“湖倉一體”(Data Lakehouse)是一種融合了數據湖(Data Lake)與數據倉庫(Data Warehouse)優勢的新型數據架構。它既繼承了數據湖對多類型數據的靈活存儲能力,也具備數據倉庫對結構化數據的高效查詢與治理能力,成為當前大數據架構演進的重要方向。
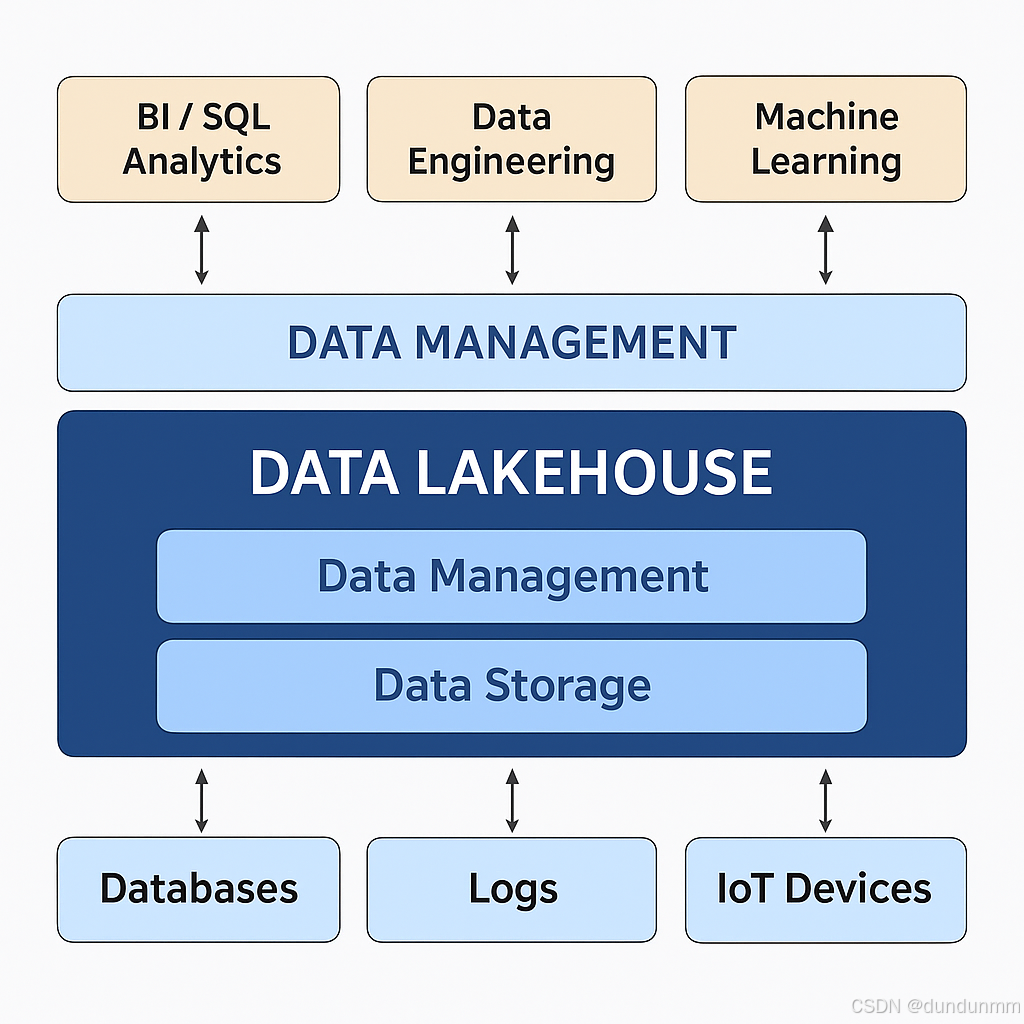
一、什么是“湖倉一體”?
湖倉一體(Data Lakehouse)是指在同一平臺中同時具備數據湖的存儲能力與數據倉庫的分析處理能力的架構模式。該架構支持將結構化、半結構化和非結構化數據統一存儲在數據湖中,并通過增強的數據管理機制與計算引擎,實現類數據倉庫的性能和可靠性,從而打通“存”和“用”的壁壘。
二、核心優勢
-
統一存儲,打破數據孤島
將企業內各業務系統、日志系統、IoT、API等產生的數據統一匯入一個底層存儲系統(如HDFS、S3),避免重復建設和數據搬運。 -
靈活的數據建模機制
支持 schema-on-read(按需建模)與 schema-on-write(預建模型)雙模式,兼顧靈活性與一致性。 -
支持多種計算與查詢引擎
與Spark、Presto、Trino、Flink、Hive、ClickHouse、Delta Lake、Iceberg等組件無縫集成,既支持實時計算,也支持離線批處理。 -
增強的數據治理能力
通過統一元數據管理、數據血緣、數據質量控制,實現數據資產可觀測、可審計、可管理。 -
大規模高性能分析
引入列式存儲、緩存加速、向量化執行等技術,在大數據場景下實現高性能 OLAP 分析,媲美傳統數據倉庫。 -
成本更優
相比傳統數據倉庫高昂的計算與存儲成本,湖倉一體架構使用云對象存儲與開源計算引擎,極大降低 TCO(總體擁有成本)。
三、湖倉一體與傳統架構的比較
| 特征 | 數據湖 | 數據倉庫 | 湖倉一體 |
|---|---|---|---|
| 數據類型支持 | 所有類型 | 結構化 | 所有類型 |
| 存儲成本 | 低 | 高 | 較低 |
| 分析性能 | 低 | 高 | 高 |
| 數據治理 | 弱 | 強 | 強 |
| 架構復雜度 | 中 | 高 | 中 |
| 場景適應性 | AI/探索分析 | BI/固定報表 | 通用(BI + AI + R&D) |
四、典型技術生態(開源/商業)
| 功能模塊 | 開源代表 | 商業代表 |
|---|---|---|
| 存儲引擎 | Apache Hudi、Delta Lake、Apache Iceberg | Databricks Lakehouse、Aliyun DLF、騰訊 TCHouse |
| 計算引擎 | Spark、Flink、Trino、ClickHouse | Snowflake、StarRocks、Kyligence |
| 元數據管理 | Apache Hive Metastore、Amundsen、DataHub | AWS Glue、阿里DataWorks |
| 數據治理 | OpenLineage、Marquez | Collibra、Informatica |
| 可視化分析 | Superset、Redash | Tableau、Power BI、Quick BI |
五、典型應用場景
-
數據要素平臺與數據資產交易:湖倉一體架構為“數據可用不可見”的共享模式提供高性能、低成本的底座支撐。
-
金融風控與合規審計:通過元數據血緣和數據審計功能,滿足強治理和審計要求。
-
多模態數據分析:圖像、文本、行為軌跡等數據整合分析,適合AI場景。
-
政務大數據平臺:支撐數據統一匯聚、共享交換、授權分析等政務需求。
-
工業互聯網與IoT平臺:處理高并發、多維度、時序數據,并進行復雜實時分析。



)










前端頁面性能檢測)

)

