持續更新中
- 一、LORA篇
- 1、介紹一下Lora的原理
- 2、LoRA 是為了解決什么問題提出的?哪些模型適合用 LoRA 微調?什么是低秩分解?
- **低秩分解:用小矩陣逼近大矩陣**
- 3、LoRA初始化
- 4、LoRA初始化秩 r 是怎么選的?為什么不選其他值?
- 📌 一般經驗:
- 5、LoRA家族
- 5.1 LoRA+
- 4.2 VeRA
- 4.3 QLoRA
一、LORA篇
1、介紹一下Lora的原理
LoRA 是一種參數高效微調方法,其核心思想是將原始權重矩陣的更新限制在一個低秩空間內,從而顯著減少訓練參數量。
不同于傳統微調,LoRA 將權重的更新項 Δ W \Delta W ΔW 表示為兩個低秩矩陣 A ∈ R r × d A \in \mathbb{R}^{r \times d} A∈Rr×d 和 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r 的乘積:
W ′ = W + Δ W = W + B A W' = W + \Delta W = W + BA W′=W+ΔW=W+BA
訓練階段只更新兩個低秩矩陣 A A A 和 B B B ,原始模型權重 W W W 保持不變;
2、LoRA 是為了解決什么問題提出的?哪些模型適合用 LoRA 微調?什么是低秩分解?
- LoRA 的核心目標:降低大模型微調成本 參數量從 O ( d 2 ) O(d^2) O(d2) → O ( r d ) O(rd) O(rd)
- 適合含大量線性層的 Transformer 架構模型 比如注意力模塊的
Q/K/V投影矩陣、FFN前饋神經網絡等
低秩分解:用小矩陣逼近大矩陣
定義:低秩分解是將高維矩陣近似為兩個低維矩陣的乘積,以降低表示復雜度。
數學形式:對于 d × d d \times d d×d 的高維矩陣 W W W,找到兩個低維矩陣 A ∈ R r × d A \in \mathbb{R}^{r \times d} A∈Rr×d 和 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r 的乘積,使得:
W ≈ B A W \approx BA W≈BA
- (A) 是 降維矩陣:將原始 d d d 維空間映射到 r r r 維子空間(提取關鍵特征)。
- (B) 是 升維矩陣:將 $r$ 維特征恢復到 d d d 維空間(重構原始空間的更新)。
- 優勢:通過僅優化 (A) 和 (B) 的 2 r d 2rd 2rd 個參數(遠小于 d 2 d^2 d2),即可近似表達 (W) 的主要變化,大幅減少計算量。
3、LoRA初始化
LoRA 的初始化通常遵循以下原則:
原始模型權重 W 不變
LoRA 的矩陣:
- A A A 通常使用正態分布初始化:
nn.Linear(..., bias=False)默認初始化- B B B 通常初始化為 全零矩陣,這樣一開始 Δ W = B A = 0 \Delta W = B A = 0 ΔW=BA=0,模型輸出不會被擾動,保證收斂穩定性
如果A也初始化成0,這樣都沒法更新了。對于
對于 y = B A x y = B A x y=BAx:
- 對 B 的梯度: ? L ? B = ? L ? y ? ( A x ) T \displaystyle \frac{\partial L}{\partial B} = \frac{\partial L}{\partial y} \cdot (A x)^T ?B?L?=?y?L??(Ax)T
- 對 A 的梯度: ? L ? A = B T ? ( ? L ? y ) ? x T \displaystyle \frac{\partial L}{\partial A} = B^T \cdot \left( \frac{\partial L}{\partial y} \right) \cdot x^T ?A?L?=BT?(?y?L?)?xT
向量對矩陣求導規則:
如果:
- y = B z y = B z y=Bz
- B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r
- z ∈ R r z \in \mathbb{R}^{r} z∈Rr
則有:
? L ? B = ? L ? y ? z T \frac{\partial L}{\partial B} = \frac{\partial L}{\partial y} \cdot z^T ?B?L?=?y?L??zT
📌 這是矩陣微積分中經典的鏈式法則: - ? L ? y \frac{\partial L}{\partial y} ?y?L? 是 d d d 維行向量(外層loss對每個輸出的導數)
- z T z^T zT 是 1 × r 1 \times r 1×r 行向量
- 所以它們的乘積是一個 d × r d \times r d×r 的矩陣(和 B 同型)
4、LoRA初始化秩 r 是怎么選的?為什么不選其他值?
LoRA 中的秩 $r$ 是一個超參數,控制低秩矩陣的維度,通常選取值為 4、8、16、32、64,具體視模型規模和任務而定。
- 太小(如 r = 1 r=1 r=1):表達能力太弱,模型性能下降
- 太大(如 r = 512 r=512 r=512):雖然逼近能力強,但和原始 full fine-tune 差別不大,喪失了 LoRA 節省資源的意義
📌 一般經驗:
| 模型規模 | 推薦 LoRA 秩 r |
|---|---|
| <100M 參數 | 4-8 |
| 100M-1B | 16 |
| >1B 模型 | 32 或 64 |
5、LoRA家族
參考:LoRA及衍生
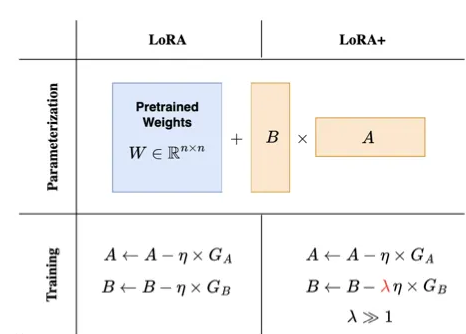
5.1 LoRA+
將矩陣 B 的學習率設置得比矩陣 A 的學習率高得多
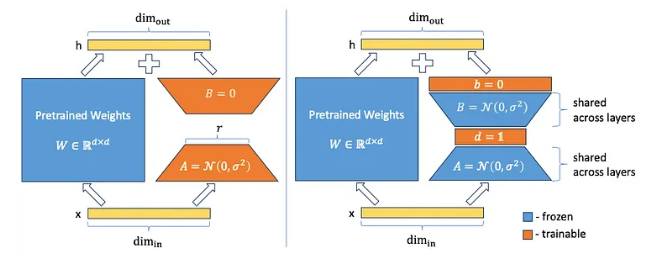
4.2 VeRA
VeRA(Very Efficient Rank Adaptation)是一種改進版 LoRA 微調方法,它固定低秩矩陣 A 和 B(隨機初始化后凍結,在所有層之間共享;),僅訓練縮放向量 d 和 b,實現參數更少、適配性更強的微調。
等等
4.3 QLoRA
對LoRA進行量化

















Java/python/JavaScript/C/C++/GO最佳實現)
——dlib庫安裝、dlib人臉檢測)
