
IP-Adapter:圖像提示適配器的技術解析與實踐指南
- 一、項目背景與技術價值
- 1.1 圖像生成中的個性化控制需求
- 1.2 IP-Adapter的核心貢獻
- 二、技術原理深度解析
- 2.1 整體架構設計
- 2.2 圖像特征編碼器
- 2.3 訓練策略
- 三、項目部署與實戰指南
- 3.1 環境配置
- 3.2 模型下載
- 3.3 基礎生成示例
- 3.4 進階應用:多條件控制
- 四、常見問題與解決方案
- 4.1 CUDA內存不足
- 4.2 圖像風格遷移失效
- 4.3 與其他LoRA模型沖突
- 五、相關論文與技術延展
- 5.1 核心論文解讀
- 5.2 擴展應用方向
- 六、總結與展望
一、項目背景與技術價值
1.1 圖像生成中的個性化控制需求
近年來,基于擴散模型(Diffusion Model)的圖像生成技術(如Stable Diffusion、DALL·E)在生成質量上取得了突破性進展。然而,現有模型在細粒度圖像控制上仍面臨挑戰:
- 文本描述的局限性:文本難以精確描述復雜構圖、風格細節或特定物體形態。
- 參考圖像的條件融合:如何將參考圖像的特征(如主體外觀、藝術風格)無縫融入生成過程,是提升可控性的關鍵。
1.2 IP-Adapter的核心貢獻
騰訊AI Lab提出的IP-Adapter通過解耦的圖像提示適配器(Image Prompt Adapter),實現了以下創新:
- 輕量級適配:僅需訓練少量參數(<100M),即可將圖像條件注入預訓練擴散模型。
- 兼容性:支持與現有控制模塊(如ControlNet)聯合使用,實現多條件控制。
- 零樣本泛化:適配器在訓練后無需微調,可直接應用于不同風格的生成任務。
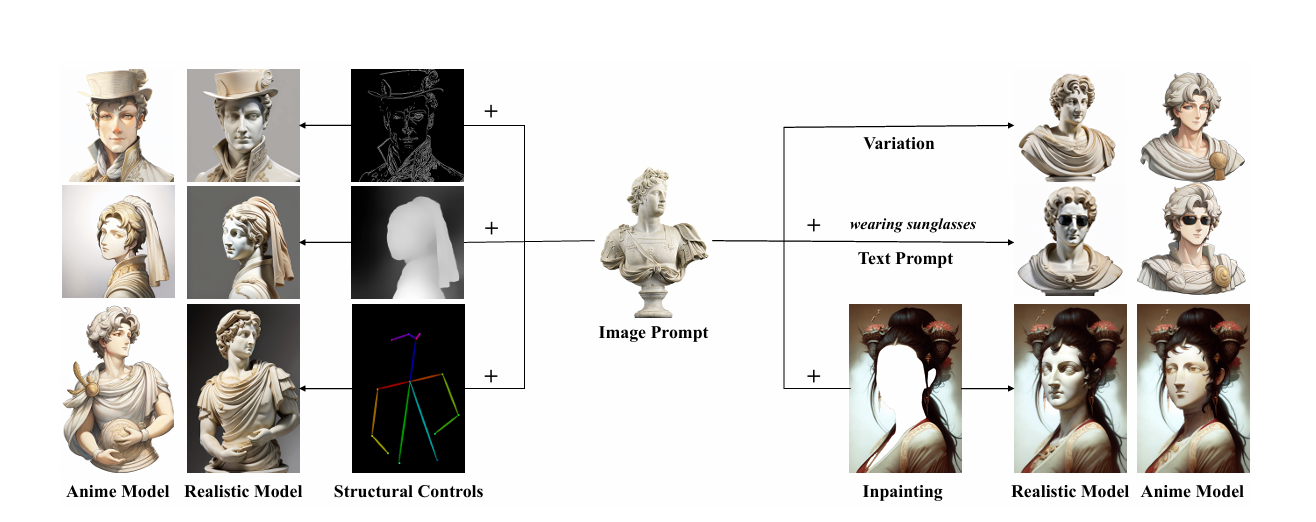
二、技術原理深度解析
2.1 整體架構設計
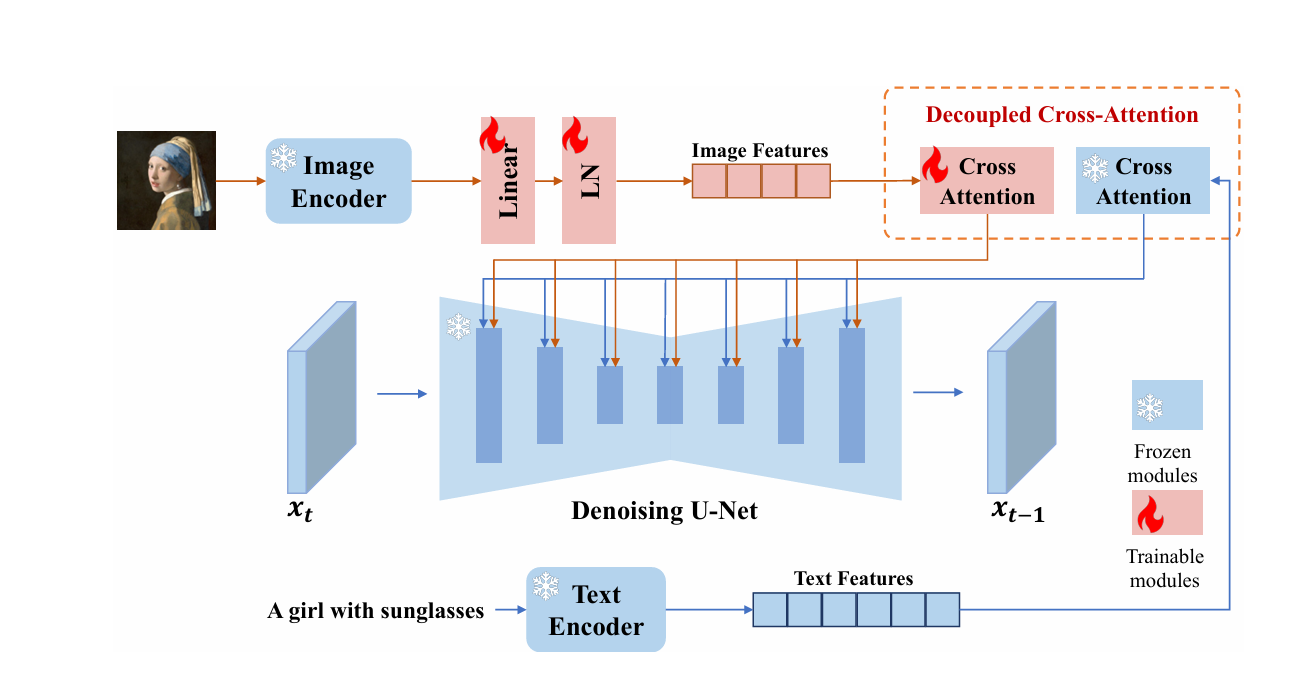
IP-Adapter的核心是一個雙路特征編碼器,將圖像提示與文本提示解耦處理,再通過交叉注意力機制融合:
CrossAttn ( Q , K , V ) = Softmax ( Q K T d ) V \text{CrossAttn}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V CrossAttn(Q,K,V)=Softmax(d?QKT?)V
其中:
- Q Q Q:擴散模型UNet的查詢向量(Query)
- K , V K, V K,V:由圖像提示特征 f i m g f_{img} fimg? 和文本提示特征 f t x t f_{txt} ftxt? 拼接生成
# 偽代碼示例:特征融合
image_features = clip_image_encoder(reference_image)
text_features = clip_text_encoder(prompt)
combined_features = concat(image_features, text_features)
q = unet_query_layer(hidden_states)
k = linear_projection(combined_features)
v = linear_projection(combined_features)
attention_output = softmax(q @ k.T / sqrt(d)) @ v
2.2 圖像特征編碼器
IP-Adapter采用CLIP圖像編碼器提取參考圖像的語義特征,并通過可學習的投影層將其映射到擴散模型的嵌入空間:
f i m g = W p r o j ? CLIP-ViT ( I r e f ) f_{img} = W_{proj} \cdot \text{CLIP-ViT}(I_{ref}) fimg?=Wproj??CLIP-ViT(Iref?)
- W p r o j W_{proj} Wproj?:可訓練權重矩陣(維度適配)
- I r e f I_{ref} Iref?:參考圖像輸入
2.3 訓練策略
- 目標函數:最小化生成圖像與目標圖像的像素級差異和語義差異:
L = λ MSE ∥ x gen ? x gt ∥ 2 2 + λ CLIP D cos ( f gen , f gt ) \mathcal{L} = \lambda_{\text{MSE}} \|x_{\text{gen}} - x_{\text{gt}}\|_2^2 + \lambda_{\text{CLIP}} \mathcal{D}_{\text{cos}}(f_{\text{gen}}, f_{\text{gt}}) L=λMSE?∥xgen??xgt?∥22?+λCLIP?Dcos?(fgen?,fgt?) - 兩階段訓練:
- 固定預訓練擴散模型,僅訓練適配器參數。
- 聯合微調解碼器部分層,提升生成細節。
三、項目部署與實戰指南
3.1 環境配置
系統要求:
- CUDA 11.7+
- PyTorch 2.0+
- xFormers(可選,用于加速注意力計算)
安裝步驟:
# 創建虛擬環境
conda create -n ip_adapter python=3.9
conda activate ip_adapter# 安裝基礎依賴
pip install torch==2.0.1 torchvision==0.15.2 --extra-index-url https://download.pytorch.org/whl/cu117# 克隆倉庫
git clone https://github.com/tencent-ailab/IP-Adapter.git
cd IP-Adapter# 安裝項目依賴
pip install -r requirements.txt
3.2 模型下載
IP-Adapter提供多個預訓練模型,需手動下載至指定目錄:
mkdir -p models/ip-adapter
wget https://huggingface.co/tencent-ailab/IP-Adapter/resolve/main/ip-adapter_sd15.bin -P models/ip-adapter
wget https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors -P models/stable-diffusion
3.3 基礎生成示例
from PIL import Image
from pipelines import StableDiffusionIPAdapterPipeline# 初始化Pipeline
pipe = StableDiffusionIPAdapterPipeline.from_pretrained("models/stable-diffusion/v1-5-pruned-emaonly.safetensors",ip_adapter_path="models/ip-adapter/ip-adapter_sd15.bin"
).to("cuda")# 加載參考圖像
reference_image = Image.open("examples/dog.jpg")# 生成圖像
prompt = "A cartoon dog wearing sunglasses, high quality"
generated_image = pipe(prompt=prompt,ip_adapter_image=reference_image,num_inference_steps=30,guidance_scale=7.5
).images[0]generated_image.save("output.jpg")
3.4 進階應用:多條件控制
IP-Adapter可與ControlNet結合,實現圖像提示+空間約束的聯合控制:
from controlnet import ControlNetModel# 加載ControlNet模型
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
pipe.controlnet = controlnet# 生成帶邊緣約束的圖像
canny_image = Image.open("edge_map.png")
generated_image = pipe(prompt=prompt,ip_adapter_image=reference_image,controlnet_condition=canny_image,controlnet_guidance=1.0
).images[0]
四、常見問題與解決方案
4.1 CUDA內存不足
錯誤信息:
RuntimeError: CUDA out of memory.
解決方案:
- 減小
batch_size(默認1→1)。 - 啟用
xFormers優化:pipe.enable_xformers_memory_efficient_attention() - 使用半精度(FP16):
pipe = pipe.to(torch.float16)
4.2 圖像風格遷移失效
現象:生成結果未繼承參考圖像風格。
調試步驟:
- 檢查圖像編碼器是否正常:
features = pipe.ip_adapter.image_encoder(reference_image) print(f"Feature shape: {features.shape}") # 應為 [1, 768] - 調整
ip_adapter_scale參數(默認1.0,可嘗試0.5~1.5)。
4.3 與其他LoRA模型沖突
現象:同時加載多個適配器時生成結果異常。
解決方案:
- 確保不同適配器的特征維度一致。
- 使用權重融合策略:
merged_weights = 0.7 * ip_adapter_weights + 0.3 * lora_weights pipe.load_adapter(merged_weights)
五、相關論文與技術延展
5.1 核心論文解讀
-
IP-Adapter原論文:
《IP-Adapter: Image Prompt Adapter for Text-to-Image Diffusion Models》
創新點:- 提出解耦的圖像提示編碼,避免與文本特征的空間耦合。
- 通過特征歸一化(Feature Normalization)提升跨數據集泛化能力。
-
對比研究:
方法 參數量 訓練數據需求 兼容性 Textual Inversion ~10KB 3-5樣本 僅限特定概念 ControlNet ~1.5B 大規模配對數據 需重新訓練 IP-Adapter ~70M 中等規模 即插即用
5.2 擴展應用方向
- 視頻生成:將IP-Adapter擴展至時序生成,實現視頻風格遷移。
- 3D生成:結合NeRF,從單張參考圖像生成3D模型。
- 醫療影像:基于醫學圖像提示生成病灶描述報告。
六、總結與展望
IP-Adapter通過輕量化的適配器設計,顯著提升了擴散模型的可控生成能力。其技術路徑為后續研究提供了重要啟示:
- 模塊化設計:將條件控制與基礎生成模型解耦,提升靈活性和可擴展性。
- 高效訓練:小樣本微調策略降低了對標注數據的依賴。
未來方向可能包括:
- 動態權重分配:根據輸入內容自動調節圖像/文本提示的貢獻權重。
- 多模態融合:結合音頻、視頻等多維度條件輸入。




 的區別和聯系)




![【python實用小腳本-79】[HR轉型]Excel難民到數據工程師|用Python實現CSV秒轉JSON(附HRIS系統對接方案)](http://pic.xiahunao.cn/【python實用小腳本-79】[HR轉型]Excel難民到數據工程師|用Python實現CSV秒轉JSON(附HRIS系統對接方案))


——機器人主控程序 main.py — aloha_real)


)


)
