領域:Object tracking
It aims to infer the location of an arbitrary target in a video sequence, given only its location in the first frame
問題/現象:
-
Anchor-based Siamese trackers have achieved remarkable advancements in accuracy, yet the further improvement is restricted by the lagged tracking robustness.
即Anchor-based Siamese trackers精確度還行但魯棒性不行 -
In prior Siamese tracking approaches, the classification confidence is estimated by the feature sampled from a fixed regular region in the feature map. This sampled feature depicts a fixed local region of the image, and it is not scalable to the change of object scale. As a result, the classification confidence is not reliable in distinguishing the target object from complex background.
分類置信度是通過從固定的局部區域得到的特征估計出來的,所以當物體尺度變化的時候它并不會改變。所以當要從復雜的背景區分目標物體時,這個分類器是不可靠的。 -
regression network in anchor-based methods is only trained on the positive anchor boxes. This mechanism makes it difficult to refine the anchors whose overlap with the target objects are small.This will cause tracking failures especially when the classification results are not reliable. The regression network is incapable of rectifying this weak prediction because it is previously unseen in the training set.原因是因為
anchor-based methods的回歸網絡僅在正樣本(當框和目標物體的重合超過一個標準時,稱這個框為正樣本)上訓練(訓練集中只有分類正確的時候,offset是什么。沒有分類錯誤的樣本)。這使得它很難去refine anchors當anchor和目標物體的重疊很少時(因為這個時候的框為負樣本,previously unseen in the training set.,先前/訓練時沒見過這樣的)。也就是當前面分類錯誤的時候,后面的回歸網絡也沒有修正這個不準確的預測的能力
can we design a bounding-box regressor with the capability of rectifying inaccurate predictions?
YES!
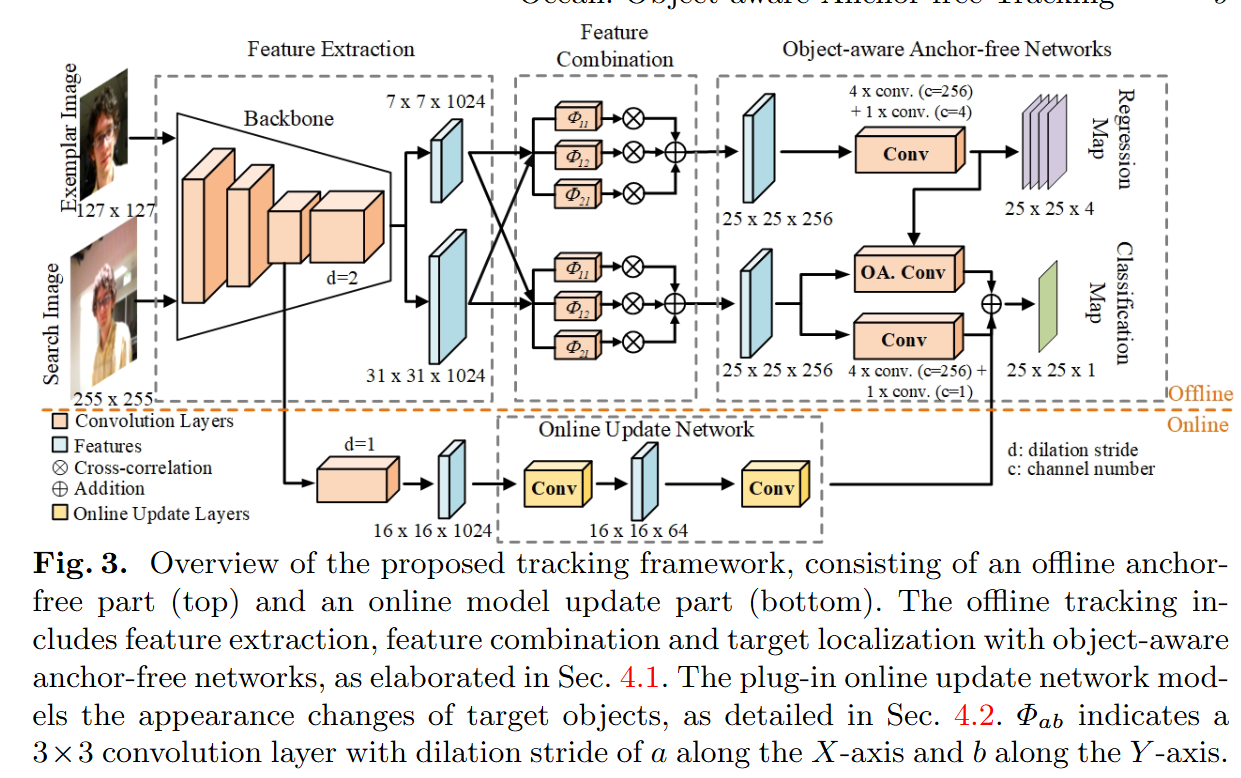
這篇文章提出的跟蹤器哈哈:Object-aware Anchor-Free Networks(Ocean)
(對應上述問題123)
-
consists of two components: an object-aware classification network and a bounding-box regression network.(anchor free的) -
The classification is in charge of determining whether a region belongs to foreground or background
分類器分出前景和背景(分類只采樣距離中心近的點為正樣本)(同時使用了object-aware feature和regular-region feature。與之前anchor free方法,如FCOS不同的是增加了一個object-aware feature,且FCOS分類和回歸都是計算所有落在GT內的點;)
introduce a feature alignment module to learn an object-aware feature from predicted bounding boxes. The object-aware feature can further contribute to the classification of target objects and background.
同時引進一個特征對齊的模塊來學習object-aware feature,使得更好的實現背景和目標物體之間的區分,也獲得了一個全局的外觀描述。
實現:將卷積核的固定采樣位置對齊到預測的回歸box(圖2c)。回歸box是通過bounding-box regression network得來的哦。對于classification map上的每個位置(dx, dy),都有一個對應的回歸預測框M=(mx, my, mw, mh),mx,my表示中心,mw,mh表示寬高。目標就是從候選框M中采樣特征來預測(dx, dy)的分類得分。 -
regression aims to predict the distances from each pixel within the target objects to the four sides of the groundtruth bounding boxes.
回歸用來預測目標物體中的每個像素點到真實錨框的四條邊的距離。(訓練時候的樣本是all the pixels in the groundtruth bounding box)
Since each pixel in the groundtruth box is well trained, the regression network is able to localize the target object even when only a small region is identified as the foreground.
就算只有很小一塊區域被分類為前景,由于each pixel in the groundtruth box is well trained,所以該回歸有修正前面不太正確的預測的可能性
(這樣理解:anchor-based一個框是一個樣本,這里一個像素是一個樣本。前面的訓練集是正確的框怎么偏移到groundtruth,后面的是每個像素到框的距離。那么當框和目標物體重疊很小但被預測為正確的框的時候。對于anchor-based,因為實際上它是負樣本,所以沒見過,沒訓練過。但對于anchor free的,即使預測為前景實際也為前景的部分很小,那也還是有實際為前景且被正確預測為前進的像素點存在的,訓練的時候見過,所以有糾正預測的可能)
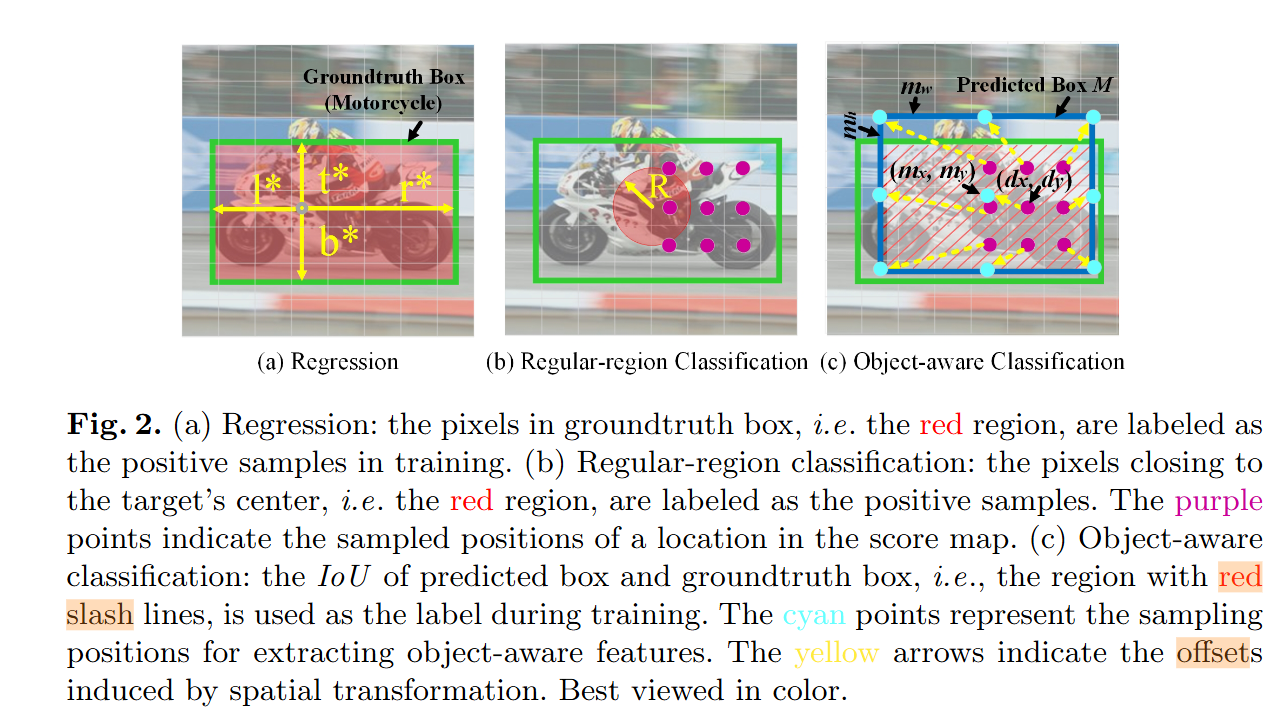
- 回歸的時候所有位于
groundtruth box內的像素都被標注為正樣本 - 對于
Regular-region classification,靠近目標中心點的一小部分區域內的像素為正樣本 - 對于
Object-aware classification,the IoU of predicted box and groundtruth box被用作標簽。
more details are provided in this paper:Ocean: Object-aware Anchor-free Tracking
補充(超簡版):
anchor-based methodsVSanchor free methodsanchor-based:- 相比于
anchor free,它使用預定義的anchor框來匹配真實的目標框 - 過程:生成
anchor boxes,判斷每個anchor box為foreground還是background(二分類),對anchor box進行微調(這部分就是前文提到的refine),使得positive anchor和真實框(Ground Truth Box)更加接近(使用regression)
- 相比于
anchor free:Different from anchor-based methods which estimate the offsets of anchor boxes, anchor-free mechanisms predict the location of objects in a direct way.- 基于角點的/中心點的/全卷積的
- 目標跟蹤VS目標檢測
- 目標檢測是事先針對特定目標的,比如人頭檢測、動物檢測,目標跟蹤則是對于任意目標的跟蹤,即事先是不知道跟蹤的具體目標的。(但是檢測器也可以根據人們需要檢測的目標進行初始化,這樣好像又有點像跟蹤器了->基于檢測的目標跟蹤。而且感覺基于檢測的的目標跟蹤有點 殺雞用牛刀 了吧,因為根本不需進行目標識別,不需要每一幀都去檢測,就只是目標跟蹤就好了)
- 理想的跟蹤器應該不需要每一幀都暴力檢測目標所在的位置,而是可以充分利用幀間信息,目標周圍的環境信息,甚至根據周邊環境推測得到的三維信息等,更加高效的確定目標所在的位置
- 再想象一個場景:一個被設計用來檢測行人的目標檢測器,如果將其應用到馬路場景上,檢測器將會檢測到馬路上的大量行人。如果只想跟蹤某個行人,那么檢測器的結果并不是人們想要的。但這時跟蹤器就完全不一樣了,給跟蹤器指定初始跟蹤行人后,它將可以在后續的過程中只跟蹤指定的行人
![[Java] 方法和數組](http://pic.xiahunao.cn/[Java] 方法和數組)


閃存讀寫保護法 加密與解密)











)


)
