一、HTTP的方法
| 方法 | 說明 | 支持的HTTP協議版本 |
| GET | 獲取資源 | 1.0、1.1 |
| POST | 傳輸實體主體 | 1.0、1.1 |
| PUT | 傳輸文件 | 1.0、1.1 |
| HEAD | 獲得報文首部 | 1.0、1.1 |
| DELETE | 刪除文件 | 1.0、1.1 |
| OPTIONS | 詢問支持的方法 | 1.1 |
| TRACE | 追蹤路徑 | 1.1 |
| CONNECT | 要求用隧道協議連接代理 | 1.1 |
| LINK | 建立和資源之間的聯系 | 1.0 |
| UNLINE | 斷開連接關系 | 1.0 |
GET:從服務器上獲取某個資源
POST:向服務器上傳xxx個資源
PUT:向服務器上傳xxx資源(文件)
DELETE:刪除服務器的xxx資源
其余的方法,使用的非常少,因此我們忽略不計
(1)GET
(一)
HTTP中最常見到的方法,有著很多操作,都會觸發HTTP GET請求
1.直接在瀏覽器地址欄中輸入URL,點收藏夾也是一樣的
2.在頁面上點擊一些連接跳轉的時候
3.HTML間接加載其他資源的時候(CSS,JS,圖片......)
HTML中通過link標簽,加載css
通過script標簽,加載js
通過img標簽,加載圖片
![]()
![]()
3.也可以通過js /java/c++/Python代碼手動構造GET請求
(二)GET請求的特點
GET請求一般沒有body,如果你通過代碼構造一個get請求,故意添加上body,理論上也是可行的
GET請求要想給服務器傳遞數據,往往就是通過? 路徑/querys stirng 來進行傳遞
![]()
(2)POST請求
(一)
1.登錄的時候

body提交的就是用戶名和密碼。
用戶名密碼,得是加密后再傳輸的,不能直接明文傳輸
對于GET請求這種沒有body的情況,一般不會用來實現登錄功能。如果非要去實現也行,可以把用戶名密碼加密之后,通過query string進行傳輸
2.上傳資源/文件
![]()
body部分就是我們傳輸的圖片和內容,圖片屬于“二進制文件”。通過HTTP body傳輸的時候,有時候就會把二進制的內容,通過base64進行編碼,變成文本的內容
body中完全可以放二進制數據的(壓縮的結果)
之所以用Base64轉成文本,主要還是因為當前圖片本身比較小,按照文本的方式,服務器代碼處理起來好實現。
base64:把而僅僅只數據,用文本(ascii字符)進行重新編碼,通過4個ascii字符,標識原來的3個字節的二進制數據。
body可以存二進制,但是url的query string不能
如果由二進制的數據想通過query string來進行保存,那么就可以通過base64進行編碼
(二)POST請求的特點
帶有body,通過body給服務器傳遞數據
不太需要query stirng傳遞了,通常情況下沒有query string(不絕對)
post的body格式看起來好像是和 query string 差不多(但是這里還有其他情況)
HTTP的這些方法,在使用的時候不一定嚴格按按照官方提供的語義來進行
經典面試題——談談GET和POST的區別
核心結論:GET 和 POST其實沒有本質區別,只是HTTP的兩個不同的方法。大部分情況下,使用GET的場景,也可以替換成POST,使用POST的場景也可以替換成GET
但是從使用習慣來講,還是存在差異的
(1)GET通常沒有body,通過query stirng傳遞數據給服務器
POST通常由body,不需要通過query string 傳遞數據
*并不絕對,你自己寫一個代碼,構造GET請求,加上body;構造POST請求,加上query stirng 都是可行的
(2)語義上的區別:GET標識“獲取”,POST表示“提交”
*不絕對,目前HTTP的方法在時間中經常會混用
GET和 POST 的區別最主要就是上面這兩個
網上還有一些其他的說法
*GET請求不安全,POST請求比GET更安全
比如登錄場景中,GET的話,就會把用戶名和密碼顯示到URL上,如果別人看一眼你的屏幕,就會知道你的密碼?
安全,得是通過“加密”來完成的
如果這個說法是正確的,那么即使沒有人看你的屏幕,黑客一抓包,也就看到了
*冪等性 GET請求 官方建議實現成“冪等的”(也就是當你的請求一定的時候,得到的響應結果也就一定),而POST請求無要求(HTTP標準文檔上)?
標準文檔只是“建議”,實際開發的時候,不一定會遵守,尤其是在現在,很多的網站都開始講究“個性化”
*可緩存,承接冪等
GET如果實現成冪等,就可以把結果緩存起來
POST不是先成冪等,就不能緩存?
*傳輸的數據量
之前有一個說法,GET請求傳輸的數據量少,POST傳輸的數據兩最大,GET請求的URL存在長度限(1MB,10MB,1KB,2KB...)?
HTTP標準文檔中沒有對URL的長度給出限制,上面的限制主要來自于 瀏覽器/HTTP服務器的實現。
*數據的類型
GET傳輸數據的時候,通過query string只能傳輸文本,POST通過body傳輸,也可以傳輸二進制?
query string雖然不能夠直接傳輸二進制,但是可以通過Urlencode傳輸二進制
(3)PUT(和POST是差不多一樣的)
(4)DELETE(和GET類似,一般不帶有body,通過query stirng傳輸數據)
二、Restful 風格的API設計(HTTP的API)
API:應用程序編程接口 Application Programming interface
方法/類(庫/框架提供的API)
有些服務器,也可以認為是API的提供者,是網絡上的接口
你給這個服務器發一個xxx的請求,服務器給你返回一個xxx的響應,可能提供TCP級別的API(例如RPC框架,形如grpc,thrift,dubbo)
也可能是提供HTTP級別的API(后面在javaee進階)
咱們需要寫一些服務器,提供Http api給別人(瀏覽器/前端)進行調用,此時就需要有一定的規范約束設計風格
1.通過請求中的方法表示不同的語義
GET:查詢
POST:新增
PUT:修改
DELETE:刪除
2.通過URL的路徑,表示操作的資源

3.請求和響應攜帶的數據,都盡量使用json格式的數據
json格式的數據:
{
key:value
key2:value2
}
4.通過HTTP響應的狀態碼,表示失敗的原因
按照上述的約定,設計出來的API風格是統一的
三、HTTP的版本號

![]()
當前最主流的HTTP版本,響應的版本號,也是在首行,但是在前面
四、HTTP報頭(header)
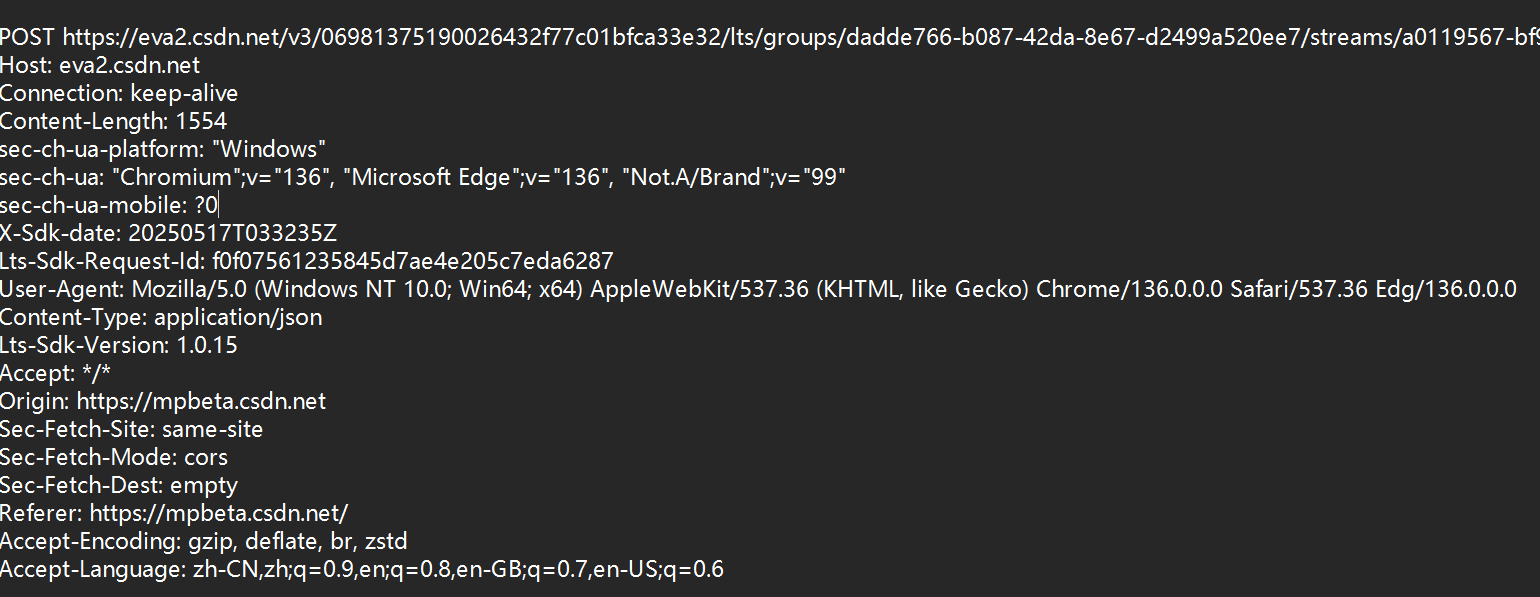
行文本,每一行都是一個鍵值對。鍵和值之間使用:空格來進行分割。
header 中的鍵值對都是標準規定的,(也允許用戶自定義),這些header中就存在特定的含義
header的key太多了,不必一一介紹
![]()
請求中的header,描述了訪問的服務器的IP(域名)和端口(可以省略)
URL中已經存在了訪問的服務器的地址和端口,比如針對HTTPS來說,HTTPS是會把header部分都加密的。URL里的服務器的地址端口,就可以和Host加密后的服務器地址和端口做一個校驗。
Content-Length: 1554
描述了body的長度
Content-Type: application/json
描述了body的數據格式
上述這兩個東西,只有請求/響應中存在body才存在這兩個屬性
這兩個東西共同解決了粘包問題(粘包問題在以前的帖子里有具體闡述,是一個面向字節流傳輸涉及到的問題,是一個TCP問題,而HTTP就是基于TCP的。如果一個TCP連接中傳輸多個HTTP請求/響應,此時就需要讓應用程序能夠區分從哪里到哪里是一個完整的應用層數據包)


byte[] body = new byte[n];
inputStream.ready(body);
HTTP協議,就是按照上述學習的格式,往TCP socket當中讀寫數據
服務器如何區分出,從哪里到哪里是一個完整的HTTP請求呢?
1)如果沒有body,直接讀到空行結束? 就可以認為請求結束了
2)如果有Body,header中必然存在Content-Length,取出Content-Length的值(字節)。找到空行,空行后面就是body的開始,從開始位置,讀Content-Length這么多字節就可以了
常見的Content-Type:
1) text/html
2) text/css
3) application/javascript
4) application/json
5) image/png
6) image/jpg 瀏覽器/服務器
根據這個 Content - Type 的值 決定 body 如何使用
如果一個請求/響應,雖然有 body 但是沒有 Content - Type 或者 Content - Length 。那就是一個非法的“請求/響應” ,比如響應中如果沒有 Content - Type ,瀏覽器會根據 body 中的數據,“猜”一個格式(有較大的概率能猜對) 。如果沒有 Content - Length 瀏覽器也能猜(按照下一個請求一定是 GET/POST 開頭)。
這就是魯棒性:一個系統的 容錯能力
英文音譯robustness
魯棒性:健壯性;強健性;耐用性;
即使你對瀏覽器很粗魯的返回錯誤格式的數據,他仍然表現的很棒。
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0

30年前1995年左右的時候,這樣的特性非常重要。
計算機/互聯網 飛速發展的階段,?最早的瀏覽器訪問的網站是純文本的。?后來,有了多媒體(圖片,音頻,視頻) 再后來,有了交互能力(JS) 。再再后來,有了更復雜的交互體系(flash,現在更強的是js體系) 用戶手上的瀏覽器,有的是老版本,只能支持文本 有的是新版本,能夠支持上述所有功能。這些全都要,因此要提供多個版本的網站,有的版本只包含文字,有的包含文字和多媒體,有的則全都包含。但是,如今的網站形態基本就定型了,(下一個革命性的變化,可能是VR技術成熟)。在的瀏覽器上面的功能基本都有。
因此User - Agent現在只有一個作用,那就是可以區分PC端還是移動端 。PC屏幕比較大比較寬,手機屏幕比較窄比較小。有些系統,也開始往多設備上進行演化了。?針對上述區分規則,也不是完全解決問題。?C語言中, 一個指針變量,存地址 地址多長。?你的手機瀏覽器一般都有功能,修改UA, 在手機上通過修改UA就能夠訪問電腦版 ,根據用戶請求的User - Agent,判定用戶使用的瀏覽器/系統版本 是哪個(也就知道瀏覽器能支持哪些特性) 前端開發的流行的方式。不用給PC手機維護兩個版本的網頁。?就一套代碼, 這一套代碼可以根據瀏覽器窗口的寬度,自動適應.


)








OpenGL渲染簡單圖形)







