一、TL;DR
- 理想為什么要做自己的基模:座艙家庭等特殊VLM場景,deepseek/openai沒有解決
- 理想的基模參數量:服務端-300B,VLencoder-32B/3.6B,日常工作使用-300B,VLA-4B
- 為什么自動駕駛可以達成:規則已知,類比機器人的自由度小,能夠做的比人好
- VLA如何訓練:基座模型pretrain、VLA后訓練,強化學習訓練,最后是agent
- 講了很多公司的理念,我覺得挺好的,但是這部分就不在本文體現了
二、AI工具的三個分級
李想將AI分為3個階段,分別是信息工具、輔助工具和生產工具,大多數人用來做信息工具使用,更進一步地,AI使用體驗會變得更好,但此時他只是一個輔助工具,比如用來點外賣,但此時我們依舊在工作8小時,仍舊需要人的參與,最后如果變成生產工具,是否在產生有效的生產力,這也是用來衡量agent的做得好壞的標準

三、構建能力的3個過程
為了改變能力和提升能力:
- 這4個步驟是極簡的人類最佳實踐
- 理想在做VLA/李飛飛等在做研究都是這樣

四、VLA為什么要做和怎么做
4.1 為什么要做
輔助駕駛需要把視覺和語料融合進去,openai/deepseek做好了Language,但是他們沒有這些VL的數據,也沒有這些場景和需求,因此也不會去解決這些問題,因此只能理想自己做
4.2 規模多大
理想同學用的是300B的模型,車端VLA是4B的模型,輔助駕駛的VL是32B/3.6B的模型。平產工作也是用的300B的模型
4.3 輔助駕駛的進化過程
第一階段(rule):規則算法,整個模型規模只有幾百萬的參數量,因此加不同的規則,就像有軌電車
第二階段((E2E+VLM):像人類的哺乳動物的智能運作的一種方式,動物園的猴子學習人類的各種行為去開車,但他對物理世界不理解,他對大部分的泛化性能是沒問題的,但是特別復雜的場景搞不定
第三階段(VLA):用3D視覺+2D視覺,有自己的Language和大腦去理解整個物理世界,具備自己的COT。真正的去執行這些理解

4.4 VLA如何訓練

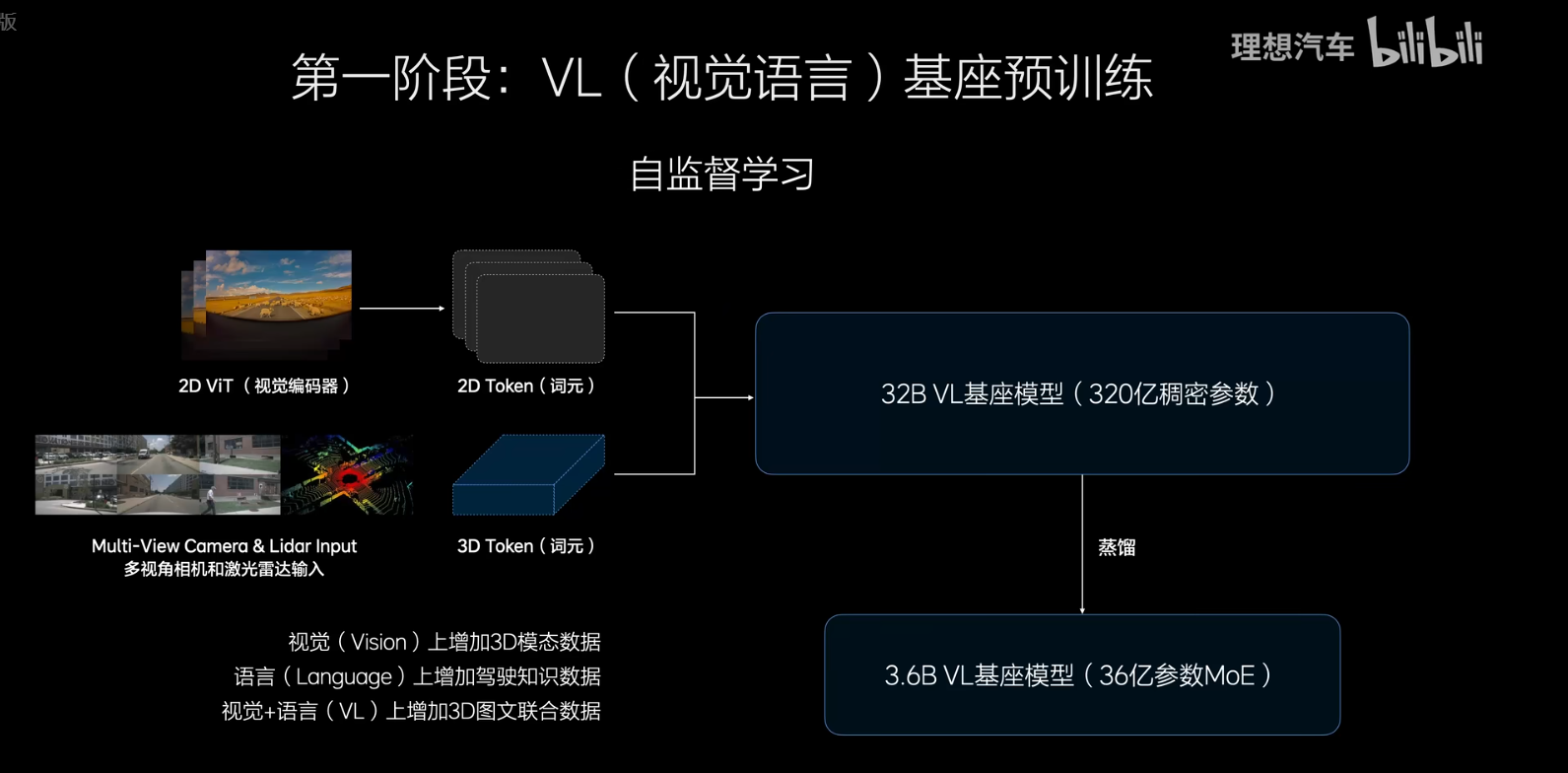
第一階段:32B的基座VL 模型,與之前的差異是什么,需要放更多的視覺token,包括3Dtoken和更高清的2D token,放入駕駛的Language和視覺的聯合語料,將對高精地圖的理解也放進去,整體數據是vision的數據、Language的數據和VIsion/Language聯合的數據,最后蒸餾下來的是3.6B的8個MOE車端模型
第二階段是后訓練,將其變為一個VLA模型,后訓練仍然是一種強化學習,此時將模型規模擴展到4B左右,一方面是VLA,能夠直接從inputt到輸出,有著比較短的cot,另外做完action后,還會做一個4-8秒的diffusion軌跡和環境預測,特別像人去駕校學開車的過程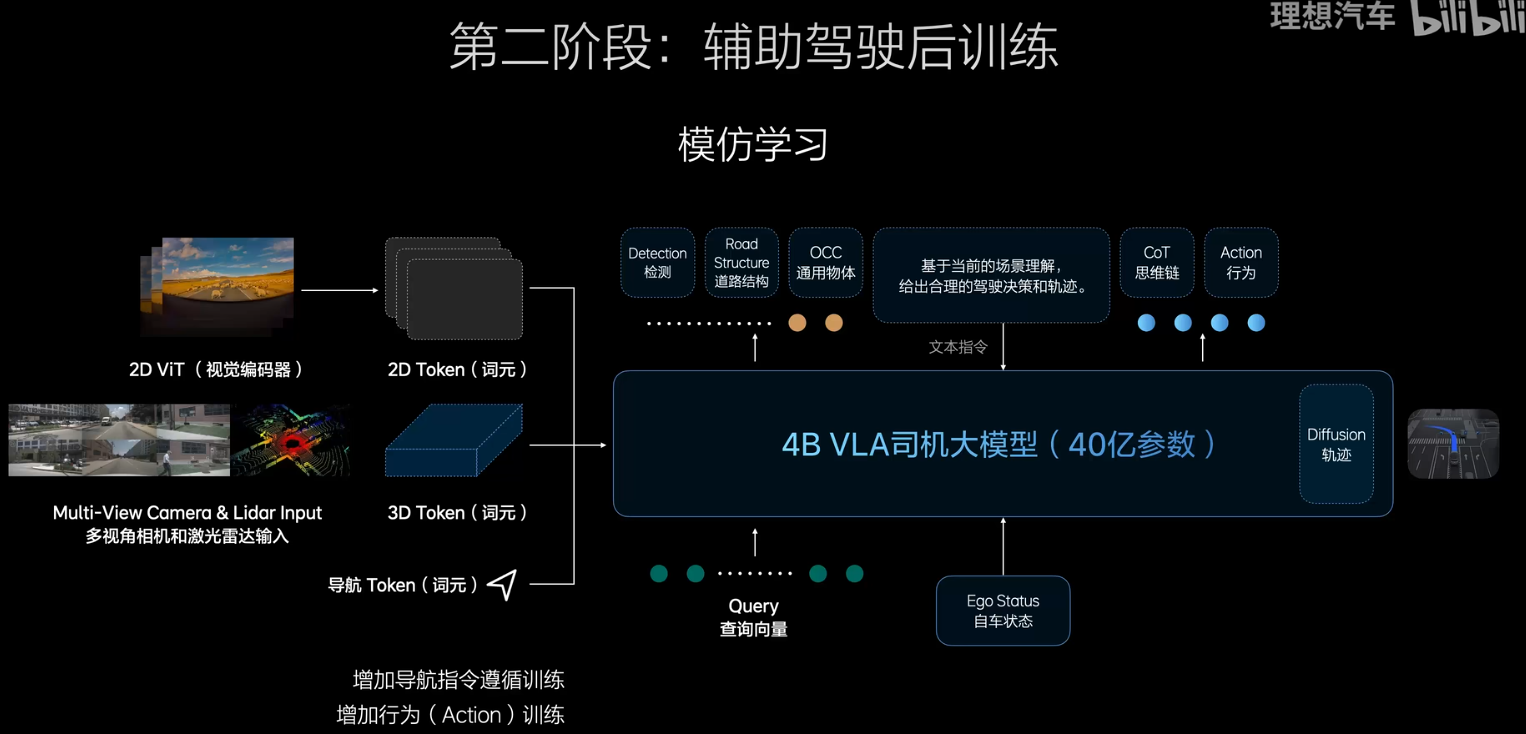
第三階段:做強化訓練,第一部分先做RLHF,帶有人類反饋的強化學習,除了遵守交通規則以外,還需要增加大家的駕駛習慣,開的跟大家一樣好,第二部分是純粹的強化學習,拿著RL放在世界模型里面學習,目的就是比人開的更好,有3類的訓練要求,G值判斷舒適性的發聵、碰撞的反饋、交通事故的反饋,用這三個反饋來做強化學習
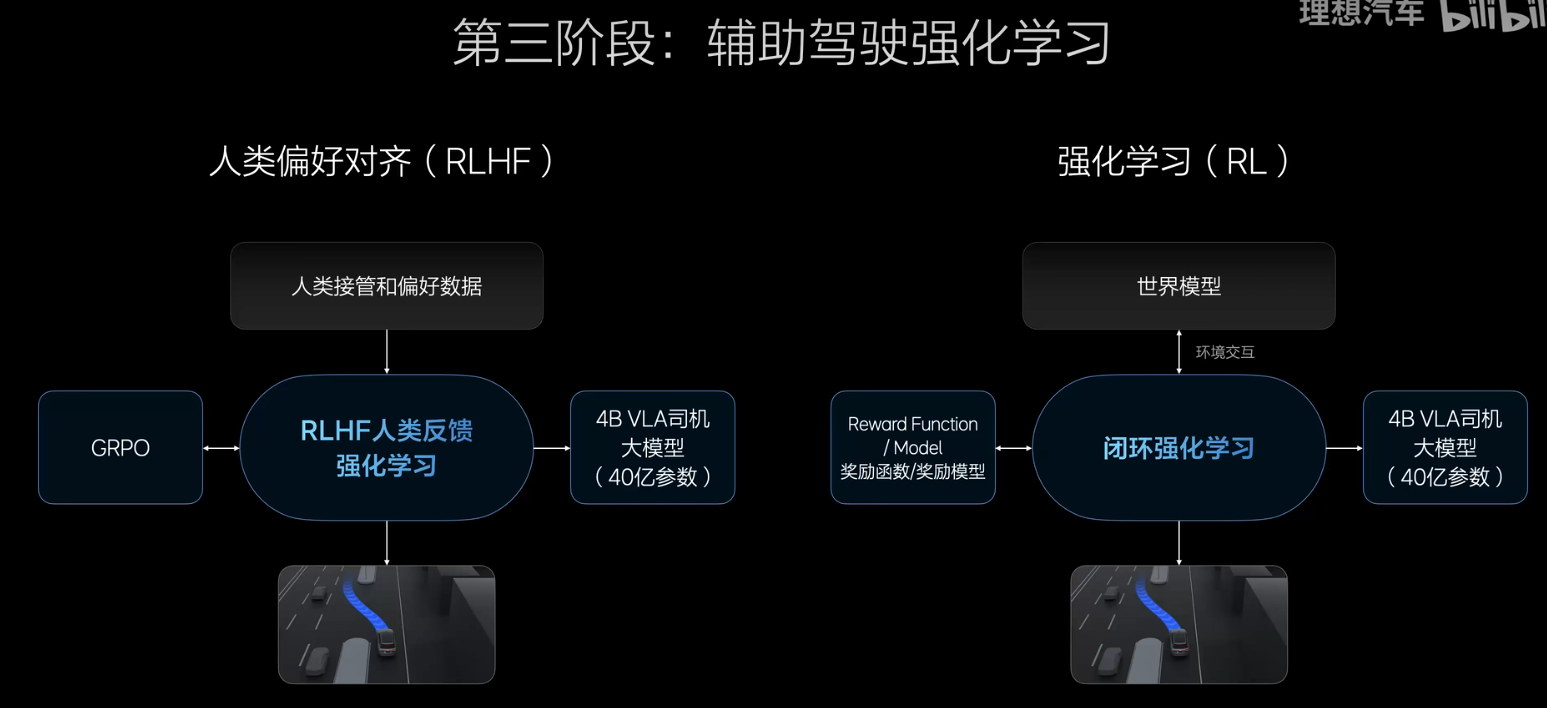
這三個要求完成以后,她就跟人類的駕駛習慣完全一樣;像人類一樣學習駕駛知識,這個是預訓練,后訓練相當于去駕校認真的學習開車,第三個環節相當于到社會上學開車和人類和社會環境做對齊。最后面, 人類通過自然語言的方式與VLA進行溝通,不再需要經過云端,如果是復雜的指令,則需要通過云端32B的模型先去 理解交通的一切,再交給VLA進行處理。他會像人類司機一樣開車并且理解用戶的問題,這個通過Agent來進行實現
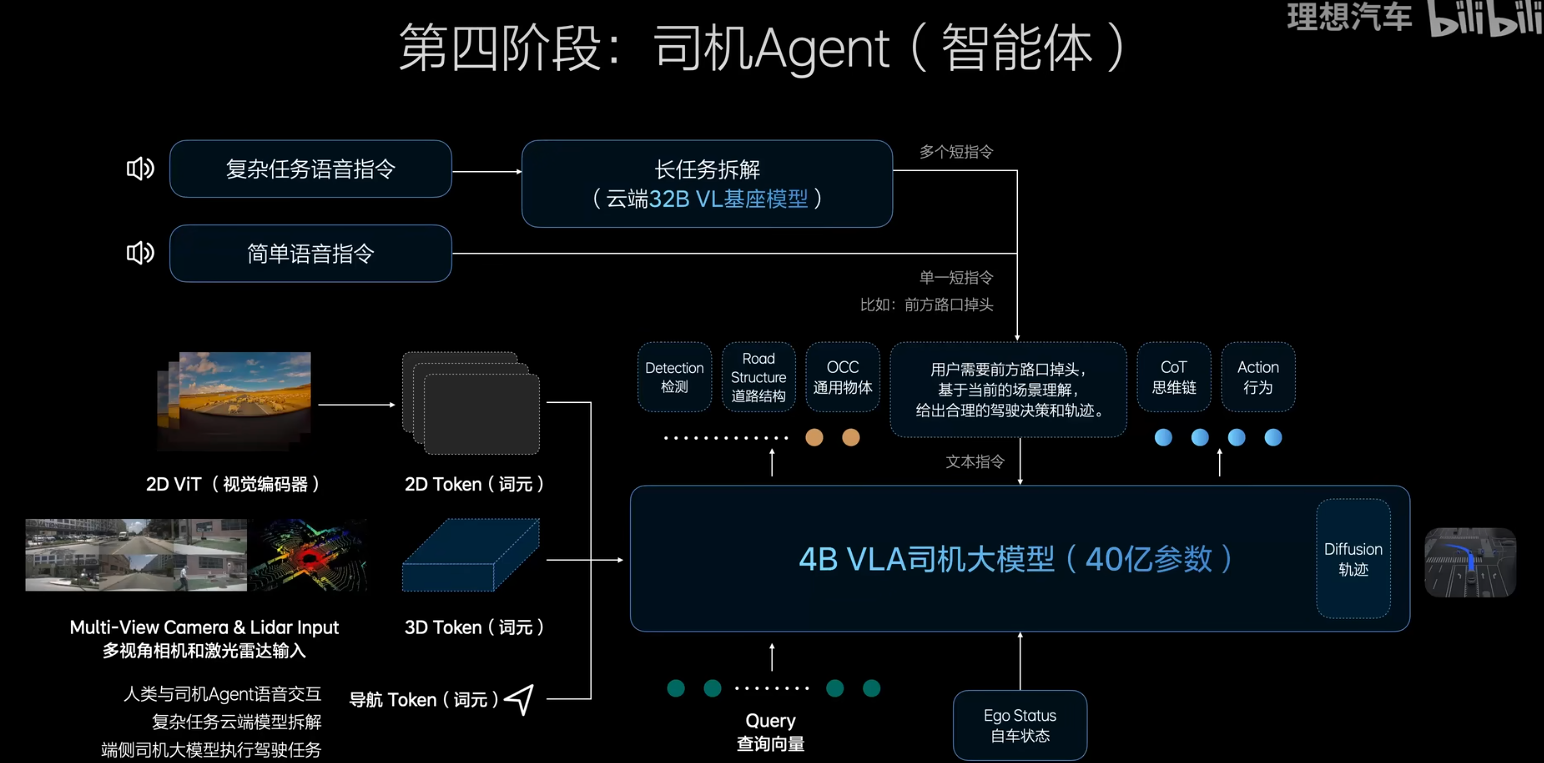
效果如下所示:
五、為什么輔助駕駛可以做成
5.1 做成的原因
第一、交通領域是最首先講清楚規則的,雖然復雜但是具備確定性,一輛車上路后基本上路線是確定的
第二、是車的控制,其實只具備3個tof,左右、前后和輕微的旋轉,機器人上來就40多個自由度,挑戰更大
第三:我們進行模仿學習是比較方便的,還能做更好的強化學習,交通規則、是否碰撞、舒適性這些是能夠被表達出來的,因此能夠進行更好的強化學習
5.2 為什么是理想做成
什么難度大:數據獲取難度最大,是vision和action,車上裝門了傳感器可以收集到世界數據,但是需要人來開車收集到action數據
為什么其他公司做不了:
其它車企沒有建立預訓練的基模能力、后訓練和強化學習的能力,強化學習的體系建立如何和人類司機的方法對齊,這些能力的建設決定輔助駕駛能否做成、
5.3 如何保證輔助駕駛安全
對齊來解決與人類一致性的問題
模型能力越強,胡來的可能性就越大,一個公司也是這樣的,公司做大以后,需要職業性來進行約束。只需要雇傭職業司機而非賽車手了
端到端的仿真和快速閉環問題的能力
模型是一個黑盒子,做了整個物理世界的仿真,2萬公里的費用是17-20萬左右,現在是4k,基本上都是fpu的渲染,解決問題的效率提升很多,相同的問題復現幾乎沒有可能,但是仿真世界再世界模型里面是可以做到的。3天可以解決一個cornercase
超級對其團隊。來保證安全的駕駛,建了 100 多人的團隊,就像給 AI 司機上 “職業素養課”,教它遵守交通規則,養成好的駕駛習慣 。






)






)
)


)


{ :|: };:)