
作者:?derekchen? ??
Demo數據集準備
我們使用公開的UTSD數據集里面的電力需求數據,作為預測算法的數據來源,基于歷史數據預測未來若干小時的電力需求。數據集的采集頻次為30分鐘,單位與時間戳未提供。為了方便演示,按照頻率從2025-01-01 00:00:00開始向前倒推生成時間戳,并存儲在TDengine對應的表里。
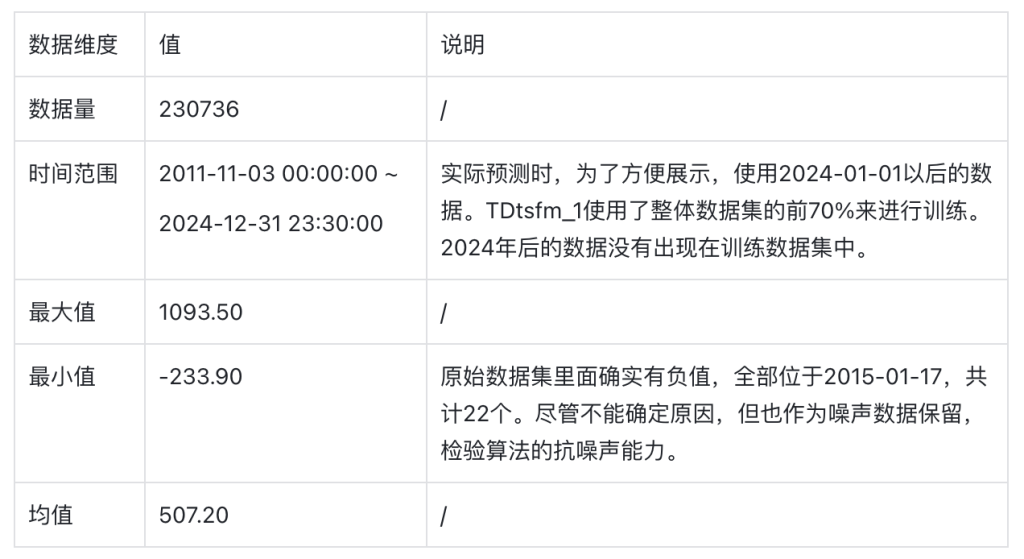
數據集中包含5個文件,我們使用編號最大的一個子集來完成演示。該數據文件,放置于https://github.com/taosdata/TDgpt-demo倉庫的demo_data目錄下,請參考下文的步驟導入TDengine以完成演示。數據集的統計信息如下:
演示環境準備
環境要求
您可基于Linux、Mac以及Windows操作系統完成Demo系統的運行。但為使用docker-compose,您計算機上需要安裝有下屬軟件:
- Git
- Docker Engine: v20.10+
- Docker Compose: v2.20+
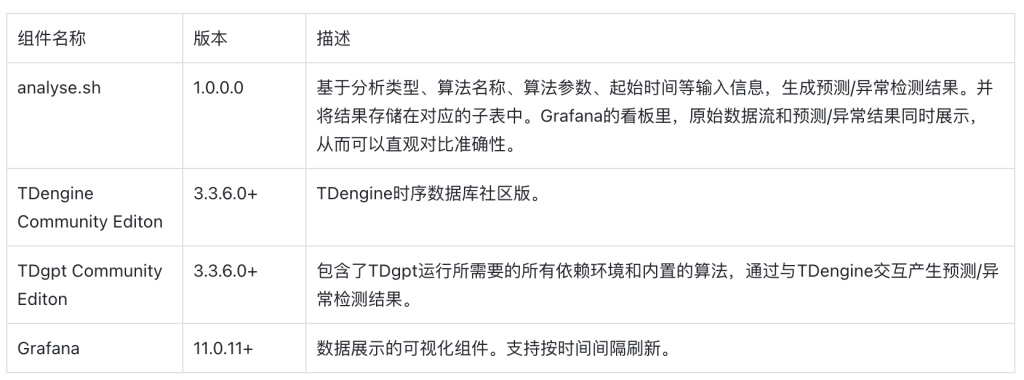
Demo中包含3個docker鏡像 (TDengine, TDgpt, Grafana),以及一組用于產生預測/異常檢測結果的shell腳本。組件版本的要求如下:
克隆Demo倉庫到本地
git clone https://github.com/taosdata/TDgpt-democd TDgpt-demochmod 775 analyse.sh
文件夾下包含docker-compose.yml、tdengine.yml兩個yml文件。docker-compose.yml 包含了所有一鍵啟動demo所需的鏡像配置信息,其引用tdengine.yml作為Grafana的數據源配置。
TDgpt-demo/demo_data下包含三個csv文件(electricity_demand.csv、wind_power.csv、ec2_failure.csv),以及三個同前綴sql腳本,分別對應電力需求預測、風力發電預測和運維監控異常檢測場景。
TDgpt-demo/demo_dashboard下包含了三個json文件(electricity_demand_forecast.json、wind_power_forecast.json、ec2_failure_anomaly.json),分別對應三個場景的看板。
docker-compose.yml中已經定義了TDengine容器的持久化卷:tdengine-data,待容器啟動后,使用docker cp命令將demo_data拷貝至容器內使用。
運行和關閉Demo
注意:在運行demo前,請根據您宿主機的架構(CPU類型),編輯docker-compose.yml文件,為TDengine指定對應的platform參數:linux/amd64(Intel/AMD CPU)或linux/arm64(ARM CPU)。TDgpt必須統一使用linux/amd64參數。
進入docker-compose.yml文件所在的目錄執行如下命令,啟動TDengine、TDgpt和Grafana一體化演示環境:
docker-compose up -d
首次運行時,等待10s后請執行如下命令將TDgpt的Anode節點注冊到TDengine:
docker exec -it tdengine taos -s "create anode 'tdgpt:6090'"
在宿主機執行下列命令,初始化體驗測試環境的數據:
docker cp analyse.sh tdengine:/var/lib/taosdocker cp demo_data tdengine:/var/lib/taosdocker exec -it tdengine taos -s "source /var/lib/taos/demo_data/init_electricity_demand.sql"
關閉演示環境,請使用:
docker-compose down
進行演示
- 打開瀏覽器,輸入http://localhost:3000,并用默認的用戶名口令 admin/admin 登錄Grafana。
- 登錄成功后,進入路徑”Home → Dashboards”頁面,并且導入electricity_demand_forecast.json文件。
- 導入后,選擇“electricity_demand”這個面板。面板已經配置好了真實值、TDtsfm_1以及HoltWinters的預測結果。當前只有真實值的數據曲線。
- 我們以analyze.sh腳本,來進行預測。首先完成TDtsfm_1算法的演示:
docker exec -it tdengine /var/lib/taos/analyse.sh --type forecast --db tdgpt_demo --table electricity_demand --stable single_val --algorithm tdtsfm_1 --params "fc_rows=48,wncheck=0" --start "2024-01-01" --window 30d --step 1d
上述shell腳本,將從指定的起始時間開始(2024-01-01)以前一個月的數據為輸入,使用TDtsfm_1算法預測當前下一天的每30mins的電力需求(共計48個數據點),直到達到electricity_demand 表中最后一天的記錄,并將結果寫入electricity_demand_tdtsfm_1_result 表中。執行新的預測前,腳本會新建/清空對應的結果表。執行過程中將持續在控制臺上,按照天為單位推進輸出如下的執行結果:
taos> INSERT INTO tdgpt_demo.electricity_demand_tdtsfm_1_result SELECT _frowts, forecast(val, 'algorithm=tdtsfm_1,fc_rows=48,wncheck=0')FROM tdgpt_demo.electricity_demanWHERE ts >= '2024-01-12 00:00:00' AND ts < '2024-02-11 00:00:00'Insert OK, 48 row(s) affected (0.238208s)
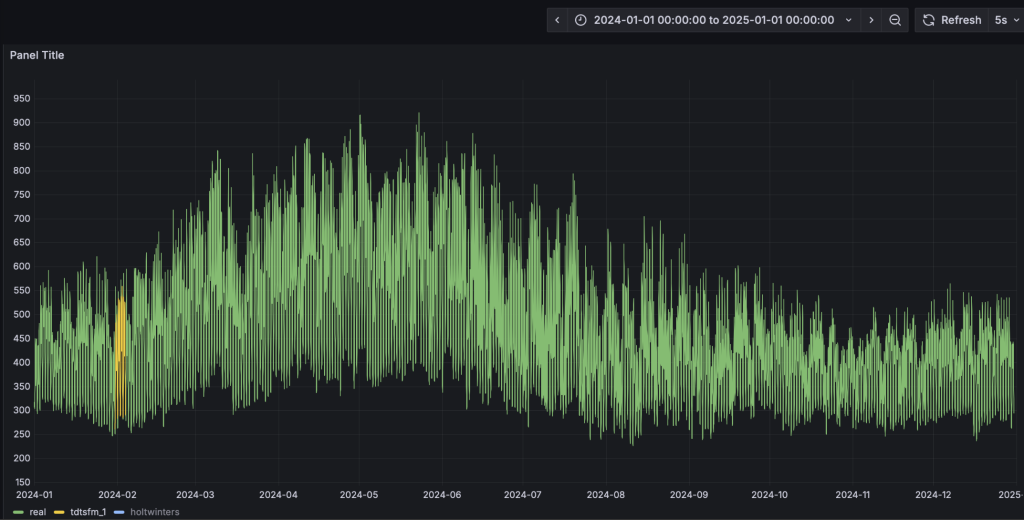
- Grafana的看板上,配置刷新頻率為5s,將動態顯示預測結果的黃色曲線,直觀呈現與實際值的對比。為了展示清晰,請按住command鍵點擊左下角的Real以及TDtsfm_1圖例(Mac下,Windows下請使用win鍵),從而只保留這兩條曲線展示。
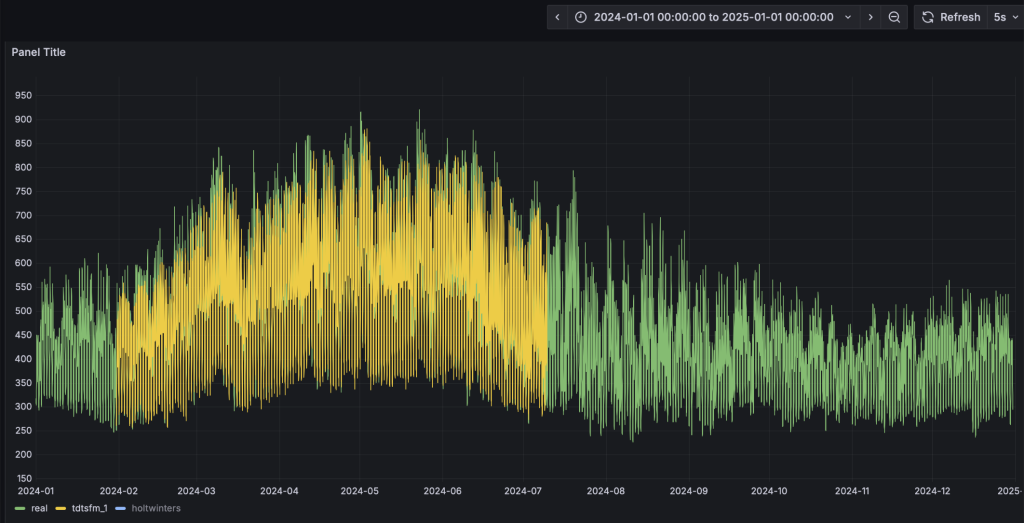
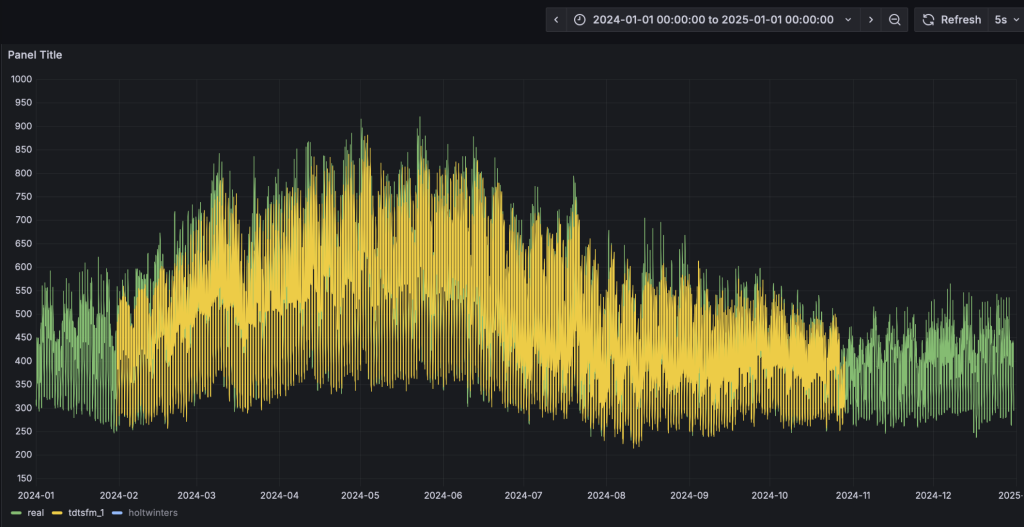
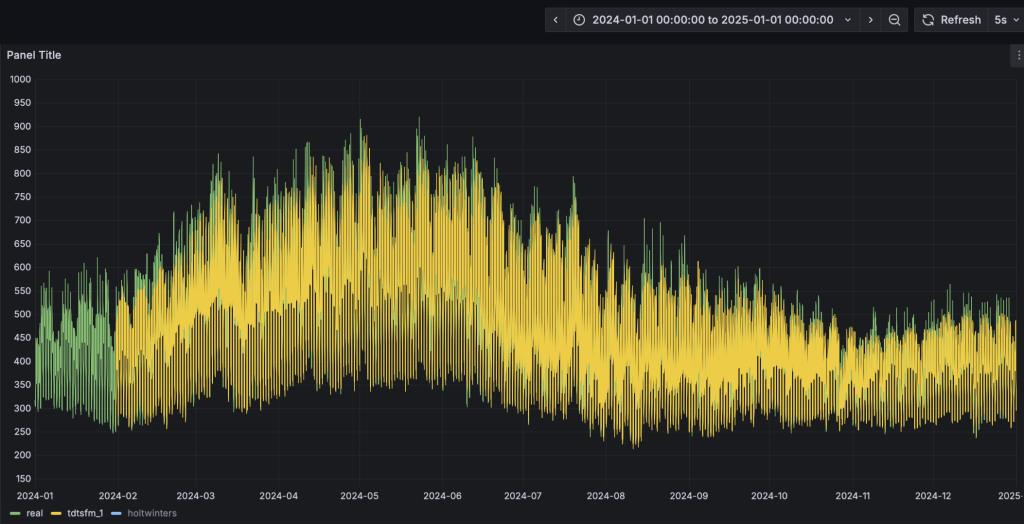
- 完成HoltWinters模型的演示:
docker exec -it tdengine /var/lib/taos/analyse.sh --type forecast --db tdgpt_demo --table electricity_demand --stable single_val --algorithm holtwinters --params "rows=48,period=48,wncheck=0,trend=add,seasonal=add" --start "2024-01-01" --window 30d --step 1d
與第四步類似,HoltWinters模型將動態輸出預測結果并呈現在看板上。從預測結果中可以看到,TDtsfm_1對數據的預測精度顯著優于傳統的統計學方法HoltWinters。除了預測精度外,HoltWinters算法的最大問題是需要非常精細化的對參數進行調整評估,否則還容易出現下圖中這種頻繁發生的預測值奇異點。
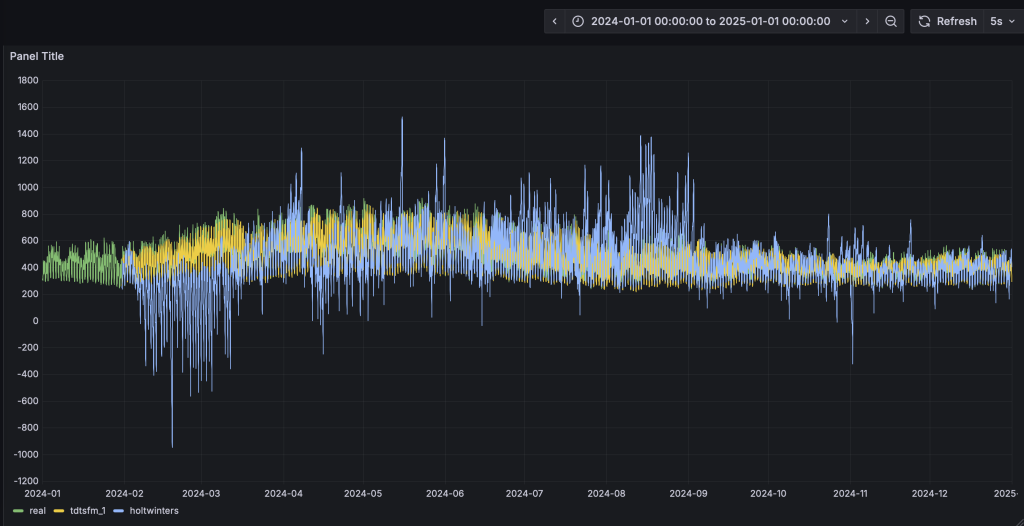
基于鼠標圈選的方式,我們可以查看一段時間內的細粒度預測結果對比:
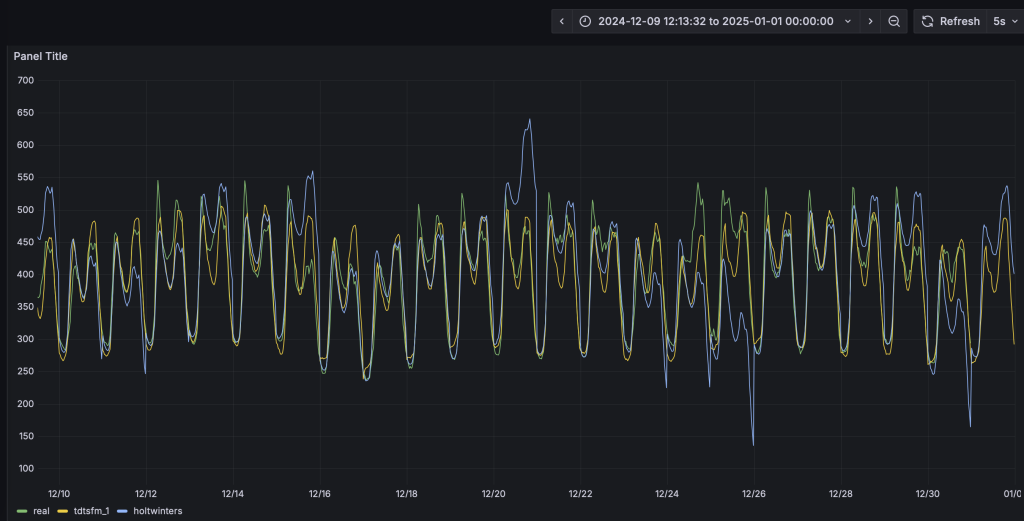
您也可以嘗試其他算法或模型,來找到最合適自己場景的算法和模型。
Demo腳本使用詳解
腳本概述?
analyse.sh腳本用于在 TDengine 數據庫上執行時間序列預測和異常檢測分析,支持滑動窗口算法處理。主要功能包括:
- 時間序列預測 :使用 HoltWinters 等算法進行未來值預測 。
- 異常檢測 :使用 k-Sigma 等算法識別數據異常點 。
- 自動窗口滑動 :支持自定義窗口大小和步長進行連續分析。
參數說明
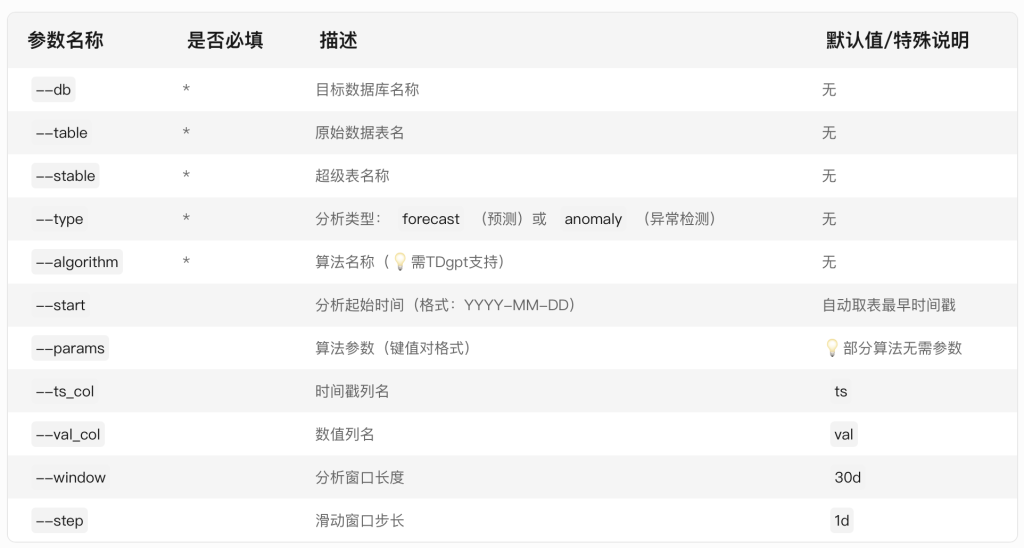
TDengine推薦使用超級表來進行數據建模。因此,Demo中建立了一個名為 single_val 的超級表,包含ts (timestamp類型) 和val (float類型),以及標簽定義scene (varchar (64) )。現階段TDgpt只支持單列值輸入輸出,因此這個超級表可以作為所有源數據表和結果表的結構定義。子表的表名與tag名稱保持一致即可。
db參數指定了源數據表和結果表隸屬的數據庫。結果表將以【源表名稱】_【算法名稱】_【result】格式存儲。Grafana里面通過查詢結果表實現分析結果和原始數據的對比。
一般情況下,對于非必填項,用戶在demo過程中只需要設置–start參數以節省運行時間。對于必填項,請參考示例值進行設置。
時間格式說明?
step和window參數指定的滑動步長和分析窗口大小需符合如下參數約定:

腳本執行流程
graph TDgpt_DemoA[開始] --> B[參數解析與驗證]B --> C{是否指定start?}C -->|否| D[查詢最小時間戳]C -->|是| E[轉換時間格式]D --> EE --> F[計算時間窗口]F --> G[生成結果表]G --> H{是否到達數據終點?}H -->|否| I[生成并執行SQL]I --> HH -->|是| J[輸出完成信息]
使用更多的數據
參考「運行和關閉Demo」章節里electricity_demand.sql腳本的內容,確保按照規定格式將數據準備為csv格式(逗號分隔,值需要用英文雙引號括起來),即可將數據導入TDengine。然后,請使用「進行演示」章節中的方法來生成預測結果,并調整Grafana中的看板以實現和實際數據的對比。
結論
在本文中,我們展示了使用TDgpt來進行電力需求預測的完整流程。從中可以看到,基于TDgpt 來構建時序數據分析,能夠以SQL方式實現與應用的便捷集成,還可以用Grafana 進行展示,大大降低開發和應用時序數據預測和異常檢測的成本。
從預測效果來看,基于transformer架構的預訓練模型TDtsfm_1在使用的數據集上展示出顯著優于Holtwinters模型的效果。在不同的實際場景下,用戶需要針對數據特點,針對模型算法進行選擇和參數調優,也可以選擇不同的算法或模型進行嘗試。
TDengine 的企業版中,TDgpt 將為用戶提供更多的選擇:
- 模型選擇器。模型選擇器可以自動根據用戶的歷史數據集,對購買的所有模型進行準確性評估。用戶可選擇最適合自己場景的模型或算法進行部署和應用。
- TDtsfm_1自研模型的重訓練及微調。TDtsfm_1基于海量時序數據進行了預訓練,在大部分場景下相比于傳統的機器學習和統計預測模型都會有顯著的準確率優勢。如果用戶對于模型預測準確度有更高的要求,可以申請購買 TDgpt 企業版的預訓練服務。使用用戶的場景歷史數據進行預訓練,在特定場景下的預測效果可能更佳。
- 第三方解決方案。濤思數據聯合國內外時序分析/異常檢測專業廠家、研究機構,為用戶提供專業的分析解決方案,包括落地過程中的實施服務等。
關于背景
電力需求預測作為現代能源管理的核心工具,其核心價值貫穿電力系統的全生命周期。在資源配置層面,通過精準預判用電趨勢,可優化發電設施布局與電網升級節奏,避免超前投資造成的資源閑置或滯后建設引發的供應缺口,典型場景中可使基礎設施投資效率提升15%-20%。對于電力運營商而言,負荷預測支撐著從燃料采購到機組調度的動態優化,在火力發電領域已實現噸煤發電量2%以上的能效提升,同時通過削峰填谷降低電網備用容量需求,顯著壓縮系統運行成本。?
在能源安全維度,預測技術構建起電力供需的緩沖機制。短期預測誤差每降低1個百分點,對應減少的緊急調峰成本可達區域電網日均運營費用的3%-5%,這在應對極端天氣或突發事件時尤為關鍵。而中長期預測則為跨區域電力互濟、儲能設施配置提供決策基線,有效緩解結構性缺電風險。市場環境中,預測能力直接轉化為經濟收益,發電企業通過日前96時段負荷預測優化報價策略,在電力現貨市場中可額外獲取10%-18%的價格套利空間,工商用戶則借助負荷特性分析制定用能方案,實現年度電費支出5%-10%的降幅。
本文提供基于 docker-compose 快速部署 TDgp 體驗測試環境的指引,并基于這個環境和真實的數據,展示日前預測電力需求的全過程,便于大家快速掌握 TDgpt,迅速讓自己擁有AI驅動的時序數據預測與異常檢測的能力。
關于TDgpt
TDgpt 是 TDengine 內置的時序數據分析智能體,它基于 TDengine 的時序數據查詢功能,通過 SQL 提供運行時可動態擴展和切換的時序數據高級分析的能力,包括時序數據預測和時序數據異常檢測。通過預置的時序大模型、大語言模型、機器學習、傳統的算法,TDgpt 能幫助工程師在10分鐘內完成時序預測與異常檢測模型的上線,降低至少80%的時序分析模型研發和維護成本。
截止到3.3.6.0版本,TDgpt?提供Arima、HoltWinters、LSTM、MLP 以及基于Transformer架構自研的TDtsfm (TDengine time series foundation model) v1版和其他時序模型,以及k-Sigma、Interquartile range(IQR)、Grubbs、SHESD、Local Outlier Factor(LOF)、Autoencoder這六種異常檢測模型。用戶可以根據TDgpt開發指南自行接入自研或其他開源的時序模型或算法。


)

—引言)



(訓練自己數據集)(Pycharm保姆級安裝教程)(lablme的使用)(GPU版))



)





數據庫安全性(安全標準,控制,視圖機制,審計與數據加密))
