如果不采用寫時拷貝技術 直接fork子進程 會發生什么?

如上圖所示 橙色為父進程所占內存空間? ?綠色為子進程所占內存空間。
如果子進程只是需要做出一點點和父進程不一樣的 其余和父進程均為相同
第一 就會出現復制開銷比較大;第二占用內存空間
所以 對fork復制進程的過程進行了優化 寫時拷貝技術;

子進程講共用父進程的地址,在fork的時候 子進程直接把父進程的表頁復制過來,只有子進程發生寫入(修改)的時候,才會分配內存復制,然后進行相對應的修改
這里進行補充:父子進程復制后 邏輯地址是完全相同的 但是物理地址不一定相同
寫時拷貝技術是一種可以推遲甚至免除拷貝數據的技術
????????傳統的 fork() 系統調用直接把所有的資源復制給新創建的進程。這種實現過于簡單并且效率低下,因為它拷貝的數據也許并不共享,更糟的情況是,如果新進程打算立即執行一個新的映像,那么所有的拷貝都將前功盡棄。Linux 的 fork() 使用寫時拷貝(copy-on-write)頁實現。寫時拷貝是一種可以推遲甚至免除拷貝數據的技術。內核此時并不復制整個進程地址空間,而是讓父進程和子進程共享同一個拷貝。
????????只有在需要寫入的時候,數據才會被復制,從而使各個進程擁有各自的拷貝。也就是說,資源的復制只有在需要寫入的時候才進行,在此之前,只是以只讀方式共享。這種技術使地址空間上的頁的拷貝被推遲到實際發生寫入的時候才進行。在頁根本不會被寫入的情況下(舉例來說,fork() 后立即調用 exec())它們就無須復制了。
????????fork() 的實際開銷就是復制父進程的頁表以及給予進程創建唯一的進程描述符。在一般情況下,進程創建后都會馬上運行一個可執行的文件,這種優化可以避免拷貝大量根本就不會被使用的數據(地址空間里常常包含數十兆的數據)。由于 Unix 強調進程快速執行的能力,所以這個優化是很重要的。
?解釋物理地址和邏輯地址的區別
我們平時所看見的地址 叫做邏輯地址。就如同目錄一樣,而每一個邏輯地址都指向一個物理地址 就如同目錄所對應的頁碼一樣
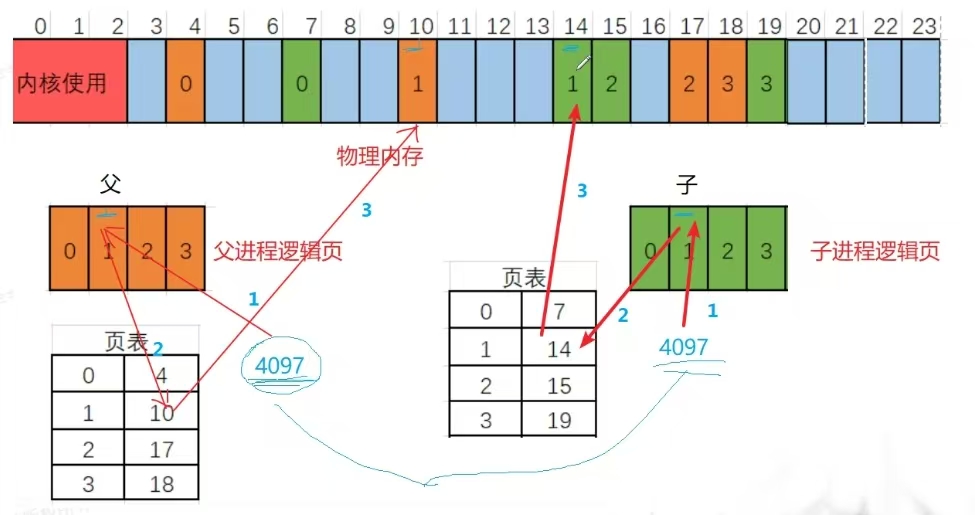
這里我們可以看出來 父子進程的邏輯地址是完全一樣的,但是物理地址不一樣
只有一個進程的時候,不需要顧慮太多,也不用去想邏輯地址和物理地址有什么不一樣的。
如果是多進程的情況下,邏輯地址相同 對應的物理地址并不一定相同,需要具體的去看各自的表頁是否相同(也就是看具體的映射關系)
不同進程的邏輯地址是沒有任何比較的意義的;






)



)








