0. 編寫代碼并嘗試運行
克隆以下代碼
git clone https://gitee.com/ai-trailblazer/qwen-vl-hello.git嘗試運行qwen-vl-hello.py,報錯原因缺少modelscope:

1. 安裝qwen-vl-utils工具包
pip install qwen-vl-utils[decord]==0.0.8
嘗試運行,不出意外的話肯定運行不了,報錯原因依然是缺少modelscope:
2. 安裝modelscope
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple再次嘗試運行,依然無法運行,報錯原因modelscope下未找到Qwen2_5_VLForConditionalGeneration:

3.安裝transformers
pip install git+https://github.com/huggingface/transformers accelerate
經歷10分鐘的漫長等待,終于下載安裝完成。再次嘗試運行,依然運行失敗,報錯原因缺少torchvision模塊:

4.安裝torchvision
pip install torchvision
5.嘗試進行視頻識別(失敗)
再次嘗試運行,事情出現轉機,開始下載模型,并進行漫長的等待(在等待過程中,順手去清理一些爆紅的C盤!)
經歷九九八十一分鐘后,發生了意外(我沒有碰它呀)

再次嘗試運行,執行失敗,報錯原因是TypeError: process_vision_info() got an unexpected keyword argument 'return_video_kwargs':
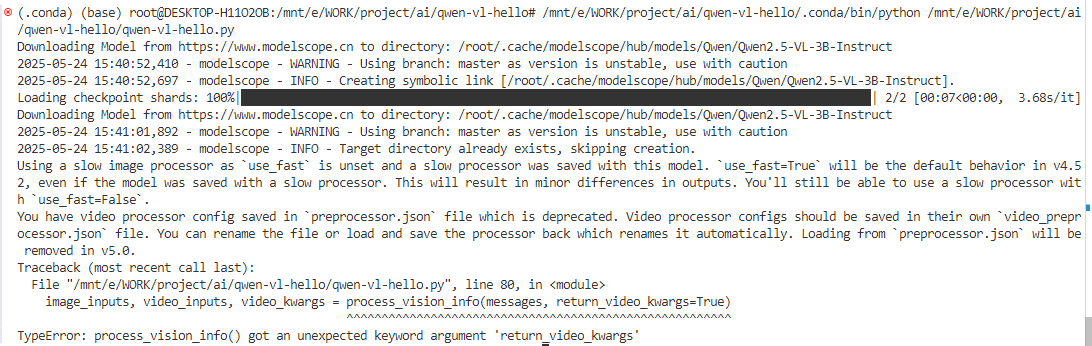
下面先進行圖片識別,排查一下是否是環境問題。
6. 嘗試圖片識別(成功)
先運行圖片識別的代碼(qwen-vl-img-hello.py)吧,沒想到又發生更大意外驚喜,wsl系統連不上了!
Reload Window后,重新連接了
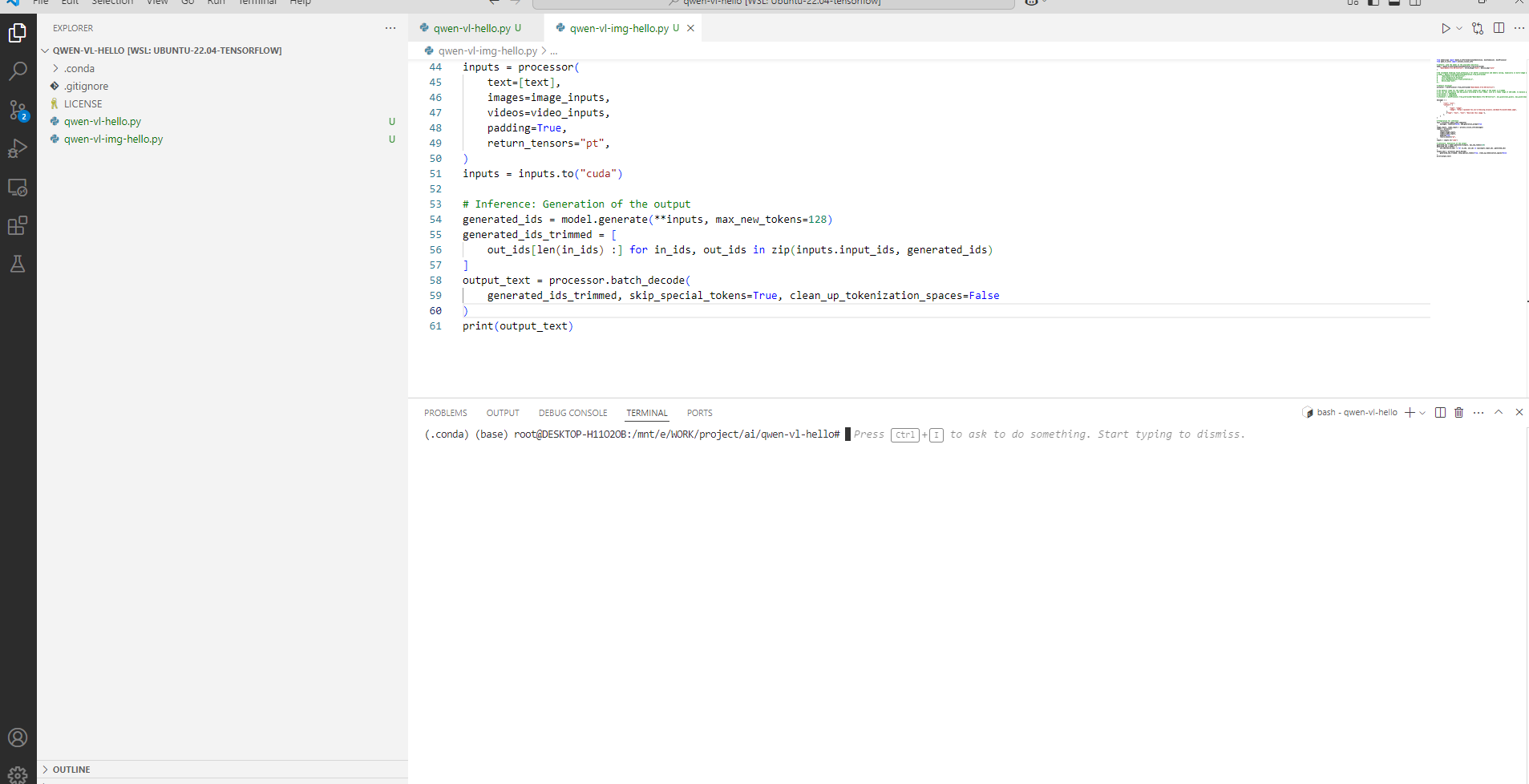
再次運行,圖片識別成功。
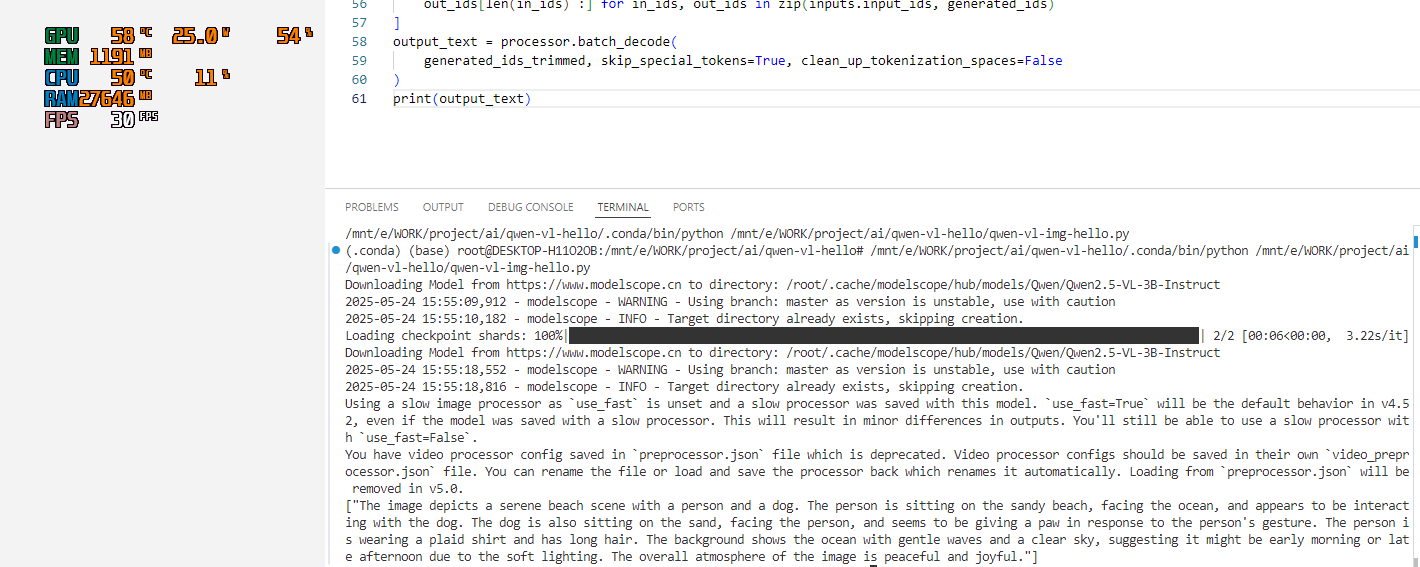

圖片識別成功,初步假設運行環境已經沒有問題了,下面再次嘗試視頻識別。
7.嘗試進行視頻識別(失敗)
依然是第5節的執行失敗原因:
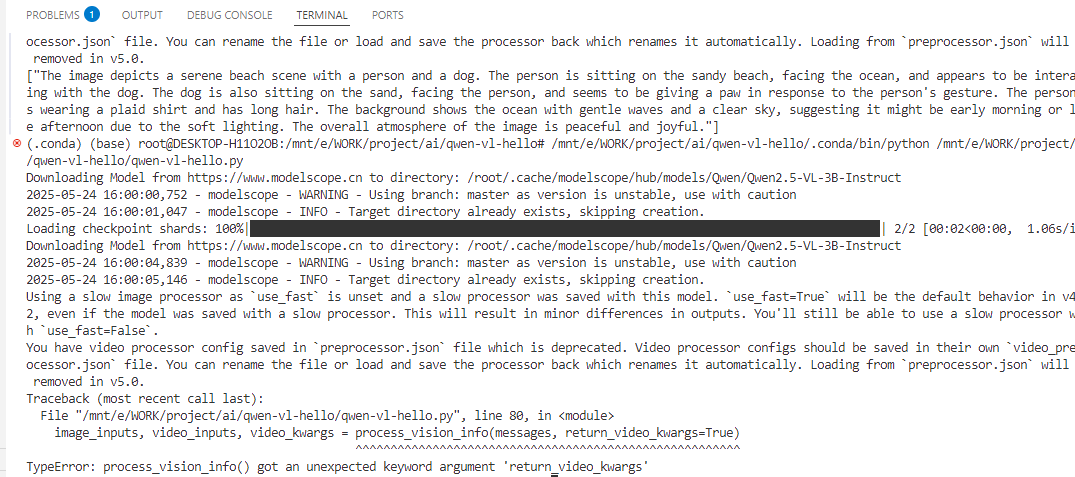
檢查代碼問題。先刪除當前不必要的代碼
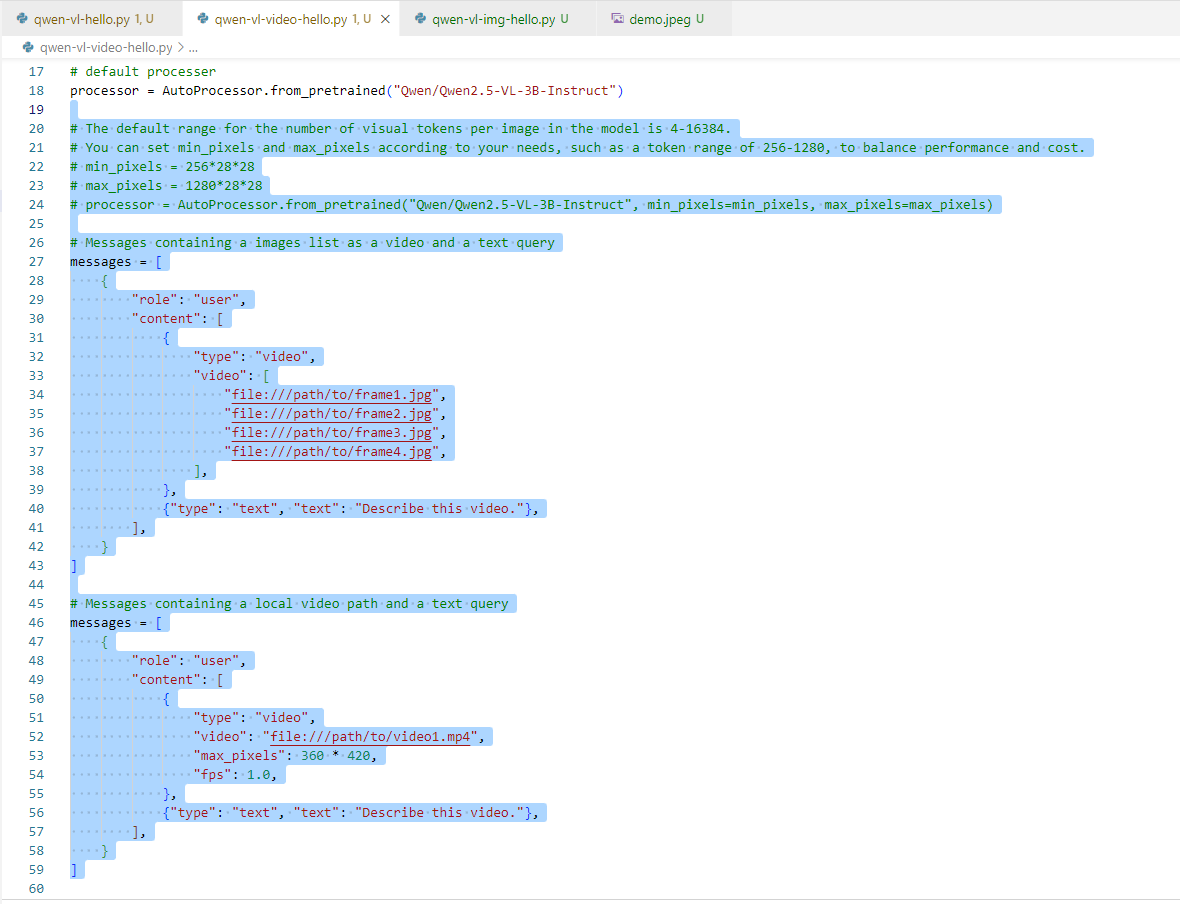
然后腦袋總算是要清醒一點了,即這一行代碼就是設置一個意料之外的參數return_video_kwargs。
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,fps=fps,padding=True,return_tensors="pt",**video_kwargs,
)
inputs = inputs.to("cuda")繼續思考解決方案:后面又要使用到這個video_kwargs,如果不配置它會不會無法返回這個參數......,管它呢,先刪除return_video_kwargs=True,反正電腦又不會炸掉!(繼續Run Python,并戰術性的喝了一口水)。
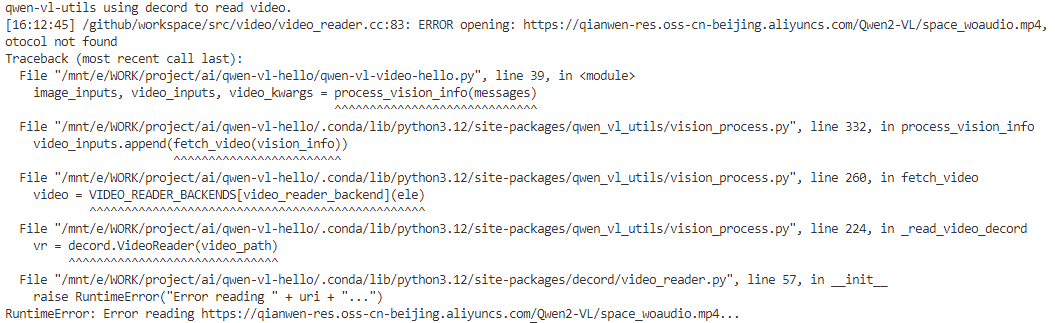
?嗯哼,報錯了:Error reading?難道是視頻鏈接失效了,復制到瀏覽器查看沒問題呀,視頻鏈接是有效的。
https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4下面將繼續排查,瞅一眼qwen-vl-utils的版本為0.0.8,沒錯兒呀,是文檔里的版本咧。
![]()
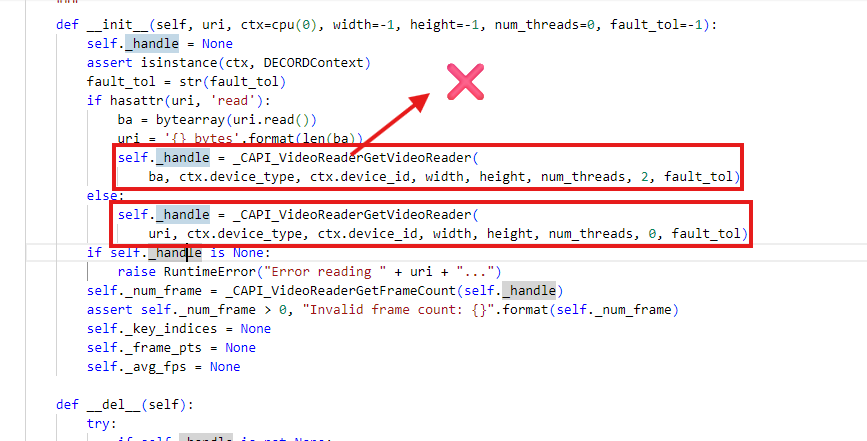
看看源碼,這個函數返回了None,但是這個函數的源碼又看不到!暫且不繼續了看源碼了,換個方向再試試。
繼續排查,嘗試識別本地視頻。(再喝一口水緩解一下壓力)
messages = [{"role": "user","content": [{"type": "video","video": "file:///mnt/e/WORK/project/ai/qwen-vl-hello/demo.mp4",},{"type": "text", "text": "Describe this video."},],}
]wsl又無法連接了!
再次連接后,再次嘗試運行,雖然報錯了,但是至少視頻是能讀取了,報錯只是說明video_kwargs這個不能用了。
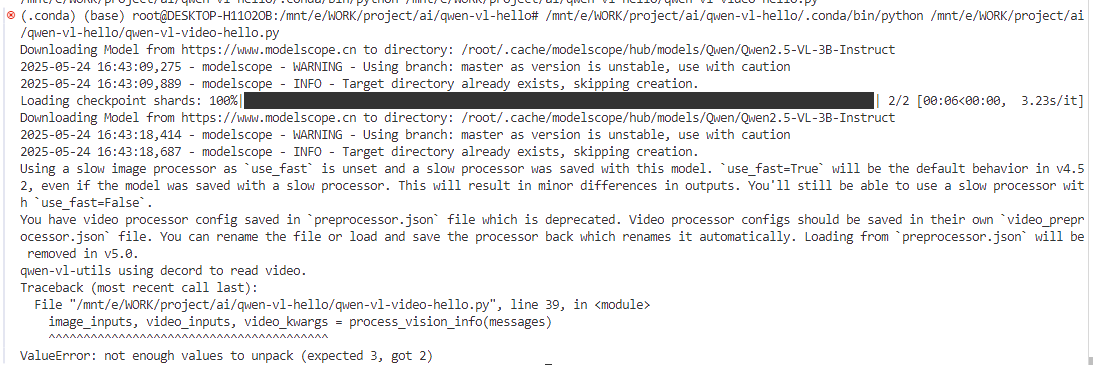
修改代碼再次嘗試運行,wsl又斷連接了
直接在命令行執行
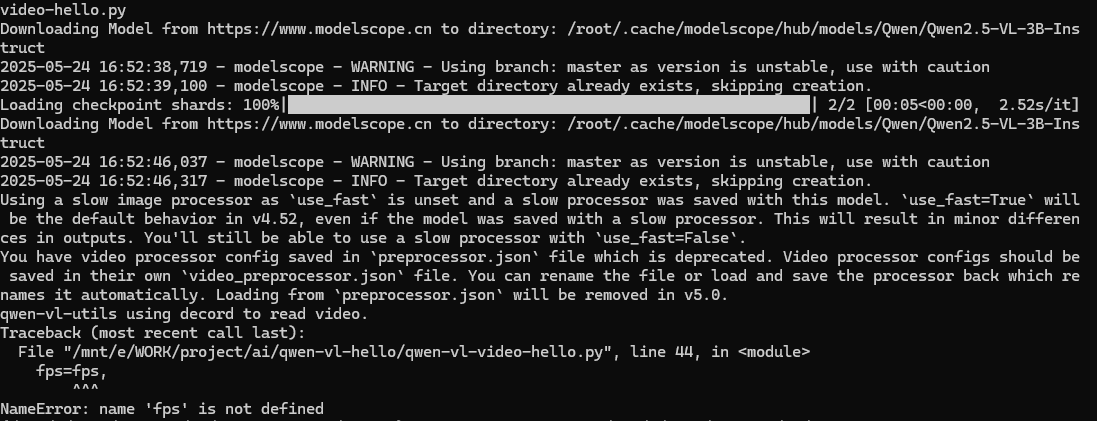
運行失敗,報錯原因fps未定義(這官方教程存在問題哦,艾特一下qwen官方)。修改代碼,刪除fps=fps。修改后再次運行
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt"
)
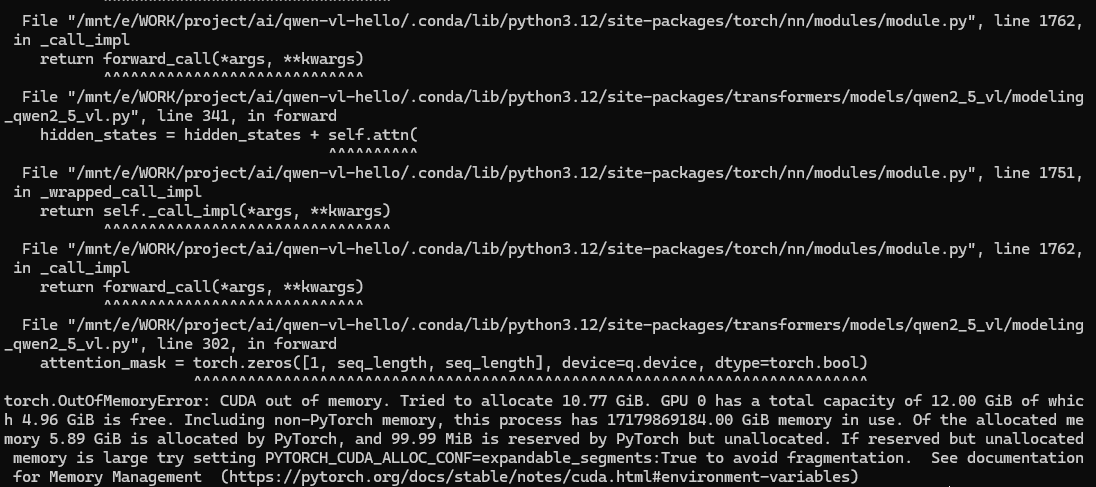
inputs = inputs.to("cuda")顯存溢出!我不服,再次嘗試還是顯存溢出,我服了。
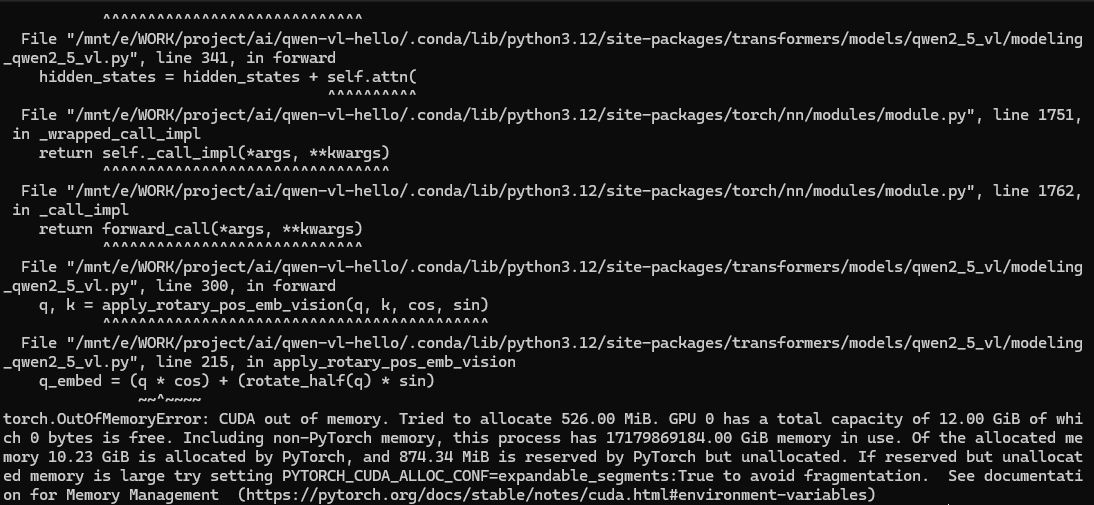
繼續嘗試量化模型Qwen/Qwen2.5-VL-3B-Instruct-AWQ
# 第一處修改
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct-AWQ", torch_dtype="auto", device_map="auto"
)# 第二處修改
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct-AWQ")繼續運行,開始下載模型,然后繼續漫長的等待(順便打開音樂播放器,放一首DJ串燒緩解一下情緒)
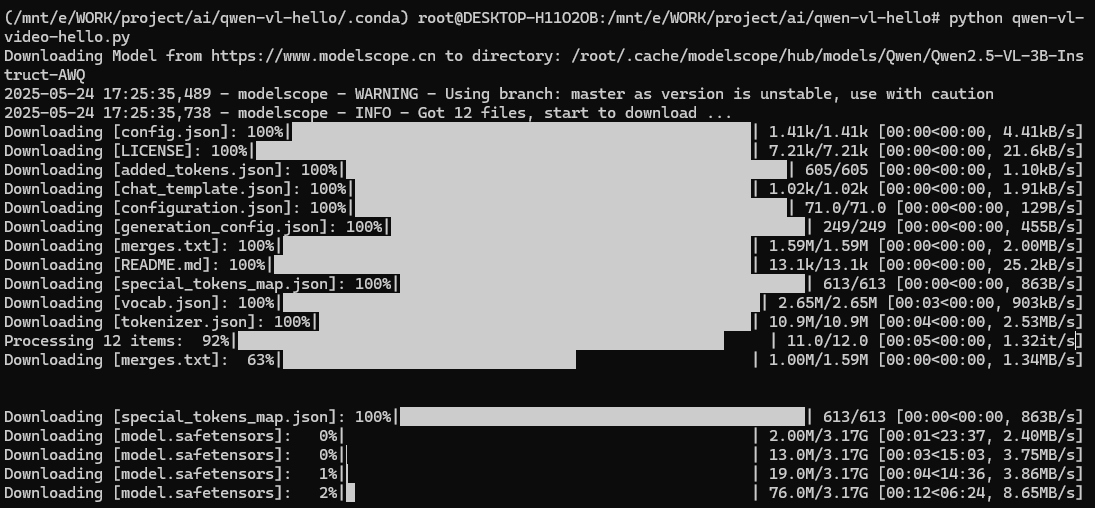
經過九九八十一天的等待后,模型下載完了,但是緊接著又報了一個錯,報錯意思是`autoawq`的版本太低。
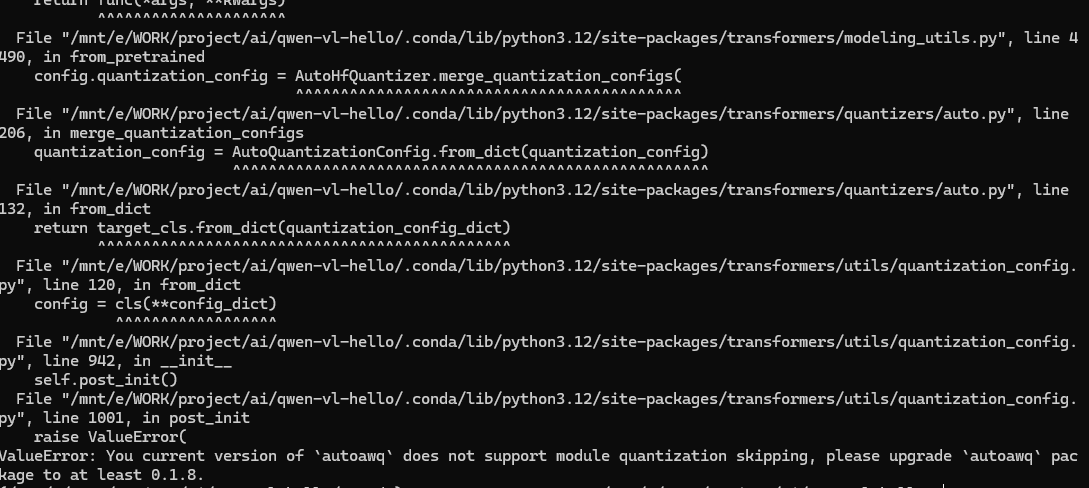
先不急,再運行一次看看,報錯依然如此。通過pip list|grep autoawq發現并沒有安裝autoawq,那就嘗試用pip安裝一個autoawq
pip install autoawq
繼續嘗試運行,顯存溢出!
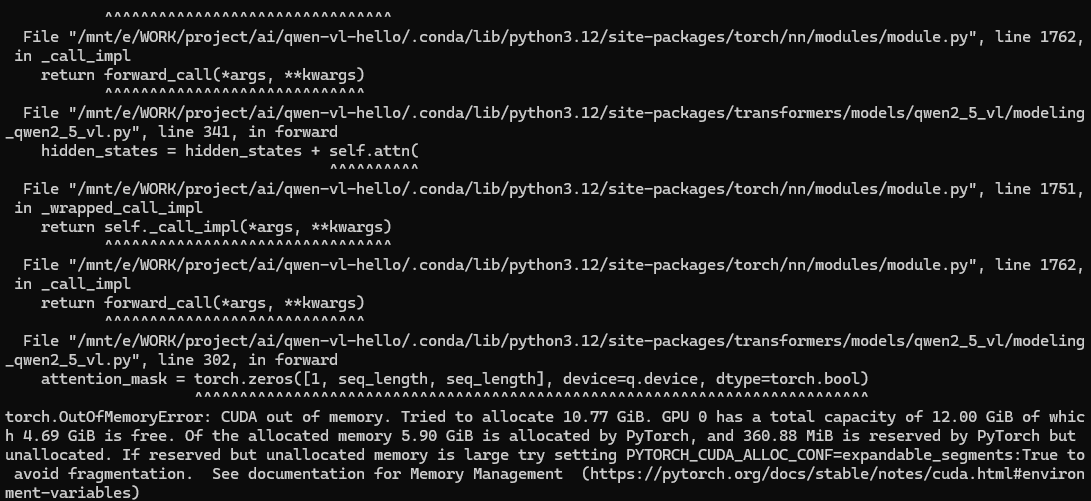
但是,細心的我發現這樣一行輸出,于是我虛心的請教了Deepseek
Unused or unrecognized kwargs: return_tensors, fps.
修改代碼
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,fps=30,padding=True,return_tensors="pt"
)
inputs = inputs.to("cuda")仍然報錯顯存溢出!但是這個輸出內容有點奇怪,區別如下(虛心的我又去查了一下這個單詞的意思unrecognized-無法識別的,也就是說:這兩個參數沒有意義加和不加都一樣!):
# 不添加fps參數
Unused or unrecognized kwargs: return_tensors, fps.# 添加fps=30后
Unused or unrecognized kwargs: fps, return_tensors.有進行了多次嘗試,添加PYTORCH_CUDA_ALLOC_CONF環境變量、指定torch_dtype,都以顯存溢出為結局
from modelscope import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import torchimport os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct-AWQ", torch_dtype=torch.float16, device_map="auto"
)
于是,我不得不承認本地的GPU顯存確實有限,下面我改變策略,在云服務進行嘗試。
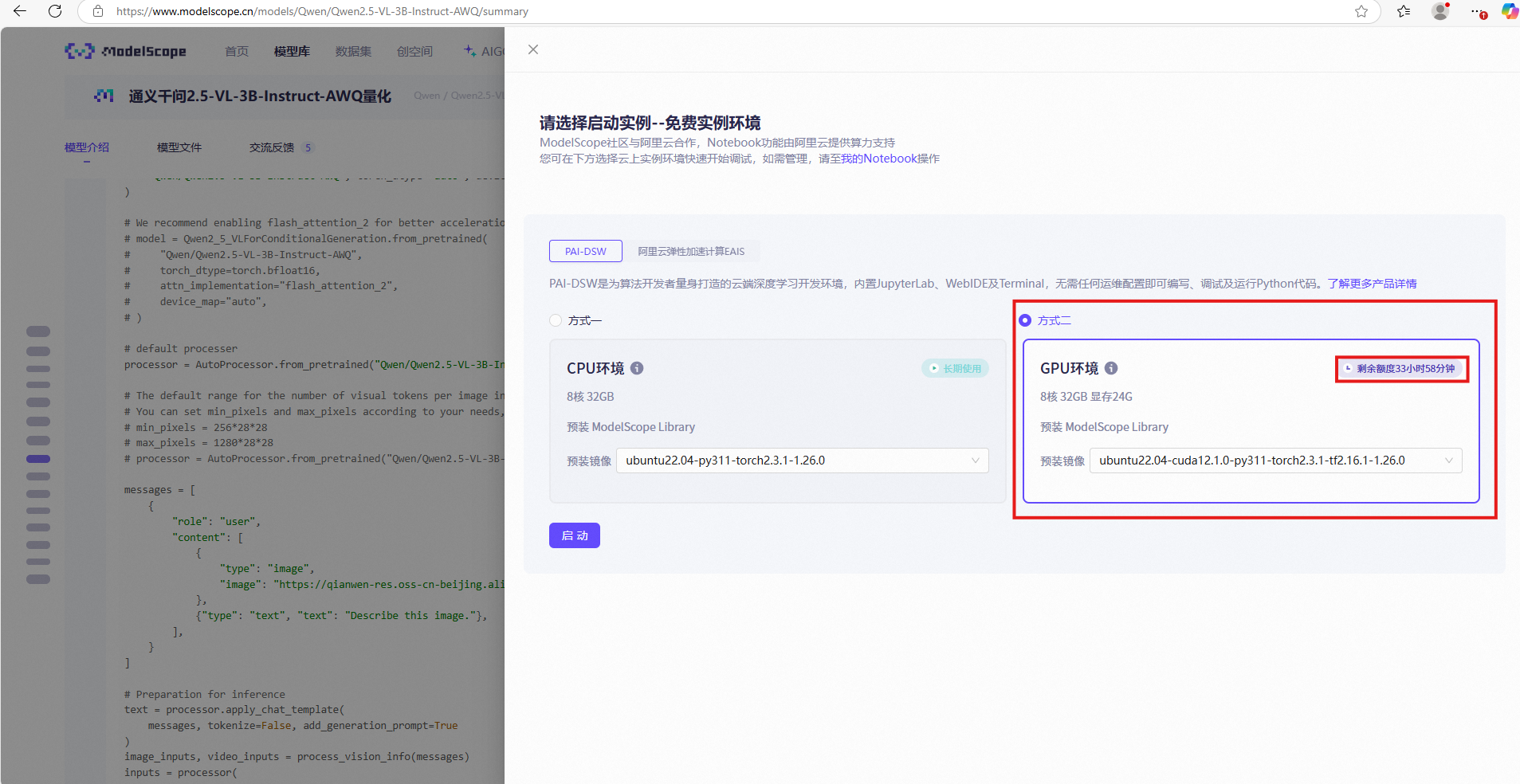
8.借用云服務器進行視頻識別(失敗)
在魔塔選擇贈送的GPU服務器使用時長,點擊啟動并稍等2分鐘左右
克隆代碼倉庫
https://gitee.com/ai-trailblazer/qwen-vl-hello.git
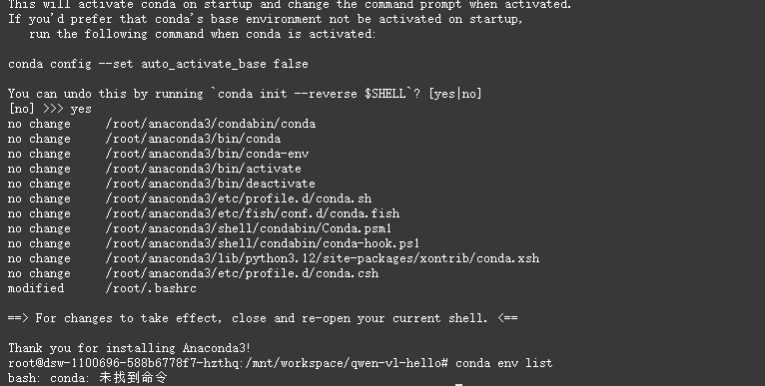
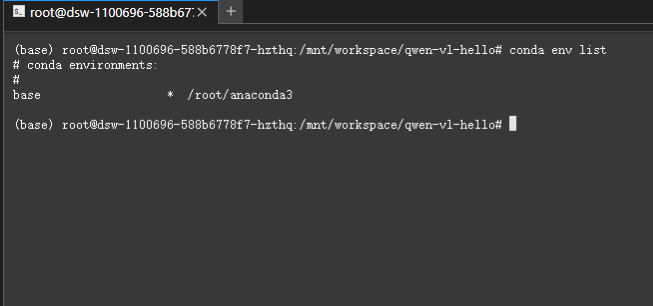
代碼拉取完成后,繼續查看conda版本和顯存。
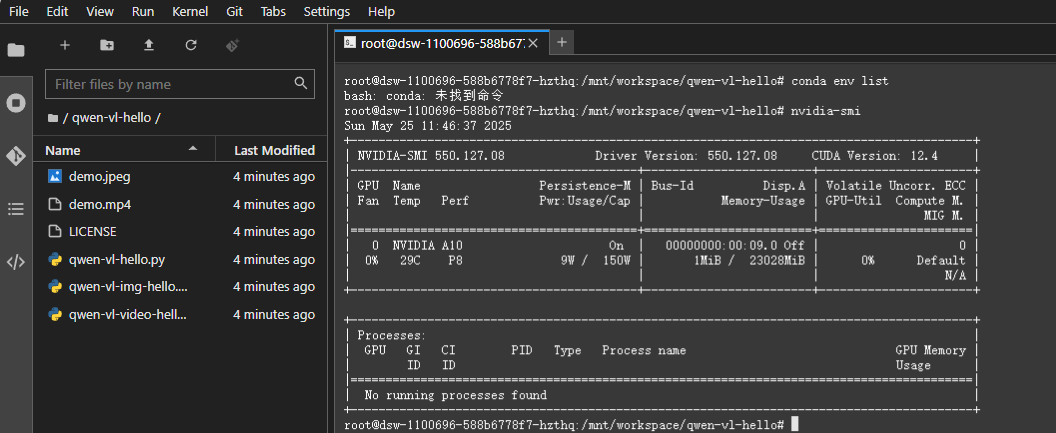
發現沒有conda,那就先在常規python環境嘗試。
pip install qwen-vl-utils[decord]==0.0.8
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install git+https://github.com/huggingface/transformers accelerate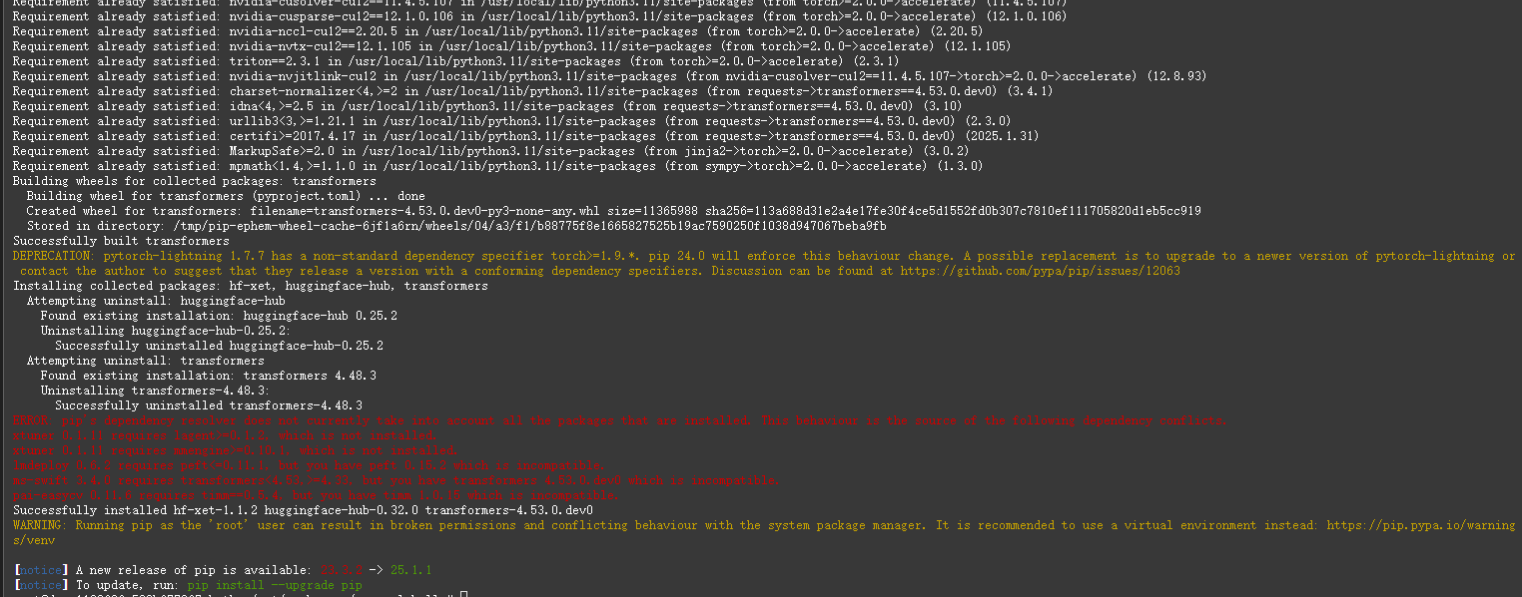
安裝transformers報錯了,暫且不管,先運行代碼
python qwen-vl-video-hello.py第一行運行報錯,找不到Qwen2_5_VLForConditionalGeneration

此時回憶一下在本地的經驗,安裝transformers可是花費了十分鐘之久,并且下載了很多內容,但是此時馬上下載完畢并且還報錯了,仔細分析錯誤原因,發現是很多python三方庫版本不兼容的問題。所以后面還是啟動一個conda環境吧
【AI訓練環境搭建】在Windows11上搭建WSL2+Ubuntu22.04+Tensorflow+GPU機器學習訓練環境
 ?
?
 ?
?
 ?
? ?
?
 ?
?
創建新的conda環境,名稱為vlenv
conda create -n vlenv python=3.12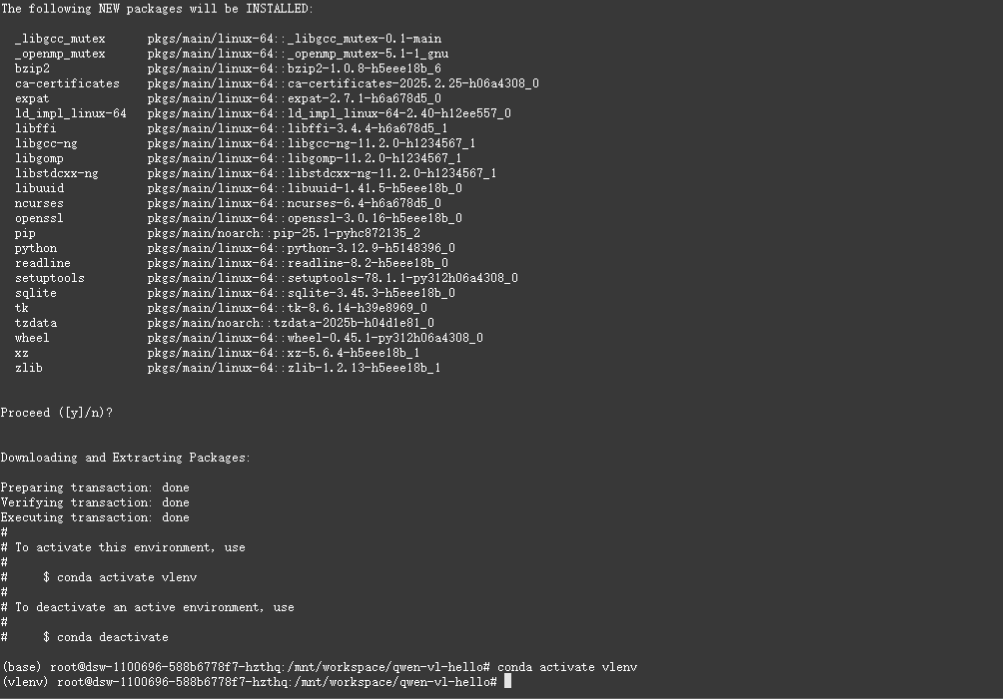 ?
?
安裝依賴
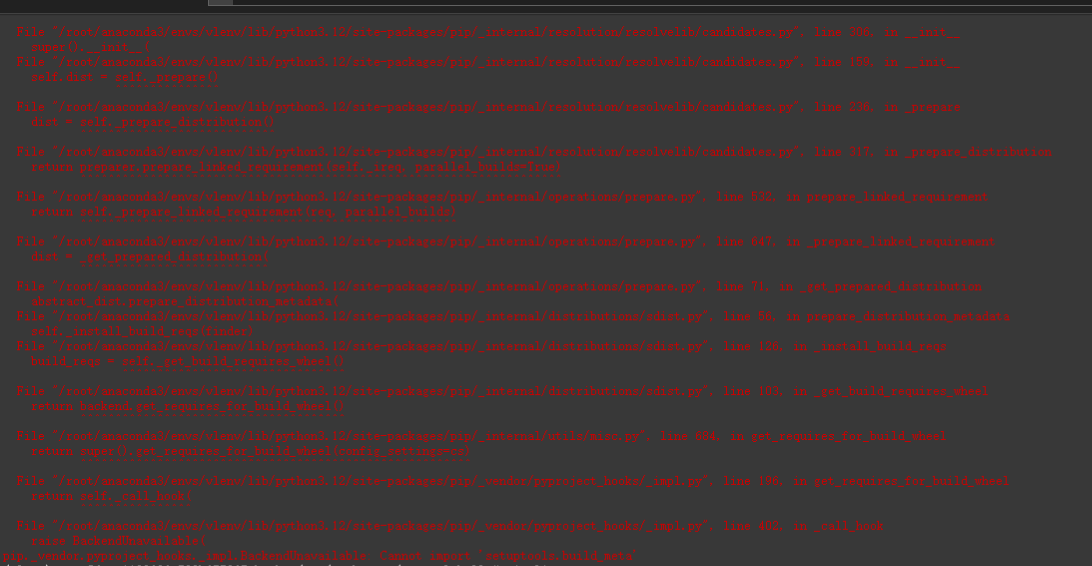
pip install qwen-vl-utils[decord]==0.0.8
pip install modelscope
pip install git+https://github.com/huggingface/transformers accelerate安裝transformers報錯了
 ?
?
重新創建一個3.11 python版本的conda環境,名稱為t1
conda create -n t1 python=3.11 ?
?
嘗試安裝
pip install qwen-vl-utils[decord]==0.0.8
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install git+https://github.com/huggingface/transformers accelerate這次看起來能正常安裝了
 ?
?
安裝完成
 ?
?
嘗試運行,報出熟悉的異常
 ?
?
安裝torchvision
pip install torchvision
再次嘗試運行
python qwen-vl-video-hello.py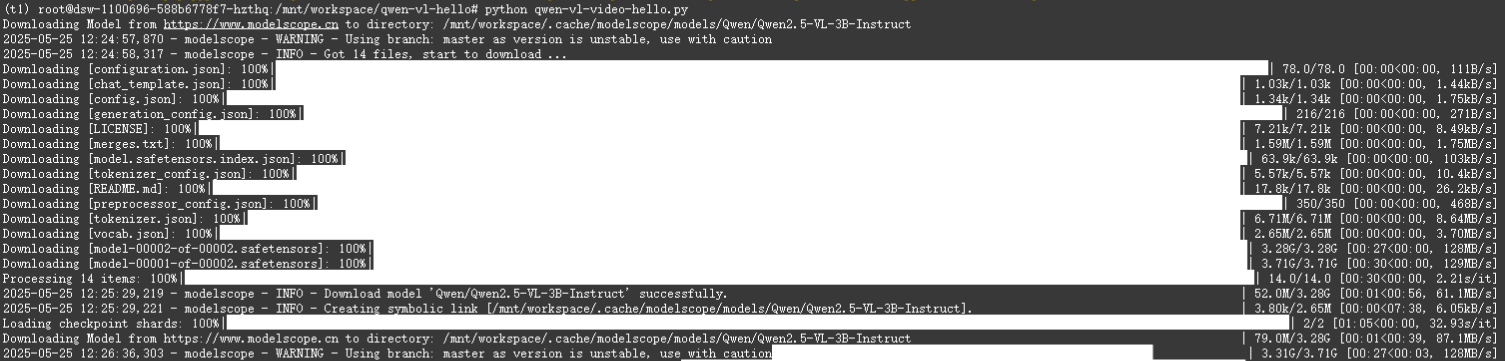
依然報顯存溢出(這可是20多個G的顯存哦)
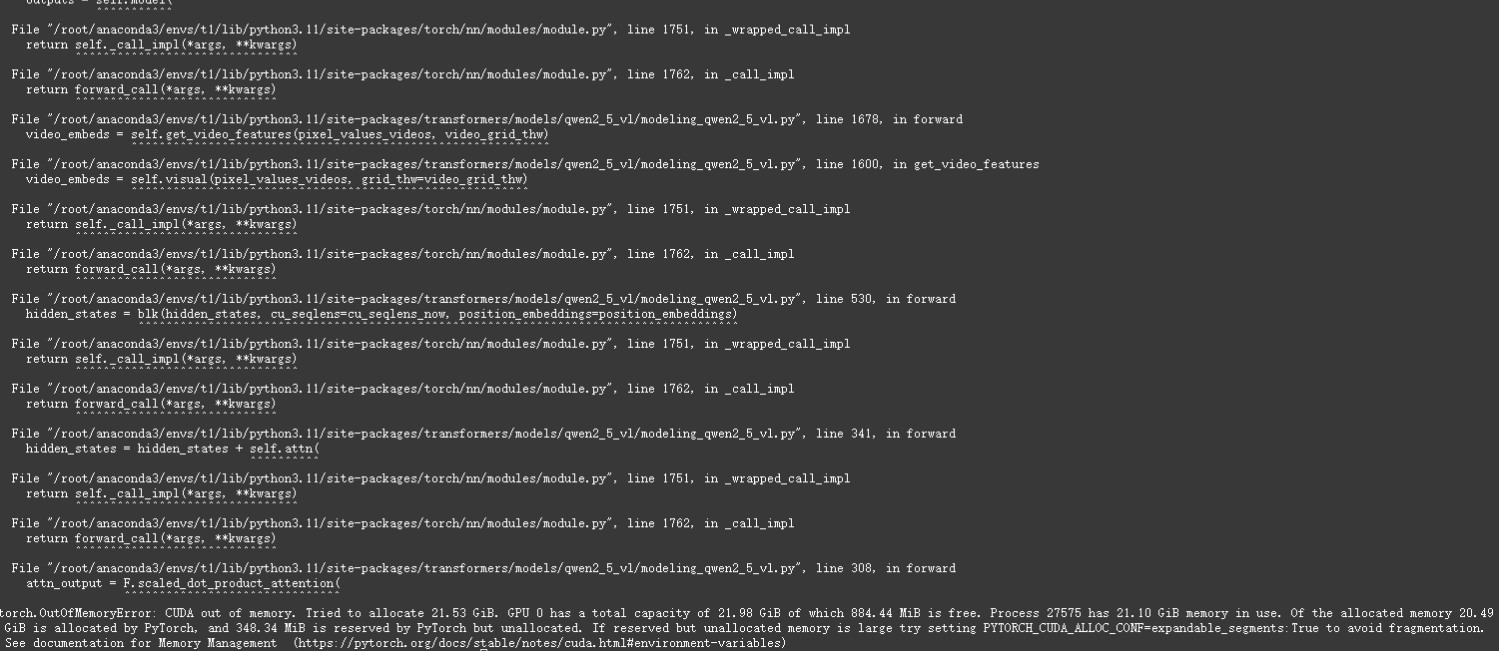
(本次實踐從本地到云服務,共花費7個多小時光陰,雖然目前沒有運行成功,但是至少在這過程中實踐了很多經驗,后續我將嘗試找一個比較小的視頻再次驗證。)
9.使用一個較小的視頻進行識別(成功)
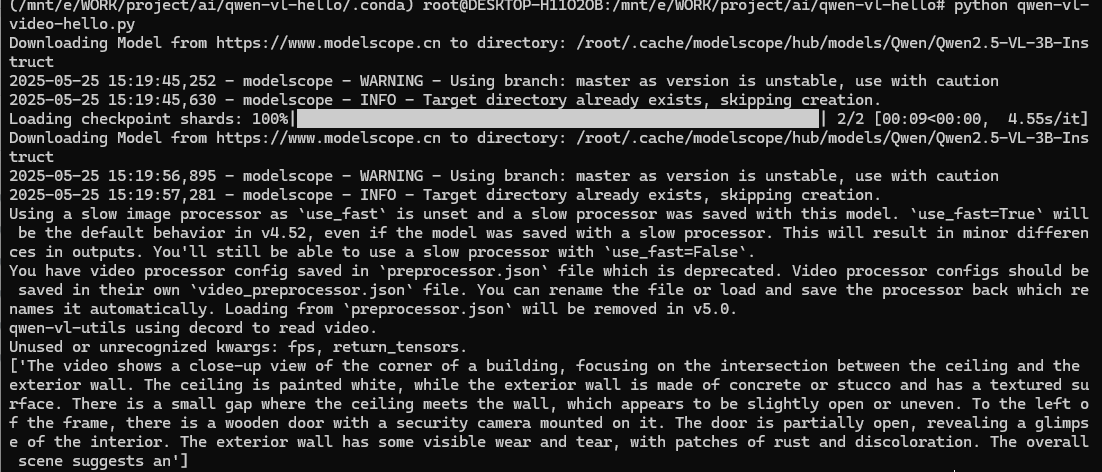
在以上實踐中,使用的是一個21M的視頻,視頻時長約三分鐘。而后我又拿了一個只有291KB的視頻,視頻時長只有1s。
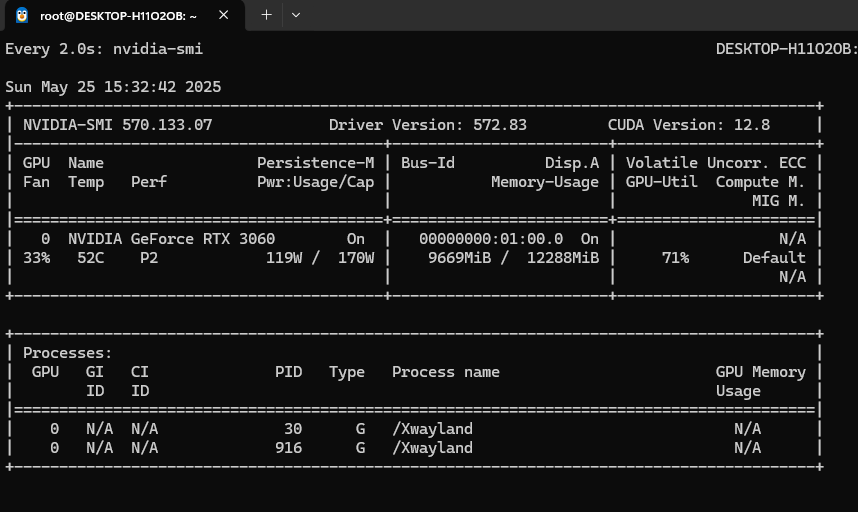
功夫不負有心人,終于成功識別了一個視頻!盡管這個視頻只有1s,可以看到GPU也占用了9G(該顯卡總共只有12G)。
10. 總結和展望
在本次實踐中,主要采用transformers拉起Qwen2.5-VL-3B大模型進行視頻識別,盡管這并不是工程化的運行方式,但是有作為入門實踐的價值。
在整個過程中,總結出以下經驗:
(1)鑒于網絡原因,最好使用modelscope來下載模型;
(2)在vscode中使用wsl的conda環境,可能會出現無響應的情況,此時直接使用cmd命令行可能更加方便;
(3)當一條路走不通時,可以換一條路,如果換一條路還是走不通,這時在回頭看方法是否有問題,很多時候就是在你回頭思考的過程中解決掉問題的,但是你還是得感謝你在另一條路上探索,因為你至少知道了那條路行不通,否則你的思維陷入到不確定中;
(4)云服務器的網絡和硬件優勢可以加速我們進行AI方面的實踐,本次實踐中在云服務器上花費的實踐僅僅只占總時長的30%,但是產生的效果卻很顯著,在這里也非常感謝modelscope社區和阿X云為我們提供的免費實例環境,非常感謝;
(5)conda是個好東西,其提供的強大的隔離式python環境,在解決各種依賴庫版本庫問題的時候非常有用,本次實踐中,在云服務器最終使用的是python3.11版本,而我本地電腦是使用的python3.12,這些經驗在工程成產過程中也很有價值;
后續的實際計劃和展望:
(1)達到這個目標“Qwen2.5-VL 可以理解超過1小時的視頻”,所需要的條件和方式有哪些?
(2)考慮更加工程化和輕量化的通過Qwen2.5-VL進行視頻識別的方案;
(3)其它模型或方案進行視頻識別的使用資源和效果對比;
?








Java/python/JavaScript/C/C++/GO最佳實現)
——dlib庫安裝、dlib人臉檢測)






- 模擬器)


