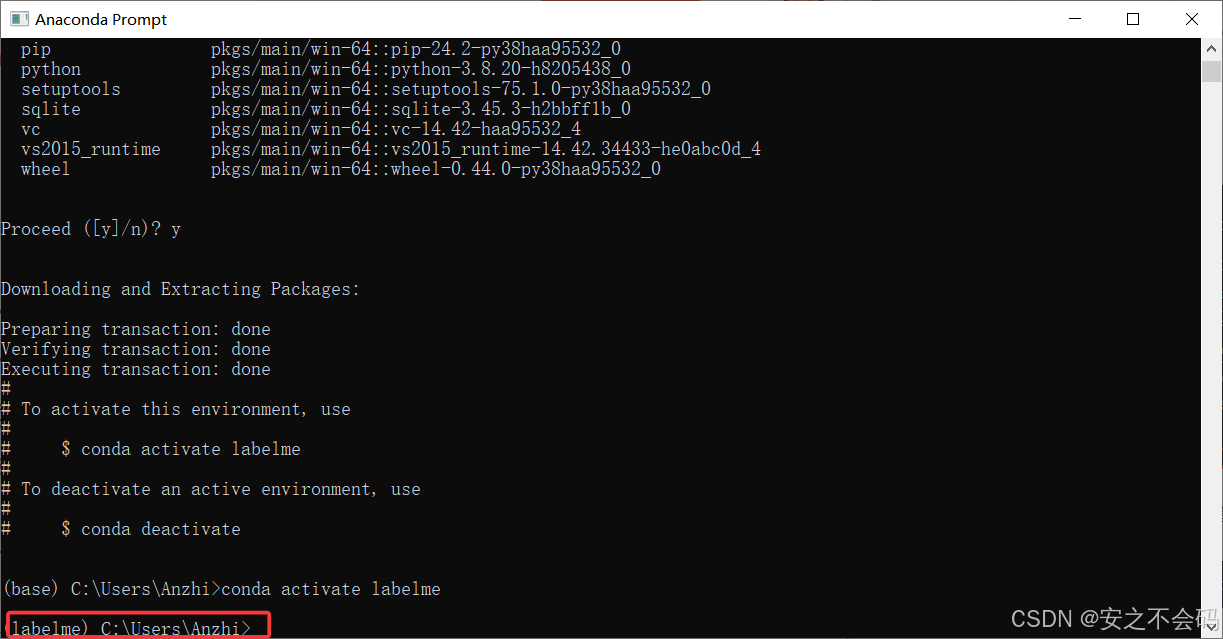
?緊接著輸入以下指令激活環境
conda activate labelme?輸出下面這樣則表述環境創建并激活成功
然后執行以下指令,安裝標注軟件
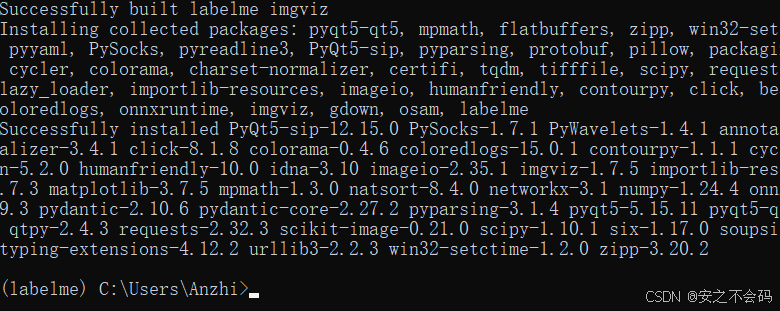
pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple這個的配置有時候加鏡像也會很慢,會容易報錯,大家多試幾次,直到配置成功就行
出現以下界面就表示配置成功
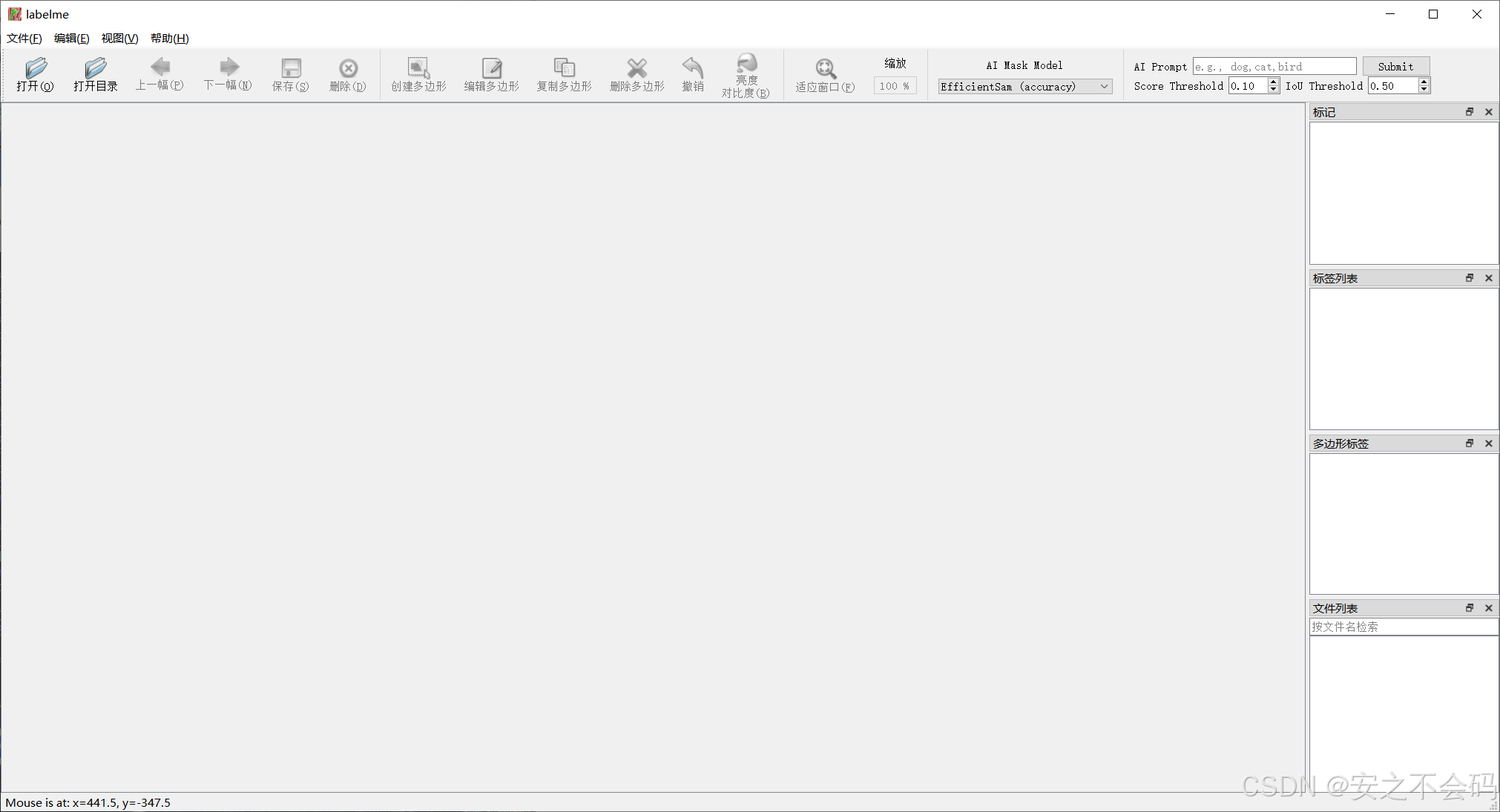
?然后就在當前界面輸入以下指令,然后自動跳轉至標注界面
labelme出現這個界面表明已經打開了標注軟件
?2.2 標注自己數據集
緊接著我們開始標注自己的數據集,首先我們點擊打開目錄,然后將自己存放圖片的文件夾打開(最好是路徑和文件夾都不要帶中文),具體操作步驟如下
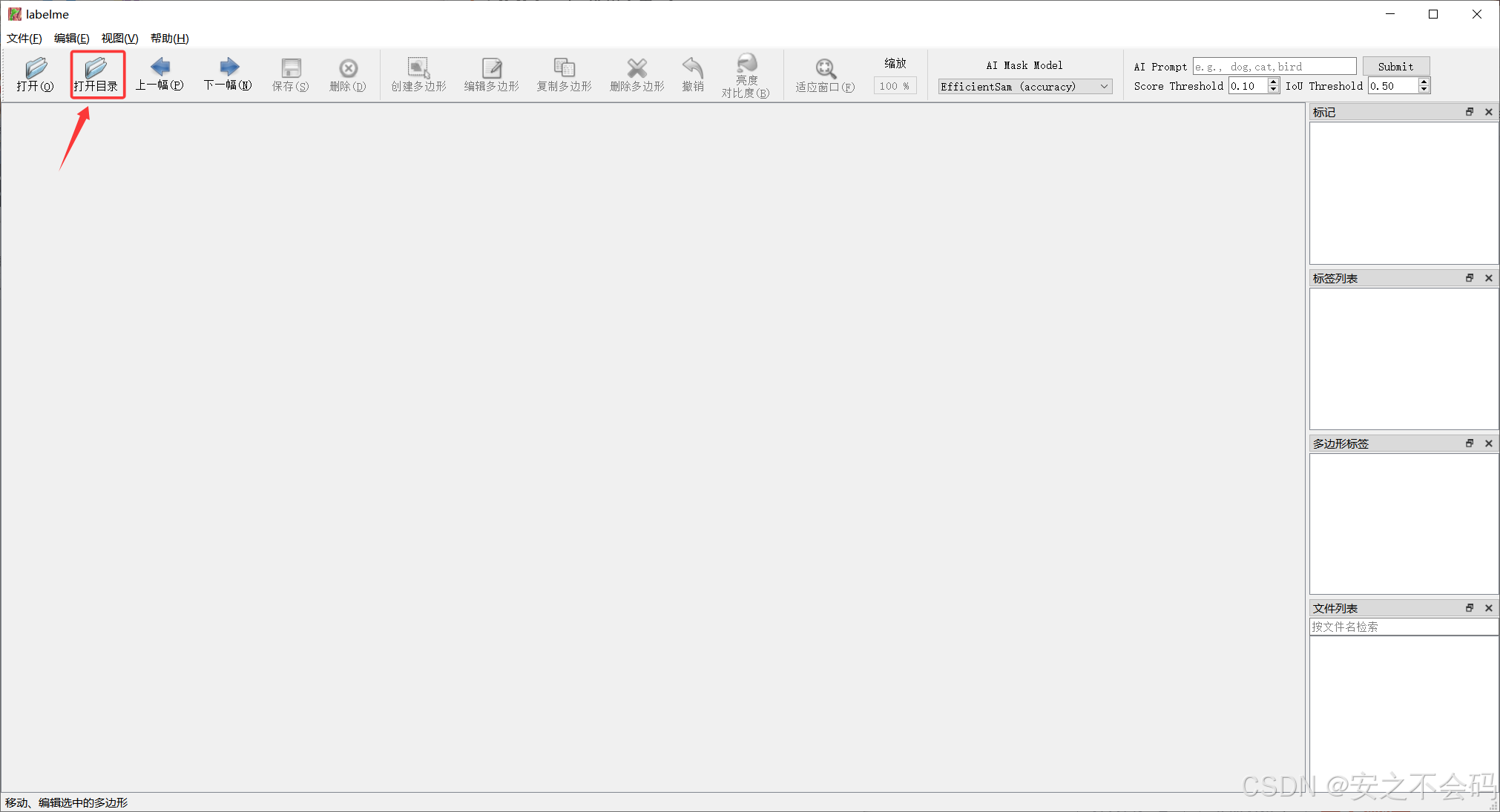
選擇好自己的圖片所在文件夾路徑之后點擊下面的選擇文件夾即可?
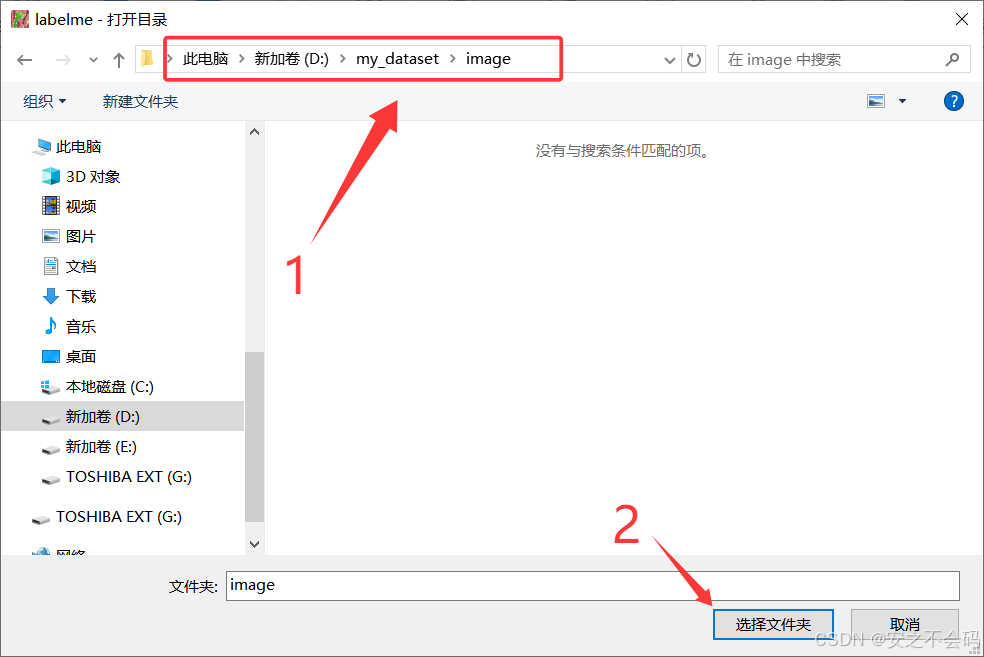
?點擊之后文件夾內圖片就會導入labelme標注軟件,然后右下方會顯示已導入圖片(ps:我的圖片是voc數據集里面隨便找的兩張,用作示例)
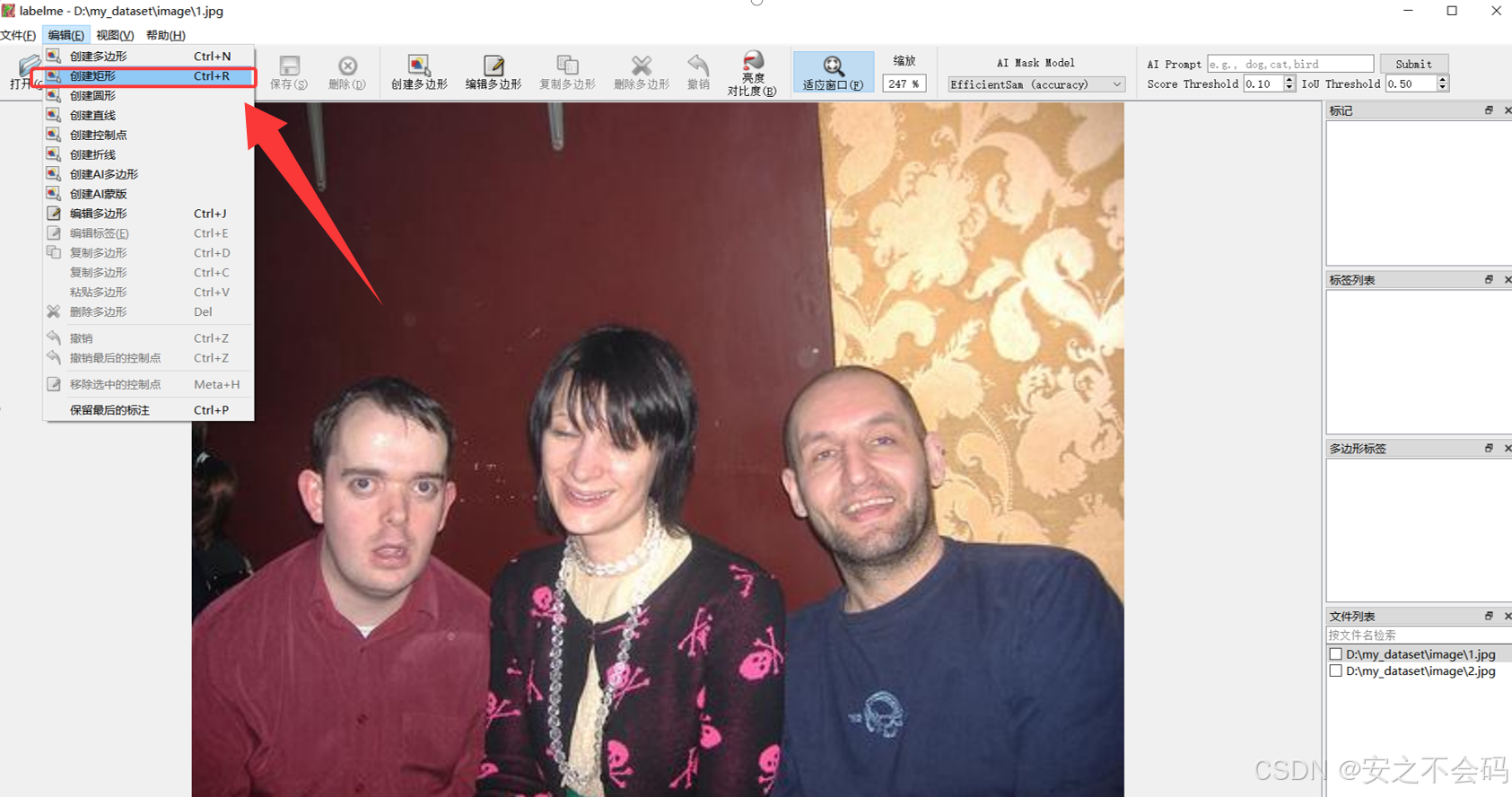
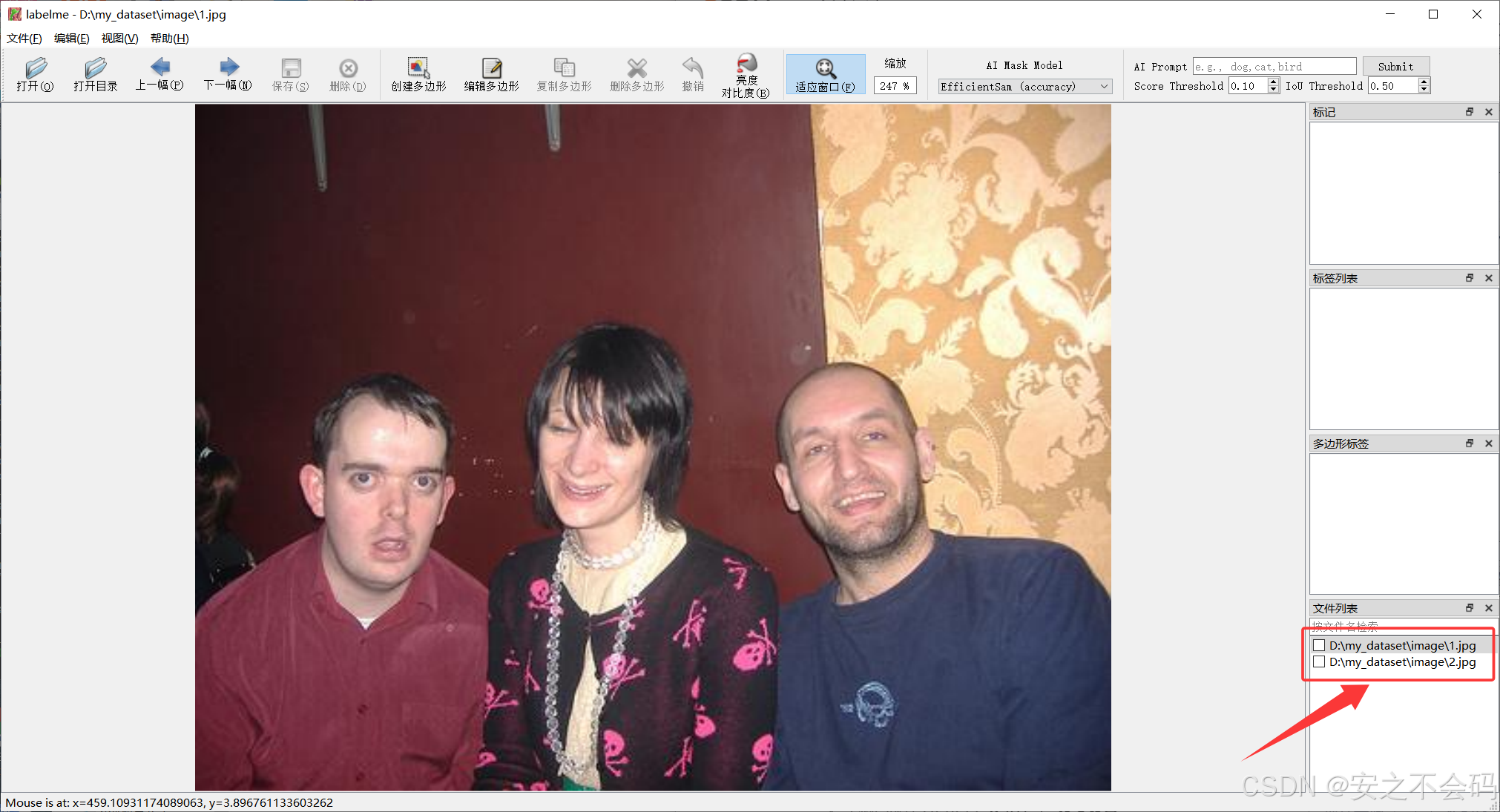 接下來大家可以點擊上方的編輯,選擇創建矩形,然后大家就可以利用這個矩形框對相應目標進行框選標注
接下來大家可以點擊上方的編輯,選擇創建矩形,然后大家就可以利用這個矩形框對相應目標進行框選標注
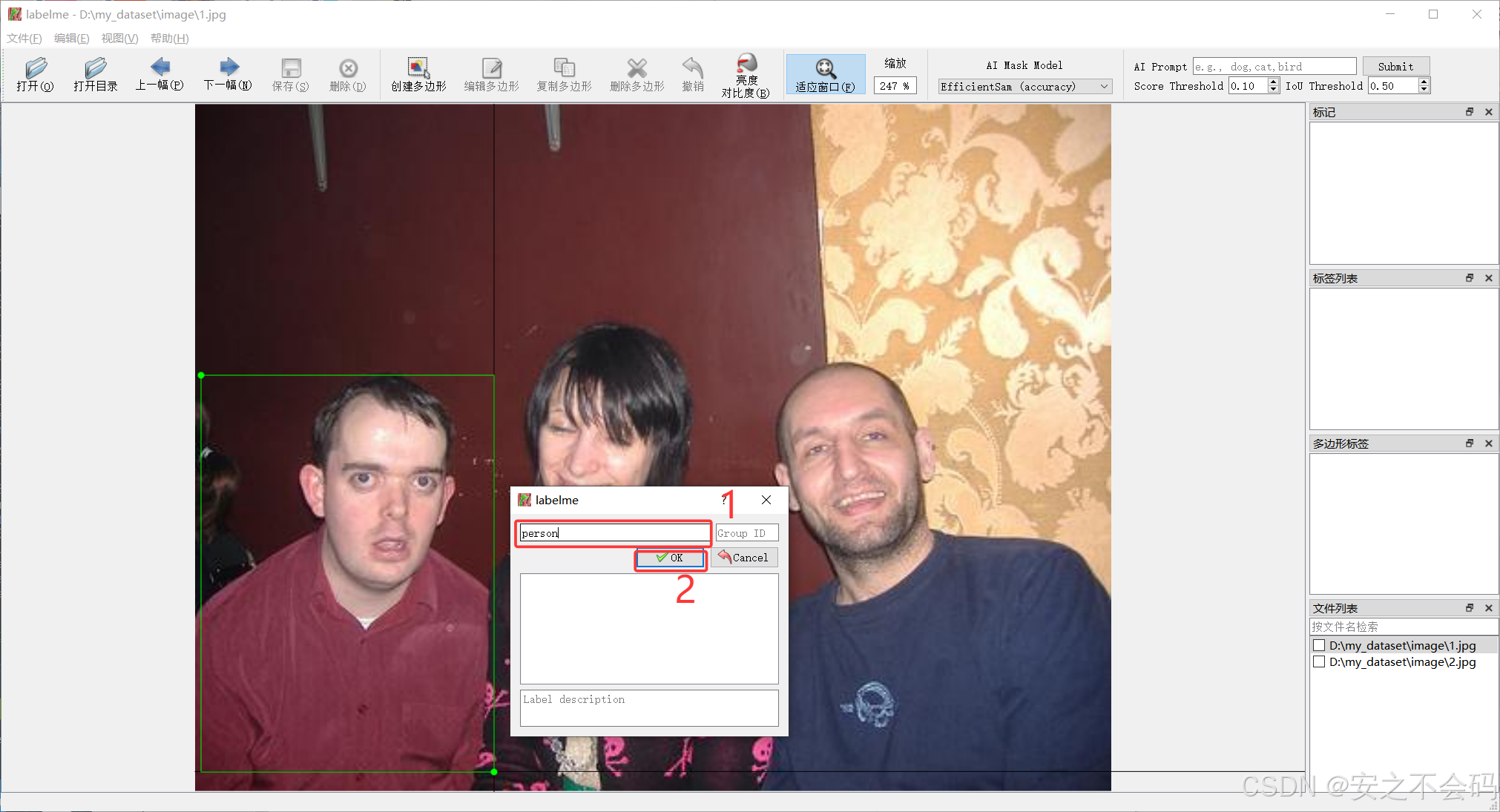
?大家框選完自己想標注的目標之后,就可以給目標定義一個名稱,然后點擊ok即可保存,下面是我標注了人(person)這個目標的示例
?下面是我標注的所有目標,然后右邊會顯示標注的數量和目標名稱,大家標注不同目標的話,只需定義不同目標名稱即可
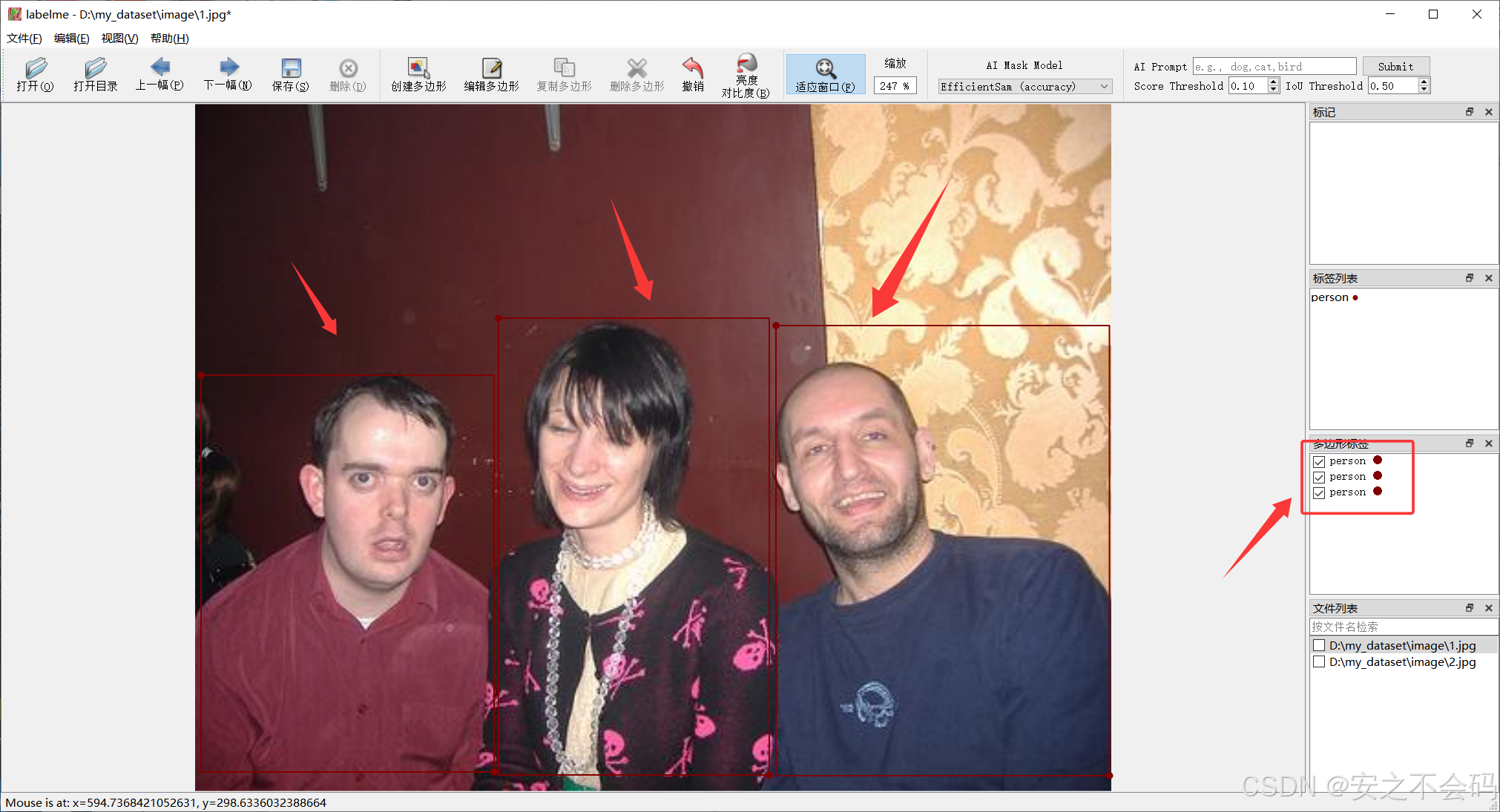
大家標注完之后點擊下一張后會出現保存提示界面,一般會把標注的信息默認存在圖片所在文件夾,大家也可以自定義保存路徑
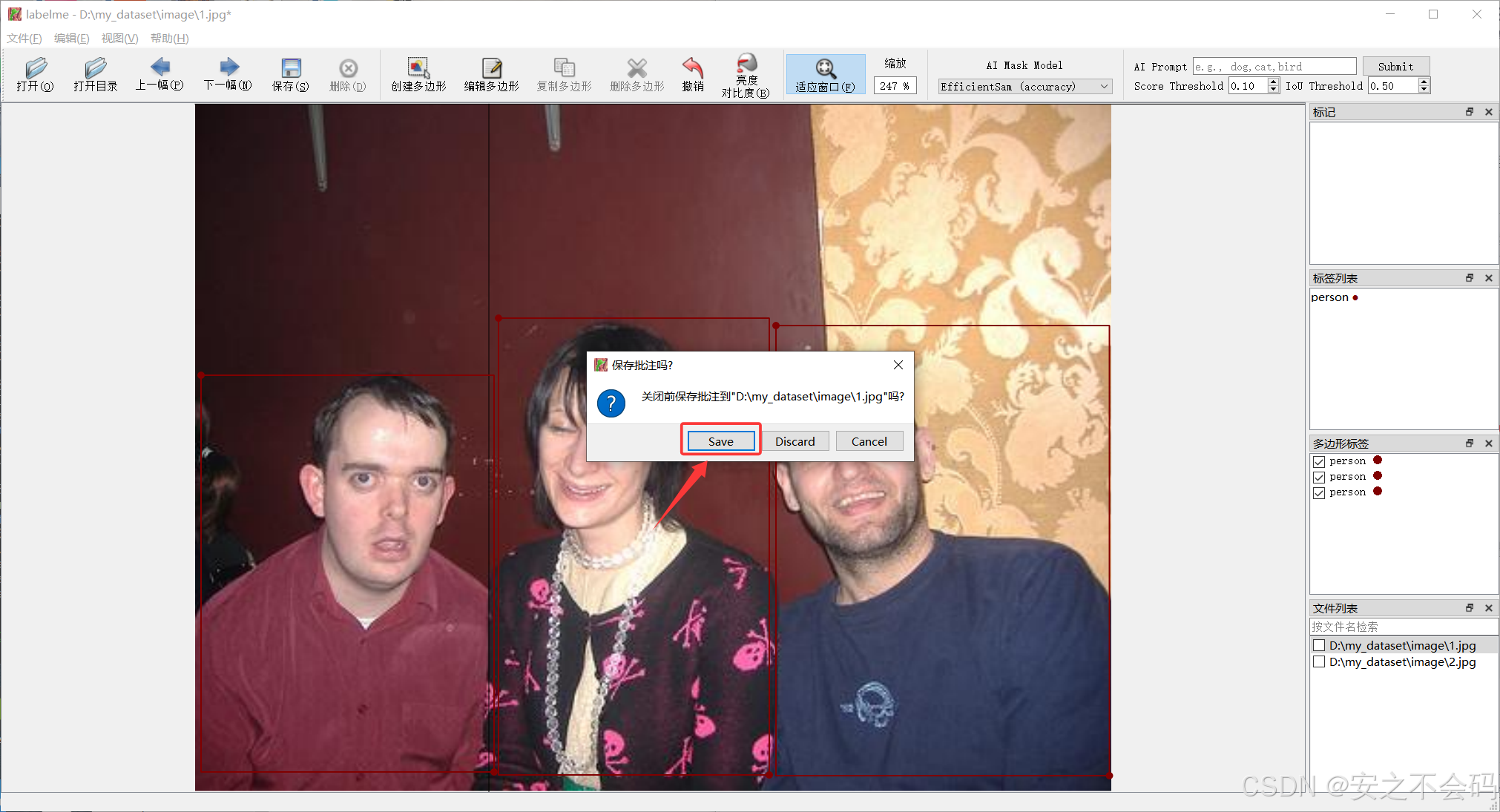
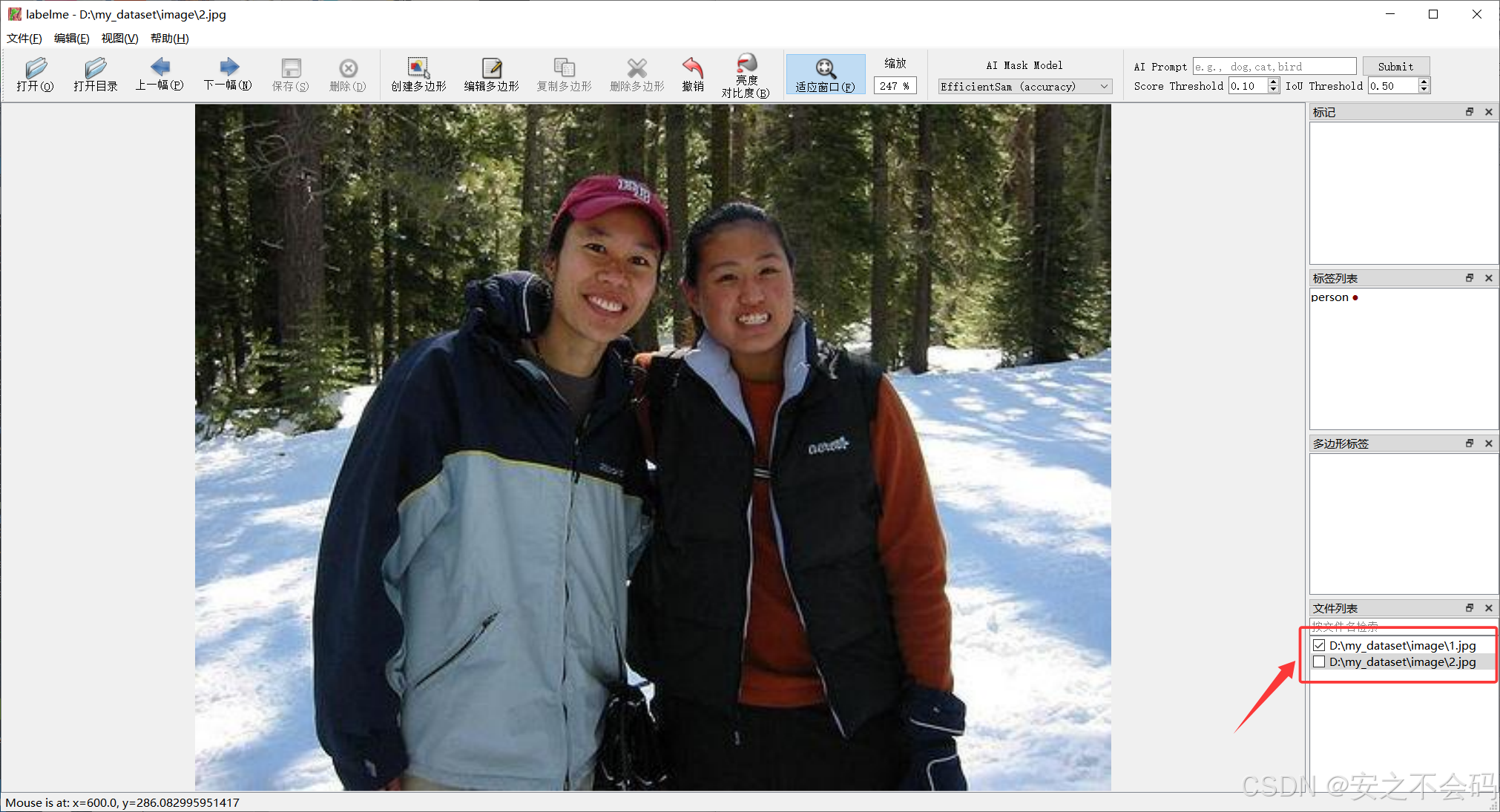
?點擊下一張后會在右下角顯示是否已經標注且保存,已保存會有對號,大家可以檢查一下,然后第二張的標注和第一張同理,后面的都按照這個方法標注保存即可
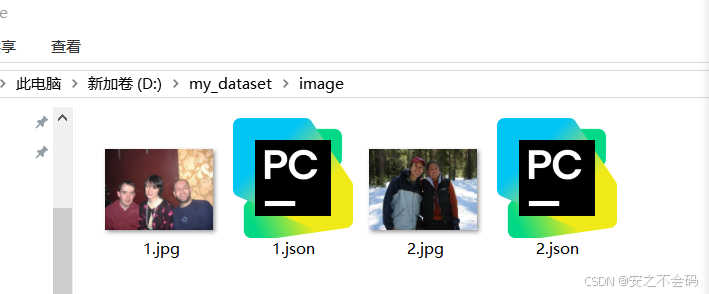
將自己數據集全部標注完成之后,會得到以下的內容,分別是圖片和與其名稱對應的.json標注文件
然后我們需要利用一個轉換腳本代碼,將這個.json文件轉換為yolo格式的.txt文件
首先,我們在第一步的文件夾內右鍵點擊建立一個新的.py格式文件
?自定義好,py文件的名稱后回車就可以新建一個名為json_to_txt的py文件
?將以下轉換代碼粘貼到該文件
import json
import os
from tqdm import tqdmdef convert_label(json_dir, save_dir, classes):json_paths = os.listdir(json_dir)classes = classes.split(',')for json_path in tqdm(json_paths):path = os.path.join(json_dir, json_path)with open(path, 'r') as load_f:json_dict = json.load(load_f)h, w = json_dict['imageHeight'], json_dict['imageWidth']# save txt pathtxt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))txt_file = open(txt_path, 'w')for shape_dict in json_dict['shapes']:label = shape_dict['label']label_index = classes.index(label)points = shape_dict['points']points_nor_list = []for point in points:points_nor_list.append(point[0] / w)points_nor_list.append(point[1] / h)points_nor_list = list(map(lambda x: str(x), points_nor_list))points_nor_str = ' '.join(points_nor_list)label_str = str(label_index) + ' ' + points_nor_str + '\n'txt_file.writelines(label_str)if __name__ == "__main__":json_dir = r'D:\my_dataset\json' ####將路徑替換為你的json文件夾路徑save_dir = r'D:\my_dataset\txt' ####將路徑替換為你的txt文件夾保存路徑classes = 'person' ####這里將自己標注的類別名稱填進去,如果有還有其他標注目標,就在person后面加個,然后跟上就行#classes = 'person,others,others2,...' ####多個目標示例convert_label(json_dir, save_dir, classes)然后將最下面的路徑根據我的提示進行修改,并且將classes改為自己標注目標的名稱即可(ps:json文件夾中只能有.json文件),運行代碼后就會在保存路徑中生成.txt文件

如果大家在運行時發生了以下報錯
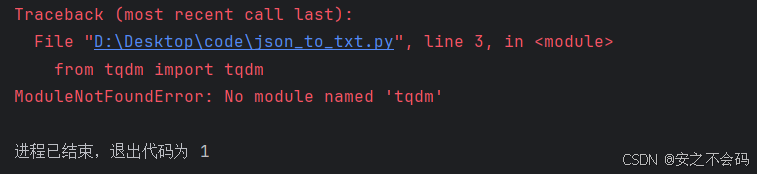
那么大家就在anaconda中打開自己的環境,或者打開終端界面,如下所示
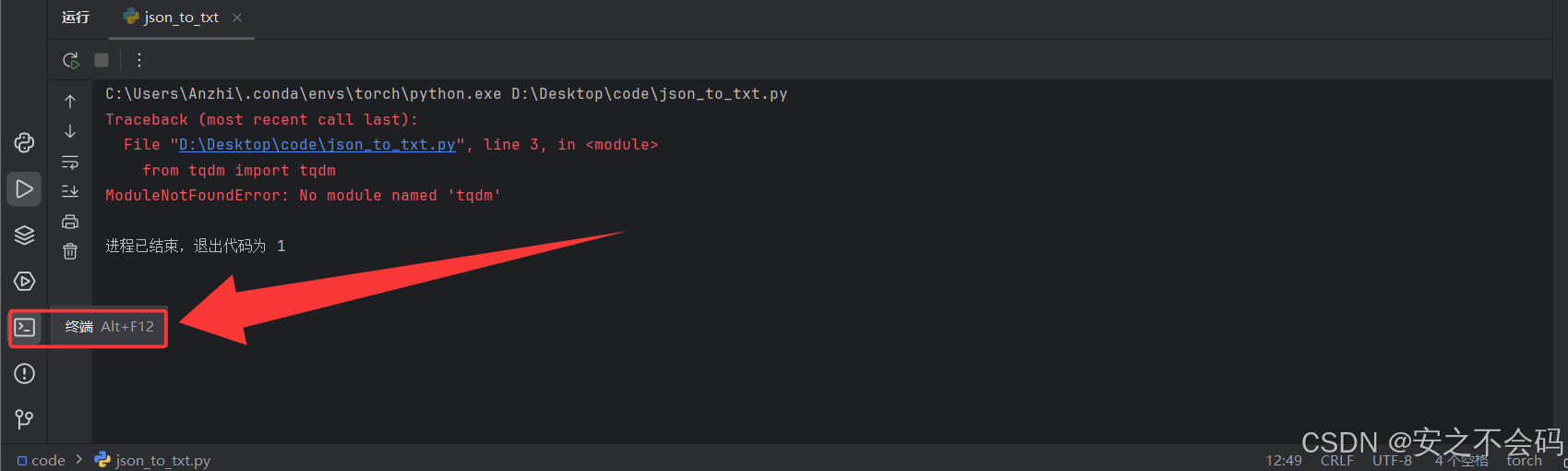
?其中()內的就是當前環境名稱,大家確認好是自己的虛擬環境名稱
?然后輸入以下指令回車后,就可以安裝缺失的tqdm包
pip install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple出現以下界面即表示安裝成功?

然后就可以直接運行上面那個代碼了,會最終得到自己的txt文件
2.3 制作自己數據集
大家把自己的圖片數據和txt數據分別放在兩個不同文件夾內進行歸類,然后再新建一個py代碼,復制粘貼下面這些代碼后,在最下面根據我的提示更改路徑,然后運行(這個代碼的主要功能是對訓練集,驗證集和測試集按照比例進行隨機劃分)
import shutil
import random
import os# 檢查文件夾是否存在
def mkdir(path):if not os.path.exists(path):os.makedirs(path)def split(image_dir, txt_dir, save_dir):# 創建一級目錄train_dir = os.path.join(save_dir, 'train')val_dir = os.path.join(save_dir, 'valid')test_dir = os.path.join(save_dir, 'test')# 創建二級目錄train_images_dir = os.path.join(train_dir, 'images')train_labels_dir = os.path.join(train_dir, 'labels')val_images_dir = os.path.join(val_dir, 'images')val_labels_dir = os.path.join(val_dir, 'labels')test_images_dir = os.path.join(test_dir, 'images')test_labels_dir = os.path.join(test_dir, 'labels')# 創建所有需要的文件夾mkdir(train_dir)mkdir(val_dir)mkdir(test_dir)mkdir(train_images_dir)mkdir(train_labels_dir)mkdir(val_images_dir)mkdir(val_labels_dir)mkdir(test_images_dir)mkdir(test_labels_dir)# 數據集劃分比例,訓練集75%,驗證集15%,測試集10%,按需修改train_percent = 0.75val_percent = 0.15test_percent = 0.10total_txt = os.listdir(txt_dir)num_txt = len(total_txt)list_all_txt = range(num_txt) # 范圍 range(0, num)num_train = int(num_txt * train_percent)num_val = int(num_txt * val_percent)num_test = num_txt - num_train - num_valtrain = random.sample(list_all_txt, num_train)# 在全部數據集中取出trainval_test = [i for i in list_all_txt if not i in train]# 再從val_test取出num_val個元素,val_test剩下的元素就是testval = random.sample(val_test, num_val)print("訓練集數目:{}, 驗證集數目:{},測試集數目:{}".format(len(train), len(val), len(val_test) - len(val)))for i in list_all_txt:name = total_txt[i][:-4]srcImage = os.path.join(image_dir, name + '.jpg')srcLabel = os.path.join(txt_dir, name + '.txt')if i in train:dst_train_Image = os.path.join(train_images_dir, name + '.jpg')dst_train_Label = os.path.join(train_labels_dir, name + '.txt')shutil.copyfile(srcImage, dst_train_Image)shutil.copyfile(srcLabel, dst_train_Label)elif i in val:dst_val_Image = os.path.join(val_images_dir, name + '.jpg')dst_val_Label = os.path.join(val_labels_dir, name + '.txt')shutil.copyfile(srcImage, dst_val_Image)shutil.copyfile(srcLabel, dst_val_Label)else:dst_test_Image = os.path.join(test_images_dir, name + '.jpg')dst_test_Label = os.path.join(test_labels_dir, name + '.txt')shutil.copyfile(srcImage, dst_test_Image)shutil.copyfile(srcLabel, dst_test_Label)if __name__ == '__main__':image_dir = r'D:\my_dataset\image' ####圖片文件夾路徑txt_dir = r'D:\my_dataset\txt' ####txt文件夾路徑save_dir = r'D:\my_dataset\dataset' ####劃分后的保存路徑split(image_dir, txt_dir, save_dir)運行代碼后,會按照規定文件夾格式對圖片和標簽進行存放,格式如下
dataset/
├── train/
│ ├── images/
│ └── labels/
├── valid/
│ ├── images/
│ └── labels/
└── test/├── images/└── labels/3. 用YOLOv8訓練自己數據集
3.1 部署YOLOv8代碼
大家可以去YOLOv8的官網去下載代碼包(盡量利用我的鏈接下載,我在鏈接中已經選好版本了,最新版本也可以用,但是有可能會因為python版本報錯)
yolov8官方下載鏈接
大家打不開官網的也可以用百度網盤鏈接下載
yolov8網盤下載鏈接? ? ?提取碼:x8yj
進入鏈接后,依次點擊code和下載安裝包進行下載
下載好之后解壓,然后將解壓文件在pycharm中打開,打開后是這樣
打開后繼續新建一個訓練的.py文件腳本,以后大家就可以利用這個腳本去訓練
from ultralytics import YOLO# Load a model
model = YOLO('yolov8n.yaml') # build a new model from YAML# 斷點續訓
#Load a model
#model =#YOLO(r'E:\anzhi\car\3\ultralytics-8.2.82\runs\detect\train27\weights\last.pt') # load a partially trained modelif __name__ == '__main__':#results = model.train(data=r'E:\anzhi\car\ultralytics\my.yaml', batch=80, epochs=10000, imgsz=640, resume=True,#workers=8, device=0)results = model.train(data=r'E:\anzhi\car\3\ultralytics-8.2.82\train.yaml',batch=40,close_mosaic=0,epochs=1000,imgsz=640,resume=True,workers=8,device=1)然后大家將右下角的環境切換到之前配置的有torch包的環境
打開項目的終端,在終端輸入以下命令配置yolov8所需包(一定要確定是在該環境內)
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple 這個里面需要配置的包有點多,大家一定要確定完全配置好了再進行下一步,出現以下界面表示配置成功
這個里面需要配置的包有點多,大家一定要確定完全配置好了再進行下一步,出現以下界面表示配置成功

3.2 訓練自己數據集
大家依次點擊ultralytics---cfg--datasets--voc.yaml,
?
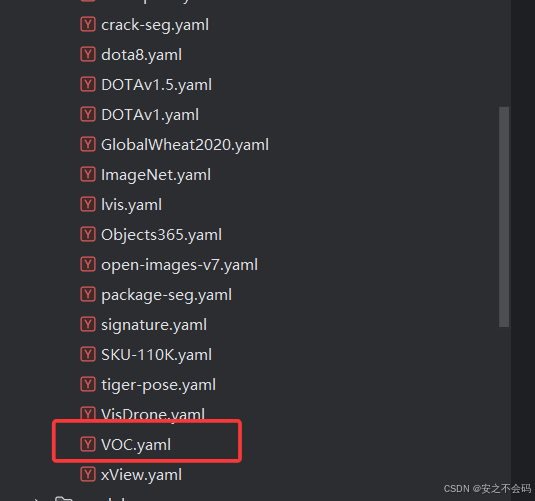
打開之后是以下頁面
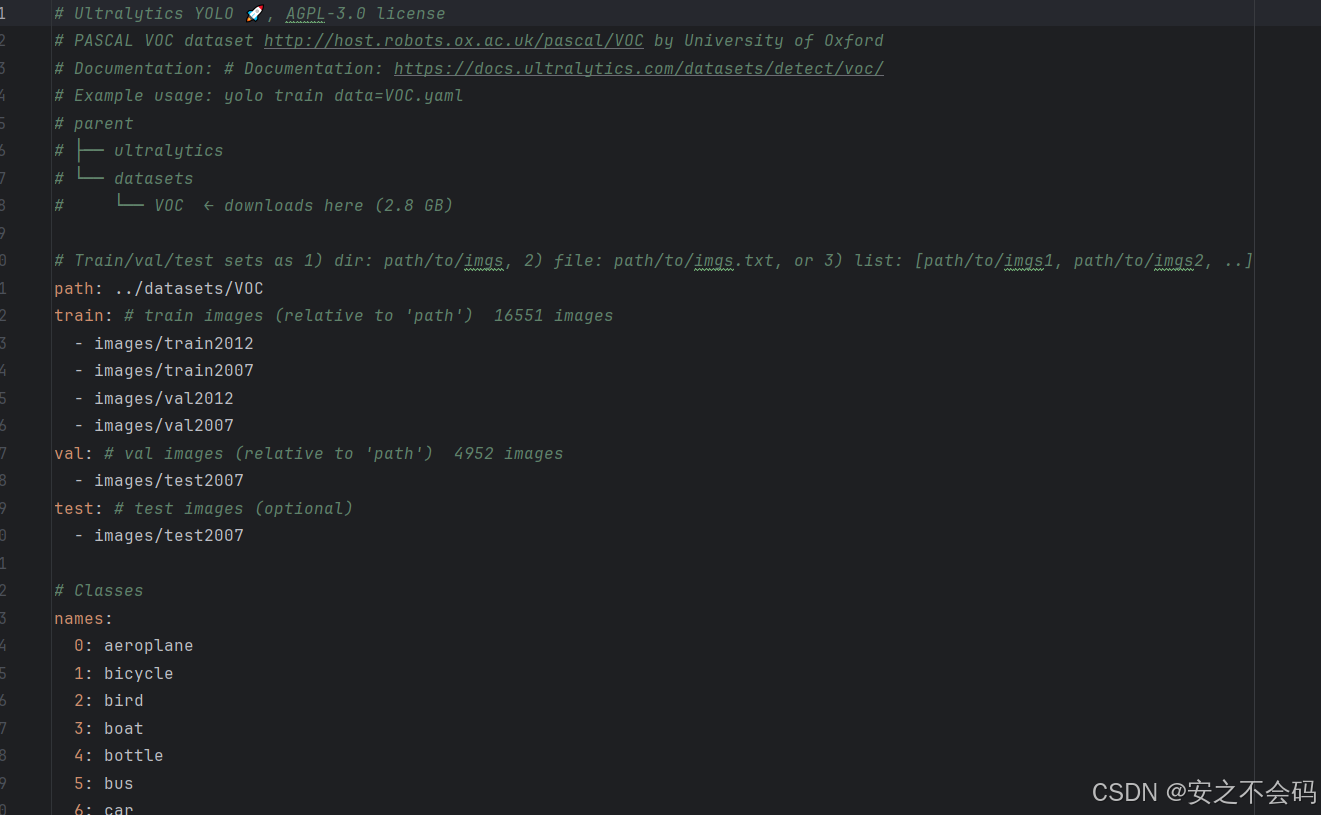
我們接下來我們將其中的內容全部替換為以下內容,其中,上面三個都替換為之間建好數據集的訓練、驗證和測試集的路徑,然后names下面將自己標注的目標個數和名稱進行替換,如果只有一個目標那就只留下0,有多的就自己加上,切記,目標的名稱也得修改(我這個是從voc數據集中截取了一部分,所有就有這些類別)
train: D:\my_dataset\voc\train # train images (relative to 'path') 128 images
val: D:\my_dataset\voc\valid # val images (relative to 'path') 128 images
test: D:\my_dataset\voc\test# Classes
names:0: person1: dog2: cow3: horse4: sheep然后在上面找到該yaml文件右鍵復制該文件絕對路徑
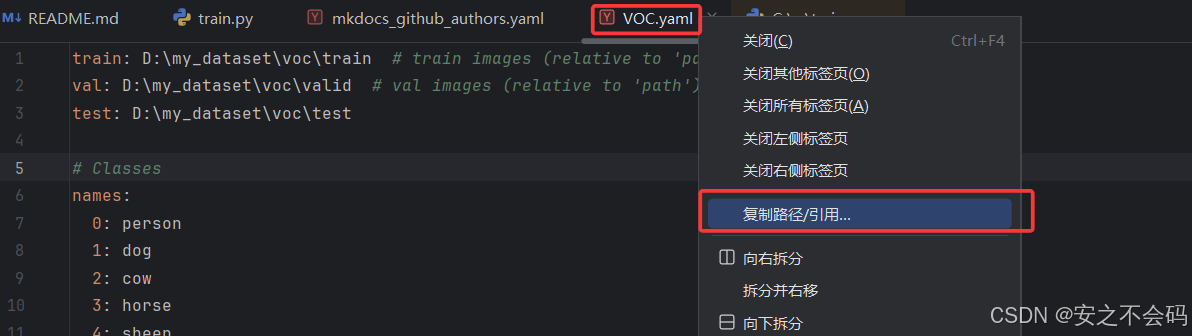
點擊這個絕對路徑就可以直接復制成功
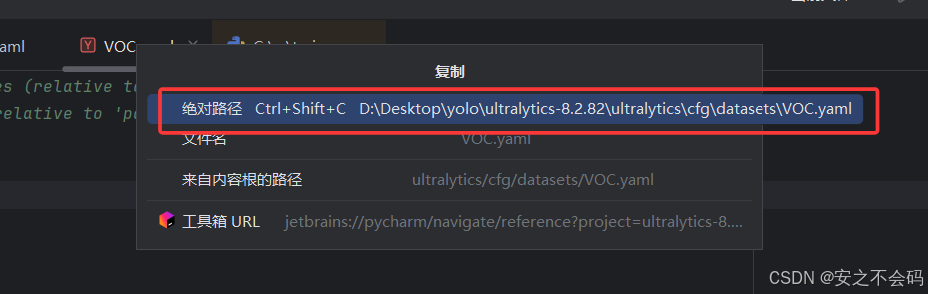
?復制成功后將該路徑粘貼到我們之間創建的tain.py腳本中,就是以下位置
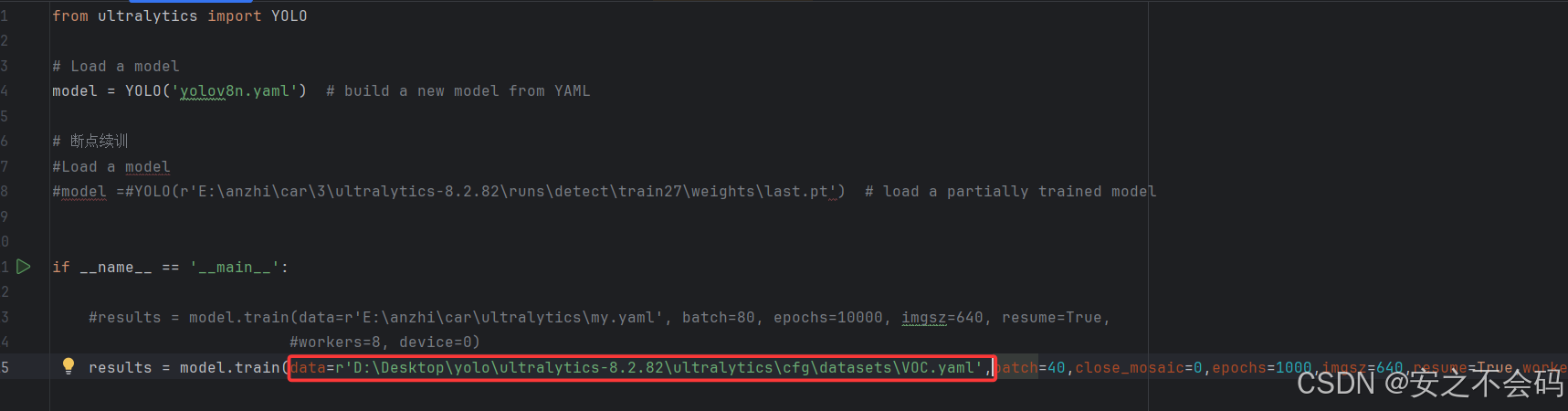
大家后面的指令可以先修改成我這樣,這里面的batch表示批次數,epochs表示訓練的輪次,resume表示是否打開中斷續訓,workers表示線程數,大家先按照我這個設置,等能跑起來沒問題之后再自己調參數訓練
batch=-1,epochs=10,imgsz=640,resume=True,workers=8
?全部修改完成后,在該頁面右鍵直接運行這個python文件即可
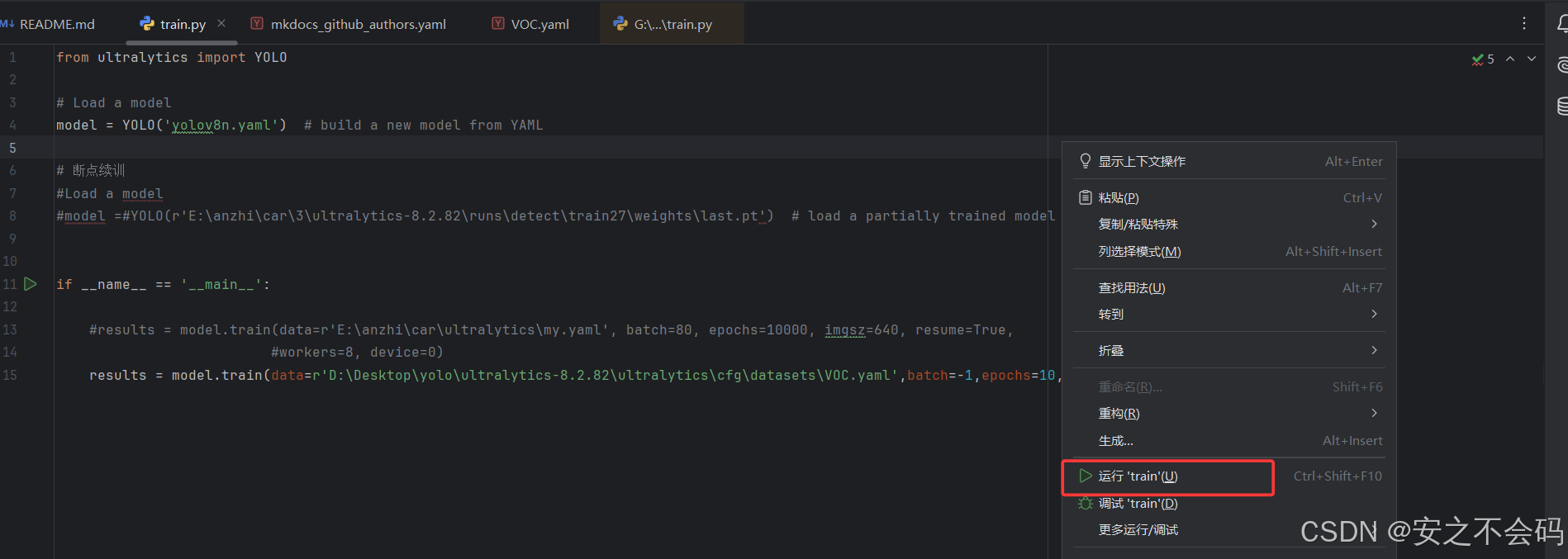
出現下面頁面表示配置成功,已經開始調用gpu訓練了
?已經開始調用GPU了,速度還是比較快的(然后可以看到,我的訓練集共有5527張,驗證集有3409張,GPU顯卡調用了5.3g)
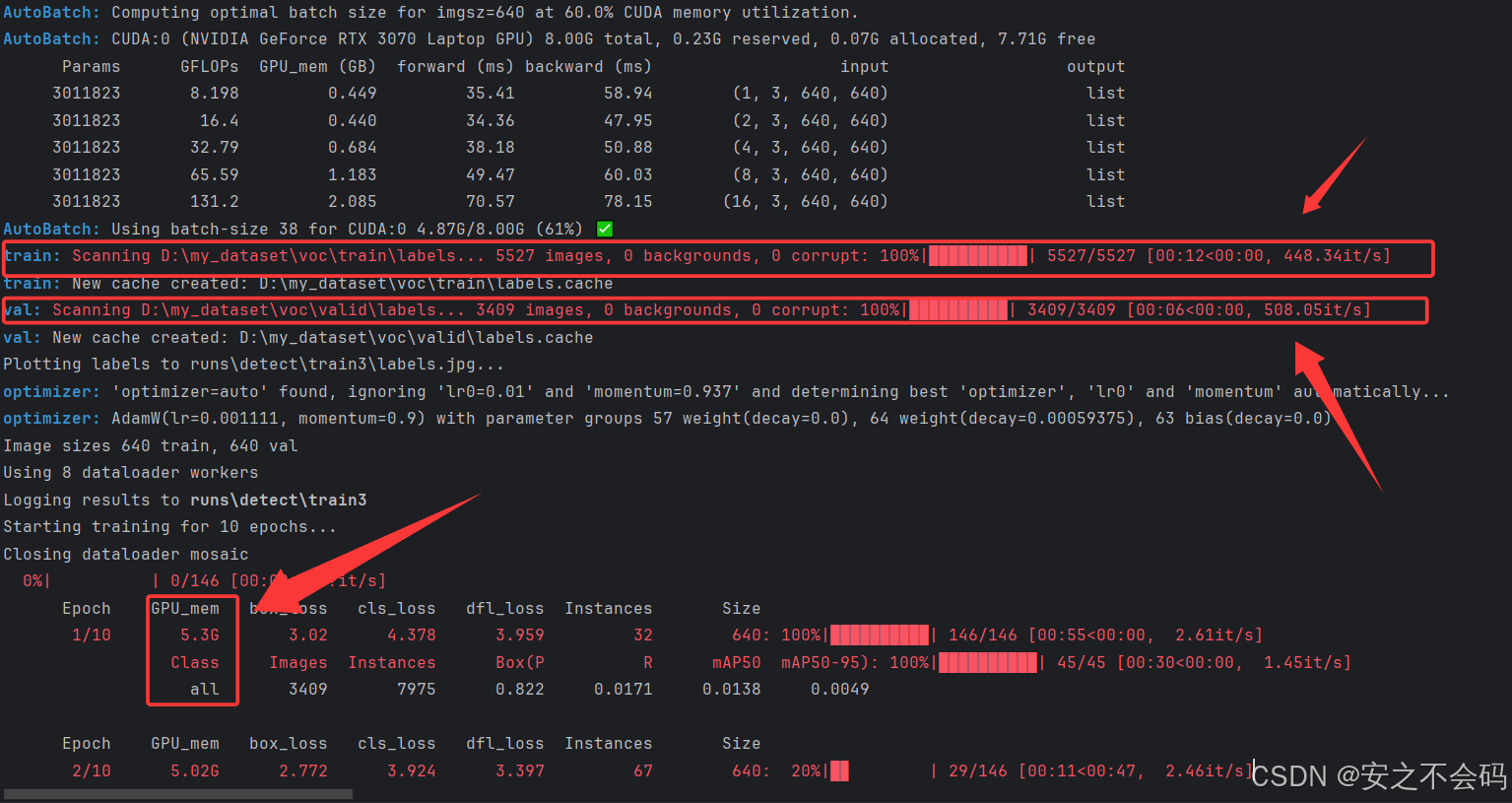
緊接著大家耐心等待一段時間,等訓練完成后會出現以下界面
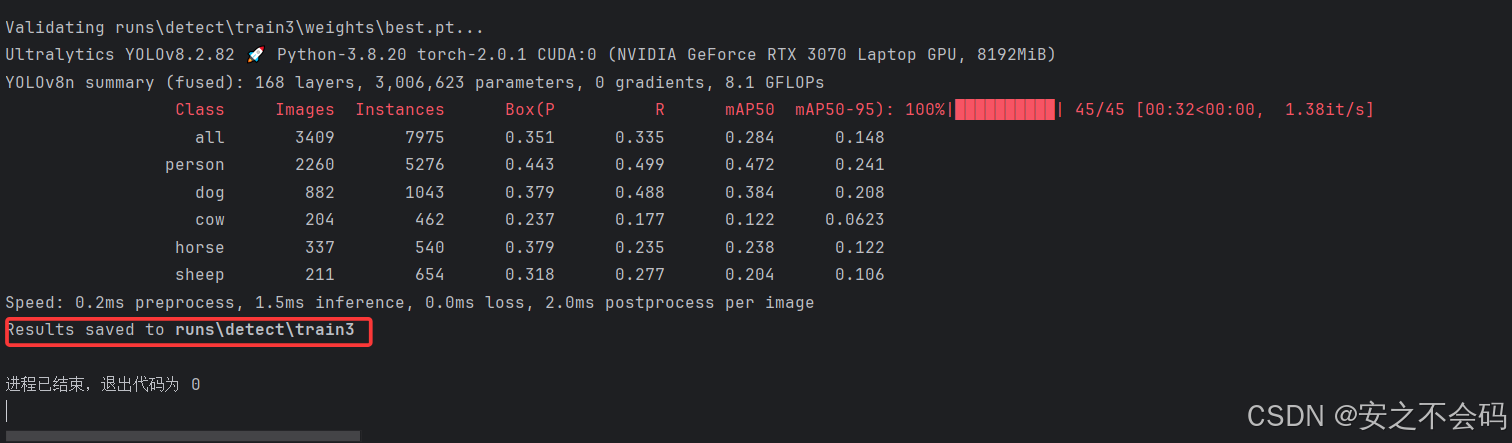
?然后最下面是相關結果的保存路徑,打開自己的yolov8文件夾,然后按照對應路徑打開就行,最終結果如下
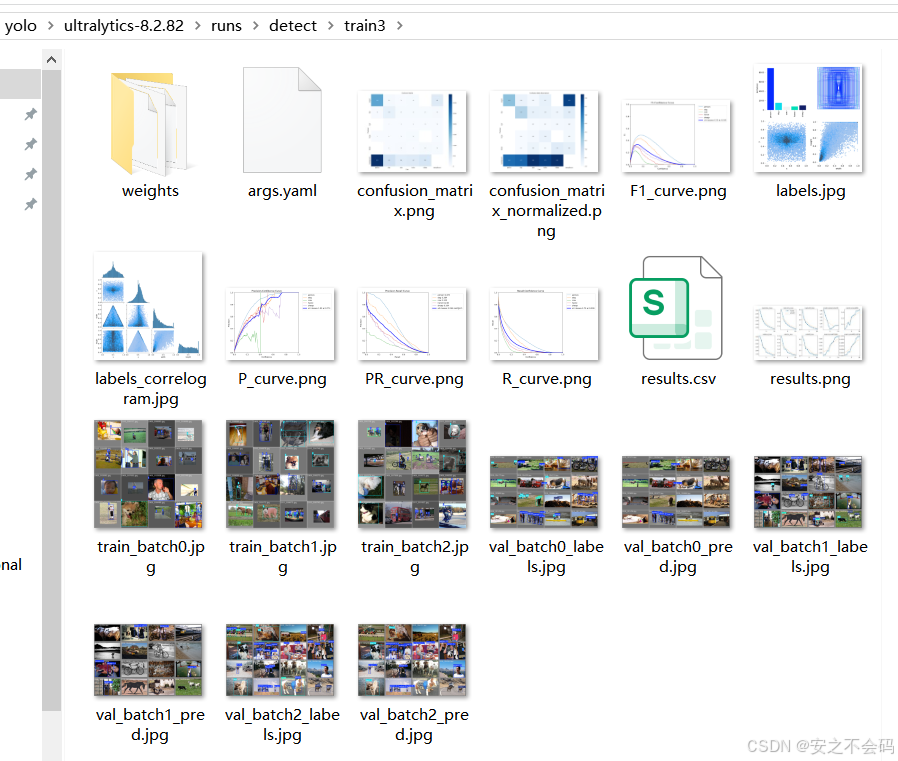
這個里面就是所有的訓練結果了
3.3 推理數據集
咱們在訓練結果的文件夾中,找到weights文件夾,然后將其中的best.pt的路徑進行復制(包括文件名稱和后綴)

然后創建一個prediction的推理腳本,并將以下內容復制進去,然后將相應的路徑進行修改,運行該腳本
from ultralytics import YOLOif __name__ == '__main__':# 使用訓練好的權重文件加載模型model = YOLO(r'D:\Desktop\yolo\ultralytics-8.2.82\runs\detect\train3\weights\best.pt') #替換為自己訓練好的best.pt文件的絕對路徑# 推理參數設置results = model.predict(save=True, source=r'D:\my_dataset\voc\valid\images\2008_000026.jpg')# 推理的圖片存放路徑得到以下的推理輸出
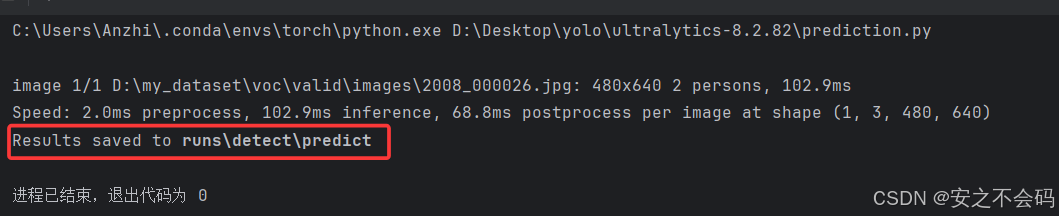
這個是推理結果的保存地址,我們進入地址查看推理結果?
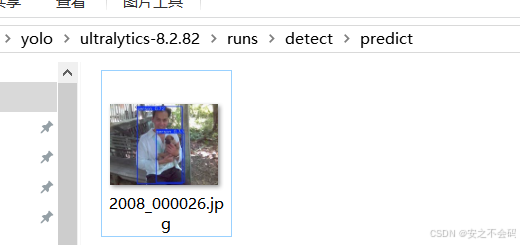

可以看出,由于訓練的次數比較少,因此存在了一個錯誤預測,不過由于右上角置信度比較低,所以還算不錯(哈哈哈哈,畢竟只訓練了10輪)?
4. 總結
本篇文章從最基礎的標注數據集開始教學,直到最終成功調用GPU訓練本人標注數據集,整個過程超級詳細,基本都可以成功復現,同時也希望能對大家有所啟發。
博主后續將還會更新更多的與YOLO相關的一些復現和yolov8的模塊替換和改進,希望大家繼續關注博主!!!創作不易,希望大家多多關注點贊!!!
?



)





數據庫安全性(安全標準,控制,視圖機制,審計與數據加密))





算法 | 用于求解已知n個3D點及其對應2D投影點的相機位姿)



