在云應用/服務的 5 層架構里,數據庫服務層穩坐第 4 把交椅,堪稱其中的 “硬核擔當”。它的復雜程度常常讓人望而生畏,不少人都將它視為整個架構中的 “終極挑戰”。
不過,也有人覺得可擴展存儲系統才是最難啃的 “硬骨頭”,其實這場關于誰更復雜的爭論沒有標準答案,很大程度上取決于具體的業務應用模式(就可擴展存儲系統,老夫打算在后續的文章中具體再聊)。
對于那些涉及復雜交易處理的應用來說,數據庫服務層實現面臨的挑戰難度顯然更高,每一次數據的讀寫、每一個事務的處理,都像是在走鋼絲,稍有不慎就可能引發數據混亂、系統崩潰等嚴重問題,實現過程中的挑戰難度堪稱地獄級別。
但如果是單純處理海量數據的簡單事件應用,數據庫服務層反而顯得有些 “多余”,這時候,云存儲層搖身一變,就成為了整個系統的 “難點 C 位”,承擔起了更為復雜的任務。
數據庫擴展大體有縱向擴展、主仆讀代理模式、主–主模式、分區模式和分布式共識模式5類解決方案。這些方案共同構成了可擴展數據庫的 “魔法寶典”,助力企業在數據的海洋中乘風破浪。
(1)縱向擴展
在數據庫擴展的工具箱里,縱向擴展就像是給系統注入一劑強化針。它最直觀的方式,是對硬件配置大刀闊斧地升級 —— 換上更強勁的 CPU、擴充海量內存、搭載讀寫速度更快的存儲設備,如同給數據庫系統裝上超級引擎,讓數據處理的吞吐量直線飆升。
同時,縱向擴展也在軟件層面持續發力。以表結構優化為例,它會巧妙運用索引,讓系統能快速定位數據;極力避免多表間復雜的關聯查詢,減少系統的運算負擔。這種軟硬件協同優化的方式,曾是第二平臺應用擴展的黃金法則,在當時的技術環境下屢試不爽。
然而在第三平臺云應用時代,縱向擴展就顯得有些力不從心了。云應用龐大的用戶規模與爆發式增長的數據需求,僅靠縱向擴展的單打獨斗,根本無法滿足日益嚴苛的可擴展性要求,逐漸在新的技術舞臺上退居幕后 。
(2)主仆讀代理模式
數據庫服務層的橫向擴展方法有多種,其中最基礎(簡潔)的是主-仆模式,如圖1所示。
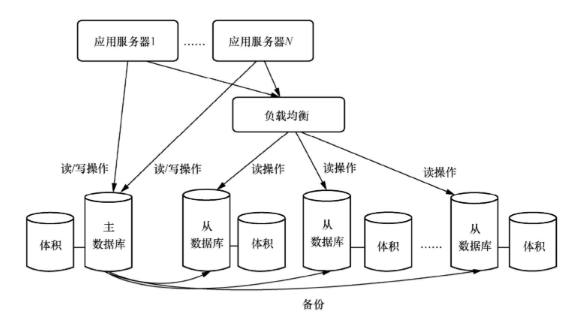
主-仆模式通常由一個Master(主)節點“挑大梁”,包攬所有數據的讀寫操作,同時配備一個或多個 Slave(仆)節點組成 “輔助小隊”,專門負責數據的只讀任務。
這樣的設計和分工相當巧妙,相當于給數據讀取能力裝上了“加速器”,數倍提升讀取效率,而主節點卸下部分讀負載后,寫操作的處理也更加游刃有余。我們知道大多數數據庫系統讀操作的數量遠遠超過寫操作(如更改、刪除、添加)的數量,因此讀操作的加快能有效解決這類系統的效能瓶頸,讓系統運行更加絲滑流暢。
主 - 仆模式能高效運轉的關鍵在于 “單點寫入” 的設計智慧。樣的設計只讓主節點執行寫操作,就像給數據管理立下了一個唯一指揮權的規矩,這就從根源上規避了多點同時寫入引發的數據同步混亂。
不過,主節點在完成寫操作后,還得肩負起數據搬運工的重任,及時將更新的數據同步到各個只讀節點。這就好比一場數據接力賽,要求主仆節點之間必須搭建起高帶寬、低時延,否則一旦數據復制延遲,就會出現數據讀取與寫入 “對不上號” 的尷尬局面。
通常來說,為了讓這個架構發揮最大威力,工程師們往往會在主 - 仆數據庫架構中安插負載均衡組件。它就相當于一名智能調度員,可以精準分配數據讀取任務,確保每個 Slave 節點都能物盡其用。
值得注意的是,這一層的負載均衡操作主要集中在 TCP/UDP 層,并且常常基于定制的數據庫通信協議展開,和應用服務層常見的標準 HTTP (S) 負載均衡大不相同,堪稱數據庫橫向擴展里的專屬秘籍。
(3)主-主模式
前面咱們通過主-仆模式解決了系統讀操作可擴展難題,那么,可寫操作的 “擴容困境” 該怎么破呢?答案是確切的——有,只不過要攻克的復雜度會高很多。
回顧之前的章節中我們討論過的CAP理論,在強一致性的數據庫系統(ACID 系統)里,數據一致性就是一條金線,不可動搖。
因此,這類系統最大的挑戰是如何保證各節點間所采用的架構能實現數據一致性。
但讓多個節點同時支持并發讀寫,就像在數據王國里打開了 “潘多拉魔盒”,稍有不慎就會引發節點間的數據不一致危機。這類系統的終極挑戰,就像在刀尖上跳平衡舞 —— 既要讓寫操作能橫向擴展,又得像精密齒輪般確保所有節點的數據嚴絲合縫、毫無偏差。
強一致性的數據庫系統(ACID系統)強調CAP中的數據一致性,而多節點同時支持并發讀寫操作極易造成節點間出現數據非一致性,因此,這類系統最大的挑戰是如何保證各節點間所采用的架構能實現數據一致性——這類系統的終極挑戰,就像在刀尖上跳平衡舞 —— 既要讓寫操作能橫向擴展,又得像精密齒輪般確保所有節點的數據嚴絲合縫、毫無偏差。
要知道,多節點并發寫跟奏交響樂沒啥差別,每個節點的寫入動作都可能影響全局。如何設計出既能承載高并發寫操作,又能通過巧妙的架構(比如分布式共識算法、復雜的數據復制協議等)把一致性牢牢 “釘住”,簡直是對工程師創造力和耐心的雙重極限考驗。這時候的系統設計,不再是主 - 仆模式那樣的 “線性思維”,而是要構建一套如同精密鐘表般的復雜協作機制,讓每個寫操作都能在多節點間找到自己的時間刻度,最終拼成完整一致的數據表盤。
以下圖2為例,MySQL數據庫的多Master節點模式采取了環狀復制數據同步機制,就像搭建了一個緊密的接力環。在3個數據庫服務器集群中,數據同步形成了一條閉合的環形鏈路:
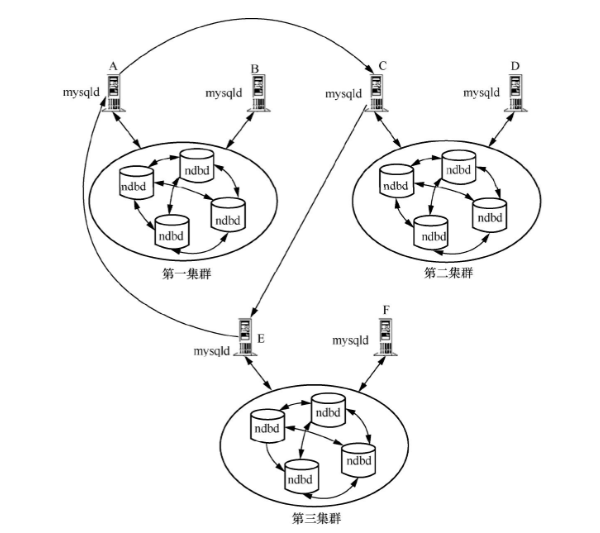
- 第一集群的 Master 節點先將更新數據同步給第二集群的對應 Slave 節點,此時第二集群的節點 “接棒” 后切換身份,以 Master 節點的角色將數據傳遞給第三集群的 Slave 節點;
- 第三集群的節點 “接力” 后同樣轉換為 Master,再將數據回傳給第一集群的同一節點,最終形成 “第一集群→第二集群→第三集群→第一集群” 的環形同步閉環。
這種設計的核心邏輯是用環型時序規避沖突。當多個節點需要同時更新數據時,環形鏈路為每個數據集分配了唯一的 “傳遞時區”—— 每個節點在環中只能按固定順序接收和發送數據,就像列車沿著固定軌道行駛,避免了多節點并發寫入同一目標時因 “路徑交叉” 導致的數據交集沖突。例如,若兩個節點同時向同一目標節點發送更新,環形機制會強制數據按順序通過鏈路流轉,確保后到達的數據能基于前序更新進行合并,而非直接覆蓋,從而從架構層面降低了數據不一致的風險。
不過,這種 “環形接力” 也需要付出代價:
- 鏈路依賴強:任意一環的延遲或故障都會像 “多米諾骨牌” 一樣影響整個集群的同步效率;
- 一致性延遲:數據需繞環一周才能完成全集群同步,在高并發場景下可能出現短期的節點間數據差異;
- 復雜度躍升:相比主仆模式的單向同步,環形架構的拓撲管理、故障恢復機制需要更精細的設計,堪稱 “用架構復雜度換一致性保障” 的典型案例。
避免在多Master節點數據庫系統中發生數據一致性沖突的解決方法有以下4種:
①徹底避免多節點寫操作(這樣又回到了主-仆模式)?。
②在應用服務層邏輯上嚴格區分不同Master節點的寫入區域,確保它們之間無交集(如不出現同時間內更改同一行數據的操作)?。
③保證不同Master節點在不重疊的時間段內對同一區域進行操作。
④同步復制,所有節點會同時進行寫操作,且當所有節點完成后,整個操作才會返回。這種模式顯然對網絡帶寬的要求極高,并且為了滿足數據的一致性而犧牲了可用性。
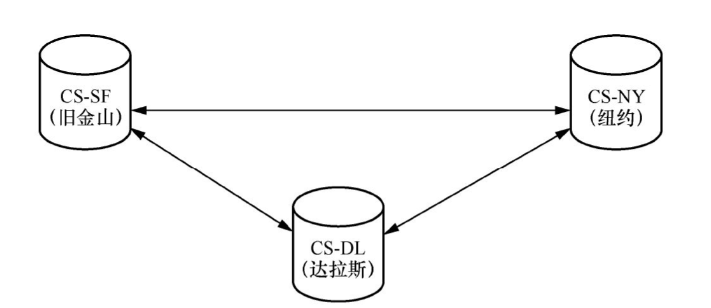
以下圖所示的分布式數據庫為例,我們可以按表1設計數據庫CS中的表,以確保位于舊金山、紐約和達拉斯的Master節點可以同時完成寫操作,并且不會出現沖突。

?
今天先到此結束,下篇內容我們再敘分區模式和分布式共識兩種模式。88~
?(文/Ricky - HPC高性能計算與存儲專家、大數據專家、數據庫專家及學者)
?



 和 P2P(點對點網絡) 的詳細對比)


篇一:閱讀與注釋QAction,其是窗體菜單欄與工具欄里的菜單項,先給出屬性測試,再給出成員函數測試,最后給出信號函數的學習于舉例測試)












