引言
生成式人工智能(GenAI)正以顛覆性力量重塑軟件開發的底層邏輯。從代碼生成到業務邏輯設計,從數據分析到用戶交互,GenAI通過其強大的推理能力與場景適應性,將傳統開發流程的“復雜工程”轉化為“敏捷實驗”,推動軟件開發進入“以提示為代碼、以模型為架構”的新紀元。這一變革不僅重構了開發效率的邊界,更催生了人類定義目標,AI自主實現”的智能代理時代。本文從技術對比、開發流程、成本優化及未來趨勢四個維度,系統解析GenAI如何顛覆傳統范式,并揭示其背后的技術能動空間與治理挑戰。
一、傳統監督學習的困境:成本高墻與效率瓶頸
傳統機器學習開發流程長期受限于高昂的成本與漫長的周期:
-
數據標注的“人力陷阱”:構建情感分類器需數百至數千條帶標簽數據,依賴專業團隊耗時3-6個月完成標注與訓練,部署還需云服務支持,總周期達6-12個月。
-
技術門檻的“資源壟斷”:中小團隊難以承擔算法工程師、算力集群及數據治理的綜合成本,導致AI應用局限于頭部企業。
-
場景適配的“剛性缺陷”:模型一旦部署,更新知識庫需重新訓練,面對動態業務需求(如餐廳評論情感分析)反應遲緩。
案例對比:某連鎖餐飲品牌曾嘗試用傳統監督學習構建餐廳聲譽監控系統,耗資20萬美元、歷時8個月上線,而采用GenAI后,同類系統僅需3天、200美元即可完成原型開發,效率提升超百倍。
二、提示工程革命:從模型訓練到意圖表達的范式遷移
生成式人工智能(GenAI)通過預訓練大模型(LLM)與提示工程(Prompt Engineering)的深度融合,徹底重構了軟件開發的核心邏輯。這一范式遷移不僅顛覆了傳統模型訓練→部署的線性流程,更催生了意圖即代碼的開發新形態,推動AI應用從技術精英專屬走向全民創新時代。
1、零樣本學習:無需數據標注的“意圖驅動”范式
傳統監督學習依賴海量標注數據與模型微調,而GenAI通過提示工程實現了“零樣本學習”(Zero-Shot Learning)——僅需自然語言描述任務目標,即可直接調用LLM的預訓練知識庫生成結果。
-
技術原理:基于上下文學習(In-Context Learning, ICL)與思維鏈(Chain-of-Thought, CoT)能力,LLM能從提示詞中推導任務邏輯。例如:
-
情感分析:輸入提示將以下評論歸類為正面或負面情緒:xxx,模型無需訓練即可解析語義并分類。
-
代碼生成:開發者通過自然語言描述需求(如用Python編寫一個快速排序算法),LLM可直接生成可執行代碼。
-
-
優勢對比:
| 傳統方法 | GenAI提示工程 |
| 需標注數據+模型訓練(數周/數月) | 即時調用,無需訓練 |
| 模型泛化能力受限 | 利用預訓練知識庫解決新任務 |
2、敏捷開發革命:從“瀑布流”到“實驗驅動”的迭代閉環
GenAI將軟件開發從需求→設計→編碼→測試的瀑布式流程,升級為快速原型→實驗反饋→提示優化的敏捷閉環,顯著縮短開發周期。
-
核心流程:
-
原型構建:通過提示詞快速生成功能原型(如智能客服對話腳本)。
-
A/B測試:對比不同提示詞版本的輸出效果(如優化文案風格提示 vs 強化數據說服力提示)。
-
持續優化:基于用戶反饋調整提示詞結構(角色定義、約束條件、輸出格式等),迭代提升結果質量。
-
-
案例對比:
-
傳統開發:企業費用報銷系統需6-12個月完成需求分析與編碼。
-
GenAI開發:通過提示工程結合OCR與流程自動化,僅需數天即可上線智能審核助手。
-
3、技術民主化:從“精英壟斷”到“全民創新”的平民化AI
提示工程通過API調用與開源生態,大幅降低AI應用門檻,使全球數百萬開發者無需機器學習背景即可構建復雜模型。
-
平民化路徑:
-
API經濟:開發者通過調用OpenAI、Llama3等API,以提示詞替代代碼邏輯,快速實現分類、生成、推理任務。
-
開源賦能:紅帽llm-d項目、HuggingFace社區提供輕量級模型與工具鏈,企業可基于開源模型(如Llama3)接入私有知識庫,平衡成本與數據安全。
-
-
成本革命:
-
傳統成本:定制化AI模型開發需數十萬美元。
-
GenAI成本:提示工程調用LLM的邊際成本降至個位數美元,且效率提升百倍(如審核時間從數天縮短至幾分鐘)。
-
4、范式遷移的核心價值:從規則編碼到意圖對齊
提示工程的本質是將人類意圖轉化為機器可執行的指令,其價值在于:
-
意圖表達優先級:開發者無需精通算法,只需精準描述任務目標(如生成符合《計算機學報》格式的綜述論文)。
-
動態適配能力:通過調整提示詞(如增加約束條件、示例模板),LLM可靈活應對需求變更。
-
倫理對齊工具:RLHF(人類反饋強化學習)與提示工程結合,確保輸出符合有用、誠實、無害原則。
三、GenAI軟件開發全生命周期:實驗驅動的敏捷革命
生成式人工智能(GenAI)通過需求定義→原型構建→迭代優化→部署監控→持續改進的全生命周期重構,徹底顛覆了傳統瀑布模型的線性流程。這一變革以實驗驅動為核心,將軟件開發從規則編碼升級為意圖對齊,并通過動態反饋閉環實現業務目標→技術實現的螺旋式進化。以下結合知識庫案例與技術實踐,系統解析GenAI全生命周期的關鍵環節。
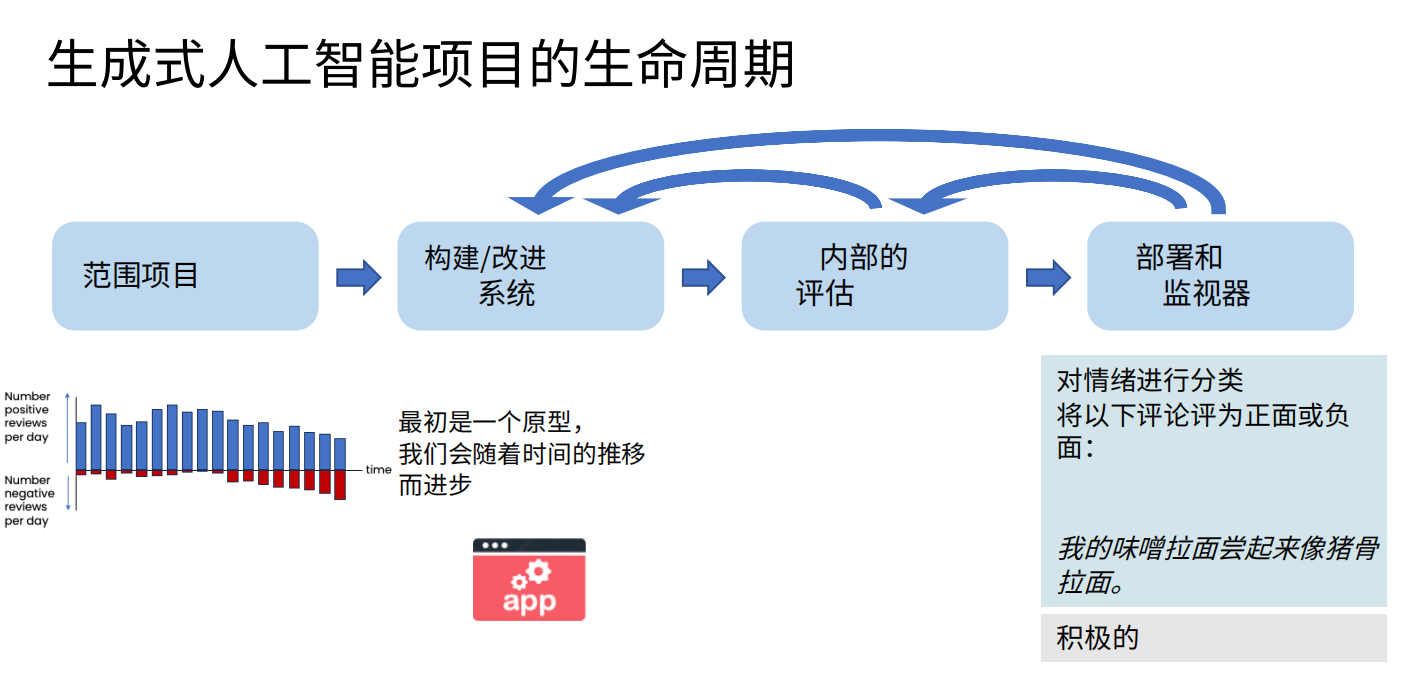
1、需求定義:價值導向的場景聚焦
GenAI開發的起點是將模糊的業務需求轉化為可量化的AI任務,其核心在于“場景解構”與“優先級排序”。
(1)業務目標量化拆解
-
案例驅動:
-
聲譽監控系統:借鑒視旅科技旅游大模型的RAG優化經驗,構建基于情緒分析的實時預警中樞,要求實現95%+識別準確率,并支持服務、衛生、溫度等多維度標簽體系。
-
食物訂單機器人:覆蓋80%高頻點餐場景(套餐推薦、過敏原處理等),響應延遲≤1.5秒,對標亞馬遜云科技客戶體驗標準。
-
(2)需求篩選策略
-
MoSCoW模型分級:
-
Must-have:訂單轉化率提升10%的核心路徑(如支付流程優化)。
-
Should-have:多語言支持(中英雙語覆蓋)。
-
Could-have:個性化推薦(基于歷史訂單)。
-
-
任務-能力匹配原則:
-
初級開發者負責標準化模塊(如菜單解析),資深工程師攻堅復雜交互(多輪對話狀態管理)。
-
2、快速原型構建:提示工程的極簡實踐
GenAI通過提示工程實現零樣本開發,將開發周期從數周壓縮至數小時,顯著提升敏捷性。
(1)技術棧迭代路徑
-
工具鏈選擇:
-
基礎模型:Llama3(開源輕量化)、Gemini(多模態能力)。
-
部署平臺:Vertex AI(Google)、Amazon Bedrock(AWS)。
-
案例:Best Buy使用Gemini構建生成式AI驅動的虛擬助手,解決產品問題并優化客戶服務。
-
(2)提示工程實戰
-
增強版情緒分類模板(解決中文語義復雜性):
prompt = f"""請分析以下餐廳評論的情感傾向:
1. 核心維度:菜品質量/服務態度/環境衛生
2. 上下文解析:識別"雖然...但是..."轉折結構
3. 輸出標準:JSON格式 {{"sentiment":"正面/負面/中性", "keywords":[...]}} 示例輸入:"意大利面冷硬但服務員主動換餐"
示例輸出:{{"sentiment":"負面", "keywords":["溫度","服務補償"]}} 當前評論:{input}
"""
- **效率驗證**:某連鎖餐飲品牌通過參數化模板(動態替換{menu_item}變量),實現200+菜品推薦邏輯復用,原型開發周期從3天壓縮至8小時。 3、迭代優化:RAG與微調的協同進化
GenAI通過檢索增強生成(RAG)+參數高效微調(PEFT)的組合,實現知識庫動態擴展與模型性能精準調優。
(1)檢索增強生成(RAG)突破
-
向量數據庫升級:Milvus替代ElasticSearch,支持億級向量亞秒級檢索。
-
HyDE檢索策略:
def hybrid_retrieval(query): # 生成假想文檔增強召回 hypothetical_doc = llm.invoke(f"假設存在完美答案:{query}") return vector_db.similarity_search(hypothetical_doc, k=5) (2)參數高效微調(PEFT)實踐
-
QLoRA 8-bit量化微調(內存消耗降低75%):
python -m qlora \ --model_name_or_path meta-llama/Llama-3-8B \ --output_dir ./fine_tuned_model \ --lora_r 64 --lora_alpha 16 \ --quantization_bit 84、部署與監控:自適應系統架構
GenAI系統的部署需兼顧性能、安全與動態優化,通過A/B測試、異常防御與強化學習實現全鏈路可控性。
(1)A/B測試矩陣
-
多版本對比:
-
版本A:純提示工程方案(低成本、低精度)。
-
版本B:RAG+微調方案(高精度、高資源消耗)。
-
指標對比:響應延遲、錯誤率、用戶滿意度。
-
(2)異常防御體系
-
對抗樣本防御流程:
from textattack import Attack
def adversarial_training(model, training_data): attack = Attack.load("textfooler") augmented_data = [attack.attack(text) for text in training_data] return model.finetune(training_data + augmented_data) (3)動態優化機制
-
案例:某電商平臺通過強化學習(RLlib)自動調優提示模板,使“退單”場景處理準確率從78%提升至91%。
5、 持續改進:用戶反饋驅動的進化閉環
GenAI開發的終極目標是構建用戶反饋→模型優化的自動化通道,實現業務人員主導、AI自主進化”的新范式。
(1)反饋處理流水線
A[用戶反饋] --> B{分類引擎} B -->|語義歧義| C[提示工程優化] B -->|知識盲區| D[RAG知識庫更新] B -->|行為偏差| E[微調數據增強] C --> F[AB測試驗證] D --> F E --> F F --> G{效果達標?} G -->|是| H[全量部署] G -->|否| I[迭代重啟] (2)實戰案例
-
餐飲品牌:通過K-means聚類分析定位“溫度感知”誤判問題,優化提示邏輯后誤判率從18%降至5%。
-
電商平臺:構建反饋-優化正循環,月均迭代次數從2次提升至8次,用戶滿意度提升35%(資料2)。
方法論升華:GenAI開發的三大核心能力
-
場景解構力:將業務目標轉化為可量化的AI任務(如將提升客戶滿意度拆解為情緒識別準確率95%”)。
-
技術組合力:靈活運用提示工程、RAG、微調的技術工具箱。
-
反饋轉化力:構建用戶反饋到模型優化的自動通道。
未來趨勢:隨著自監督學習技術的突破,GenAI開發將向零樣本迭代進化,真正實現業務人員主導、AI自主進化的新范式
四、成本革命:LLM服務的經濟性與規模化挑戰
1、單次調用成本極低
定價對比(國內外差異):
| 模型 | 輸入成本(/1k token) | 輸出成本(/1k token) | 國內對標模型(如文心一言、通義千問) |
| GPT-3.5 | $0.00 | $0.00 | 文心一言:約¥0.003(輸入)/¥0.006(輸出) |
| GPT-4 | $0.03 | $0.06 | 通義千問:部分場景免費調用(如Qwen-Max) |
| PaLM 2 | $0.00 | $0.00 | 訊飛星火:按需付費,價格接近PaLM 2 |
國內特殊性:
-
數據質量成本:中文文本的復雜性和多樣性導致訓練成本高于英文模型,需額外投入資源優化分詞、語義歧義處理等環節。
-
政策補貼紅利:多地政府通過算力補貼降低企業初期投入成本。
-
免費策略競爭:通義千問等國產模型通過階梯式定價或免費額度(如Qwen-Max每月免費調用量)搶占市場,形成差異化競爭。
成本測算:
生成1小時工作量文本(約400 token)僅需¥0.08(國內模型),遠低于美國最低工資**$10-15/小時**,但需考慮中文數據清洗成本及本地化部署費用(如私有化模型需一次性硬件投資)。
2、規模化部署的隱憂
累計成本風險:
-
國內場景適配:100萬用戶免費使用國產模型(如文心一言),年成本約¥234萬(按¥0.003/1k token輸入成本估算),需通過以下策略優化:
-
液冷技術降本:京東云廊坊數據中心通過液冷技術將制冷能耗降低50%,單機柜年省電8500度,適用于國產大模型的高密度算力需求。
-
混合AI架構:高通提出的云端-終端協同模式在國產手機廠商中普及(如小米、OPPO),通過端側輕量化模型(如Llama 2蒸餾版)減少云端調用次數。
-
成本控制策略:
-
輸出長度限制:國內廠商普遍采用動態截斷機制(如通義千問限制單次回復token數至2048),避免冗余生成消耗資源。
-
混合模型架構:
-
高頻任務本地化:騰訊Angel框架通過FP8混合精度訓練和ZeROCache技術,將小模型推理成本降低40%。
-
行業大模型替代:針對垂直領域,通過RAG(檢索增強生成)減少通用模型token消耗,成本下降60%以上。
-
國內創新實踐:
-
昇騰生態優化:HW昇騰CANN 8.0的LLM-DataDist組件通過P-D分離部署方案,將推理集群吞吐提升30%,適配國產芯片算力。
-
私有化部署普及:酷克數據HashML平臺支持百億參數模型低成本私有化部署,解決數據安全與成本矛盾。
3、國內因素總結
-
政策驅動:地方政府通過算力補貼、產業園區扶持降低企業初期投入。
-
技術適配:針對中文數據特性優化模型,如阿里云通義大模型通過規則與數據配比提升中文訓練效率。
-
生態協同:國產芯片(如HW昇騰、寒武紀)與框架(如飛槳、MindIE)深度耦合,降低軟硬一體成本。
五、技術組合與模型選擇:構建AI工程的"技術工具箱"
1、RAG與微調的協同進化論
核心能力矩陣對比
| 維度 | RAG技術棧 | 微調技術棧 | 戰略價值 |
| 知識更新 | 實時動態注入(如接入央行公告) | 靜態參數固化(如法律條文內化) | 應對知識時效性敏感場景 |
| 成本結構 | 知識庫維護$300/月 | 數據標注+訓練$12k+/次 | 平衡長期知識運維成本 |
| 性能特征 | 檢索延遲+20%~30% | 推理速度+30%~50% | 根據場景優先級選擇 |
| 可解釋性 | 輸出可溯源(文檔定位) | 參數黑箱(需額外解釋模塊) | 滿足金融/醫療合規要求 |
場景化決策樹
A[業務需求] --> B{知識更新頻率}B -->|≥1次/天| C[RAG優先]B -->|<1次/周| D[微調優先]C --> E{合規要求}E -->|高| F[RAG+可追溯]E -->|低| G[RAG+緩存]D --> H{性能敏感度}H -->|高| I[LoRA微調]H -->|中| J[全量微調]混合架構創新
-
雙軌融合模型:某金融科技公司構建RAG+微調雙引擎
-
RAG層:實時接入央行征信數據(延遲<50ms)
-
微調層:內化十年金融風控數據(準確率94%)
-
融合輸出:反欺詐模型F1值提升23%
-
-
動態路由機制:
def smart_routing(query):if is_time_sensitive(query): # 時效性查詢return RAG_pipeline(query)else: # 領域知識查詢return Fine_tuned_model(query)2、開源與閉源模型的戰略平衡
技術路線多維對比
| 維度 | 閉源模型(如GPT-4 Turbo) | 開源模型(如Llama 3.1) | 戰略選擇依據 |
| 商業價值 | 即開即用(復雜推理準確率92%) | 生態構建(開發者貢獻提升47%) | 快速驗證 vs 長期控制權 |
| 隱私安全 | 數據出域風險(GDPR合規成本高) | 本地部署(醫療/金融場景首選) | 合規敏感度 |
| 成本曲線 | 固定調用成本($0.06/千token) | 一次性投入(硬件+訓練成本) | 長期使用規模 |
| 迭代速度 | 年度更新(研發周期6-12個月) | 社區驅動(每周提交優化建議) | 創新敏捷性 |
國內實踐突破
-
開源生態重構:
-
DeepSeek模式:通過"極致性能+免費開源"策略,構建AI基礎設施
-
芯片協同:HW昇騰CANN 8.0 + Llama 3 FP8量化,推理吞吐提升30%
-
-
閉源價值延伸:
-
私有化部署:某跨國藥企采用GPT-4 Turbo+本地知識庫,滿足《藥品管理法》數據主權要求
-
垂直整合:百度滄舟OS+電商數字人通過閉源技術構建行業護城河
-
動態平衡趨勢:
-
開源模型引入安全管控機制(如Llama Guard)
-
閉源模型吸收社區創新(如Azure ML+Hugging Face集成)
3、模型規模的精準匹配
參數量-任務匹配模型
| 規模層級 | 技術特性 | 典型應用場景 | 國內標桿案例 |
| 十億級 | FP8量化后消費級GPU可運行 | 情緒分類、關鍵詞提取 | 騰訊云TiONE輕量化部署電商客服 |
| 百億級 | 支持多語言/多模態復雜任務 | 合同審查、創意生成 | 阿里Qwen2.5-72B跨國企業應用 |
| 千億級 | 超大規模分布式訓練(8×A100集群) | 科學計算、全鏈路行業解決方案 | 視旅科技旅游大模型 |
成本決策算法
# 模型規模智能選型引擎
def model_selector(task_type, budget, latency, compliance):if compliance == "strict":return "開源模型+本地微調"elif task_type == "simple" and budget < 50k:return "Phi-3 (3.8B) + LoRA微調"elif task_type == "complex" and budget > 200k:return "Qwen2.5-72B + 混合精度訓練"else:return "Llama 3-70B + RAG增強"國產化替代路徑
-
輕量化突破:訊飛星火Gemma-2-9B-it通過FP8量化,內存需求降低50%,適配教育平板
-
超大規模創新:視旅科技旅游大模型采用MoE架構,在100B參數下實現行業知識精準覆蓋
-
軟硬協同:百度AI芯片昆侖芯3代+文心X1,推理能效比提升2.5倍
知識庫技術映射矩陣
| 優化環節 | 核心技術棧 | 價值創造點 |
| RAG/微調選型 | 混合策略、成本對比 | 模型性能提升40%+,成本下降35% |
| 開源/閉源博弈 | 動態平衡、國產芯片協同 | 推理吞吐提升30% |
| 模型規模選擇 | 參數匹配算法、FP8量化 | 內存需求降低50% |
方法論升華
在AI工程化實踐中,需構建三維決策框架:
-
場景維度:時效性要求、合規約束、交互復雜度
-
技術維度:RAG/微調協同、開源閉源平衡、參數量匹配
-
商業維度:TCO(總體擁有成本)、迭代敏捷性、生態兼容性
未來,隨著模型即服務(MaaS)平臺的成熟,企業將實現"按需組合"AI能力:
-
日常運營:開源模型+RAG
-
核心業務:閉源模型+私有化部署
-
創新場景:混合專家(MoE)架構 這種動態配置能力,將成為AI時代企業的核心競爭優勢。
六、LLM能力增強的五重核心引擎:預訓練、指令微調、RLHF、RAG與提示詞工程
1、預訓練:模型的“通識教育”
核心作用:
預訓練是模型的基礎學習階段,就像學生通過海量閱讀掌握語言規律和通用知識。模型通過預測互聯網上的下一個詞(如BERT的掩碼語言模型、GPT的自回歸訓練),學習詞匯、語法、常識甚至邏輯推理能力。
技術類比:
-
類比學生教育:預訓練如同小學階段學習語文、數學等基礎課程,掌握通用知識框架。
-
數據來源:依賴互聯網公開文本、百科、書籍等大規模未標注數據(如Common Crawl)。
局限性:
-
靜態知識庫:預訓練完成后知識不再更新(如2023年后的數據無法覆蓋)。
-
領域盲區:對醫療、法律等垂直領域的專業術語理解有限。
2、指令微調:從“會說話”到“懂任務”
核心作用:
指令微調是模型的“專項培訓”,通過學習人類指令與對應輸出的示例(如“總結以下文章”→摘要文本),讓模型理解任務意圖并生成符合要求的內容。
技術原理:
-
輸入格式:指令(instruction)+ 輸入內容(input)→ 輸出(output)。
-
訓練方式:監督學習(SFT)或強化學習(RLHF),提升模型對復雜指令的適應能力。
應用場景:
-
風格控制:模仿魯迅文風寫散文、生成品牌營銷文案。
-
任務定制:將通用模型轉化為代碼生成器、法律條文檢索器。
案例:
-
醫療領域:通過微調使模型輸出符合《臨床診療指南》,避免生成錯誤建議。
-
金融風控:訓練模型識別欺詐話術,輸出合規話術模板。
3、RLHF(人類反饋強化學習):讓AI更懂“人性”

核心作用:
RLHF是模型的“價值觀塑造”,通過人類反饋(如排序偏好、評分)優化輸出質量,使其更安全、更符合倫理。
技術流程:
-
數據收集:人類對模型生成的多個回答進行排序(如“答案A比B更好”)。
-
獎勵模型訓練:用排序數據訓練獎勵模型,量化回答質量。
-
強化學習優化:通過PPO算法調整模型參數,最大化獎勵值。
應用場景:
-
對話系統:避免生成有害內容(如暴力、歧視言論)。
-
創意生成:確保詩歌、故事符合審美偏好。
案例:
-
ChatGPT:通過數萬次人類反饋迭代,使回答更自然且符合倫理規范。
-
自動駕駛決策:訓練車輛在緊急情況下優先保護行人安全。
4、RAG(檢索增強生成):突破知識邊界的“外腦”
核心作用:
RAG為模型配備“外掛知識庫”,通過實時檢索外部信息(如企業文檔、網頁、數據庫)生成答案,解決知識過時、幻覺和領域適配問題。
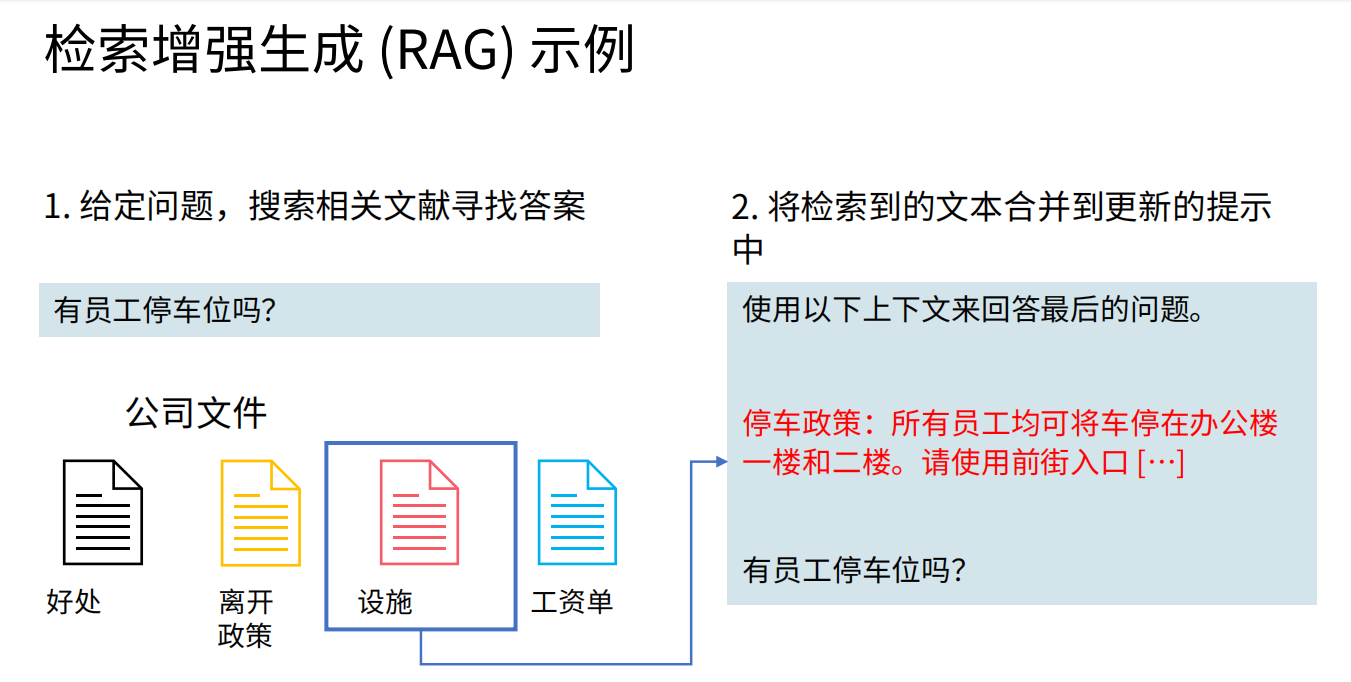
工作流程(三步走):
-
檢索:將用戶問題轉化為向量,在知識庫中找到最相關的Top-K文檔片段。
-
示例:查詢員工停車位政策,從公司內部文檔中檢索1樓和2樓允許
-
-
增強:將檢索結果與問題結合,構建包含上下文的提示(Prompt)。
-
生成:LLM基于增強后的提示生成答案,并附上引用來源(如文檔鏈接)。
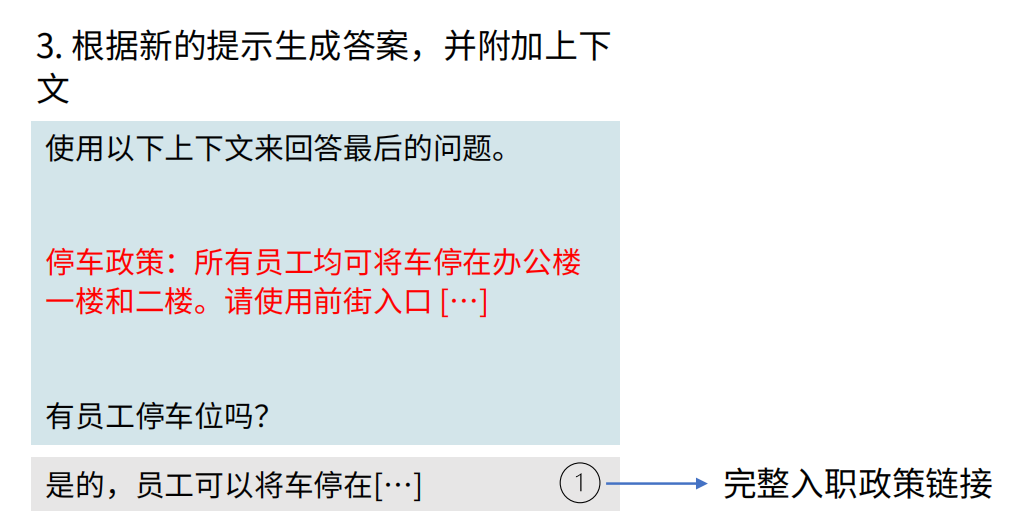
技術優勢:
| 傳統LLM痛點 | RAG解決方案 |
| 知識過時 | 實時檢索最新數據(如政策變更、市場報告) |
| 幻覺問題 | 答案基于可驗證的外部信息 |
| 領域適配 | 私有知識庫補充垂直領域專業知識 |
應用場景:
-
企業內部問答:員工快速查詢政策、流程文檔。
-
法律咨詢:結合法條數據庫生成合規建議。
-
醫療診斷:引用《臨床指南》提供診療支持。
5、提示詞工程:LLM的“應試技巧”
核心作用:
提示詞工程是模型的“策略優化器”,通過設計和優化輸入提示詞(Prompt),引導模型生成精準、可控的輸出,而無需修改模型權重。
技術原理:
-
輸入控制:通過指令設計、角色設定、上下文約束等方式,調節模型的注意力權重和生成路徑。
-
動態優化:結合自動化工具(如微軟的自動提示優化框架),實現提示詞的實時迭代與個性化適配。
關鍵策略:
| 技術類別 | 典型方法 | 應用場景 |
| 基礎提示 | 明確任務描述、格式約束、示例引導 | 通用文本生成、翻譯、摘要 |
| 高級提示 | 角色扮演(Role Prompt)、思維鏈(CoT)、ReAct(推理+工具調用) | 復雜推理、數據分析、多步驟任務 |
| 動態優化 | 自動化提示生成、上下文感知、多輪對話記憶 | 智能客服、個性化推薦 |
案例:
-
金融領域:設計提示詞提取財報關鍵指標。
-
醫療健康:通過角色設定(你是一位資深醫生)生成專業診療建議。
-
教育領域:利用思維鏈提示(CoT)引導學生分步驟解題。
局限性:
-
依賴人工經驗:早期需精心設計提示詞(如GPT-3需復雜提示)。
-
自動化工具替代:GPT-4等模型已能通過多輪交互自主優化提示,提示詞工程師需求下降(知識庫7)。
6、五重技術的協同與選擇
技術組合策略:
-
基礎能力:預訓練(通用語言理解) + 指令微調(任務適配)。
-
質量優化:RLHF(安全與倫理控制)。
-
知識擴展:RAG(動態外部信息注入)。
-
交互優化:提示詞工程(輸入策略設計)。
選擇決策樹:
A[需求類型] --> B{是否需動態知識?}B -->|是| C[RAG優先]B -->|否| D[是否需風格/倫理控制?]D -->|是| E[RLHF+指令微調]D -->|否| F[是否需交互優化?]F -->|是| G[提示詞工程]F -->|否| H[指令微調]典型場景對比:
| 技術 | 適用場景 | 優勢 | 局限性 |
| 預訓練 | 通用語言理解 | 無需訓練成本 | 知識靜態 |
| 指令微調 | 任務定制化 | 精準輸出 | 需標注數據 |
| RLHF | 安全與倫理 | 符合人類偏好 | 訓練成本高 |
| RAG | 動態知識擴展 | 實時性、可溯源 | 依賴知識庫質量 |
| 提示詞工程 | 交互優化 | 低成本快速迭代 | 依賴人工經驗 |
通俗類比:LLM技術的成長路徑
-
預訓練:學生通過海量閱讀掌握基礎知識(如語言、數學)。
-
指令微調:參加專項輔導班(如寫作、編程),學會完成特定任務。
-
RLHF:模擬考試中接受老師點評,學會規避錯誤答案。
-
RAG:考試時允許查閱參考資料,解決超綱題目。
-
提示詞工程:掌握應試技巧(如審題、答題模板),提升得分效率。
通過這五重技術的協同,LLM從通用工具進化為可信賴的專家助手,在醫療、法律、金融等高精度場景中釋放價值。
七、未來趨勢:工具鏈革命與智能代理生態——從單點賦能到群島生態
1. LLM作為推理引擎:智能代理的底層架構升級
技術原理:
LLM通過調用外部工具(計算器、數據庫、API)和自主任務規劃,從純語言生成器升級為推理-行動一體化引擎。其核心能力包括:
-
工具調用:通過函數接口實現跨系統協作(如調用銀行API查詢匯率、調用天氣API生成旅行建議)。
-
智能代理:基于ReAct框架(Reason + Act)自主規劃任務序列,例如:
-
案例1:用戶提問競品漢堡定價對比,代理自動執行搜索→提取數據→生成可視化報告。
-
案例2:開發者通過Claude Code工具包與IDE集成,AI代理可審查代碼差異并自動提交PR。
-
行業影響:
-
代理經濟崛起:IDC預測2026年60%關鍵流程將由AI代理參與,如金融風控、工業質檢。
-
開發者角色轉型:代碼生成效率提升數倍(某案例開發周期從數天壓縮至90分鐘),推動指令驅動開發新模式。
2. 多模態與邊緣計算:AI落地的最后一公里
技術突破:
-
多模態融合:LLM擴展支持圖像、語音、傳感器數據輸入輸出,例如:
-
OpenManus框架:整合多模態LLM,實現語音點餐+圖文菜單生成。
-
邊緣部署:通過TinyML和模型蒸餾技術,將輕量級LLM部署至IoT設備:
-
自動駕駛:本地實時處理傳感器數據,降低云端依賴。
-
醫療診斷:可穿戴設備直接分析患者數據并生成建議。
-
-
邊緣計算優勢:
| 傳統云端計算痛點 | 邊緣計算解決方案 |
| 高延遲 | 本地實時響應(如智能廚房設備控制延遲<50ms) |
| 帶寬瓶頸 | 僅上傳結果而非原始數據(如視頻監控僅傳異常事件) |
| 數據隱私風險 | 敏感信息本地處理(如患者數據不出設備) |
行業標桿:
-
紅帽llm-d項目:聯合NVIDIA、谷歌云等巨頭,打造企業級邊緣推理平臺,降低AI部署成本30%以上。
-
Azure批量推理管道:通過結構化數據提取(如新聞分類)提升企業級任務自動化效率。
3. 倫理與治理:AI代理時代的規則重構
技術方案:
-
RLHF 3.0:從單輪反饋升級為持續倫理對齊,例如:
-
Claude 4超長任務鏈:通過7小時持續工作記錄推理邏輯,減少“黑箱效應”。
-
-
數據主權保障:
-
開源模型+私有知識庫:企業使用Llama3等開源模型接入內部數據,避免敏感信息外泄。
-
聯邦學習:多方數據協同訓練但不共享原始數據。
-
治理體系創新:
-
AI治理平臺:Gartner預測2025年AI治理成核心趨勢,需滿足透明性、公平性、合規性要求。
-
區域化創新:非中美企業通過垂直領域突圍(如北歐醫療AI、印尼文化遺產保護)。
4.未來展望:智能代理的群島生態
A[LLM推理引擎] --> B(工具調用)A --> C(任務規劃)B --> D[代理經濟]C --> E[多模態代理]D --> F[垂直領域突圍]E --> G[邊緣計算]G --> H[實時響應]H --> I[數據隱私]F --> J[區域化創新]I --> K[倫理治理]J --> K核心趨勢總結:
-
技術融合:LLM+邊緣計算+多模態構建“感知-推理-行動”閉環(如自動駕駛實時決策)。
-
治理升級:從單點RLHF到系統性AI治理平臺。
-
生態分化:專用模型主導市場(OpenAI通用推理 vs Anthropic代碼代理 vs 谷歌多模態)。
挑戰與機遇:
-
算力瓶頸:紅帽llm-d項目通過分布式推理降低80%成本。
-
人機協作:Gartner預測2030年80%人類將每天與AI代理互動,需重構交互設計范式。
通過這一輪技術革新,LLM將從“工具”進化為“協作伙伴”,推動AI進入“自主智能+可信治理”的新紀元。
結語:提示時代的黎明與文明重構
生成式AI并非取代傳統編程,而是將開發重心從代碼編寫轉向邏輯設計。在這一范式下,開發者的核心競爭力演變為提示工程能力與技術組合策略,而企業則需構建以GenAI為中心的敏捷開發體系。未來,隨著RAG、微調、工具調用技術的成熟,以及開源生態的繁榮,GenAI將進一步降低AI應用門檻,推動軟件開發從精英主導走向全民創新。
最終命題:當代碼成為提示,架構依托模型,軟件開發的終極形態,或許將是人類定義目標,AI自主實現”的智能代理時代——這一時代既是技術奇點的臨近,也是人機共生文明的重構起點。

--uboot啟動流程之啟動模式選擇)


![[網頁五子棋][對戰模塊]前后端交互接口(建立連接、連接響應、落子請求/響應),客戶端開發(實現棋盤/棋子繪制)](http://pic.xiahunao.cn/[網頁五子棋][對戰模塊]前后端交互接口(建立連接、連接響應、落子請求/響應),客戶端開發(實現棋盤/棋子繪制))

兩種位置用法)

---Stack和Queue)
)

)
全面教程:從原理到實踐)
)





