摘要
本文主要介紹了Web頁面端日志采集的設計。首先闡述了頁面瀏覽日志采集,包括客戶端日志采集的實現方式、采集內容及技術亮點。接著介紹了無線客戶端端日志采集,包括UserTrack的核心設計、移動端與瀏覽器端采集差異以及典型應用場景崩潰分析。最后探討了日志采集的挑戰與解決方案,以及日志采集前置到用戶終端的相關問題。
1. Web頁面端日志采集
1.1. 頁面瀏覽(展現)日志采集
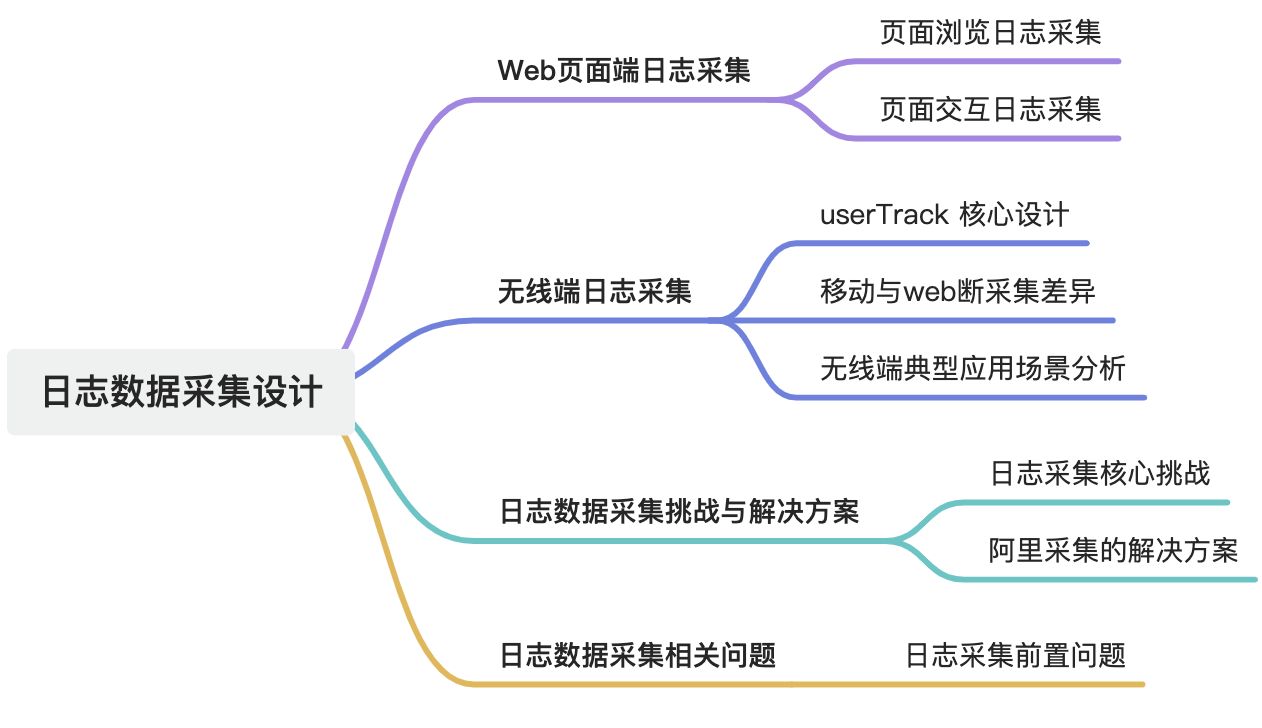
記錄頁面加載和首次渲染的日志,是互聯網產品最基礎的統計來源。
1.1.1. 客戶端日志采集
實現方式:
- 動態腳本植入(占比高):由業務服務器在響應HTTP請求時,動態插入日志采集腳本(如通過模板引擎注入
<script>標簽)。 - 優勢:支持實時參數配置(如動態業務標識、AB實驗參數),無需人工干預。
- 手動植入:開發人員在頁面代碼中手動嵌入SDK腳本,適用于定制化需求較高的場景。
采集內容:
- 頁面參數:URL、Referrer(來源頁)、頁面標題等。
- 上下文信息:HTTP Referer(上一步頁面)、用戶行為軌跡(如點擊事件)。
- 環境信息:UserAgent(瀏覽器類型/版本)、屏幕分辨率、時區等。
技術亮點:
- 防篡改機制:通過HMAC簽名驗證請求合法性,防止偽造日志。
- 跨域處理:使用JSONP或CORS解決跨域腳本加載問題。
1.1.2. 客戶端日志發送
發送策略:
- 同步發送:優先在頁面加載完成時立即發送,確保核心指標(PV/UV)實時性。
- 延遲發送:對非關鍵日志(如用戶停留時長)采用異步上報,避免阻塞頁面渲染。
技術實現:
- HTTP協議:通過GET/POST請求發送,參數拼接在URL或Body中(如
?t=1620000000&_m_h5_tk=xxx)。 - 可靠性保障:
-
- Beacon API:在頁面卸載時使用
navigator.sendBeacon確保數據發送。 - 本地存儲兜底:失敗日志暫存LocalStorage,下次會話補傳。
- Beacon API:在頁面卸載時使用
優化措施:
- 請求合并:同頁面多個日志合并為單次請求,減少連接數。
- 數據壓縮:使用Gzip或Brotli壓縮URL參數。
1.1.3. 服務器端日志收集
接收與響應:
- 快速響應:日志服務器收到請求后立即返回200狀態碼,避免影響頁面加載性能。
- 異步寫入:日志內容寫入內存緩沖區(如Kafka Producer Buffer),非阻塞處理。
緩沖區設計:
- 分級存儲:
-
- 熱緩沖區:內存級存儲,支持高吞吐寫入(如Apache Pulsar內存隊列)。
- 冷緩沖區:磁盤級存儲,應對突發流量溢出(如本地文件隊列)。
- 數據持久化:定期刷盤(如每5秒),防止數據丟失。
1.1.4. 服務器端日志解析存檔
解析流程:
- 格式解碼:解析URL參數或POST Body,提取結構化字段(如
_m_h5_tk解析為設備指紋)。 - 數據清洗:
-
- 字段校驗:過濾非法字符(如XSS攻擊特征)。
- 異常值處理:剔除異常時間戳(如未來時間或超長停留時長)。
- 補全信息:
-
- 關聯業務數據:通過
_m_h5_tk關聯用戶畫像(如地域、設備型號)。 - 時區校正:統一轉換為UTC時間。
- 關聯業務數據:通過
- 存儲與分發:
-
- 標準日志文件:按小時切割存儲至HDFS(如
/log/pv/2023100101.log)。 - 實時消息隊列:推送到Kafka供下游實時計算(如Flink統計UV)。
- 標準日志文件:按小時切割存儲至HDFS(如
1.2. 頁面交互日志數據采集
記錄用戶與頁面交互行為的日志(如點擊、滾動、表單輸入等),用于行為分析。
1.2.1. 阿里“黃金令箭”交互日志采集方案
1.2.1.1. 業務方注冊與模板生成
元數據管理:
- 業務方在“黃金令箭”控制臺注冊:
-
- 業務標識(如“淘寶購物車”)。
- 場景維度(如“商品詳情頁曝光”)。
- 交互采集點(如“按鈕點擊”“輸入框回車”)。
- 動態生成代碼模板:系統根據配置生成輕量級JS SDK代碼片段(如
goldendart.js)。
技術特點:無代碼侵入:通過動態注入腳本,無需修改業務代碼邏輯。
參數化配置:支持自定義事件參數(如按鈕ID、輸入內容)。
1.2.1.2. 交互代碼植入與綁定
植入方式:
- 手動植入:開發人員將SDK代碼嵌入HTML頁面(如
<script src="goldendart.js"></script>)。 - 自動注入:通過阿里云ARMS等工具動態注入SDK(適用于動態頁面)。
行為綁定:
- 通過事件監聽器(如
addEventListener)綁定交互行為:
// 示例:監聽按鈕點擊事件
goldendart.track('button_click', {button_id: 'add_to_cart',page_url: window.location.href
});- 上下文增強:自動附加環境信息(如設備類型、頁面URL、時間戳)。
1.2.1.3. 日志觸發與上報
觸發時機:
- 同步觸發:用戶行為發生時立即上報(如點擊事件)。
- 延遲觸發:對高頻行為(如滾動)采用防抖策略(如每500ms聚合一次)。
數據上報:
- HTTP協議:通過POST請求發送至日志服務器(如
https://log.taobao.com/golden_arrow)。 - 數據完整性:通過HMAC簽名驗證數據合法性,防止篡改。
- 數據格式:
POST /golden_arrow
{"event_type": "input_submit","biz_code": "taobao_cart","custom_data": {"item_id": "12345", "price": 99.9},"_m_h5_tk": "設備指紋","timestamp": 1620000000
}1.2.1.4. 服務器端處理與存儲
日志接收:
- 快速響應:返回200狀態碼,避免阻塞業務請求。
- 異步寫入緩沖區:數據寫入Kafka或RocketMQ,支持削峰填谷。
數據解析策略:
- 非結構化存儲:保留原始JSON數據,僅解析固定字段(如
biz_code、event_type)。 - 動態Schema支持:業務方可自定義字段(如電商場景的
sku_id、游戲場景的level_id)。
數據關聯:通過_m_h5_tk設備指紋關聯PV日志與交互日志,構建用戶行為時序鏈條。
1.2.2. 頁面日志的服務器端清洗和預處理
| 處理階段 | 處理原因 | 處理方法 | 技術手段 | 輸出結果 |
| 識別虛假流量 | 過濾惡意流量(如爬蟲、作弊、DDoS攻擊),避免污染核心指標(如PV/UV)。 | - 基于機器學習模型識別異常模式(如高頻點擊、異常IP聚集) | - 機器學習(如XGBoost) | 清洗后的合法日志,剔除異常流量 |
| 數據缺項補正 | 統一數據口徑,補充缺失字段(如用戶登錄后回補身份信息)。 | - 數據歸一化(如統一時間戳格式) | - Flink實時計算 | 標準化結構化數據,字段完整率提升 |
| 無效數據剔除 | 去除冗余、錯誤或失效數據(如已下架商品的交互日志)。 | - 配置驅動的數據校驗(如正則校驗字段格式) | - 數據質量監控工具(如Apache Griffin) | 精簡數據集,存儲與計算資源消耗降低 |
| 日志隔離分發 | 滿足數據安全(如隱私合規)或業務隔離需求(如區分核心業務與非核心業務日志)。 | - 基于RBAC的權限控制(如僅允許特定團隊訪問支付日志) | - 數據加密(如TLS傳輸) | 隔離后的日志按需分發至不同業務環境 |
2. 無線客戶端端日志采集
2.1. UserTrack(UT)的核心設計
2.1.1. 事件分類機制
| 事件類型 | 定義 | 典型場景 | 技術實現差異 |
| 頁面事件 | 頁面生命周期事件(加載、卸載、曝光)。 | 頁面PV/UV統計、停留時長計算。 | 監聽 生命周期或前端路由變化。 |
| 控件點擊事件 | 用戶與界面元素的交互行為(按鈕點擊、滑動)。 | 按鈕轉化率分析、熱力圖生成。 | 注入事件監聽器(如 )。 |
| 自定義事件 | 業務定制化行為(如支付成功、游戲通關)。 | 核心業務指標統計、用戶路徑分析。 | 通過UT API主動上報(如 )。 |
2.1.2. 關鍵技術挑戰與解決方案
| 挑戰 | 問題表現 | UT的解決方案 |
| 設備唯一性標識 | Android設備ID碎片化(IMEI/Android ID等)。 | 設備指紋算法:融合多維度信息(設備ID+IP+UserAgent+時間戳),生成哈希值 。 |
| Hybrid日志統一 | H5與Native日志格式不一致,數據難以關聯。 | 橋接機制:通過JSBridge將H5事件轉發至Native層統一上報。 |
| 網絡不穩定 | 數據上傳失敗導致丟失。 | 本地存儲+重試策略:失敗日志暫存SQLite,網絡恢復后批量重試。 |
| 數據解析復雜性 | 日志字段異構(如JSON與鍵值對混合)。 | 統一數據格式:所有日志序列化為Key-Value結構,支持動態Schema解析。 |
2.1.3. 數據上傳策略
實時性分級:
- 高優先級(如崩潰日志):立即上傳,失敗時啟用短信重試。
- 普通優先級(如點擊事件):批量上傳(每30秒或退出頁面時)。
流量控制:
- 動態壓縮(GZIP壓縮率>70%)。
- 智能降頻(弱網環境下采樣率降至10%)。
2.2. 移動端與Web端采集差異
| 維度 | 移動端(UT) | 瀏覽器端(黃金令箭) |
| 設備標識 | 設備指紋(IMEI/Android ID+算法哈希) | Cookie+IP+UserAgent |
| 事件觸發 | 依賴Native API(如Activity生命周期) | 基于瀏覽器事件(如 |
| 網絡環境 | 需處理弱網、斷網場景(如地鐵、地下室) | 依賴穩定HTTP連接 |
| 數據格式 | 統一Key-Value結構,適配多語言(Java/Kotlin) | 基于URL參數或JSON,依賴JavaScript執行環境 |
2.3. 無線端日志采集典型場景
崩潰分析:捕獲ANR(Android無響應)與Crash日志,關聯設備信息快速定位問題。
// 示例:捕獲Java異常并上報
try {// 業務代碼
} catch (Exception e) {UT.track("crash", new HashMap<String, String>() {{put("stack_trace", e.toString());put("device_model", Build.MODEL);}});
}用戶行為分析:追蹤“加入購物車”按鈕點擊率,優化商品詳情頁布局。
性能監控:統計頁面加載時長(onCreate到onResume耗時)。
3. 日志采集挑戰與解決方案
3.1. 日志采集核心挑戰
以下是整理后的表格:
| 問題分類 | 表現描述 | 核心難點 |
| 海量日志處理壓力 | 日志量達億級/日,大促期間近萬億級數據;全鏈路(采集、傳輸、解析、分析)存在性能瓶頸。 | 需協同優化峰值QPS、傳輸速度、實時解析吞吐量與計算資源分配,避免單一環節成為性能瓶頸。 |
| 日志結構化與規范化 | 日志類型多樣、規模激增,需統一分類與標準化;避免資源浪費(如過度預處理)或覆蓋不全(僅處理關鍵日志)。 | 動態業務需求下,如何靈活適配不同日志的解析規則(如URL正則匹配維護成本高),平衡規范化和靈活性。 |
| 實時性與業務深度平衡 | 高實時性場景(如推薦系統)要求端到端低延遲,但傳統鏈路環節多(采集→傳輸→解析→分析),難以滿足需求。 | 需權衡穩定性與擴展性(如增加實時計算能力可能引入故障風險),優化鏈路環節或采用輕量化處理方案。 |
| 資源分配與熱點突發 | 流量熱點(如大促頁面)與常規模塊共享資源,易導致關鍵業務被淹沒。 | 在共享基礎設施時實現優先級控制與分流,避免資源競爭,需動態調度策略(如基于SLA的資源隔離)。 |
| 動態配置與擴展性 | 業務快速迭代要求日志采集規則靈活調整,傳統靜態配置(季度/年更新)無法適應。 | 客戶端和服務端協同實現高頻更新(如周/月級)與配置化落地,需動態配置中心支持(如熱更新、版本回滾)。 |
3.2. 阿里數據采集解決方案
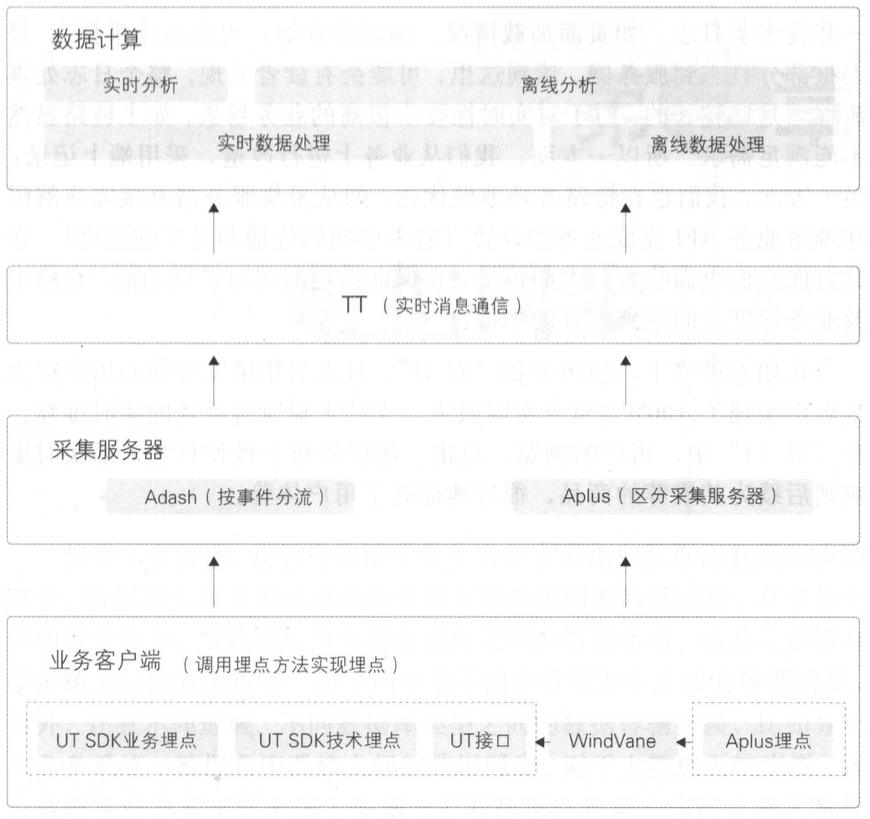
3.2.1. 日志采集鏈路的分層優化
推送式配置管理
- 服務端可動態下發采集配置,實現日志的實時采樣、延遲上報、限流控制。
- 配置可針對具體應用、平臺、事件或場景,實現精細化管理。
客戶端前置分類與更新
- 將部分日志分類與邏輯前置到客戶端,減少服務器端處理壓力。
- 客戶端采集代碼支持高頻率更新(周/月級),并實現配置化,提高響應速度。
3.2.2. 日志分流機制
按優先級與業務分流
- 對日志進行優先級劃分(如用戶行為 vs 技術日志)。
- 根據業務特征和日志重要程度,將日志拆分至不同采集處理通道。
按業務類型路由分流
- 日志采集路徑根據頁面類型變化,早期進行路由分流,減少后端分支判斷和資源消耗。
3.2.3. 采算一體應用鏈路
SPM 與 Goldlog 規范系統
- SPM(頁面流量埋點)規范:支持頁面訪問日志結構化、歸類、自動聚合分析。
- Goldlog(自定義事件埋點)規范:支持定制事件采集與可視化分析。
- 用戶通過簡單配置即可完成日志注冊、采集、統計、展示的全流程。
元數據中心支持
- 埋點信息通過元數據注冊,驅動采集與后端計算協同,降低手動配置成本。
3.2.4. 高性能日志處理與錯峰限流
高峰期日志限流機制
- 對非關鍵日志延遲上傳或采樣上報,確保系統高可用性。
- 高峰期動態啟用限流策略,平穩過渡后再恢復全量日志處理。
端上日志記錄+本地計算
- 對于高實時性場景(如實時推薦),直接在采集節點完成部分業務邏輯處理,跳過部分中間層,提升處理
4. 日志數據采集相關問題
4.1. 日志采集前置到用戶終端(如手機)是否有要求、以及是否會影響用戶使用體驗?
4.1.1. 是否對用戶手機有要求?
原則上沒有硬性要求
- 日志前置分類主要涉及客戶端(如App)中嵌入的埋點邏輯和配置信息,不依賴手機的硬件特性。
- 適用于絕大多數智能手機終端(Android/iOS主流版本均支持)。
面向客戶端更新的兼容性設計
- 采用配置化、模塊化更新,避免因新功能導致舊版本手機不兼容。
- 若某些機型或系統版本不支持某項功能,可通過灰度發布、降級策略處理。
性能資源方面需適當控制
- 日志前置分類需要一定的 本地計算資源(CPU)、存儲資源(緩存),但設計時通常考慮其開銷微小。
- 會對設備帶來極小的計算和存儲負擔,但遠低于音視頻渲染等任務。
4.1.2. 是否會影響用戶使用體驗?
正常使用幾乎無感知
- 分類操作通常在頁面加載/事件觸發后異步執行,不占用主線程,不阻塞 UI 渲染。
- 日志寫入與上傳采用異步+批量策略,不會造成明顯卡頓或延遲。
日志上傳有節流策略
- 支持延遲上傳、弱網暫停、僅 WiFi 上傳等配置策略,避免在用戶弱網或流量寶貴時頻繁傳輸日志。
極端情況下的影響控制
- 在極端高頻埋點場景(如滾動監聽、滑動手勢等)中,如果埋點密集、優化不當,可能會引起:頁面卡頓、電量消耗稍高、應用包體增大(埋點 SDK 過重)
解決方法:
- 使用采樣率控制 + 埋點聚合策略(如將滾動次數合并統計)
- 動態配置控制哪些埋點啟用
- 定期清理本地緩存日志
4.1.3. 互聯網大廠是怎么控制這類問題的?
- SDK 輕量設計:客戶端 SDK 僅承擔分類和緩存,不做復雜計算。
- 配置中心動態控制:可對特定設備型號/系統版本下發特定策略。
- 灰度與A/B測試機制:保障任何埋點和分類策略上線前都經過性能驗證。
- 本地監控指標采集:檢測客戶端埋點對性能的影響,實時反饋和優化。
5. 博文參考
《阿里巴巴大數據實踐》


的差異)
)


)












