DeepSeek-R1論文筆記
- 1、研究背景與核心目標
- 2、核心模型與技術路線
- 3、蒸餾技術與小模型優化
- 4、訓練過程簡介
- 5、COT思維鏈(Chain of Thought)
- 6、強化學習算法(GRPO)
- 7、冷啟動
- **1. 冷啟動的目的**
- **2. 冷啟動的實現步驟**
- **3. 冷啟動的作用**
- **典型應用場景**
- 匯總
- 一、核心模型與技術路線
- 二、蒸餾技術與小模型優化
- 三、實驗與性能對比
- 四、研究貢獻與開源
- 五、局限與未來方向
- 關鍵問題
- 1. **DeepSeek-R1與DeepSeek-R1-Zero的核心區別是什么?**
- 2. **蒸餾技術在DeepSeek-R1研究中的核心價值是什么?**
- 3. **DeepSeek-R1在數學推理任務上的性能如何超越同類模型?**
DeepSeek-R1
? 標題:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
? 時間:2025年1月
? 鏈接:arXiv:2501.12948
? 突破:基于DeepSeek-V3-Base,通過多階段強化學習訓練(RL)顯著提升邏輯推理能力,支持思維鏈(CoT)和過程透明化輸出。
1、研究背景與核心目標
-
大語言模型的推理能力提升
近年來,LLM在推理任務上的性能提升顯著,OpenAI的o1系列通過思維鏈(CoT)擴展實現了數學、編碼等任務的突破,但如何通過高效方法激發模型的推理能力仍需探索。- 傳統方法依賴大量監督數據,而本文探索**純強化學習(RL)**路徑,無需監督微調(SFT)即可提升推理能力。
-
核心目標
- 驗證純RL能否驅動LLM自然涌現推理能力(如自我驗證、長鏈推理)。
- 解決純RL模型的局限性(如語言混合、可讀性差),通過多階段訓練提升實用性。
- 將大模型推理能力遷移至小模型,推動模型輕量化。
2、核心模型與技術路線
-
DeepSeek-R1-Zero
- 純強化學習訓練:基于DeepSeek-V3-Base,使用GRPO算法,無監督微調(SFT),通過規則獎勵(準確性+格式)引導推理過程。
- 能力涌現:自然發展出自我驗證、反思、長鏈推理(CoT)等行為,AIME 2024 Pass@1從15.6%提升至71.0%,多數投票達86.7%,接近OpenAI-o1-0912。
- 局限性:語言混合、可讀性差,需進一步優化。
-
DeepSeek-R1
- 多階段訓練:
- 冷啟動階段:使用數千條長CoT數據微調,提升可讀性和初始推理能力。
- 推理導向RL:引入語言一致性獎勵,解決語言混合問題。
- 拒絕采樣與SFT:收集60萬推理數據+20萬非推理數據(寫作、事實QA等),優化通用能力。
- 全場景RL:結合規則獎勵(推理任務)和神經獎勵(通用任務),對齊人類偏好。
- 性能突破:AIME 2024 Pass@1 79.8%(超越o1-1217的79.2%),MATH-500 97.3%(對標o1-1217的96.4%),Codeforces評級2029(超越96.3%人類選手)。
- 多階段訓練:
3、蒸餾技術與小模型優化
- 蒸餾策略:以DeepSeek-R1為教師模型,生成80萬訓練數據,微調Qwen和Llama系列模型,僅用SFT階段(無RL)。
- 關鍵成果:
- 14B蒸餾模型:AIME 2024 Pass@1 69.7%,遠超QwQ-32B-Preview的50.0%。
- 32B/70B模型:MATH-500 94.3%、LiveCodeBench 57.2%,刷新密集模型推理性能紀錄。
4、訓練過程簡介
zero:cot+grpo
R1:冷啟動+cot+grpo


5、COT思維鏈(Chain of Thought)
COT詳細原理參考:CoT論文筆記
2022 年 Google 論文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通過讓大模型逐步參與將一個復雜問題分解為一步一步的子問題并依次進行求解的過程可以顯著提升大模型的性能。而這些推理的中間步驟就被稱為思維鏈(Chain of Thought)。
思維鏈提示(CoT Prompting),在少樣本提示中加入自然語言推理步驟(如“先計算…再相加…”),將問題分解為中間步驟,引導模型生成連貫推理路徑。
-
示例:標準提示僅給“問題-答案”,思維鏈提示增加“問題-推理步驟-答案”(如)。
-
區別于傳統的 Prompt 從輸入直接到輸出的映射 <input——>output> 的方式,CoT 完成了從輸入到思維鏈再到輸出的映射,即 <input——>reasoning chain——>output>。如果將使用 CoT 的 Prompt 進行分解,可以更加詳細的觀察到 CoT 的工作流程。
-
示例對比(傳統 vs. CoT)
-
傳統提示
問題:1個書架有3層,每層放5本書,共有多少本書? 答案:15本 -
CoT 提示
問題:1個書架有3層,每層放5本書,共有多少本書? 推理: 1. 每層5本書,3層的總書數 = 5 × 3 2. 5 × 3 = 15 答案:15本
-
關鍵類型
-
零樣本思維鏈(Zero-Shot CoT)
無需示例,僅通過提示詞(如“請分步驟思考”)觸發模型生成思維鏈。適用于快速引導模型進行推理。 -
少樣本思維鏈(Few-Shot CoT)
提供少量帶思維鏈的示例,讓模型模仿示例結構進行推理。例如,先給出幾個問題及其分解步驟,再讓模型處理新問題。

如圖所示,一個完整的包含 CoT 的 Prompt 往往由指令(Instruction),邏輯依據(Rationale),示例(Exemplars)三部分組成。一般而言指令用于描述問題并且告知大模型的輸出格式,邏輯依據即指 CoT 的中間推理過程,可以包含問題的解決方案、中間推理步驟以及與問題相關的任何外部知識,而示例則指以少樣本的方式為大模型提供輸入輸出對的基本格式,每一個示例都包含:問題,推理過程與答案。
以是否包含示例為區分,可以將 CoT 分為 Zero-Shot-CoT 與 Few-Shot-CoT,在上圖中,Zero-Shot-CoT 不添加示例而僅僅在指令中添加一行經典的“Let’s think step by step”,就可以“喚醒”大模型的推理能力。而 Few-Shot-Cot 則在示例中詳細描述了“解題步驟”,讓大模型照貓畫虎得到推理能力。
提示詞工程框架( 鏈式提示Chain):其他提示詞工程框架,思維鏈CoT主要是線性的,多個推理步驟連成一個鏈條。在思維鏈基礎上,又衍生出ToT、GoT、PoT等多種推理模式。這些和CoT一樣都屬于提示詞工程的范疇。CoT、ToT、GoT、PoT等提示詞工程框架大幅提升了大模型的推理能力,讓我們能夠使用大模型解決更多復雜問題,提升了大模型的可解釋性和可控性,為大模型應用的拓展奠定了基礎。
參考:
https://blog.csdn.net/kaka0722ww/article/details/147950677
https://www.zhihu.com/tardis/zm/art/670907685?source_id=1005
6、強化學習算法(GRPO)
詳細GRPO原理參考:DeepSeekMath論文筆記
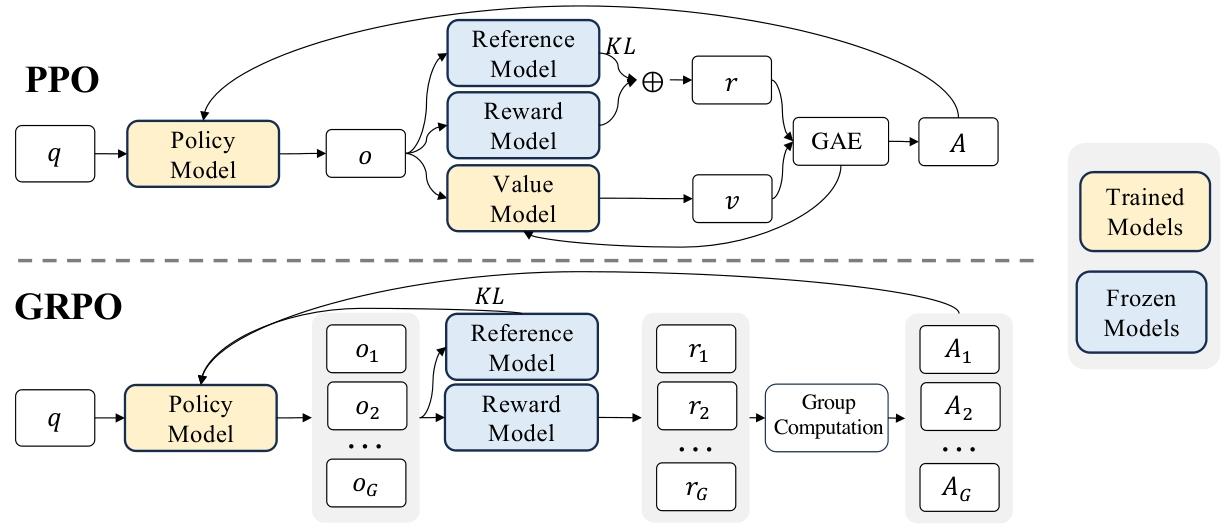
2.2.1 強化學習算法
群組相對策略優化 為降低強化學習的訓練成本,我們采用群組相對策略優化(GRPO)算法(Shao等人,2024)。該算法無需與策略模型規模相當的評論家模型,而是通過群組分數估計基線。具體來說,對于每個問題𝑞,GRPO從舊策略𝜋𝜃𝑜𝑙𝑑中采樣一組輸出{𝑜1, 𝑜2, · · · , 𝑜𝐺},然后通過最大化以下目標函數優化策略模型𝜋𝜃:
J GRPO ( θ ) = E [ q ~ P ( Q ) , { o i } i = 1 G ~ π θ old ( O ∣ q ) ] 1 G ∑ i = 1 G ( min ? ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 ? ε , 1 + ε ) A i ) ? β D KL ( π θ ∣ ∣ π ref ) ) , ( 1 ) J_{\text{GRPO}}(\theta) = \mathbb{E}\left[ q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta^{\text{old}}}(O|q) \right] \frac{1}{G} \sum_{i=1}^G \left( \min\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta^{\text{old}}}(o_i|q)} A_i, \text{clip}\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta^{\text{old}}}(o_i|q)}, 1 - \varepsilon, 1 + \varepsilon \right) A_i \right) - \beta D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) \right), \quad (1) JGRPO?(θ)=E[q~P(Q),{oi?}i=1G?~πθold?(O∣q)]G1?i=1∑G?(min(πθold?(oi?∣q)πθ?(oi?∣q)?Ai?,clip(πθold?(oi?∣q)πθ?(oi?∣q)?,1?ε,1+ε)Ai?)?βDKL?(πθ?∣∣πref?)),(1)
D KL ( π θ ∣ ∣ π ref ) = π ref ( o i ∣ q ) ( π θ ( o i ∣ q ) π ref ( o i ∣ q ) ? log ? π θ ( o i ∣ q ) π ref ( o i ∣ q ) ? 1 ) , ( 2 ) D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) = \pi_{\text{ref}}(o_i|q) \left( \frac{\pi_\theta(o_i|q)}{\pi_{\text{ref}}(o_i|q)} - \log \frac{\pi_\theta(o_i|q)}{\pi_{\text{ref}}(o_i|q)} - 1 \right), \quad (2) DKL?(πθ?∣∣πref?)=πref?(oi?∣q)(πref?(oi?∣q)πθ?(oi?∣q)??logπref?(oi?∣q)πθ?(oi?∣q)??1),(2)
其中,𝜀和𝛽為超參數,𝐴𝑖為優勢函數,通過每組輸出對應的獎勵集合{𝑟1, 𝑟2, . . . , 𝑟𝐺}計算得到:
A i = r i ? mean ( { r 1 , r 2 , ? ? ? , r G } ) std ( { r 1 , r 2 , ? ? ? , r G } ) . ( 3 ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, · · · , r_G\})}{\text{std}(\{r_1, r_2, · · · , r_G\})}. \quad (3) Ai?=std({r1?,r2?,???,rG?})ri??mean({r1?,r2?,???,rG?})?.(3)


7、冷啟動


冷啟動(Cold Start)
在DeepSeek-R1的訓練流程中,冷啟動是一個關鍵階段,旨在通過少量高質量數據為模型提供初步的推理能力,為后續強化學習(RL)奠定基礎。以下是其核心內容:
AI 冷啟動是指人工智能系統在初始階段因缺乏足夠數據或歷史信息導致的性能瓶頸問題,常見于推薦系統、大模型訓練、提示詞優化等場景。以下是基于多領域研究的綜合解析:
AI模型訓練的冷啟動問題
-
數據匱乏的挑戰
? 問題:模型初期因數據不足導致推理能力弱,生成結果混亂或重復。
? 解決方案:
? 冷啟動數據(Cold-start Data):
? 高質量微調:用少量人工篩選的推理數據(如數學題詳細步驟)對模型進行初步訓練,提供“入門指南”。
? 數據來源:從大型模型生成(如ChatGPT)、現有模型輸出篩選、人工優化等方式獲取。 -
多階段訓練策略
? 階段1:冷啟動微調:用冷啟動數據優化模型基礎推理能力,提升生成結果的可讀性和邏輯性。
? 階段2:強化學習(RL):通過獎勵機制(如答案準確度、格式規范性)動態調整模型參數,優化推理策略。
? 階段3:多場景優化:結合拒絕采樣(篩選高質量輸出)和監督微調(SFT),擴展模型在專業領域(如金融、醫學)的適用性。
三、提示詞與上下文冷啟動
-
提示詞冷啟動策略
? 知識初始化:利用領域知識庫初始化模型參數,指導模型生成更符合任務需求的回答。
? 動態調整:根據模型表現實時調整學習率和任務權重,例如在復雜任務中增加上下文信息權重。 -
上下文信息利用
? 時間/場景適配:結合用戶當前環境(如工作日早晨推薦新聞,周末推薦娛樂內容)提升推薦相關性。
? 多模態數據融合:整合文本、圖像、社交網絡等多源數據,豐富冷啟動階段的特征提取。
1. 冷啟動的目的
? 解決DeepSeek-R1-Zero的局限性:
直接從基礎模型啟動RL(如DeepSeek-R1-Zero)會導致生成內容可讀性差、語言混雜(如中英文混合)。
? 引導模型生成結構化推理鏈:
通過冷啟動數據,教會模型以“思考過程→答案”的格式輸出,提升可讀性和邏輯性。
2. 冷啟動的實現步驟
(1) 數據收集
? 來源:
? 模型生成:用基礎模型(DeepSeek-V3-Base)通過few-shot提示生成長鏈推理(CoT)數據。
? 人工修正:對模型生成的答案進行篩選和潤色,確保可讀性。
? 外部數據:少量開源數學、編程問題的高質量解答。
? 格式要求:
強制要求模型將推理過程放在<reasoning>標簽內,答案放在<answer>標簽內,例如:
<reasoning>設方程√(a?√(a+x))=x,首先平方兩邊...</reasoning>
<answer>\boxed{2a-1}</answer>
(2) 監督微調(SFT)
? 數據規模:數千條(遠少于傳統SFT的百萬級數據)。
? 訓練目標:讓模型學會:
? 生成清晰的推理步驟。
? 遵守指定輸出格式。
? 避免語言混雜(如中英文混合)。
3. 冷啟動的作用
? 提升可讀性:
通過結構化標簽和人工修正,生成內容更符合人類閱讀習慣。
? 加速RL收斂:
冷啟動后的模型已具備基礎推理能力,RL階段更易優化策略。
? 緩解語言混合問題:
強制輸出格式和語言一致性獎勵(如中文或英文占比)減少混雜。
典型應用場景
-
推薦系統
- 新用戶注冊時,通過引導式問卷(主動學習)或熱門內容(規則策略)完成冷啟動,隨后逐步切換至個性化推薦。
- 案例:TikTok對新用戶先推送泛領域熱門視頻,再根據前幾個視頻的互動數據快速建模興趣標簽。
-
自然語言處理(NLP)
- 新領域對話系統冷啟動:用預訓練語言模型(如LLaMA)結合少量領域數據微調,快速適應垂直場景(如法律咨詢、金融客服)。
-
計算機視覺(CV)
- 新類別圖像識別:通過遷移學習加載ImageNet預訓練模型,再用少量新類別樣本微調,解決“新物體冷啟動”問題。
-
醫療AI
- 罕見病診斷冷啟動:利用元學習快速適配新病例,或通過合成醫學影像數據增強模型泛化能力。
匯總
一、核心模型與技術路線
-
DeepSeek-R1-Zero
- 純強化學習訓練:基于DeepSeek-V3-Base,使用GRPO算法,無監督微調(SFT),通過規則獎勵(準確性+格式)引導推理過程。
- 能力涌現:自然發展出自我驗證、反思、長鏈推理(CoT)等行為,AIME 2024 Pass@1從15.6%提升至71.0%,多數投票達86.7%,接近OpenAI-o1-0912。
- 局限性:語言混合、可讀性差,需進一步優化。
-
DeepSeek-R1
- 多階段訓練:
- 冷啟動階段:使用數千條長CoT數據微調,提升可讀性和初始推理能力。
- 推理導向RL:引入語言一致性獎勵,解決語言混合問題。
- 拒絕采樣與SFT:收集60萬推理數據+20萬非推理數據(寫作、事實QA等),優化通用能力。
- 全場景RL:結合規則獎勵(推理任務)和神經獎勵(通用任務),對齊人類偏好。
- 性能突破:AIME 2024 Pass@1 79.8%(超越o1-1217的79.2%),MATH-500 97.3%(對標o1-1217的96.4%),Codeforces評級2029(超越96.3%人類選手)。
- 多階段訓練:
二、蒸餾技術與小模型優化
- 蒸餾策略:以DeepSeek-R1為教師模型,生成80萬訓練數據,微調Qwen和Llama系列模型,僅用SFT階段(無RL)。
- 關鍵成果:
- 14B蒸餾模型:AIME 2024 Pass@1 69.7%,遠超QwQ-32B-Preview的50.0%。
- 32B/70B模型:MATH-500 94.3%、LiveCodeBench 57.2%,刷新密集模型推理性能紀錄。
三、實驗與性能對比
| 任務/模型 | DeepSeek-R1 | OpenAI-o1-1217 | DeepSeek-R1-Zero | DeepSeek-V3 |
|---|---|---|---|---|
| AIME 2024 (Pass@1) | 79.8% | 79.2% | 71.0% | 39.2% |
| MATH-500 (Pass@1) | 97.3% | 96.4% | 86.7% | 90.2% |
| Codeforces (評級) | 2029 | - | 1444 | 1134 |
| MMLU (Pass@1) | 90.8% | 91.8% | - | 88.5% |
四、研究貢獻與開源
- 方法論創新:
- 首次證明純RL可激發LLM推理能力,無需監督微調(SFT)。
- 提出“冷啟動數據+多階段RL”框架,平衡推理能力與用戶友好性。
- 開源資源:
- 開放DeepSeek-R1/Zero及6個蒸餾模型(1.5B、7B、8B、14B、32B、70B),基于Qwen和Llama。
五、局限與未來方向
- 當前局限:
- 語言混合問題(中英文混雜),多語言支持不足。
- 工程任務(如代碼生成)數據有限,性能待提升。
- 對提示格式敏感,少樣本提示可能降低性能。
- 未來方向:
- 探索長CoT在函數調用、多輪對話中的應用。
- 優化多語言一致性,解決非中英查詢的推理語言偏好問題。
- 引入異步評估,提升軟件任務的RL訓練效率。
關鍵問題
1. DeepSeek-R1與DeepSeek-R1-Zero的核心區別是什么?
答案:DeepSeek-R1-Zero采用純強化學習訓練,無需監督微調(SFT),依賴規則獎勵自然涌現推理能力,但存在語言混合和可讀性問題;DeepSeek-R1在此基礎上引入冷啟動數據(數千條長CoT示例)進行初始微調,并通過多階段訓練(SFT+RL交替)優化可讀性、語言一致性和通用能力,最終性能更接近OpenAI-o1-1217。
2. 蒸餾技術在DeepSeek-R1研究中的核心價值是什么?
答案:蒸餾技術將大模型的推理模式遷移至小模型,使小模型在保持高效的同時獲得強大推理能力。例如,DeepSeek-R1-Distill-Qwen-14B在AIME 2024上的Pass@1為69.7%,遠超同規模的QwQ-32B-Preview(50.0%);32B蒸餾模型在MATH-500上達94.3%,接近o1-mini的90.0%。該技術證明大模型推理模式對小模型優化至關重要,且蒸餾比直接對小模型進行RL更高效經濟。
3. DeepSeek-R1在數學推理任務上的性能如何超越同類模型?
答案:DeepSeek-R1在AIME 2024上的Pass@1為79.8%,略超OpenAI-o1-1217的79.2%;MATH-500達97.3%,與o1-1217持平(96.4%)。其優勢源于強化學習對長鏈推理的優化(如自動擴展思考步驟、自我驗證),以及冷啟動數據和多階段訓練對推理過程可讀性和準確性的提升。此外,規則獎勵模型確保了數學問題答案的格式正確性(如公式框輸出),減少了因格式錯誤導致的失分。








)


)







