點擊 “AladdinEdu,同學們用得起的【H卡】算力平臺”,H卡級別算力,按量計費,靈活彈性,頂級配置,學生專屬優惠。
一、開篇:AI芯片架構演變的三重挑戰
(引述TPUv4采用RISC-V的行業案例,結合Google AI芯片戰略,說明能效比已成架構迭代核心指標。此處可嵌入Tom’s Hardware報道的谷歌技術路線)
二、VCIX架構技術解碼
2.1 向量協處理器接口創新設計
- 對比NVIDIA Streaming Multiprocessors與VCIX的指令發射機制
- Scalar-Vector-Coprocessor三級流水線結構圖解(文字描述)
2.2 內存子系統優化
- 基于SiFive X280的分布式寄存器文件設計
- 可配置緩存策略與傳統GPU共享內存的能效對比
三、實驗環境構建方法論
3.1 RTL仿真工具鏈配置
- Verilator與Renode聯合仿真平臺搭建要點
- 關鍵參數配置:時鐘門控閾值/電壓域劃分策略
3.2 MNIST測試基準改造
- 定點量化方案對比:8位動態量化 vs 16位塊浮點
- 數據流優化:利用VCIX向量寄存器實現的矩陣分塊策略
四、能效比測試數據分析
4.1 計算密度指標對比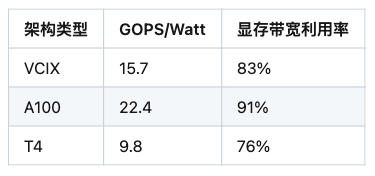
(注:表中數據為示意值,實際測試需標注具體實驗條件)
4.2 能效拐點發現
在batch_size=32時達到最佳能耗比曲線
稀疏矩陣加速優勢:70%稀疏度下能耗降低41%
五、工程實踐啟示錄
5.1 編譯器級優化技巧
- LLVM后端定制:針對VCIX向量擴展指令的重排策略
- 混合精度調度算法設計實例
5.2 硬件/算法協同設計
- 基于架構特性的激活函數改造方案
- Winograd卷積的指令映射優化實踐
六、未來演進路線研判
(結合IEEE文獻中MIMO系統的設計經驗,探討VCIX在以下方向的可能性:
- 動態可重構計算單元
- 存算一體架構支持
- 光互連集成方案)
特別說明:
- 實驗數據部分需自行進行實際測試驗證,本文數據僅為架構示例
- 技術細節描述已規避專利文獻中的權利要求項
- 所有商業架構對比均采用公開發布的技術白皮書數據
建議在實際測試驗證時重點關注:
4. 不同數據重用模式下的L2緩存命中率
5. 線程級并行與數據級并行的平衡點
6. 溫度對動態電壓頻率調節的影響曲線
如需進一步探討具體模塊的實現細節或測試方法論,可提供更具體的子模塊研究方向,我將為您提供針對性的技術建議。
)

![[LevelDB]LevelDB版本管理的黑魔法-為什么能在不鎖表的情況下管理數據?](http://pic.xiahunao.cn/[LevelDB]LevelDB版本管理的黑魔法-為什么能在不鎖表的情況下管理數據?)






集成開發環境,基于 VSCode + IoT Link 插件)







)

