目錄
一、歡迎
二、機器學習是什么
三、監督學習
四、無監督學習
一、歡迎
機器學習是當前信息技術領域中最令人興奮的方向之一。在這門課程中,你不僅會學習機器學習的前沿知識,還將親手實現相關算法,從而深入理解其內部機理。
事實上,機器學習已廣泛滲透進我們的日常生活。例如,每次你使用 Google、Bing 進行搜索,或用 Facebook、Apple 的圖像識別功能識別朋友,甚至郵箱中的垃圾郵件過濾器,背后都離不開機器學習算法的支持。這些算法讓系統能夠“學習”如何提供更好的服務。
機器學習之所以廣受歡迎,是因為它不僅服務于人工智能領域,更已成為計算機的一種核心能力。我們以前可以手動編寫程序來解決基礎問題,比如尋找最短路徑,但像網頁搜索、圖像識別、反垃圾郵件等復雜任務,則必須依靠機器自我學習來完成。
它在醫療、工程、計算生物學等多個行業中發揮著巨大作用。比如:
-
數據挖掘:分析網頁點擊流數據,優化用戶體驗。
-
醫療健康:通過分析電子病歷,發現疾病模式。
-
基因研究:處理大規模基因序列,探索生命奧秘。
-
自動控制:如訓練無人直升機自動飛行。
-
手寫識別:用于郵件自動分揀。
-
自然語言處理與計算機視覺:提升語言和圖像理解能力。
-
個性化推薦系統:如 Amazon、Netflix、iTunes 的推薦功能。
此外,機器學習也被用來幫助我們理解人類學習本身和大腦的工作機制。它不僅推動 AI 夢想的實現,也是 IT 行業最受歡迎的技能之一。許多科技公司都在積極尋找掌握機器學習的人才,遠遠超出目前的供給。
二、機器學習是什么
雖然“機器學習”沒有一個統一的定義,但有兩個經典的描述:
Arthur Samuel(20世紀50年代):
他將機器學習定義為“在沒有明確設置的情況下,使計算機具有學習能力的研究領域”。
他創建了一個西洋棋程序,程序通過與自己對弈上萬次,不斷優化策略,最終下棋水平超過了他本人。Tom Mitchell(卡內基梅隆大學):
定義:“一個程序被認為能從經驗E中學習,解決任務T,達到性能度量值P,當且僅當,有了經驗E后,經過P評判,程序在處理T時的性能有所提升”
例如:垃圾郵件過濾系統
任務 T:識別垃圾郵件
經驗 E:觀察是否把郵件標記為垃圾郵件
性能度量 P:系統正確分類郵件的準確率
機器學習算法主要包括監督學習、無監督學習,以及其他類型如強化學習和推薦系統。
三、監督學習
監督學習指的就是給學習算法一個數據集,其中包含了“正確答案”,通過訓練模型來學習已有數據中的規律,然后運用學習算法算出更多的“正確答案”。下面通過幾個例子來理解它的核心思想。
例子1:預測房價(回歸問題)
這里有一份從俄勒岡州的波特蘭市收集的房價數據,把這些數據畫出來,如下圖,橫軸表示房子的面積(平方英尺),縱軸表示房價(千美元)。基于這組數據,如果有一套750平方英尺的房子,想知道這房子能賣多少錢?
可以應用學習算法,對數據進行擬合,比如用一條直線來擬合這些數據,由此看出房子可以賣大約15萬美元;也可以用二次函數來擬合數據可能效果會更好,看出房子可以賣出接近20萬美元。
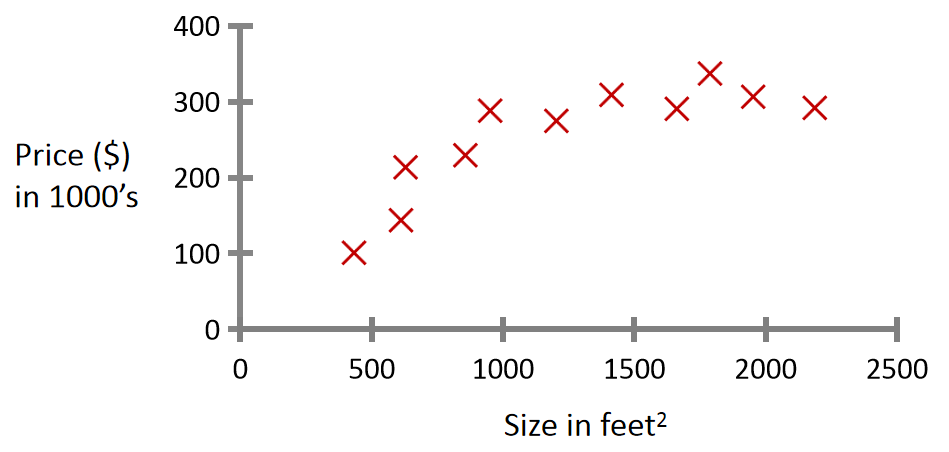
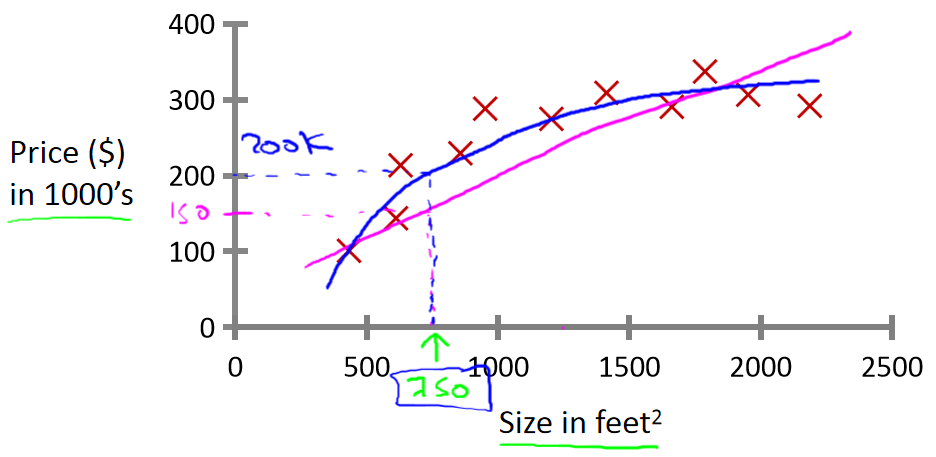
這種任務就是回歸問題,回歸是指試圖推測連續值的屬性。?在這個例子中“正確答案”是房子的實際售價。
例子2:通過查看病歷來判斷乳腺腫瘤是否為惡性(分類問題)
假設有一組數據,橫軸表示腫瘤的大小,縱軸是1或0,1代表惡性,0代表良性。有5個良性腫瘤樣本,用藍叉表示,有5個惡性腫瘤樣本,用紅叉表示。現在有個尺寸已知的乳腺腫瘤,能否估算出這個腫瘤是惡性還是良性的概率?
在機器學習的問題中,會有多個特征,比如除了腫瘤尺寸外,還知道患者年齡。如下圖,橫軸表示腫瘤的大小,縱軸表示患者年齡。數據集可能是藍圈表示良性,紅叉表示惡性。在給定的數據集上,學習算法可能用一條直線來分離,并以此來判斷良性或惡性瘤。
在機器學習的算法中,往往會有更多特征,比如腫塊密度、腫瘤細胞大小的一致性、腫瘤細胞形狀的一致性等其它的特征。如何處理更多甚至無窮多的特征呢?后面會講支持向量機算法,里面有一個巧妙的數學技巧,能讓計算機處理無限多個特征。
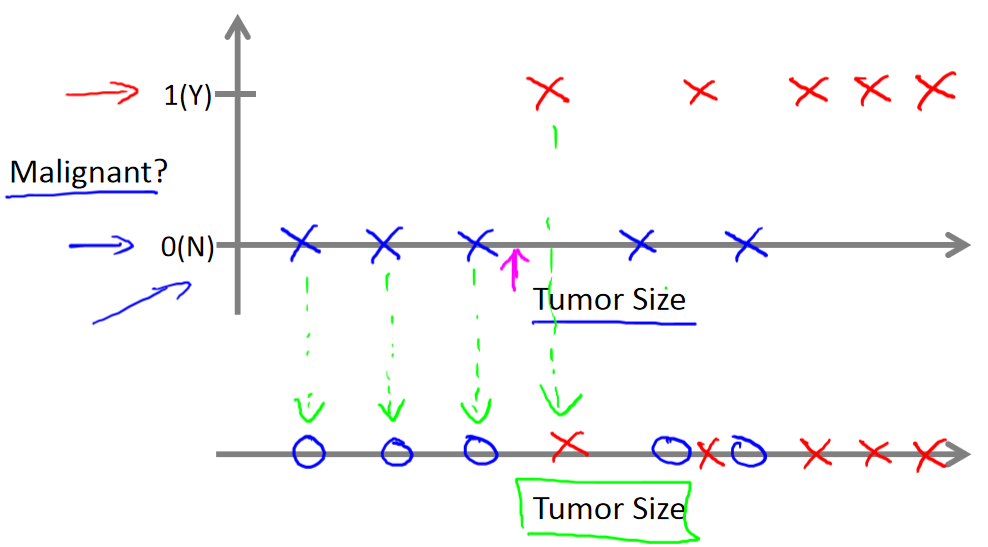
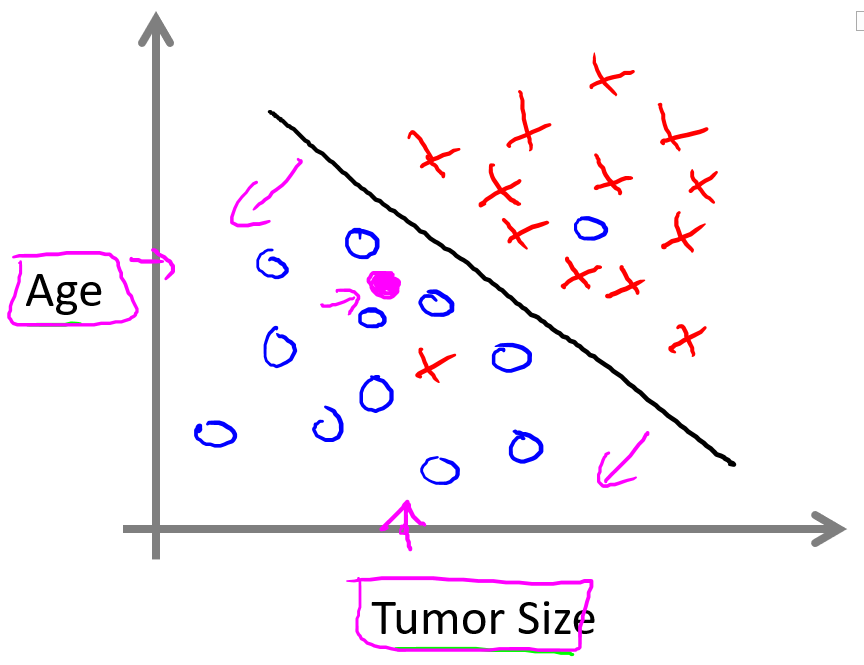
這種任務屬于分類問題,目標是推測出一個離散的輸出(0或1)。分類問題中,有時會有兩個以上的輸出值,比如:0=良性,1=第一類乳腺癌,2=第二類乳腺癌,3=第三類乳腺癌。這些離散輸出值對應不同的類別,因此屬于多分類問題。
四、無監督學習
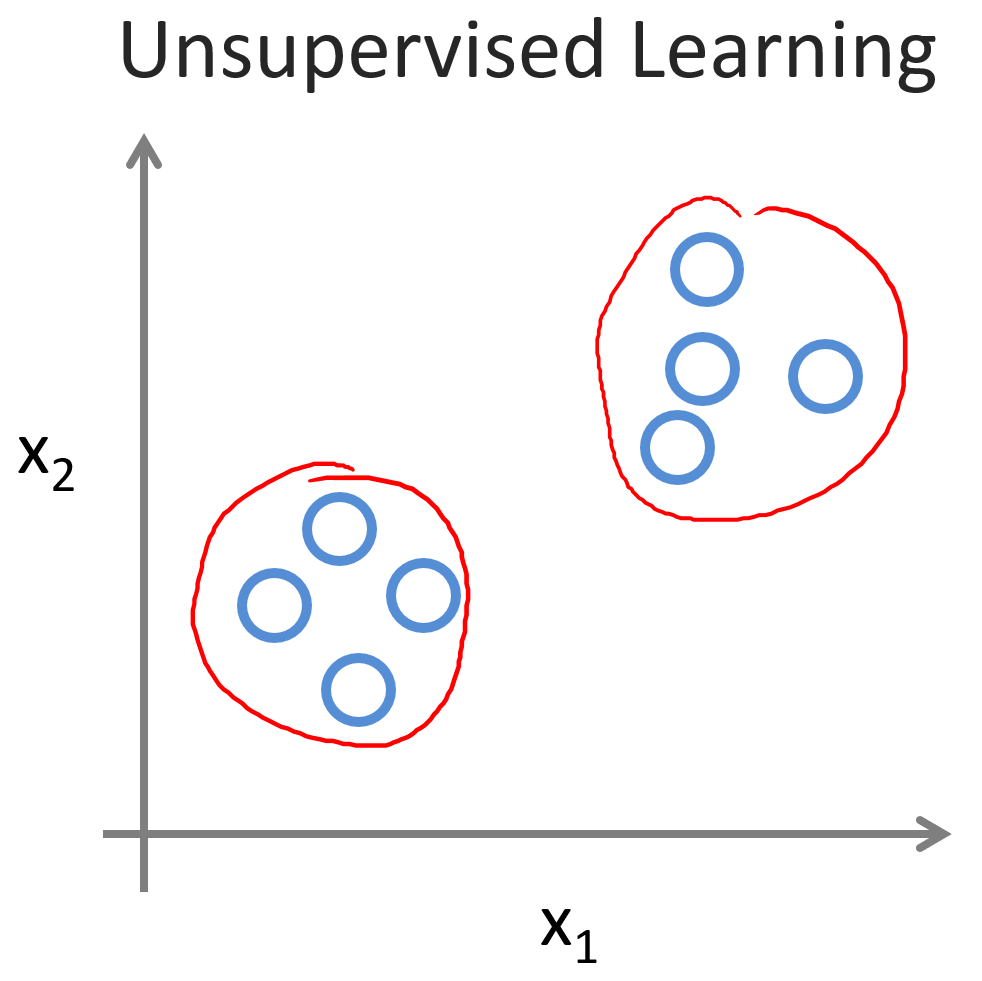
在無監督學習中,我們的數據集沒有標簽或“正確答案”。我們不知道每個樣本屬于哪一類,甚至不知道應該有多少類。我們唯一擁有的只是原始的數據,算法的任務是從這些數據中自動發現結構或規律。
一個典型的無監督學習任務是聚類(Clustering)。算法試圖將數據劃分為若干個簇,如下圖:算法可以自動識別出兩個明顯不同的簇(群組),即使我們事先并不知道這些簇的存在。
?
?聚類算法的實際應用,比如:
谷歌新聞聚類
一個非常貼近生活的應用是 Google News。它每天會收集大量新聞內容,并使用聚類算法自動將相關的新聞歸到一起。你看到的每一組新聞,其實是無監督學習算法將它們聚到一起的結果。
基因表達分析
聚類算法也應用在基因數據分析中。例如,我們可以對不同個體的DNA微陣列數據進行分析,試圖找出是否存在某些特定的基因表達模式。雖然我們并不知道哪些人屬于哪一類,但通過聚類算法,我們可以將具有相似基因表達的個體歸為一類。
無監督學習及其聚類算法被廣泛應用于以下領域:
- 計算機集群管理
在大數據中心,通過聚類算法自動識別哪些計算機可以協同工作,以提高效率。
- 社交網絡分析
分析你常聯系的人,自動將社交網絡中的朋友分組,每組中的人彼此熟識。
- 市場細分(Market Segmentation)
企業可以使用顧客數據,自動將用戶劃分為不同的市場細分群體,進而進行更有針對性的營銷。
- 天文數據分析
聚類算法也被用于分析星系形成過程,提供了很多有趣且有用的理論支持。
另一種無監督學習任務是雞尾酒宴問題。你可以想象在一個嘈雜的雞尾酒宴會中,有兩個人同時在說話。我們在房間里放置兩個麥克風,分別錄下兩段混合音頻。任務是從這兩段錄音中分離出各自的說話聲。這個任務同樣屬于無監督學習。你不知道哪個聲音是誰的,只能讓算法自己去從音頻中“解混合”,分離出原始的音頻源。



(訓練自己數據集)(Pycharm保姆級安裝教程)(lablme的使用)(GPU版))



)





數據庫安全性(安全標準,控制,視圖機制,審計與數據加密))





算法 | 用于求解已知n個3D點及其對應2D投影點的相機位姿)