?
在當今人工智能快速發展的時代,語音識別技術已經成為人機交互的重要方式之一。本文將介紹如何使用Python結合Vosk和PyAudio庫實現一個離線語音識別系統,無需依賴網絡連接即可完成語音轉文字的功能。
技術棧概述
1. Vosk語音識別引擎
Vosk是一個開源的語音識別工具包,支持多種語言,具有以下特點:
-
離線工作,不需要網絡連接
-
輕量級,適合嵌入式設備
-
支持多種編程語言接口
-
提供預訓練模型,開箱即用
2. PyAudio音頻處理庫
PyAudio是Python的音頻處理庫,提供跨平臺的音頻輸入輸出功能:
-
支持實時音頻流處理
-
簡單易用的API
-
跨平臺支持(Windows, Linux, Mac)
代碼實現解析
1. 環境準備與依賴安裝
首先需要安裝必要的Python庫:
bash
復制
下載
pip install vosk pyaudio
2. 音頻輸入設置
python
復制
下載
import pyaudio# 初始化音頻輸入流 p1 = pyaudio.PyAudio() IVW_ASR_TARGET_DATA_LINE = p1.open(format=pyaudio.paInt16,channels=1,rate=16000,input=True,frames_per_buffer=6400)
這里我們設置了:
-
音頻格式為16位整數(paInt16)
-
單聲道(channels=1)
-
采樣率16kHz(rate=16000)
-
每幀6400字節的緩沖區
3. Vosk語音識別核心代碼
python
復制
下載
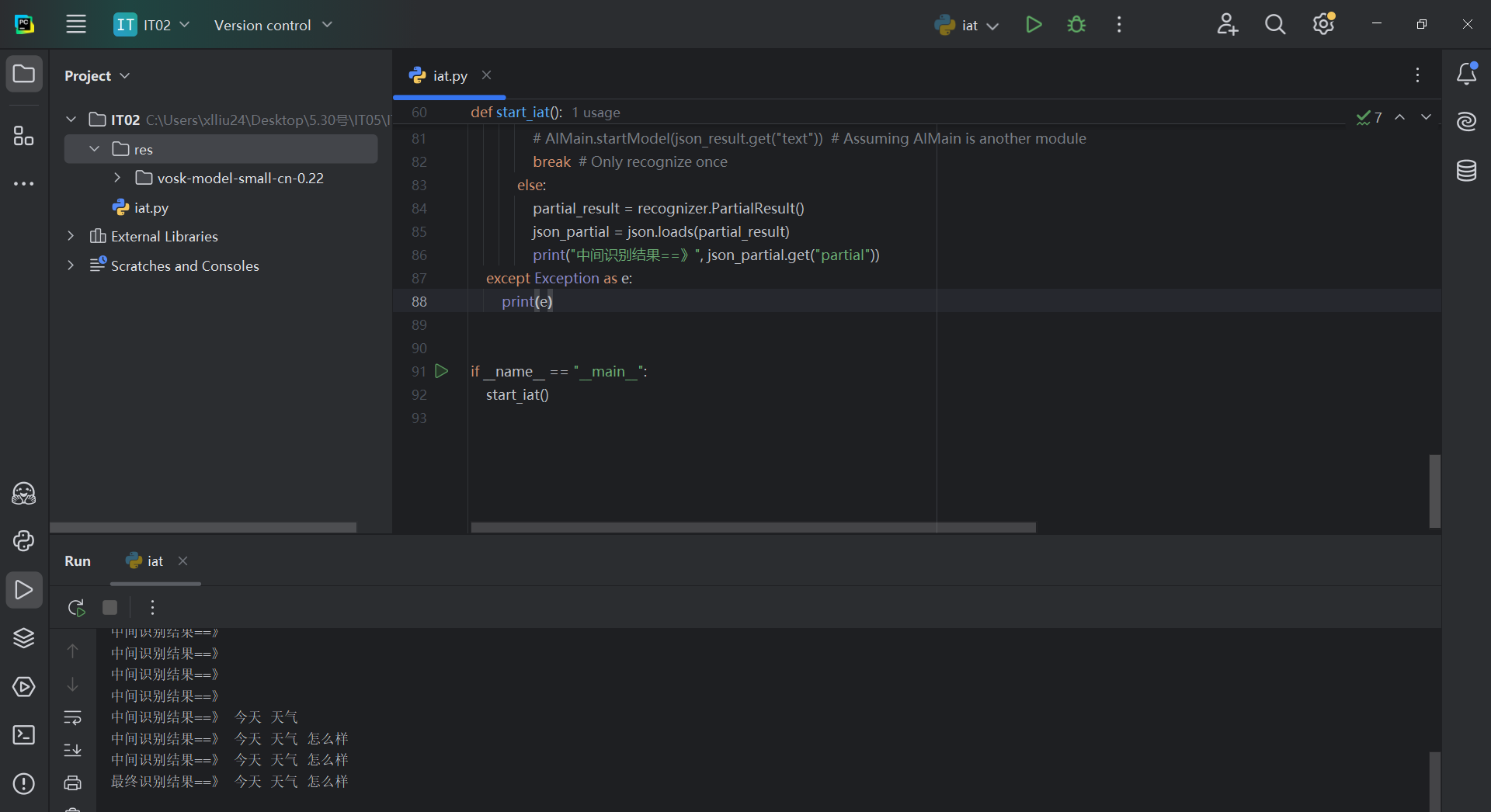
from vosk import Model, KaldiRecognizerdef start_iat():# 加載中文語音模型model = Model("res/vosk-model-small-cn-0.22")recognizer = KaldiRecognizer(model, 16000)try:while True:# 讀取音頻數據buffer = IVW_ASR_TARGET_DATA_LINE.read(6400)if len(buffer) == 0:break# 處理語音識別if recognizer.AcceptWaveform(buffer):# 獲取最終識別結果result = recognizer.Result()json_result = json.loads(result)print("最終識別結果==》", json_result.get("text"))breakelse:# 獲取中間識別結果partial_result = recognizer.PartialResult()json_partial = json.loads(partial_result)print("中間識別結果==》", json_partial.get("partial"))except Exception as e:print(e)
4. 模型文件準備
Vosk需要下載對應的語音模型文件,中文小模型可以從Vosk官網下載,解壓后放在res/vosk-model-small-cn-0.22目錄下。
關鍵技術點解析
1. 實時音頻流處理
使用PyAudio的open()方法創建音頻輸入流,通過循環讀取音頻數據實現實時處理:
python
復制
下載
while True:buffer = IVW_ASR_TARGET_DATA_LINE.read(6400)# 處理buffer...
2. 語音識別狀態處理
Vosk識別器提供兩種結果獲取方式:
-
AcceptWaveform(): 當檢測到語音結束時返回True,可通過Result()獲取最終結果 -
PartialResult(): 實時返回中間識別結果
3. 多線程處理考慮
在實際應用中,可能需要將音頻采集和語音識別放在不同線程中處理,以避免阻塞主線程。
應用場景擴展
-
智能家居控制:通過語音指令控制家電
-
車載語音助手:離線環境下的語音導航和控制
-
工業設備語音控制:嘈雜環境下的語音指令識別
-
語音筆記應用:快速記錄會議內容或靈感
性能優化建議
-
模型選擇:根據需求平衡精度和速度,小模型速度快但精度略低
-
音頻預處理:添加噪聲抑制、回聲消除等處理提高識別率
-
關鍵詞檢測:結合喚醒詞檢測降低系統功耗
-
結果后處理:添加語法檢查提高識別文本質量
常見問題解決
-
模型加載失敗:檢查模型路徑是否正確,文件是否完整
-
音頻無法輸入:檢查麥克風權限和硬件連接
-
識別率低:嘗試調整音頻采樣參數或更換更大模型
-
延遲問題:優化緩沖區大小,或使用更高效的硬件
結語
本文介紹了使用Python+Vosk+PyAudio實現離線語音識別的基本方法。這種方案特別適合需要隱私保護或網絡條件受限的場景。通過簡單的代碼修改,讀者可以將其集成到各種應用中,實現語音交互功能。
完整的項目代碼已在上文展示,讀者可以根據實際需求進行調整和擴展。語音識別技術正在快速發展,期待未來有更多更強大的開源工具出現。




——CDN)







--uboot啟動流程之啟動模式選擇)


![[網頁五子棋][對戰模塊]前后端交互接口(建立連接、連接響應、落子請求/響應),客戶端開發(實現棋盤/棋子繪制)](http://pic.xiahunao.cn/[網頁五子棋][對戰模塊]前后端交互接口(建立連接、連接響應、落子請求/響應),客戶端開發(實現棋盤/棋子繪制))

兩種位置用法)

---Stack和Queue)