數據集并行的概念:
并行場景1:
對不同數據執行相同的操作:
串行執行:
可以同時進行:
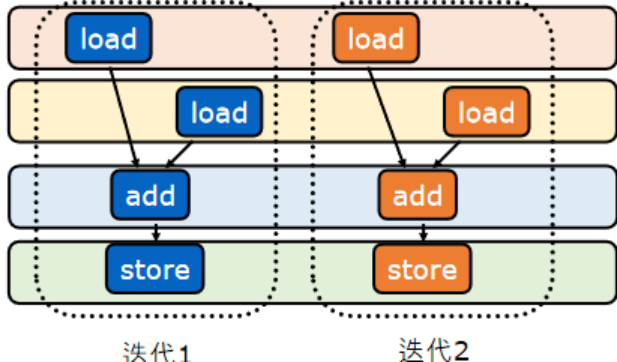
可以嘗試一個多條指令,多核執行
引入:
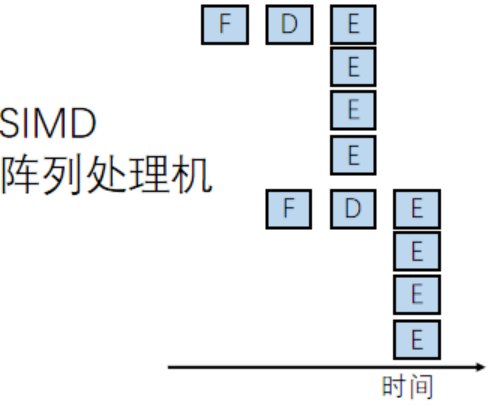
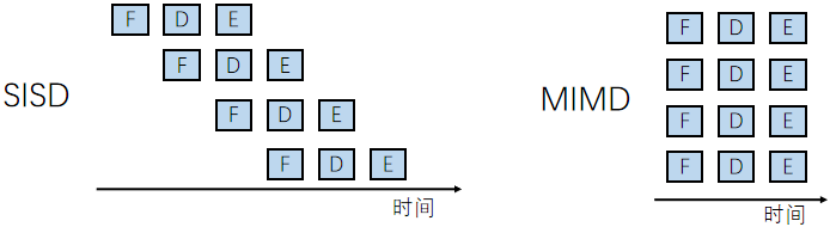
SISD:
單核,單線程,串行執行,這樣耗時
MIMD:
多核,多線程,并行執行,一條指令多次重復,變成了MIMID
存在的問題:
在標量CPU流水線中,取址、譯碼等操作邏輯復雜,且開銷不低
對于數據級并行任務,無論是在SISD還是MIMD(多核)器件上運行,其取址、譯碼操作都是有冗余的
SIMD:
更多的CPU,但是有著更少的取指令和譯碼,更快的執行(但是也需要更多的數據寄存器,來支持增加后的多數據的存儲)
兩類處理機:
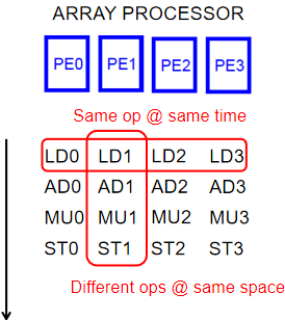
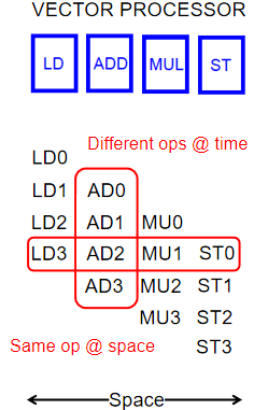
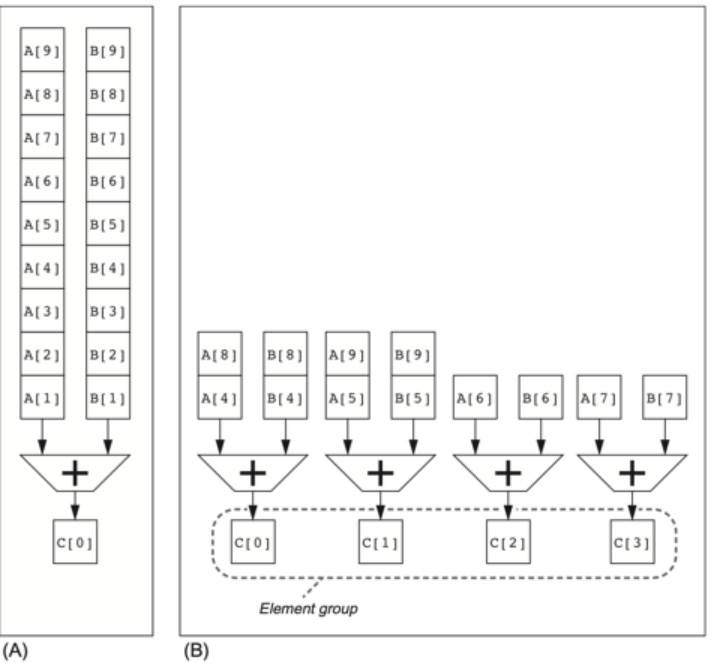
陣列處理機:同一指令在同一時間處理不同空間上的不同的數據元素
向量處理機:同一指令在連續的時間內在同一空間處理不同的數據元素
陣列處理機(同一個指令,同時在不同的地方處理)
向量處理機
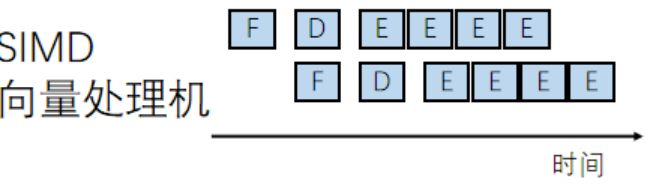
讓我們去對比SISD和MIMD,發現處理數據的時間更多了,明顯更加的優秀了
(同一個指令,會處理很多個數據)
向量體系結構和GPU
向量體系結構特點:窄而寬,指令流水線深,ALU寬度窄,單詞指令流水后可以處理更多的數據,掩蓋不必要的流水時間
GPU的特點:寬而淺,ALU寬度寬,流水線本身簡單,直接對更多的數據進行計算,同一時刻處理更多數據
向量體系結構:
-基礎知識:
科學計算領域的很多問題需要處理大批量操作重復且互相沒有關聯的計算
向量:一組由一維數組組成的數據
標量:單個數據
在流水線處理機中,設置向量數據表示及相應的向量指令,稱為向量處理機。
不具有向量數據表示和相應的向量指令的流水線處理機,稱為標量處理機。
向量的處理方式:
D=A+(B+C)為例
-橫向計算
一個一個的計算 di=ai*(bi+ci)
對于這個循環:先計算:ki=bi+ci,di=ai*ki
這里會造成N次數據相關,而且每次都會涉及到2次操作的切換,總:2*N次功能切換
-縱向計算
先計算:K=B+C
然后計算:D=A*K
這里涉及1次數據相關,1次功能切換,明顯更優秀了
但是這里需要每次都訪問完向量的所有元素,所以這就需要:存儲器-存儲器結構,這里可能造成每次的存儲操作過于麻煩
-縱橫計算
為了能夠在寄存器之間進行我們的數據交換,我們會嘗試將數據進行分組,每一組的大小允許我們將數據放到寄存器上,
假設向量的長度是N,每一組的長度是n,那么組數有N/n+(N%n!=0 ) =s組
所以先分組計算k=b+c,d=a*k
一共s組,每組一次數據相關,2次功能切換
這樣就可以使用寄存器-寄存器結構了
總結:
1.向量體系結構應當具有很大的順序寄存器堆?(Register File),可加載更多向量元素以支持縱向計算
2.向量體系結構從內存中收集散落的數據,將其放入寄存器堆中,并對寄存器堆中的數據們進行操作,然后將這些結果放回內存(一次傳輸一組數據,LD/ST流水化)
3.一條指令能夠對一個向量的數據進行操作,也就對向量中諸多獨立數據元素進行了操作(縱向計算,功能單元流水化)
功能部件流水化:
比如我們將浮點加法流水化:

我們就會得到一個更快的處理過程
向量處理機的優勢:
由于向量的ld和sd是深度流水化了,所以一個大型的寄存器也就起到了一個緩沖的作用,可以掩蓋訪存延遲帶來的帶寬
亂序執行的超標量處理器往往具有復雜的設計,亂序程度越高,其功能實現也就越復雜,容易觸碰功能墻
順序指令的標量處理器可以輕松的拓展為向量處理器
舉例:
我們有8個Vector Reg,流水化的向量功能部件,每周期1個操作(需要控制單元來檢查結構or數據冒險),ld和sd全流水化,每個周期1個字,標量寄存器集合(32位)
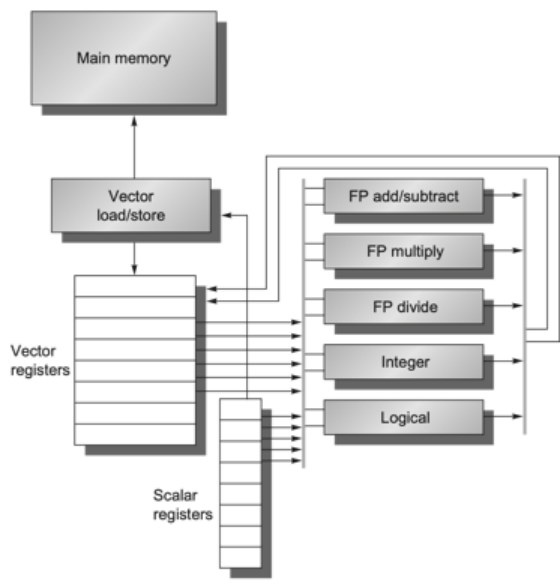
特殊的寄存器:
VL向量長度寄存器:我們的向量長度就要小于64,我們通過VL這個寄存器來控制
VM向量屏蔽寄存器:如果向量的長度小于64,或者控制語句下對某些元素單獨操作的時候使用,即使maskcode有大部分的0(數據大部分無效),也可以獲得很快的指令執行速度
Vmips向量指令格式:

合理使用Vmips不光可以節省代碼,也可以大量節約取值和指令譯碼的時間

一些相關概念:
循環間相關:對一個循環來說,如果各輪迭代之間存在相關性,則稱為循環間相關,否則為循環間無關
可向量化:針對一組MIPS指令描述的循環,如果滿足循環間無關,則循環稱為可向量化的,編譯器可為其生成向量指令。
指令編隊(convoy):由一組不包含結構冒險的向量指令組成,一個編隊中的所有向量指令在硬件條件允許時可以并行執行。
向量處理機的優化
-多車道技術:
在最開始的串行執行中盡可能的優化,使用多個ALU,就像是把單行道,拓展為4車道
-鏈接技術**:
鏈接技術:當兩條指令出現“寫后讀”相關時,若它們不存在功能部件沖突和向量寄存器(源或目的) 沖突,就有可能把它們所用的功能部件頭尾相接,形成一個鏈接(長)流水線,進行流水處理。
鏈接過程:無鏈接情況下,后面的功能需要等到前一個功能的n個結果都產生才能開始;而鏈接情況下,后面的功能只需要等到前一個功能的第一個結果產生就可以開始,即向量數據的生產與向量數據的消費進行延遲的重疊。
鏈接實質:把流水線定向的思想引入到向量執行過程,對兩條流水線進行聯合控制,沒有改變寄存器和運算電路。
以下的討論中假設各個部件之間傳遞一個結果需要一拍時間。
讓我們來看一個例子:(向量寄存器沖突)
V3=V1+V2
V5=V4&V1
這里就產生了數據相關,向量寄存器沖突,不能夠實現鏈接
功能部件沖突:
V3=V1*V5
V6=V7*V6
這里都使用了乘法部件,功能部件產生沖突
讓我們來看一個鏈接的例子:
假設功能單元的時間開銷為:浮點加減(6 cycle),浮點乘法(7 cycle),浮點存儲操作(6 cycle)。為了同步要求,將向量元素送往功能部件,以及把結果存入向量寄存器需要一拍時間,從存儲器中把數據送入訪存功能部件也需要一拍時間。為以下程序畫出鏈接示意圖,并分析非鏈接執行和鏈接執行兩種情況下的執行時間。假設向量長度為N,N≤64。
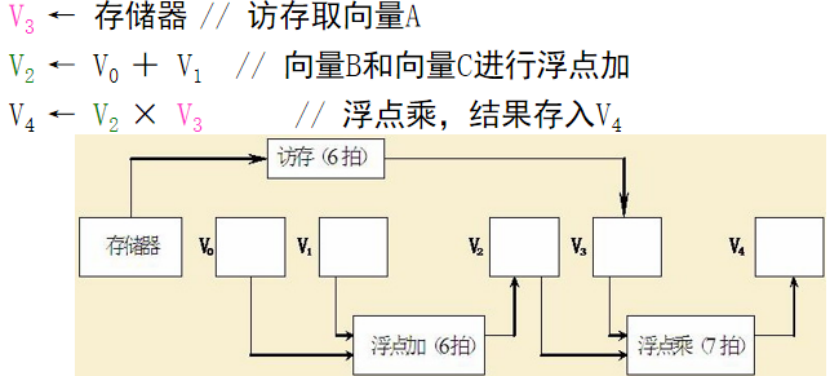
如果不鏈接的話,串行執行:
執行的時間:
[(1+6+1)+N-1]+[(1+6+1)+N-1]+[(1+7+1)+N-1] = 3N +22
如果前面兩個指令并行:
[(1+6+1)+N-1]+[(1+7+1)+N-1] = 2N +15
如果前面兩個并行,第三個指令鏈接執行
一個指令的時間: ?[(1+6+1)] +[(1+7+1)] = 17
N個指令: ?17+N-1=N+16
總結:
-無向量寄存器使用沖突和無功能部件使用沖突
-鏈接的指令之間需要將前一個指令的元素送入寄存器才能開始鏈接
-當一條向量指令的兩個源操作數分別是兩條先行指令的結果寄存器時,要求先行的兩條指令產生運算結果的時間必須相等,即要求有關功能部件的通過時間相等。
-要進行鏈接執行的向量指令的向量長度必須相等,否則無法進行鏈接。
-一次鏈接行為通常僅發生在分組內部,即不對整個N進行鏈接,而對個分組內的n個向量元素的計算過程進行鏈接
-編隊技術:
定義:幾條能在同一個時鐘周期內一起開始執行的向量指令集合稱為一個編隊;
要求:同一個編隊內:
不存在結構沖突;
不存在數據沖突;
存在數據沖突,但是可以鏈接。
例題:
假設每種向量功能部件只有一個,下面一組向量指令,在不使用鏈接技術和使用鏈接技術的情況下如何編隊?

不用鏈接的編隊:
LV->(MULTSV,LV)->ADDV->SV
使用鏈接的編隊:
(LV,MULTSV)->(LV,ADDV)->SV
-分段開采技術
當向量的長度N大于向量寄存器的長度n時,必須把長向量N分成長度固定為n的段,然后循環分段處理,每一次循環只處理一個向量段。這種技術稱為分段開采技術。
由系統硬件和編譯軟件合作完成控制,對程序員是透明的。
影響一個向量體系結構的因素:
操作數向量的長度
向量啟動時間
數據相關,可否鏈接
結構相關,可否編隊,多車道,發射限制
GPU體系結構:
介紹:
GPU:具有極高的計算吞吐率和內存帶寬,專用圖形圖像處理器,適合紋理圖像處理
GPGPU,通用圖形處理器:可進行通用計算編程:例如CUDA, OpenCL適合處理SIMD程序
GPU擁有眾核(上千個運算單元,支持更大量的運算)
GPU的處理模式:
流水線?
還是并發?
SPMD(單程序多數據)編程模型:
程序采用多線程的模型,而非向量指令,與SIMD編程模型不同
特點:
不同的進程/線程運行同一個程序源代碼(SP),但是分別使用不同的輸入數據進行各自的計算(MD)
不同進程/線程相互獨立,沒有執行順序的要求
常用的并行編程模型多數采用SPMD模式
CUDA:采用SPMD編程方式的,基于C++,由NVIDIA提出的通用并行計算平臺和編程模型
異構編程:
Host:
主機(CPU)
運行C++程序
Device:
物理上分離的協處理器(GPU)
運行kernel程序
運行thread
運行CUDA目標代碼
我們以向量加法為例:
就可以在host上喚醒多個協處理器,,交給他們來幫助我們快速的去處理(線程)
GPU的執行方式:SIMT,
單指令多線程的方式
特點:
是SIMD和多線程的結合版,
線程按照固定的方式運行
固定個數的線程一起執行(SIMD)(Warp)
但是使用的標量指令(和傳統的SIMD不同)
GPU處理單元的執行方式:SIMD
總結:
GPU的編程模型:SPMD
GPU的執行方式:SIMT
計算單元的處理方式:SIMD
優點:
編程靈活,支持任意大小的工作量,任意寬度的硬件
每個線程單獨對待
wrap過程的對程序員透明
一個顯卡的結構:
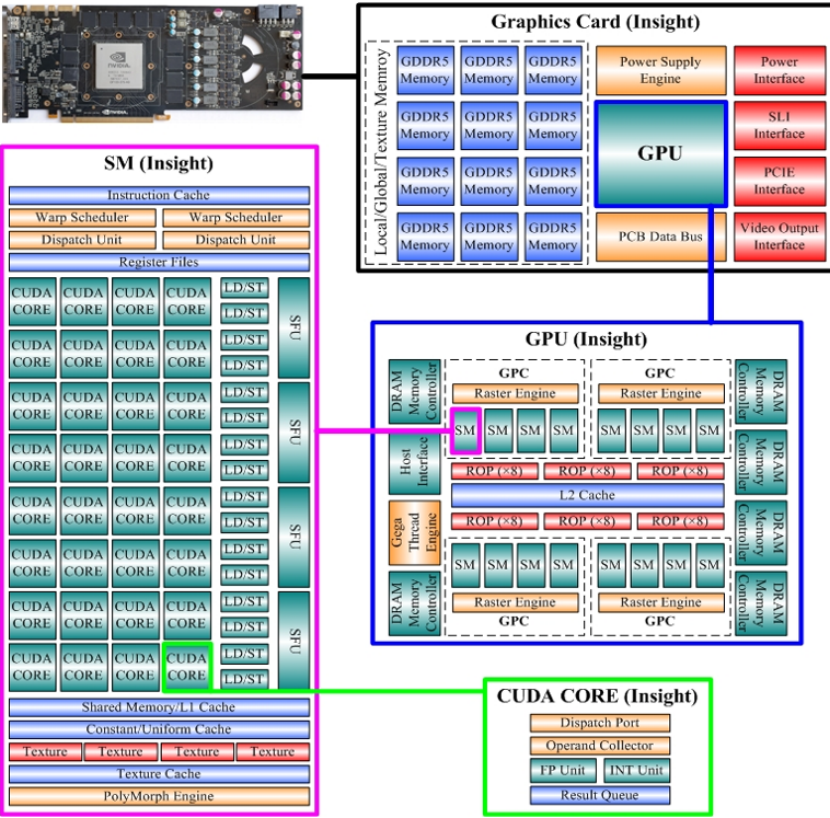
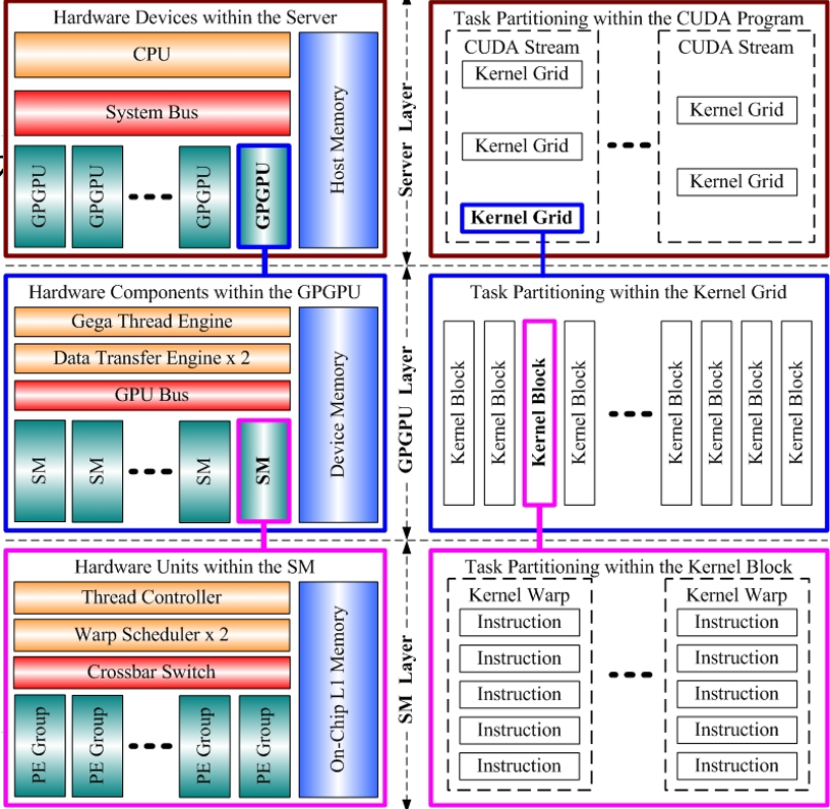
GPGPU微體系結構:
線程以warp為單位調度,
同一個warp的不同的線程按照simt的方式執行
大容量寄存器組用于存放所有線程的數據
SP(Streaming Processor)
進行數據的并行計算,i.e., ALU
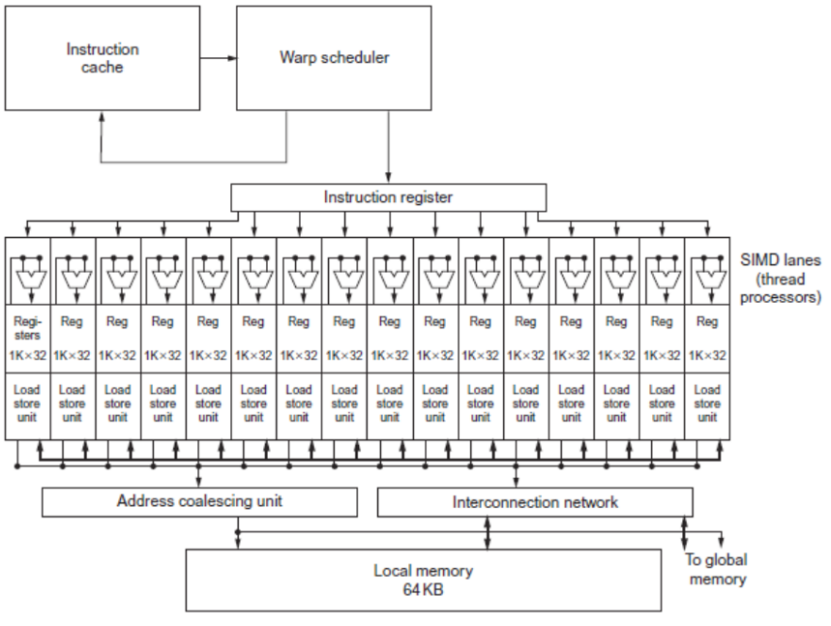
同一個wrap中的不同線程按照SIMT的方式執行
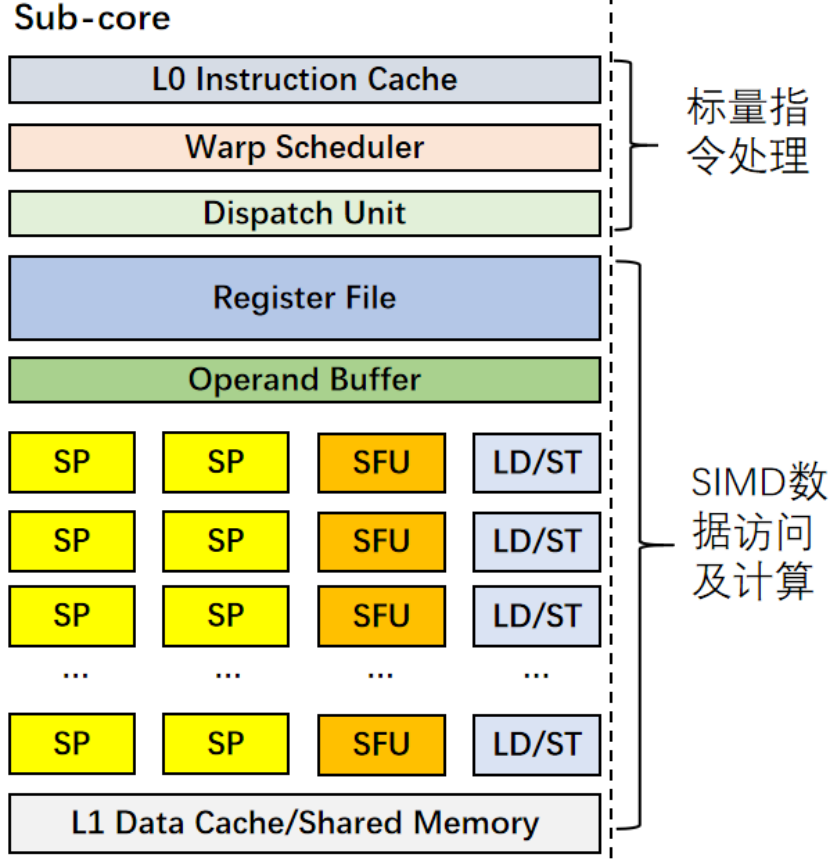
流水線
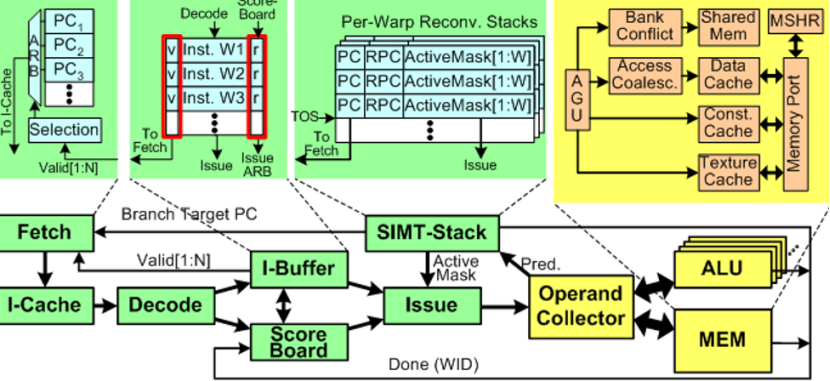
Warp:
在NvidiaGPU中,Warp為32個標量線程構成的SIMT執行單元
,在GPUSM中,Warp是最小的調度和執行單位(也就是說GPU沒法控制某個單獨的線程)
Warp中不同的Thread執行保持同步(執行系統的PC對應的指令)
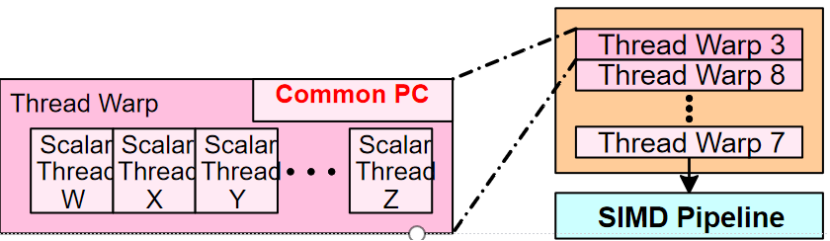
通過顆粒度多線程并行掩蓋延遲
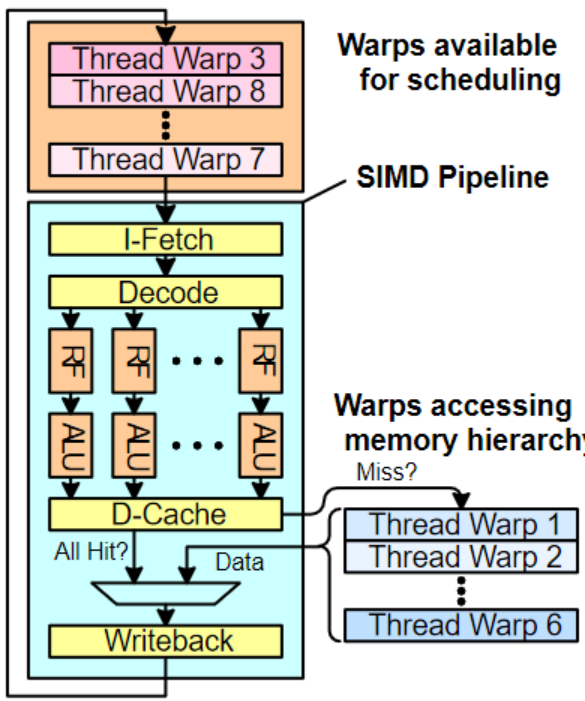
(右下角)
Warp調度:
通過Warp之間的交替調度掩蓋長時間的方程帶來的延遲
Warp執行:
通過多線程和并行處理單元來加速計算的原理。GPU 中 warp 是線程的基本調度單位,利用多個功能單元并行處理可以顯著提升計算效率。
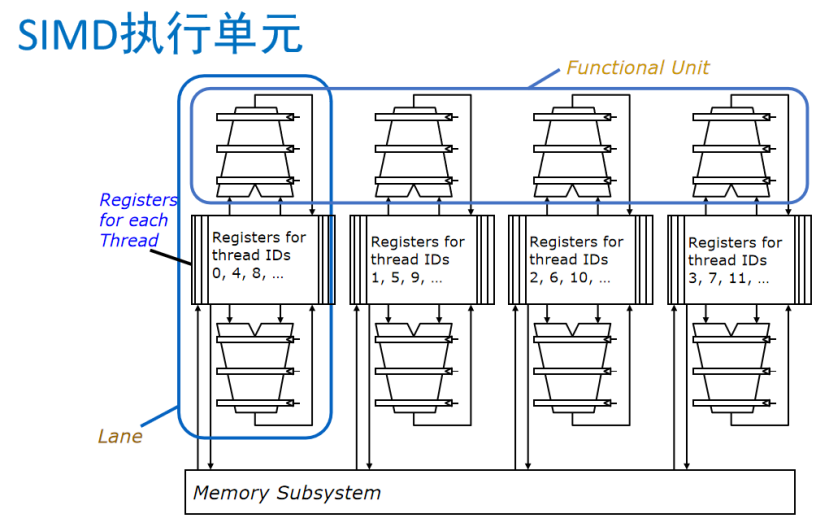
Functional Unit(功能單元)
功能單元是執行實際運算操作(如加法、乘法等)的部件。在 SIMD 架構中,它可以同時對多個數據元素執行相同的指令,提高計算效率 。例如在圖形處理中,對多個像素點進行色彩調整時,功能單元可并行處理。
Registers for each Thread(每個線程的寄存器)
寄存器是處理器內部高速存儲單元,用于臨時存儲數據和指令。圖中不同線程 ID 對應的寄存器組,分別存儲對應線程的數據。線程在執行 SIMD 指令時,從這些寄存器中快速讀取和寫入數據,加快運算速度 。
Lane(通道)
Lane 可理解為 SIMD 執行單元中的一條數據處理通路。每個 Lane 處理一部分數據,多個 Lane 并行工作,共同完成對多個數據的處理。例如在一個 4 - Lane 的 SIMD 單元中,一次可同時處理 4 組數據。
Memory Subsystem(內存子系統)
內存子系統負責數據的存儲和傳輸,為 SIMD 執行單元提供運算所需的數據,并存儲運算結果。它與寄存器和功能單元協同工作,確保數據在不同存儲層次間高效流動 。
Streaming Processor(流處理器)
GPU(圖形處理單元)中用于處理數據并行計算任務的核心組件。它專注于對數據流進行高效處理,適用于需要大量并行計算的場景,如圖形渲染、科學計算、深度學習等。
眾多流處理器(SP)并行工作,每個流處理器又包含多個 CUDA core ,可以同時處理大量數據。像在深度學習訓練中,大量神經元的計算任務就可由這些并行的流處理器高效完成,極大提升運算速度。
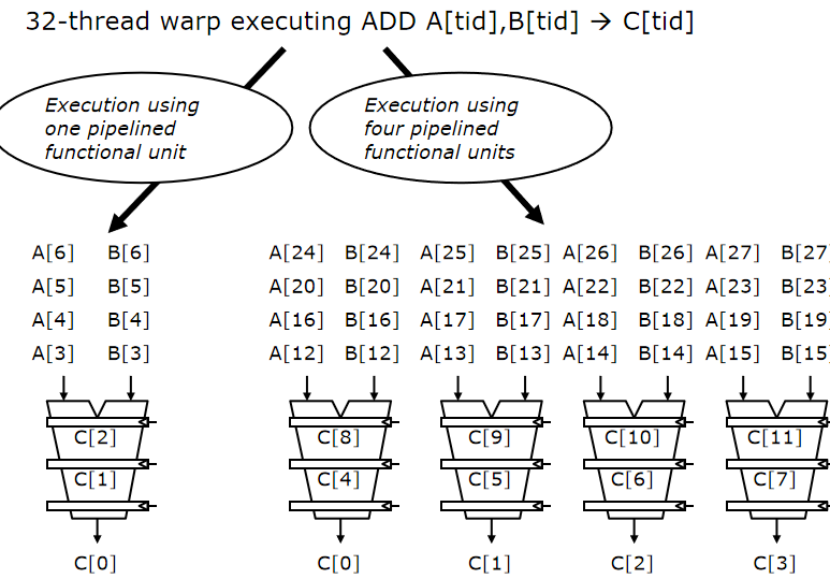
Warp指令級的并行執行
可以將不同指令交替執行
假設機器中有8個通道,1個warp中有32個線程
每周期完成24個操作,但是每周期流出1個warp
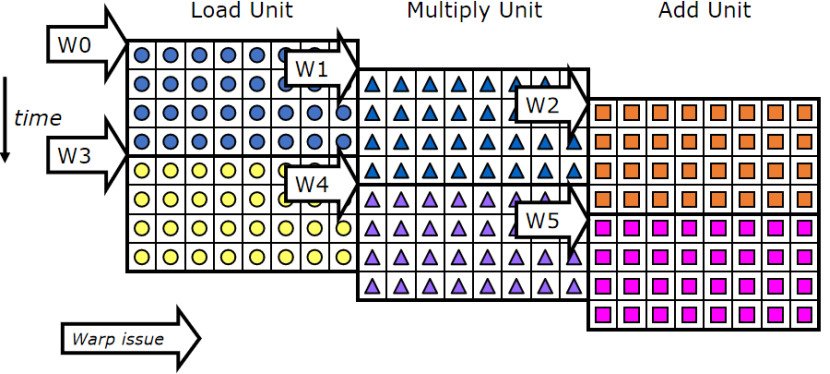
同一時間可以操作8個,4個周期一個warp的對應操作
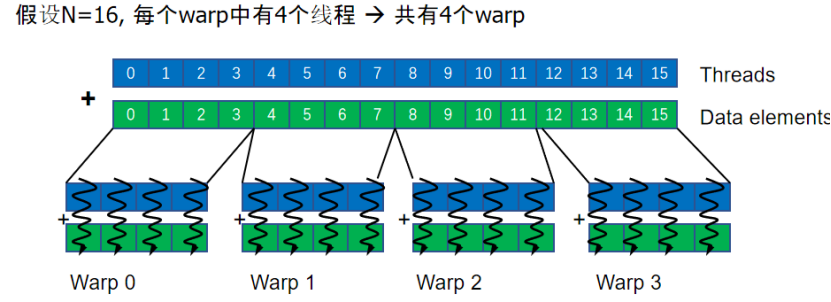
SIMT的訪存方式:
執行同一指令的不同線程使用線程ID來訪問不同的數據
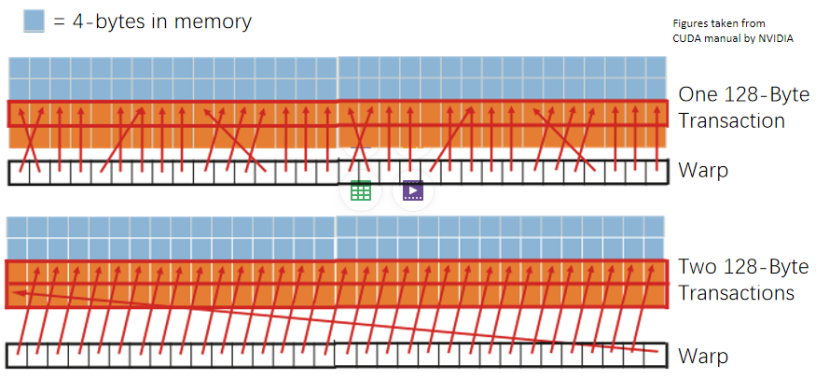
Coalescing:
將一個warp中不同thread的內存訪問合并成更少的訪問次數:
如果一個warp中的32個thread訪問內存中連續的4B大小的位置,合并成一個128B的訪存請求(coalescing),而不是發送32個4B的訪存請求
有效降低SM和DRAM之間的訪存次數 :減少片上網絡、片上存儲劃分、DRAM的工作量
如圖:
GPU程序層次模型:
一個程序kernel grid包含有多個block,一個block有多個thread,而thread作為標量線程執行完成的步驟代碼
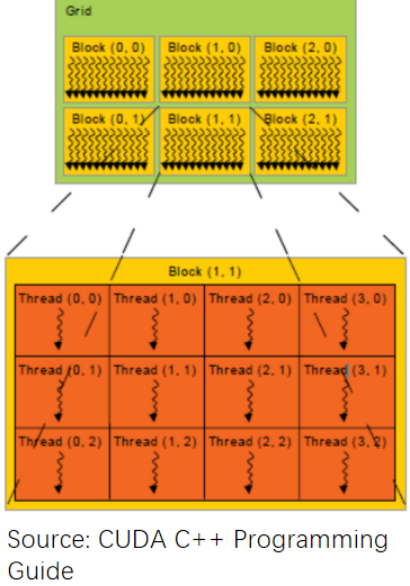
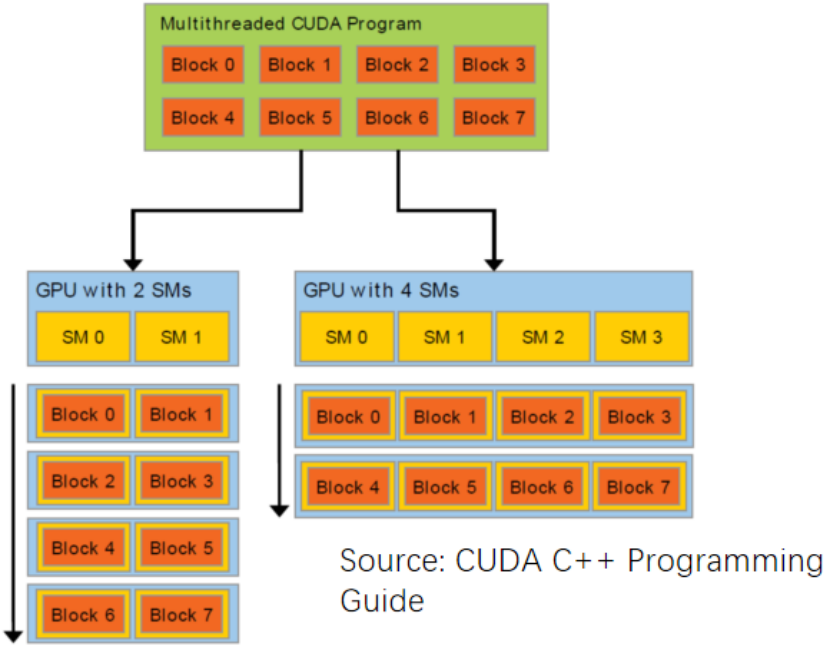
kernel以block為單位來分配到硬件中,多個block可以分配到同一個SM,只要空間足夠
在SM內部,來自同一個block的不同線程組成一個Warp,這里的BLOCK和THREAD對程序員可見,但是warp對程序員不可見
同一kernel中的所有線程都共享相同的代碼
不同線程執行進度可能不同
但是同一warp中的線程一同執行
可以在Block級別進行同步
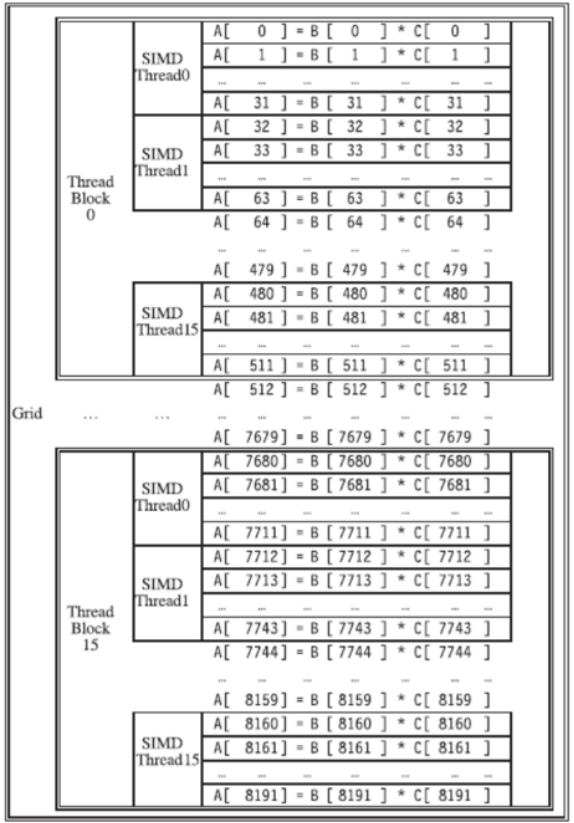
例子:一個grid可以劃分區域為多個可處理的單元*Block,里面多個線程,一次以SIMD方式處理
GPU和傳統的SIMD的區別:
傳統SIMD采用單線程
向量指令之間鎖步執行:一個向量指令完成后后續指令才能開始執行
編程方式為SIMD,軟件需要知道向量長度
ISA中有向量/SIMD指令
GPU以SIMD方式執行大量標量線程
可以非鎖步執行
每個線程可以被獨立看待,由硬件進行線程組合(Warp)
編程方式為SPMD
ISA是標量的
Nvidia ISA的特點
Parallel Thread Execution
(PTX)抽象特性:它是 NVIDIA 編譯器的指令集目標,是對硬件指令集的一種抽象表示。不依賴于特定的 GPU 硬件版本,可實現各代 GPU 的兼容性,方便開發者編寫通用代碼,不同硬件都能處理基于 PTX 編寫的程序。
指令格式:“opcode.type d,a,b,c;” 是其指令格式。其中 opcode 為操作碼,指明要執行的操作(如加法、乘法等 );type 表示操作數的數據類型(如整數、浮點數等 );d 是目的操作數,a、b、c 是源操作數。
虛擬寄存器使用:使用虛擬寄存器,在編譯和運行時由軟件進行映射和管理,便于優化寄存器分配,提高代碼執行效率,也增加了編程靈活性。
軟件翻譯:PTX 指令需要由軟件(如 NVIDIA 的編譯器 )翻譯成機器語言,才能被 GPU 硬件執行。
PTX 與 SASS 的轉換
PTX(Parallel Thread Execution):是 NVIDIA GPU 指令集的一種中間表示形式,具有硬件無關性,方便實現跨代 GPU 的代碼兼容性。它是一種面向軟件編程的抽象指令集,由 NVIDIA 編譯器生成。
SASS(Serialized Assembler)?:PTX 在運行時會被轉換成?SASS。SASS 是 GPU 實際執行的機器指令形式,更貼近硬件底層,是一種二進制編碼的匯編指令 。這種轉換過程類似于將高級語言編譯為機器語言,使程序能在特定 GPU 硬件上執行。
SASS 與 GPGPU 計算能力的關系
對應關系:SASS 與 GPGPU(General - Purpose computing on Graphics Processing Units,通用圖形處理器計算 )計算能力相對應。不同的 GPU 計算架構(如不同代的 NVIDIA GPU 架構 )具有不同的硬件特性和功能單元配置。一般來說,一種計算架構有一組對應的 SASS 指令,這些指令針對特定架構的硬件資源進行優化,以充分發揮該架構的計算性能。
跨架構復用:雖然一種架構通常有一組對應的 SASS 指令,但不同架構也可能采用相同的 SASS。這可能是因為某些指令在不同架構中功能和實現方式類似,或者是為了在新架構中保持對舊代碼的兼容性,降低軟件開發和移植成本。
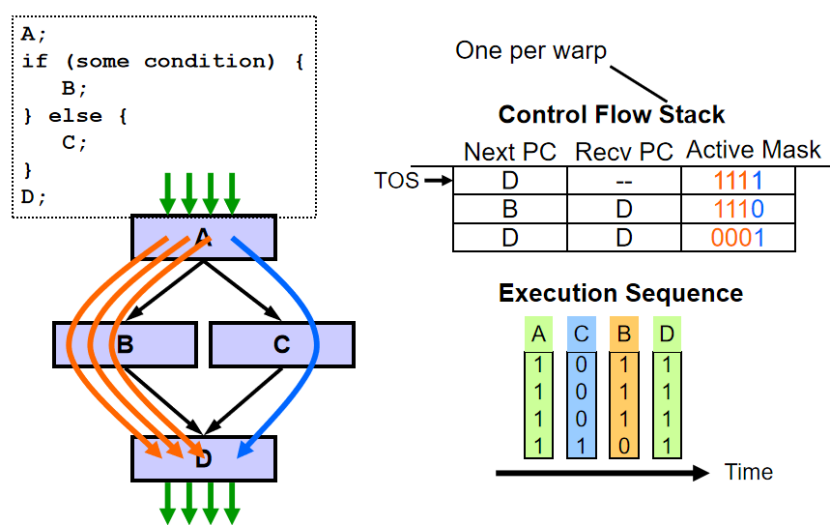
分支處理:
分支處理原理
掩碼機制:GPU 分支硬件借鑒向量處理機的向量屏蔽寄存器思路,使用掩碼來標識哪些線程需要執行特定分支代碼。掩碼是一種二進制標識,每個位對應一個線程,通過掩碼可快速篩選出符合條件的線程集合 ,讓它們執行相應分支操作。
硬件棧處理:利用硬件棧輔助分支處理。遇到分支(分歧 )時,通過 “push”?操作將當前狀態壓入棧中,并設置新的掩碼位,確定執行不同分支的線程;當分支執行完成匯聚時,執行 “pop” 操作,從棧中恢復之前的狀態,確保線程執行的正確性和連貫性 。

示例代碼解析
高級語言邏輯:示例中if (X[i] != 0)是條件判斷,滿足條件時執行X[i] = X[i] - Y[i];?,否則執行X[i] = Z[i];?。
匯編指令解析
ld.global.f64 RD0, [X+R8]; RD0 = X[i]?
//從全局內存地址X+R8處加載 64 位浮點數到寄存器RD0?,獲取X[i]的值。
setp.neq.s32 P1, RD0, #0
比較RD0與 0 是否不相等,結果存入謂詞寄存器P1?,若不相等P1為真,否則為假。
@!P1, bra???ELSE1, *Push;
//若P1為假(即X[i] == 0?),通過bra(跳轉 )指令跳轉到ELSE1標簽處執行。跳轉前執行*Push操作,將舊掩碼壓棧并設置新掩碼位,確定執行該分支的線程 。
后續指令ld.global.f64 RD2, [Y+R8]; RD2 = Y[i]等是條件為真時執行的操作,完成X[i] = X[i] - Y[i];計算并存儲結果。
@P1, bra ENDIF1, *Comp;
//若P1為真,跳轉到ENDIF1標簽處,*Comp操作對掩碼位取反。
ELSE1標簽下指令
ld.global.f64 RD0, [Z+R8]; RD0 = Z[i]
//執行X[i] = Z[i];操作。
ENDIF1: <next instruction>, *Pop;
//執行*Pop操作,從棧中彈出舊掩碼,恢復之前的狀態,繼續后續指令執行。
分支分歧:
同一個Warp的不同thread在遇到分支指令時產生的分歧
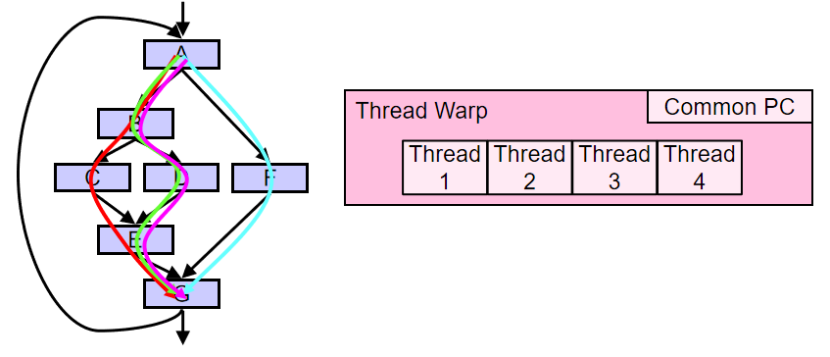
分支分歧:當同一warp中的不同線程在遇到分支指令時執行不同的路徑
GPU使用簡化的控制邏輯來減少控制部分所占的面積:thread無法單獨控制和調度,并行的處理單元同一個時鐘周期只能處理相同的操作
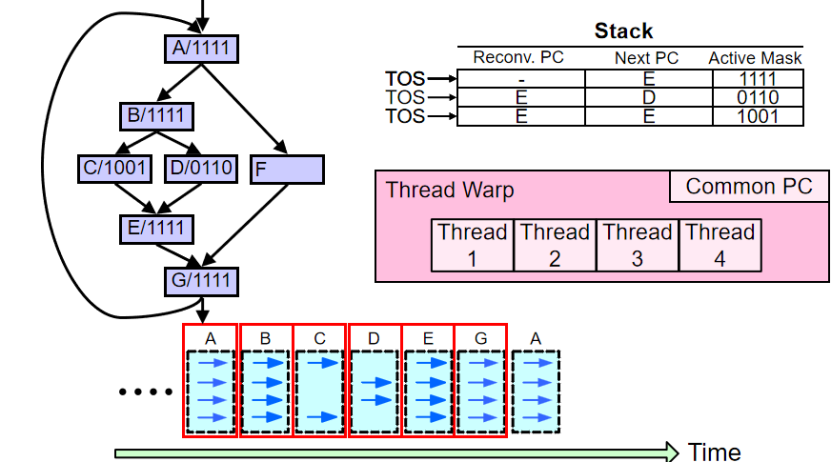
每一個Warp使用一個棧來處理分支分歧,分支指令中加入一個匯聚指令域
支分歧處理原理
棧處理機制:在 GPU 中,每個 warp(通常包含 32 個線程 )會用一個棧(SIMT Stack )來處理分支分歧。當遇到分支指令時,通過棧來管理不同分支路徑的執行狀態。棧中記錄程序計數器(PC)、返回程序計數器(RPC)和活動掩碼(Active Mask)等信息 。活動掩碼標識哪些線程執行當前分支,PC 記錄當前執行指令位置,RPC 用于分支結束后恢復執行位置。
匯聚指令域:分支指令中可加入匯聚指令域,用于協調 warp 內不同線程在分支執行完后的匯聚操作,確保所有線程能正確恢復到統一執行路徑,避免執行混亂。
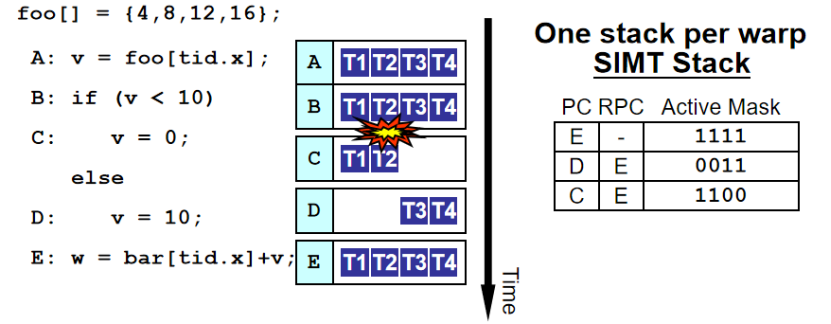
代碼邏輯:
首先定義數組foo[] = {4, 8, 12, 16}?。
語句A: v = foo[tid.x];根據線程索引tid.x從數組foo中取值賦給v?。
接著B: if (v < 10)進行條件判斷,滿足條件(v < 10?)執行C: v = 0;?,不滿足執行D: v = 10;?。
最后E: w = bar[tid.x]+v;進行計算。
執行過程:
初始時,棧記錄狀態E?,活動掩碼為1111?,表示 warp 內所有線程(T1、T2、T3、T4 )都處于活躍執行狀態。
執行到分支指令B時發生分歧,部分線程(T1、T2 )滿足條件走C路徑,部分(T3、T4 )走D路徑,此時棧更新記錄不同分支狀態,如在狀態C時活動掩碼為1100?(T1、T2 活躍 ) ,狀態D時活動掩碼為0011?(T3、T4 活躍 ) 。
當各分支執行完成,通過匯聚指令協調,所有線程在E處匯聚繼續執行后續操作,棧恢復相關狀態以保證執行的正確性。
存儲層次:
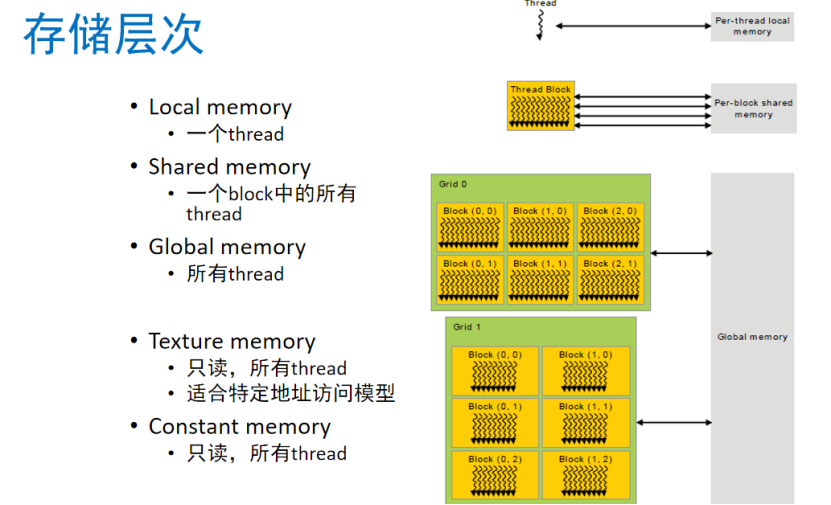
Local memory(本地內存)
作用范圍:每個線程私有的內存空間,僅該線程可訪問。
用途:用于存儲線程執行過程中的臨時變量、局部數據等。比如在一個復雜計算任務中,線程計算過程中產生的中間結果可暫存于此,避免與其他線程數據混淆。
特點:訪問速度相對較快,但容量有限,僅服務于單個線程。
Shared memory(共享內存)
作用范圍:一個線程塊(block)內所有線程共享的內存區域。
用途:方便線程塊內線程間進行數據交換與協作。例如在并行計算矩陣乘法時,可將部分矩陣數據加載到共享內存,線程塊內各線程可共同讀取和處理,減少對全局內存的訪問次數,提升計算效率。
特點:訪問速度快于全局內存,不過容量也有限,且需合理管理以避免數據沖突。
Global memory(全局內存)
作用范圍:所有線程均可訪問的內存空間,是 GPU 內存的主要部分。
用途:用于存儲大規模數據,如大型數組、矩陣等。像在深度學習訓練中,模型的參數、訓練數據等通常存儲于此。
特點:容量大,但訪問速度相對較慢,每次訪問延遲較高,因此優化對全局內存的訪問模式是提高 GPU 性能的關鍵之一。
Texture memory(紋理內存)
作用范圍:所有線程可讀,是一種特殊的只讀內存。
用途:適合特定的地址訪問模型,尤其在圖形渲染領域,用于存儲紋理數據。在一些科學計算中,若數據訪問模式符合其特性(如具有空間局部性 ),也可使用紋理內存加速訪問。
特點:具備一定的緩存機制,能根據特定算法優化數據讀取,提升數據訪問效率。
Constant memory(常量內存)
作用范圍:所有線程可讀的只讀內存。
用途:用于存儲在程序執行過程中不變的常量數據,如數學計算中的常數系數、配置參數等。
特點:通常被緩存在 GPU 芯片內,訪問速度較快,且可減少對全局內存中常量數據的重復讀取。
GPU虛擬化:
一個GPU的SM很多,但是對于單用戶只能用很少的SM,這樣利用率很低;
硬件上把多個SM進行分割成多個切片;
軟件上為每個用戶分配一個SM切片;
使得每個用戶都能滿負荷使用SM;
每個用戶感覺自己擁有了一個GPU。














Java/python/JavaScript/C/C++/GO最佳實現)
——dlib庫安裝、dlib人臉檢測)



