文章目錄
- 1. 主從復制
- 1.1 主從復制是怎么個事🤔
- 1.2 拓撲結構
- 1.2.1 一主一從拓撲
- 1.2.2 一主多從拓撲
- 1.2.3 樹形拓撲
- 1.3 主從復制原理
- 1.3.1 復制過程
- 1.3.2 數據同步PSYNC
- 1.3.2.1 replicationid/replid (復制id)
- 1.3.2.2 復制偏移量維護
- 1.3.3 psync運行流程
- 1.3.4 全量復制
- 1.3.4.1 全量復制流程
- 1.3.5 部分復制
- 1.3.6 復制積壓緩沖區
- 1.3.7 實時復制
1. 主從復制
在分布式系統中,有一個非常關鍵的問題:單點問題。
- 如果某個服務器程序,只有一個節點:
- 可用性問題:如果這個機器掛了,意味著服務就中斷了。
- 單點服務器的性能和并發量也是比較有限的。
引入分布式系統,主要就是為了解決上述的單點問題。在分布式系統中,往往有多個服務器 來部署redis服務,從而構成一個redis集群,此時就可以讓這個集群給整個分布式系統提供服務。
- Redis的幾種部署方式:
- 主從模式
- 主從 + 哨兵模式
- 集群模式
1.1 主從復制是怎么個事🤔
在若干個Redis節點中,有一個是主節點,其余的是從節點。從節點上的數據要隨著主節點變化,從節點上的數據要和主節點保持一致。
本來在主節點上保存一堆數據,引入從節點之后,就是要把主節點上的數據復制到從節點上,后續如果主節點的數據有修改,也會同步到從節點上。
在實際業務場景中,讀操作往往要比寫操作更加頻繁。在Redis主從模式中,從節點上的數據,不允許修改,只能讀取數據;主節點可以進行讀操作和寫操作。
主從復制是只能從“主”到復制到“從”,不能從“從”到主復制。
上面我們說單點問題,如果這個節點掛了,那么整個Redis服務就掛了。使用主從結構來進行部署,再采用異地多活(在不同的機房進行部署,防止全部部署在一個機房中,如果這個機房掛了,那么Redis服務也就掛了)的方式進行部署,就大大保證了可用性。
- 主節點和從節點之間是通過網絡來進行傳輸的(TCP),TCP內部支持nagle算法,這個算法是默認開啟的。
- 開啟nagle算法:會增加tcp的傳輸延遲,但是會減少網絡帶寬。
- 關閉nagle算法:會減少tcp的傳輸延遲,會增加網絡帶寬。
Nagle算法
- 問題: 當程序頻繁的發送體積非常小的數據,每個數據包的有效載荷可能只有1-2個字節。然而每個網絡數據包都包含至少40個字節的TCP和IP頭部信息,發送一個字節的數據實際需要傳輸41個字節,這樣不僅網絡利用率極低,還會增加路由器的負擔,加劇網絡擁塞,影響整體網絡效率。
- 算法原理:
- 當發送方應用程序第一次調用send寫入數據時,即使數據量很小,系統也會立即發送這個數據包。
- 在收到第一個數據包的確認(ACK)之前:
- 如果緩沖區中積累的數據達到了最大報文長度,此時發送方會立即將這個滿載的大數據包發送出去。
- 在這個過程中一直沒有積累到最大報文長度,當收到了第一個數據包的ACK確認,發送方也會立即將緩沖區內積累的所有數據包打包成一個數據包發送出去。
1.2 拓撲結構
1.2.1 一主一從拓撲
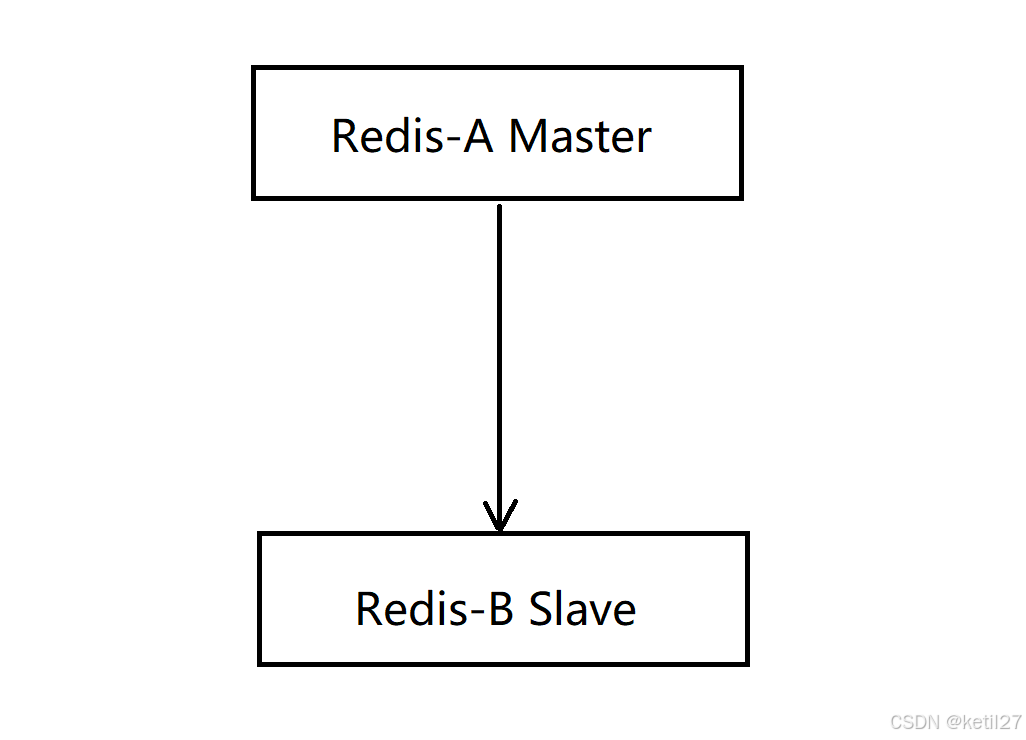
在主節點上進行讀操作和寫操作,在從節點上進行讀操作。但是如果寫請求太多,此時會給主節點造成一些壓力。
可以通過關閉主節點的AOF,只在從節點上開啟AOF,從而減小主節點的壓力。但是主節點關閉了AOF就會有一個缺陷,如果主節點掛了,不能自動重啟。如果自動重啟了,沒有AOF文件,就會丟失數據,進一步的主從同步,會把從節點的數據也給刪了。
當主節點掛了之后,讓主節點從從節點獲取AOF文件,再啟動,就可以解決上面的問題。
1.2.2 一主多從拓撲
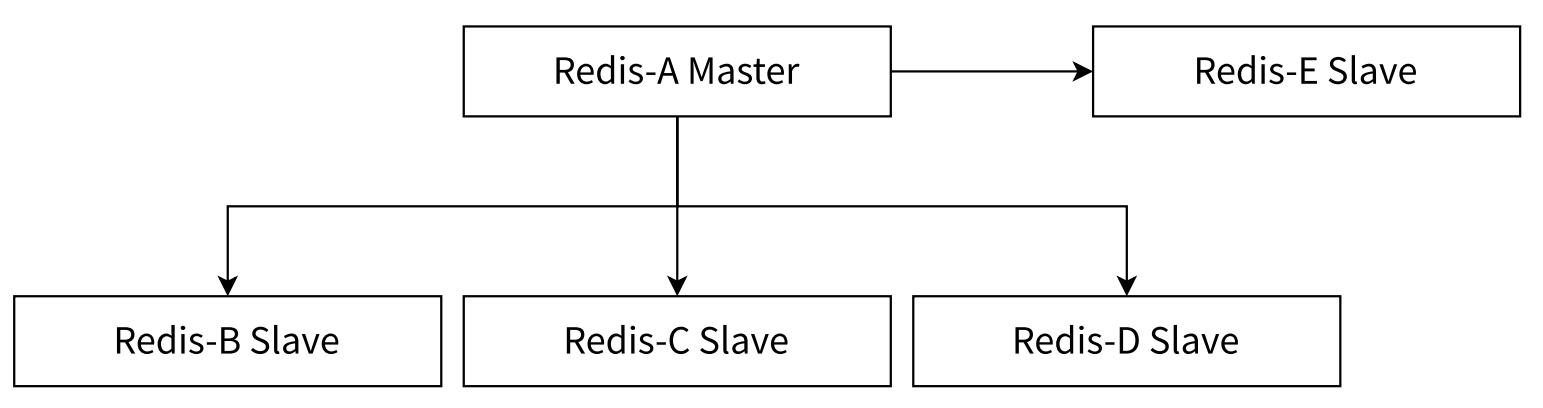
這種一主多從的結構,在從節點越多,主節點發生修改,就要同步到從節點上多份,加大了主節點的負載。
1.2.3 樹形拓撲
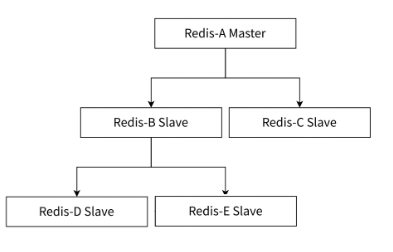
主節點只需要同步部分從節點,剩下的節點交給從節點慢慢的去向從節點的從節點進行同步,這樣主節點就不需要那么高的網絡帶寬了。
但是這樣一旦主節點的數據進行了修改,同步是延時就變的更長了。
1.3 主從復制原理
1.3.1 復制過程
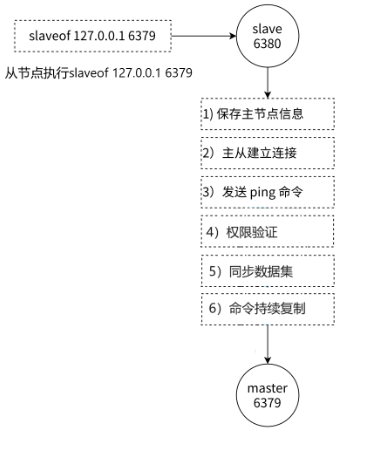
在 Redis 主從復制中,始終是由從節點主動發起并向主節點建立連接的。
1. 從節點保存主節點的ip和端口號。
2. 從節點與主節點建立socket連接(TCP連接,三次握手)。
3. 驗證主節點是否能夠正常工作,發送ping.
4. 是否需要密碼驗證?
5. 數據同步。
6. 進入命令傳播階段,主節點持續發送寫命令。
1.3.2 數據同步PSYNC
1.3.2.1 replicationid/replid (復制id)
replicationid是主節點生成的,主節點在啟動時,或者晉升為主節點時都會生成repplicationid(即使是同一個主節點,每次重啟,replicationid也是不一樣的)。從節點和主節點建立了復制關系就會從主節點這邊獲取到主節點的replicationid。
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_replid:1da596acecf5a34b4b2aae45bd35be785691ae69
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
master_replid 和 master_replid2
- 假設現在是一主一從結構,主節點是A,從節點是B。主節點A會生成replid,從節點B會獲取到A的replid。
- 如果A和B在通信過程中出現了一些網絡抖動,B就可能以為A掛了,B就會自己成為主節點,于是B給自己生成了一個新的master_replid。雖然B自己生成了一個,但是它也會用master_replid2記錄之前那個舊的replid。
- 如果后續網絡恢復了,B就可以根據master_replid2找到之前的主節點,之前的主節點會作為B的從節點繼續提供服務。
- 如果后續A節點的網絡沒有恢復,B就繼續充當主節點處理后續的請求。
1.3.2.2 復制偏移量維護
offset就是在描述進度,主節點和從節點都會維護自己的偏移量。
主節點會收到很多修改操作的命令,每個命令都要占用幾個字節,主節點會把這些每個命令的字節數進行累加。
從節點的偏移量就描述了現在從節點從主節點那里同步數據同步到了哪里。
如果從節點的偏移量和主節點的偏移量一樣了,那么就代表此刻從節點和主節點中的數據完全保持一致了。
1.3.3 psync運行流程
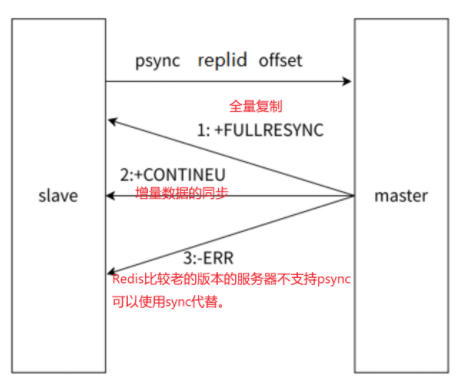
從節點發送psync時帶有replid 和offset值,主節點就根據psync的參數來進行判定,這次是按照全量復制合適還是部分復制合適。
replicationid:描述數據的來源。
offset:描述數據的復制進度。
psync可以從主節點獲取全量數據,也可以獲取一部分數據:
1. offset = -1,獲取全量數據。
2. offset = 具體的正整數,從當前偏移量開始獲取。
1.3.4 全量復制
全量復制?般用于初次復制場景,Redis 早期支持的復制功能只有全量復制,它會把主節點全部數據?次性發送給從節點,當數據量較?時,會對主從節點和網絡造成很?的開銷。
全量復制的時機:
- 從節點首次和主節點進行數據同步。
- 主節點不方便進行部分復制的時候。
1.3.4.1 全量復制流程
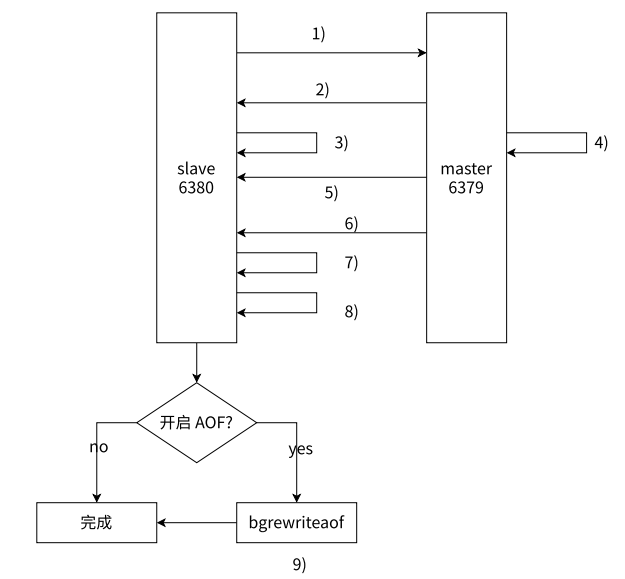
-
從節點發送PSYNC命令請求同步,由于是第一次進行復制,從節點沒有主節點的replid和復制偏移量,所以發送pysnc ? -1。
-
主節點根據命令,判斷出來要進行全量復制,回復+FULLRESYNC。
-
從節點就收主節點的運行信息并進行保存。
-
主節點執行bgsave命令生成RDB,同時啟動復制積壓緩沖區。
-
主節點將RDB文件發送到從節點,從節點保存RDB數據到本地硬盤。
-
主節點將從生成RDB到接收完成期間主節點執行的寫命令,寫入到復制緩沖區中,等從節點保存完RDB文件之后,主節點再將緩沖區中的數據不發給從節點,不發的文件仍按以rdb的二進制格式追加寫入到收到的rdb文件中,保持主從一致性。
-
從節點清空舊數據。
-
從節點加載RDB文件得到與主節點一致的數據。
-
如果從節點已經開啟了AOF持久化,在上述的加載過程中,從節點就會產生出很多的AOF日志,此時殘生的AOF日志,整體來說,可能會產生一定的冗余信息,因此會針對AOF日志進行重寫。
主機點生成的RDB二進制文件,不是直接保存到文件中的,而是直接進行網絡傳輸了,從節點也是直接把接收到的數據進行加載。這樣就是無硬盤模式(省下了一系列是讀硬盤和寫硬盤的操作)。
runid 和 replid
- runid:每個節點都不同,是用來標識一次redis的運行的。runid主要是用在支撐redis哨兵這個功能的。
- replid:具有主從關系,主從節點是相同的。
1.3.5 部分復制
?于處理在主從復制中因網絡閃斷等原因造成的數據丟失場景,當從節點再次連上主節點后,如果條件允許,主節點會補發數據給從節點。因為補發的數據遠小于全量數據,可以有效避免全量復制的過高開銷。
部分復制的時機: 從節點已經從主節點上復制過數據了。因為網絡抖動或者從節點重啟了,從節點需要重新從主節點這邊同步數據。
1.3.6 復制積壓緩沖區
積壓緩沖區數據是內存中的簡單固定長度的隊列,會記錄最近一段時間主節點修改的數據。
從節點通過心跳包發送給主節點自己的offset進度,主節點判斷這個進度是否在積壓緩沖區之內,如果確實是在擠壓緩沖區內,就進行部分復制,否則就進行全量復制。
1.3.7 實時復制
從節點已經和主節點同步好數據了,但是之后,從節點還會源源不斷的收到修改的請求,需要把這些同步給從節點。
從節點和主節點之間會建立TCP的長連接,然后主節點把自己收到的修改請求,通過TCP長連接,發送給從節點,從節點再根據這些修改請求,修改內存中的數據。
心跳包機制
在進行實時復制的時候,需要保證連接處于一個可用的狀態。
- 主節點默認每隔10s給從節點發送一個ping命令,從節點收到之后就相應pong.
- 從節點默認每隔一秒鐘就給主節點發送一個特定的請求,上報當前從節點復制數據的offset。
實時復制是主從節點保持同步的常態過程;部分復制是網絡中斷后恢復同步的補救措施。






)












語法 glue函數)