- undo log(回滾日志):引擎層生成的日志,實現了事務的原子性,用于事務回滾和MVCC。
- redo log(重做日志):引擎層生成的日志,實現了事務的持久性,用于非正常關閉的數據恢復。
- bin log(歸檔日志):Server層生成的日志,主要用于數據備份和主從復制。
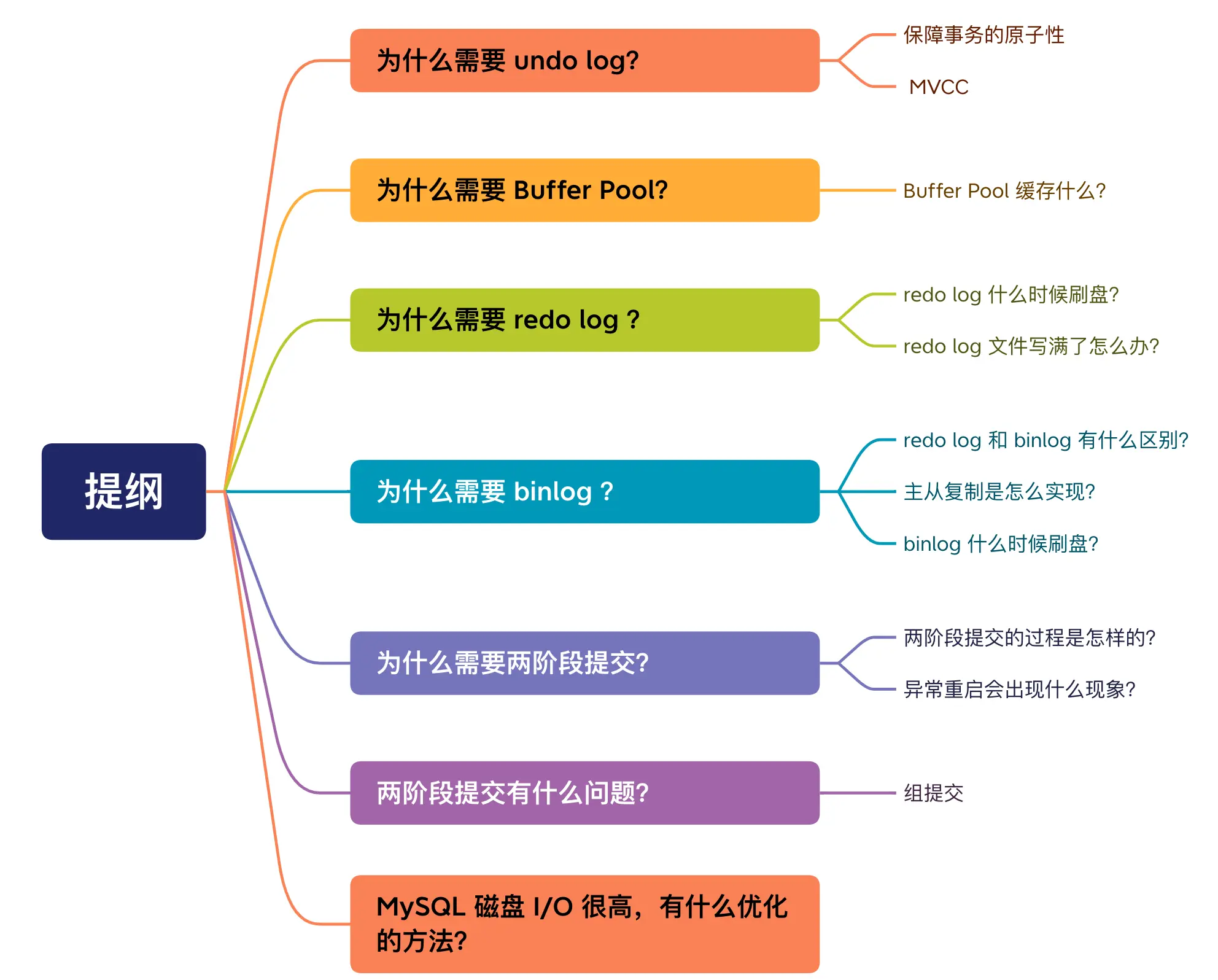
undo log詳解:
undo log是一種用于撤銷回退的日志,在事務沒提交之前,會先記錄更新前的數據到undo log日志文件中,事務回滾時,可以利用undo log來進行回滾。
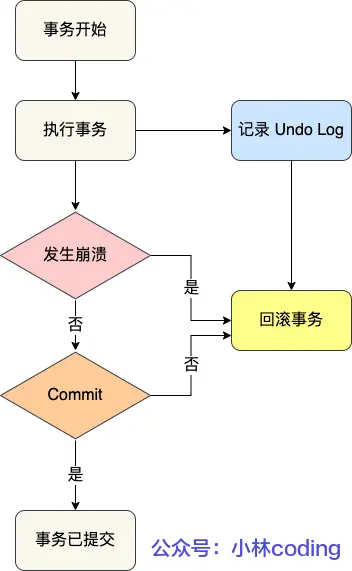
undo log中記錄著update、insert、delete等修改操作的反操作。例如刪除一條記錄時,undo會先將記錄中的內容先記錄下來,并使用insert操作。
每個undo log都有一個roll_pointer指針和一個trx_id事務id:
- 通過事務id我們可知本次修改是哪個事務執行的
- 通過roll_pointer我們可將undo log串成一個鏈表,從最新指向最舊,這個鏈表就是版本鏈
- 這兩個字段是每行數據的隱藏字段
- 每次事務開啟時,roll_pointer會指向開啟前的undo log?,且該undo log作為版本鏈新的頭節點
undo log利用版本鏈和Read View實現MVCC(多版本并發控制):
- 對于讀已提交和可重復讀隔離級別的事務來說,它們的快照讀(普通select 語句)是通過Read View+undo log來實現的,它們的區別在于創建Read View的時機不同。
- 讀已提交:每次select語句后都會生成一個新的Read View,也就是說可以看到其他事務提交的結果,可能會造成不可重復讀。
- 可重復讀:首次select語句后生成一個Read View,后續的查詢都使用該Read View,期間其他事務的已提交數據無法感知,避免了不可重復讀的問題。
- 串行化:無快照讀,不依賴Read View,通過加鎖實現
Read View詳解:
核心字段:
- trx_ids:記錄生成視圖時系統中所有活躍(未提交)的事務id的列表
- min_trx_id:活躍事務列表中的最小事務id,表示活躍事務的起始邊界
- max_trx_id+1:即將分配的事務id,也就是當前最大事務id+1,表示未來事務的邊界
- m_creator_trx_id:生成視圖的當前事務id
可見性判斷規則:
- 可見:事務id<min_trx_id(該版本在Read View生成前就已提交)
- 不可見:事務id>max_trx_id||事務id包含在活躍事務列表中(Read View生成時處于未提交狀態)
- 例外可見:事務id=m_creator_id(修改操作是生成視圖的事務執行的)
在實現這兩個隔離級別的事務時,查詢的行數據會通過事務id字段與Read View中的字段進行對比,通過roll pointer在版本鏈中遍歷,直到找到可見的數據記錄,從而并發控制事務訪問同一個數據記錄的行為,這就稱為MVCC。
redo log詳解:
Buffer Pool提高了讀寫效率,但它是基于內存的,遇到非正常關閉時會導致數據丟失。
所以數據庫更新記錄時,會先在Buffer Pool中更新并標記為臟頁,隨后將本次修改以redo log的形式記錄下來,這時候更新操作才算完成了。
臟頁數據刷盤時依然是根據Buffer Pool,日志用于崩潰恢復時重建臟頁數據。
后續,引擎會選擇合適的時機異步刷盤臟頁數據,這就是WAL(Write-Ahead Logging)技術。
WAL:MySQL的寫操作并不直接寫入到磁盤上,而是先記錄日志,再在合適的時機寫入磁盤中。
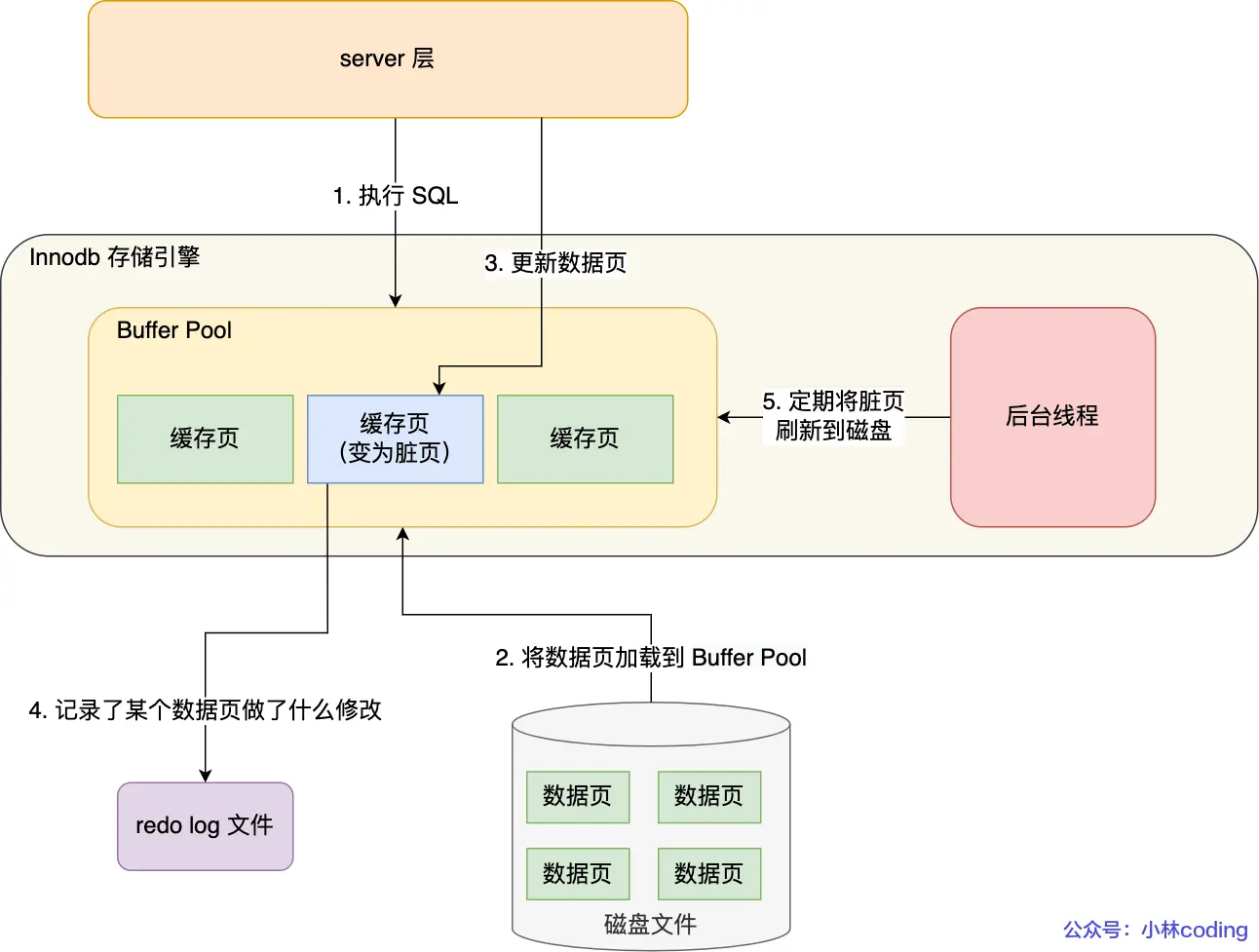
redo具體記錄什么?
- redo log是物理日志,記錄了某個數據頁做了什么修改,例如對XXX表空間中的YYY數據頁ZZZ偏移量的地方做了AAA更新,每當執行一個事務時就有一條或者多條這樣的物理日志。
- 事務提交時,只需將redo log持久化到磁盤中即可,無需等待緩存中的臟頁數據持久化。且redo log是順序寫入磁盤,Buffer Pool是隨機寫入,需要時間尋找可用空間。因此日志的持久化是遠遠快于完整數據持久化的。
- 系統崩潰時,MySQL就可以根據redo log重構臟頁數據,恢復到最新狀態。
產生的redo log是否直接寫入磁盤中?
- 實際上,redo log也并非直接寫入磁盤中,因為這樣會產生大量IO操作,而且磁盤的運行速度遠低于內存。
- redo log也有自己的緩存——redo log buffer,每當有redo log產生,會先寫入到緩存中,后續再進行持久化。緩存默認大小16mb,可以通過innodb_log_Buffer_size參數動態調整大小,增大它的大小可以讓MySQL處理大事務時不必直接寫入磁盤。
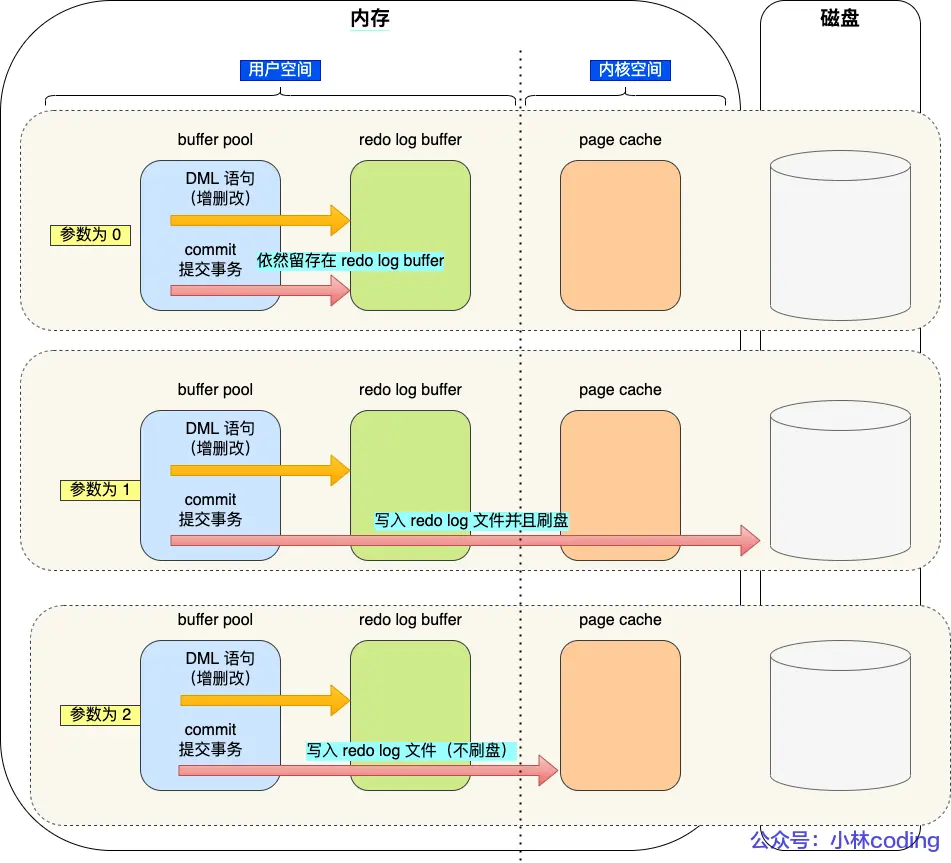
redo log什么時候刷盤?
- MySQL正常關閉時
- redo log buffer記錄的寫入量大于redo log buffer內存空間的一半
- InnoDB的后臺線程每隔一秒刷盤一次
- 每次事務提交時都將緩存持久化到磁盤(可選策略,通過innodb_flush_log_at_trx_commit參數控制)
redo log文件寫滿了怎么辦?
- 默認情況下,InnoDB存儲引擎有1個重做日志組,日志組由2個redo log文件組成,分別名為ib_logfile0和ib_logfile1
- 兩個文件的大小是固定且一致的,文件組是以循環寫的方式工作的,類似于循環隊列
- 所以file0會先被寫滿,寫滿后切換至file1,file1寫滿后又會回到file0
- redo log是為防止臟頁數據意外丟失而存在的,當臟頁數據已經持久化到磁盤中,我們就需要從redo log中移除對應的記錄。check point相當于要擦除(覆蓋)的位置(類似于redis的環形緩存區)
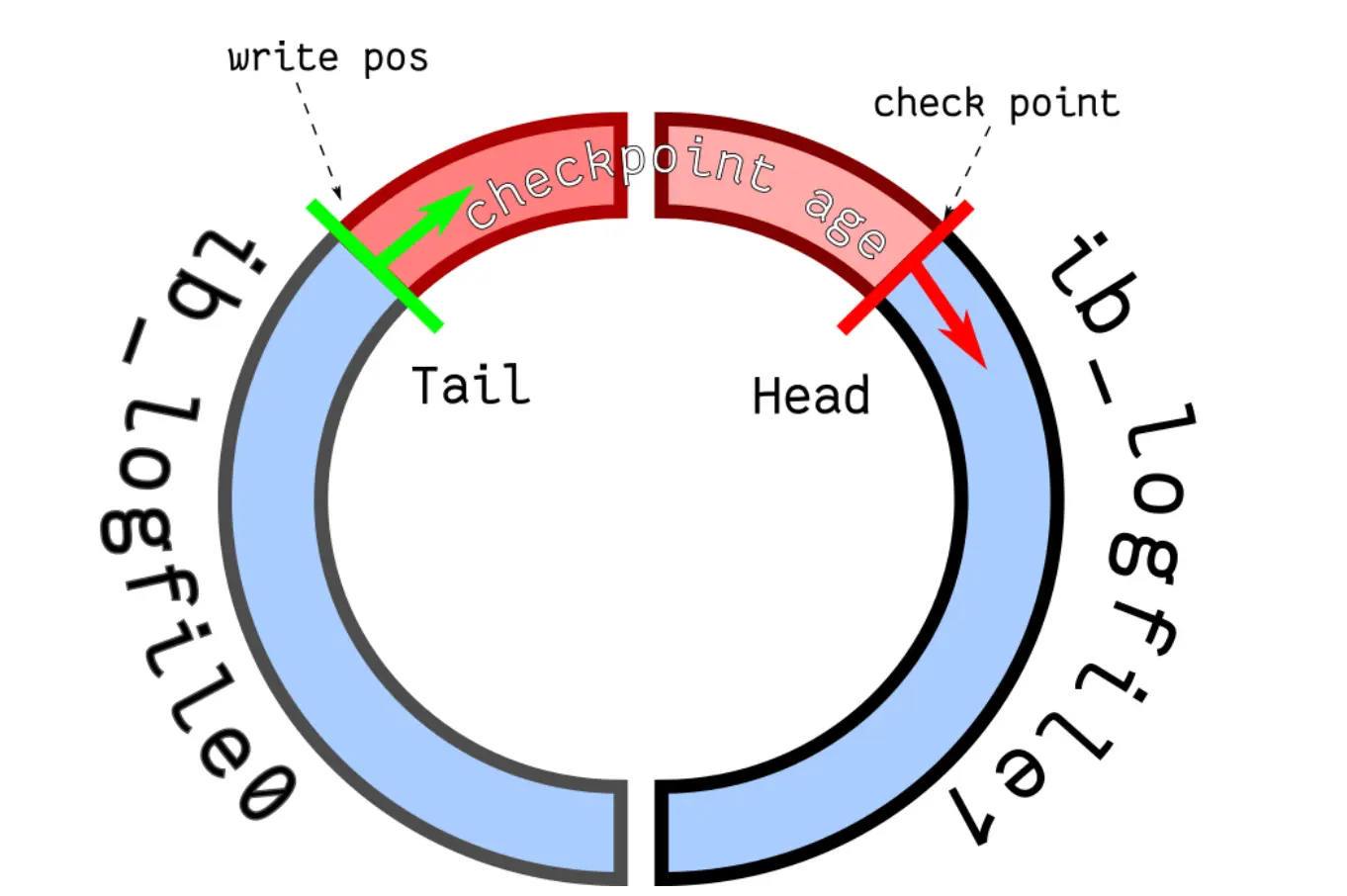
- write pos和checkpoint的移動都是順時針方向;
- write pos到checkpoint之間的部分,用于記錄新的更新操作
- checkpoint到write pos之間的部分,為待持久化的臟頁數據記錄
- 若write pos追上了checkpoint,意味著redo log文件已滿,此時MySQL不能執行新的更新操作,導致MySQL阻塞。阻塞時會將Buffer Pool的臟頁刷新到磁盤中,然后標記redo log哪些記錄可以被擦除,接著對舊的redo log記錄進行擦除,等待文件騰出空間后checkpoint繼續移動,MySQL恢復正常運行。
- 對于并發量大的系統,適當設置redo log的文件大小非常重要,否則容易導致MySQL阻塞。
redo log和undo log的區別?
- redo log:記錄的是事務修改后的數據狀態,記錄的是更新后的值,用于事務崩潰恢復,保證事務的持久性。
- undo log:記錄了事務修改前的數據狀態,記錄的是更新前的值,用于事務回滾,保證事務的原子性。
- 事務提交前發生錯誤可通過undo log回滾,即使是崩潰也沒事,因為事務沒提交的數據本身就是無效的。
- redo log針對的是事務提交后但數據還未持久化就發生崩潰的場景,重啟后MySQL可根據redo log恢復事務
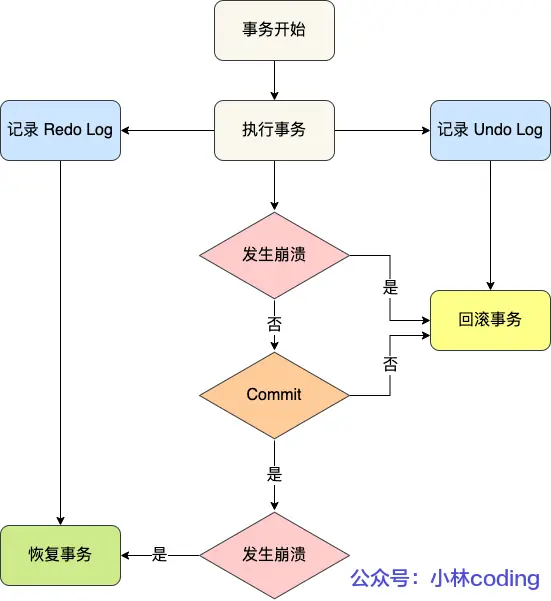
有了redo log后,通過WAL技術,就可以保證即使數據庫異常關閉重啟,之前提交的記錄都不會丟失,這個能力就稱為crash-safe(崩潰恢復)。保證了數據的持久性和一致性。
binlog詳解
前文介紹的undo log和redo log都是Innodb存儲引擎生成的。
MySQL完成更新操作后,server層會生成一條binlog,事務提交后會將該事務執行產生的所有binlog統一寫入binlog文件中。
binlog文件記錄了所有數據庫表結構變更、表數據修改的操作,但不會記錄查詢相關操作。
為什么還需要redo log?
最開始MySQL并沒有Innodb引擎,使用的是MyISAM引擎,所以沒有crash-safe特性,bin log只能用于歸檔,而redo log可實現crash-safe。
redo log和bin log的區別:
1、適用對象不同:
- binlog是MySQL的server層實現的日志,所有引擎都可以使用
- redo log是Innodb引擎實現的日志
2、文件格式不同:
- binlog 有 3 種格式類型,分別是 STATEMENT(默認格式)、ROW、 MIXED,區別如下:? ?
- STATEMENT:每一條修改數據的 SQL 都會被記錄到 binlog 中(相當于記錄了邏輯操作,所以針對這種格式, binlog 可以稱為邏輯日志),主從復制中 slave 端再根據 SQL 語句重現。但 STATEMENT 有動態函數的問題,比如你用了 uuid 或者 now 這些函數,你在主庫上執行的結果并不是你在從庫執行的結果,這種隨時在變的函數會導致復制的數據不一致;
- ?ROW:記錄行數據最終被修改成什么樣了(這種格式的日志,就不能稱為邏輯日志了),不會出現 STATEMENT 下動態函數的問題。但 ROW 的缺點是每行數據的變化結果都會被記錄,比如執行批量 update 語句,更新多少行數據就會產生多少條記錄,使 binlog 文件過大,而在 STATEMENT 格式下只會記錄一個 update 語句而已;
- ?MIXED:包含了 STATEMENT 和 ROW 模式,它會根據不同的情況自動使用 ROW 模式和 STATEMENT 模式;
- redo log是物理日志,記錄的是某個數據頁做了什么修改,比如對XXX表空間中的YYY數據頁ZZZ偏移量的地方做了AAA更新。
3、寫入方式不同:
- binlog是追加寫,寫滿一個文件,就創建一個新的文件繼續寫入,不會覆蓋以前的日志,保存的是全量日志。
- redo log是循環寫,日志空間大小固定,全部寫滿就從頭開始,保存未被刷入磁盤的臟頁數據。
4、用途不同:
- binlog用于備份恢復、主從復制
- redo log用于崩潰等故障的數據恢復
主從復制如何實現?
MySQL的主從復制依賴于binlog,也就是記錄MySQL上的所有變化并以二進制形式保存在磁盤上。復制過程就是將binlog中的數據從主庫傳輸到從庫上,一般是異步操作。
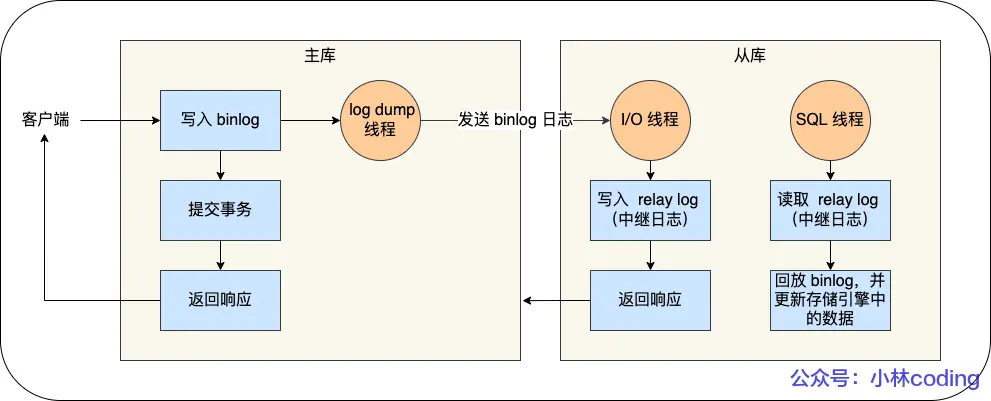
三個階段:
- 寫入binlog:主庫寫binlog日志,提交事務,并更新本地存儲數據
- 同步binlog:將binlog復制到所有從庫上,每個從庫將binlog寫到暫存日志中
- 回放binlog:恢復binlog,更新存儲引擎中的數據
binlog什么時候刷盤?
- 事務執行過程中,日志先寫到binlog cache(Server層的緩存),事務提交時再將緩存中的日志寫到binlog文件中。
- 一個事務的binlog是不能拆開的,需要保證一次性寫入,避免破壞原子性,也對應一個線程只能同時執行一個事務的設定。
- MySQL為每個線程分配了一片內存用于緩沖binlog,該內存叫binlog cache,參數binlog_cache_size用于控制單個線程內binlog cache所占內存的大小
- 事務提交時,執行器將binlog cache里的完整事務寫入到binlog文件中,并清空緩存
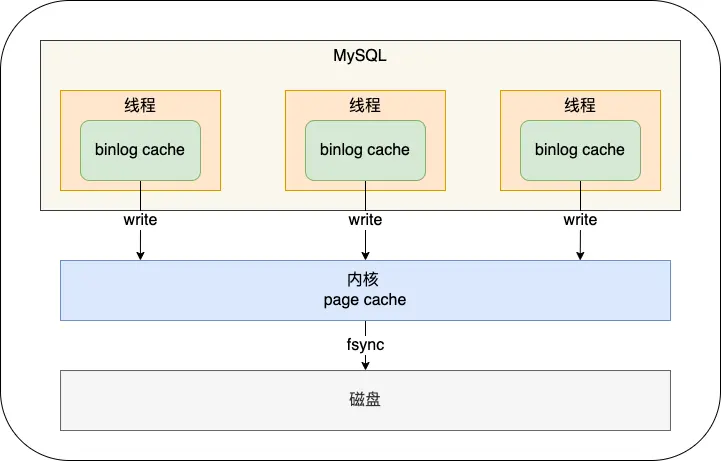
write操作即為寫到binlog文件中,但并不是持久化,而是在內核緩存中存儲,不涉及磁盤io
fsync才是真正的刷盤操作,涉及磁盤io
MySQL提供一個sync_binlog參數(默認為0)來控制數據庫的binlog刷到磁盤上的頻率:
- sync_binlog=0時,表示每次提交事務都只write,不fsync,后續交由操作系統決定何時將數據持久化到磁盤。
- sync_binlog=1時,表示每次提交事務都會write,并馬上執行fsync
- sync_binlog=N時,表示每次提交事務都會write,但積累N個事務后才fsync
update語句的執行過程:
優化器分析出成本最小的執行計劃后,執行器按照執行計劃開始更新:
1、執行器調用存儲引擎接口,通過索引查詢記錄
- ? ? ? ? 若該條記錄所在的頁存在于Buffer Pool中,直接返回給執行器使用
- ? ? ? ? 若該條記錄在Buffer Pool中,則從磁盤讀取對應數據頁到Buffer Pool中,并返回給執行器
2、執行器得到聚簇索引記錄后,會比較更新前和更新后的記錄是否一樣
- ? ? ? ? 若一樣則直接跳過后續的日志寫入、事務提交等操作。
- ? ? ? ? 若不一樣則將修改前和修改后的記錄都作為參數傳入InnoDB層,執行真正的更新記錄操作。
3、開啟事務,記錄undo log,寫入Buffer Pool的Undo頁面,Undo頁面變化時記錄對應的redo log
4、InnoDB層開始更新記錄,并更新內存(同時標記為臟頁),然后將記錄寫入redo log里面,此時更新操作完成。
- ????????為減少磁盤IO并不直接將臟頁寫入磁盤中,而是先記錄redo日志,后尋找合適時機刷盤臟頁數據。也就是WAL技術。
5、至此,更新語句結束。
- ????????語句完成后,記錄該語句對應的binlog,此時記錄的binlog會被保存到binlog cache,并沒有刷新到磁盤上的binlog文件,事務提交時才會統一將該事務運行過程中的所有的binlog文件刷新到磁盤(中途會先write到內核的頁緩存中)中。
6、兩階段提交日志。
為什么需要兩階段提交?
事務提交后,redo log和binlog都需要持久化到磁盤中,但這兩個是獨立邏輯,可能出現半成功的情況,造成數據不一致,需要確保它們提交的原子性。
redo log提交成功,binlog提交失敗。主庫數據更新成功但binlog丟失記錄,進而導致主從復制時從庫數據是舊的,以及備份的數據不一致。
binlog提交成功,redo log提交失敗。主庫數據更新丟失,但從庫和備份有記錄,導致主庫數據是舊的,數據不一致。
兩階段提交則是將單個事務拆分為了兩個階段:prepare階段和Commit階段。每個階段由協調者和參與者共同完成。這里的Commit階段與commit語句不同,commit語句包含了這里的Commit階段。







)



)

![[模型部署] 1. 模型導出](http://pic.xiahunao.cn/[模型部署] 1. 模型導出)



+flutter項目搭建-混合開發+分欄效果)

