文章目錄
- 1.時間序列建模的完整流程
- 2. 模型選取的和數據集
- 2.1.ARIMA模型
- 2.2.數據集介紹
- 3.時間序列建模
- 3.1.數據獲取
- 3.2.處理數據中的異常值
- 3.2.1.Nan值
- 3.2.2.異常值的檢測和處理(Z-Score方法)
- 3.3.離散度
- 3.4.Z-Score
- 3.4.1.概述
- 3.4.2.公式
- 3.4.3.Z-Score與標準差
- 3.4.4.Z-Score與數據標準化
- 3.4.5.歐幾里得距離
- 4.數據分析
- 4.1.重置DateFrame類型數據索引
- 4.2.數據可視化
- 4.2.Python 庫 – statsmodels
- 4.2.3.特性
- 4.2.4.基本功能
- 4.2.5.高級功能
- 4.2.6.實際應用
- 4.3.趨勢性分析
- 4.4.季節性分析
- 4.5.周期性分析
- 4.6.整合圖
- 4.7. ACF和PACF
- 4.8.平穩性檢驗
- 5.模型訓練
- 6.Python庫 – pdmarima
- 6.1.主要功能
- 6.2.基本用法
- 6.3.高級用法
- 7.ARIMA模型分析流程
1.時間序列建模的完整流程
-
數據收集:
首先收集時間序列數據。這些數據應該是按時間順序排列的連續觀察值(數據的時間不連續可以么,是不可以如果有這種不連續的情況,建議提高時間單位從而避免這個情況)。
-
數據預處理:
數據清洗:處理缺失值。
異常值數據轉換:如對數轉換,歸一化等,以穩定數據的方差(此處應該是兩部分包括異常值檢測和異常值處理)。 -
數據分析:分析數據的特征,如季節性、趨勢、周期性等,這一步是重要的你的模型的效果好壞可能百分之60來源于模型,另外的百分之40就來源于這一步。
-
模型選擇:
可以選擇的模型包括ARIMA(自回歸積分滑動平均模型)、季節性ARIMA、指數平滑、Prophet模型、機器學習模型等。
還可以使用深度學習方法,如循環神經網絡(RNN)、長短期記憶網絡(LSTM)。
同時還有這兩年比較流行的Transformer模型,此方法適合想要發論文的同學。 -
劃分數據集:將數據集劃分為測試集驗證集訓練集
-
模型訓練:使用訓練數據集來訓練選定的模型。
-
模型評估:
在測試集上評估模型性能。
常用的評估指標包括均方誤差(MSE)、均方根誤差(RMSE)、平均絕對誤差(MAE)等。 -
參數調優:根據模型在測試集上的表現調整參數,以提高預測準確性。
2. 模型選取的和數據集
2.1.ARIMA模型
ARIMA模型對于參數的設定是十分敏感的,不同的參選擇效果可能差異很大
2.2.數據集介紹
一個股票數據集,從2016-01-04開始到2018-12-28,每天采集一次數據,中間時期有缺失值
(PS:electricity數據集是平穩的)
3.時間序列建模
3.1.數據獲取
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_16:37
@FileName:1獲取數據.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd"""
pd.read_csv()讀取.csv文件,并將其加載到一個Pandas DateFrame中
index_col=['date']:指定date列作為DateFrame的索引
parse_dates=['date']:將date列解析為日期時間格式,如果不指定這一參數,date列將被視為普通的字符串
"""
data = pd.read_csv(r"E:\07-code\time_series_study\data\traffic.csv", index_col=['date'], parse_dates=['date'])
print(data.index)
print(data)
3.2.處理數據中的異常值
3.2.1.Nan值
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_17:26
@FileName:2處理數據中的Nan值.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import numpy as np
import pandas as pddata_dict = {'Date': pd.date_range(start='2023-01-01', periods=10, freq='D'),'Volume': [100, np.nan, 200, 300, np.nan, 400, 500, np.nan, 600, 700]
}
data = pd.DataFrame(data_dict).set_index('Date')
"""Volume
Date
2023-01-01 100.0
2023-01-02 NaN
2023-01-03 200.0
2023-01-04 300.0
2023-01-05 NaN
2023-01-06 400.0
2023-01-07 500.0
2023-01-08 NaN
2023-01-09 600.0
2023-01-10 700.0
"""
print(data.to_string())"""
data['Volume']: 選擇 data DataFrame 中的 Volume 列
.rolling(window=5, min_periods=1): 創建一個滑動窗口對象,該對象將在 Volume 列上滑動。window=5 指定窗口大小為 5(即計算每個位置的前 5 個值的平均值)min_periods=1 指定窗口中至少有 1 個非 NaN 值時才計算平均值
.mean(): 計算每個滑動窗口的平均值,返回一個與 Volume 列大小相同的 Series,對應位置的值為該位置滑動窗口內的平均值。
"""
moving_avg = data['Volume'].rolling(window=5, min_periods=1).mean()
"""
Date
2023-01-01 100.0
2023-01-02 100.0
2023-01-03 150.0
2023-01-04 200.0
2023-01-05 200.0
2023-01-06 300.0
2023-01-07 350.0
2023-01-08 400.0
2023-01-09 500.0
2023-01-10 550.0
"""
print(moving_avg)# Fill NA/NaN values using the specified method.
# dict/Series/DataFrame, This value cannot be a list.
data['Volume'] = data['Volume'].fillna(moving_avg)
"""Volume
Date
2023-01-01 100.0
2023-01-02 100.0
2023-01-03 200.0
2023-01-04 300.0
2023-01-05 200.0
2023-01-06 400.0
2023-01-07 500.0
2023-01-08 400.0
2023-01-09 600.0
2023-01-10 700.0
"""
print(data.to_string())print("---traffic數據集---")
re_data = pd.read_csv(r'E:\07-code\time_series_study\data\exchange_rate_test.csv', index_col=['date'], parse_dates=['date'])
print("原始數據:")
# print(tr_data)
moving_avg = re_data['OT'].rolling(window=5, min_periods=1).mean()
print("移動平均值:")
print(moving_avg)
re_data['OT'] = re_data['OT'].fillna(moving_avg)
print("去Nan值后的數據:")
# print(tr_data)
print("over")3.2.2.異常值的檢測和處理(Z-Score方法)
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_8:58
@FileName:3檢查和處理異常值.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd
# 示例
# TODO:1.模擬數據
"""
pd.date_range 函數中的 freq 參數用于指定日期范圍的頻率。它決定了生成的日期索引之間的時間間隔。常用的頻率選項包括日、月、年等。
"""
data = {'date': pd.date_range(start='2024-07-04', periods=10, freq='D'),'Volume': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000]
}
data = pd.DataFrame(data=data).set_index('date')
# 引入一些異常值
"""
loc():Access a group of rows and columns by label(s) or a boolean array.
data.loc[...]:這是 Pandas 的 loc 索引器,用于按標簽選擇數據。.loc[] is primarily label based, but may also be used with a boolean array.data.loc['2023-07-06', 'Volume']:選擇 2023-07-06 這一天的 Volume 列。
"""
data.loc['2024-07-06', 'Volume'] = 5000
data.loc['2024-07-11', 'Volume'] = -2000
# 打印原始數據
print("原始數據:")
print(data.to_string())# TODO:2.計算激動平均值、Z-Score
# 計算移動平均值
data['moving_average'] = data['Volume'].rolling(window=5, min_periods=1).mean()
# 計算Z-Score
data['Z-Score'] = (data['Volume'] - data['Volume'].mean()) / data['Volume'].std()
"""
.abs()取絕對值
"""
# 輸出data['Z-Score']的絕對值
print("data['Z-Score']的絕對值:")
print(data['Z-Score'].abs())# TODO:3.檢查并處理異常值
# 將異常值替換為移動平均值
data.loc[data['Z-Score'].abs() > 1.5, 'Volume'] = data['moving_average']
# 打印處理后的數據
print("處理后的數據:")
print(data.to_string())# 真實數據示例
# TODO:1.獲取數據
data = pd.read_csv(r"E:\07-code\time_series_study\data\exchange_rate_test.csv",index_col=['date'],parse_dates=['date']
)
# TODO:2.計算移動平均值和Z-Score
# 假設 data 是你的 DataFrame,column_name 是需要處理的列名
data['moving_avg'] = data['OT'].rolling(window=5, min_periods=1).mean()# 計算 Z-Score
data['z-score'] = (data['OT'] - data['OT'].mean()) / data['OT'].std()# TODO:3.檢測并處理異常值
# 將異常值替換為移動平均值
data.loc[data['z-score'].abs() > 1.5, 'OT'] = data['moving_avg']
print()3.3.離散度
離散度的評價方法:
-
極差
最大值-最小值
-
離均差平方和
離均差是數據與均值之差,為了避免正負問題:絕對值、平方,為了避免符號問題最常用的就是平方
-
方差
由于離均差的平方和與樣本個數有關,只能反映相同樣本的離散度,而實際工作中做比較很難做到相同的樣本,因此為了消除樣本個數的影響,增加可比性,將離均差的平方和求平均值,這就是我們所說的方差成了評價離散度的較好指標。
-
標準差
由于方差是數據的平方,與檢測值本身相差太大,人們難以直觀的衡量,所以常用**方差開根號**換算回來這就是我們要說的標準差。
-
變異系數
3.4.Z-Score
3.4.1.概述
z-score 也叫 standard score, 用于評估樣本點到總體均值的距離。z-score主要的應用是測量原始數據與數據總體均值相差多少個標準差。
z-score是比較測試結果與正常結果的一種方法。測試與調查的結果往往有不同的單位和意義,簡單地從結果本身來看可能毫無意義。當我們知道小明數學考了90分(滿分100),我們也許會認為這是一個好消息,但是如果我們拿小明的成績與班上平均成績相比較,我們也許會深感惋惜。z-score可以告訴我們小明數學成績和總體數學平均成績的比值。
3.4.2.公式
Z-Score 公式:單個樣本的情況:
z = x ? μ σ z=\frac{x-\mu}{\sigma} z=σx?μ?
例如:小明的數學成績是90,班級的數學平均成績為95,標準差為2,此時對于此例中的z score為:
z = x ? μ σ = 90 ? 95 2 = ? 2.5 z = \frac{x-\mu}{\sigma}=\frac{90-95}{2}=-2.5 z=σx?μ?=290?95?=?2.5
z score告訴我們這個分數距離平均分數相差幾個標準差。此例中,小明的數學分數低于班級平均分數2.5個標準差。
當我們不知道數據總體的μ和σ ,我們可以使用樣本均值和樣本標準差 ,此時我們可以用下式精確地表示式:
z i = x i ? x  ̄ S z_i=\frac{x_i-\overline{x}}{S} zi?=Sxi??x?
Z-Score 公式:均值的標準誤差:
如果我們有多個樣本,并且想知道這些樣本均值與總體均值距離多少個標準差,可以使用此公式:
z = x  ̄ ? μ σ ÷ n z=\frac{\overline{x}-\mu}{\sigma\div\sqrt{n}} z=σ÷n?x?μ?
例如:考過這張數學卷子的人的平均成績為80,標準差為15。那么對于包括小明等40位同學所在的班級來說:
z = x  ̄ ? μ σ ÷ n = 95 ? 80 15 ÷ 40 = 6.3 z=\frac{\overline{x}-\mu}{\sigma\div\sqrt{n}}=\frac{95-80}{15\div\sqrt{40}}=6.3 z=σ÷n?x?μ?=15÷40?95?80?=6.3
3.4.3.Z-Score與標準差
Z-Score表示抽樣樣本值與數據均值相差標準差的數目。舉個例子:
- z-score = 1 意味著樣本值超過均值 1 個標準差;
- z-score = 2 意味著樣本值超過均值 2 個標準差;
- z-score = -1.8 意味著樣本值低于均值 1.8 個標準差。
Z-Score告訴我們樣本值在正態分布曲線中所處的位置。Z-Score = 0告訴我們該樣本正好位于均值處,Z-Score = 3 則告訴我們樣本值遠高于均值。
3.4.4.Z-Score與數據標準化
Z-Score是一個經常被用于數據標準化的方法。在多指標評價體系中,由于各評價指標的性質不同,通常具有不同的數量級和單位,如果直接利用原始數據,就會突出數值較高的指標在分析中的作用,相對弱化數值較低指標的作用。因此,為了保證結果的可靠性,需要對原始數據進行標準化。
通過Z-Score 公式進行標準化(或者規范化):
z = x ? μ σ z=\frac{x-\mu}{\sigma} z=σx?μ?
其中:
- z是規范化后的值(也稱為z分數或者標準分數)
- x是原始數據
- μ是原始數據的均值
- σ是原始數據集的標準差
Z-Score標準化的目的:
Z-score規范化的原理基于統計學中的標準分數概念。它的主要目的是將原始數據轉換成一個標準的尺度,以便進行比較和分析。
- **中心化:**Z-score規范化通過從每個原始數據點中減去數據集的均值(μ),將數據的中心移動到零點。這一步是為了消除數據的原始均值對分析結果的影響,使得新的數據集具有零均值。
- **縮放尺度:**除了中心化之外,Z-score規范化還通過將中心化后的每個數據點除以數據集的標準差(σ),將數據縮放到相同的尺度。這一步是為了消除數據的尺度(或單位)差異,使得不同特征或不同數據集之間的比較更加公平和有意義。
通過這兩步操作,原始數據被轉換為一個具有零均值和單位方差的新數據集。這個過程也叫做標準化,得到的數據被稱為標準分數或Z分數。
Z-score規范化的主要優點包括:
- **尺度不變形:**規范化后的數據具有相同的尺度,這使得不同特征之間的比較更加公平。
- **中心化:**數據被中心化到均值為0,這有助于某些機器學習算法(如支持向量機和邏輯回歸)的性能和穩定性。
- **保持數據分布:**Z-score規范化不會改變數據的分布形狀。如果原始數據近似正態分布,那么規范化后的數據將具有均值為0和標準差為1,但仍然保持其原有的分布形狀。
- **距離解釋性:**在規范化后的空間中,歐幾里得距離可以解釋為標準差的倍數,這有助于理解數據點之間的相對距離。
在實際應用中,Z-score規范化廣泛應用于機器學習和數據分析領域,特別是當算法對數據的尺度和分布敏感時。例如,支持向量機(SVM)和K-均值聚類等算法在處理具有相同尺度的數據時表現更好。
此外,Z-score規范化也有助于提高梯度下降等優化算法的收斂速度。
3.4.5.歐幾里得距離
歐幾里得距離(Euclidean distance)是在數學中常用于衡量兩個點之間的距離的一種方法。它在幾何學和機器學習等領域都有廣泛的應用。歐幾里得距離基于兩點之間的直線距離,可以看作是在一個多維空間中測量兩個點之間的直線距離。
4.數據分析
分析數據的特征,如季節性、趨勢、周期性等(這一步是重要的,模型的效果好壞可能百分之60來源于模型,另外的百分之40就來源于數據分析)。
4.1.重置DateFrame類型數據索引
import pandas as pddata = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)
# 重置索引,創建一個新的整數索引
"""
pandas.DataFrame.reset_index:Reset the index, or a level of it.set the index of the DataFrame, and use the default one instead. If the DataFrame has a MultiIndex, this method can remove one or more levels.
參數:drop: bool, default FalseDo not try to insert index into dataframe columns. This resets the index to the default integer index."""
data = data.reset_index(drop=True)# 重置索引,創建一個新的整數索引
data = data.reset_index(drop=True)
4.2.數據可視化
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_10:55
@FileName:4數據分析-數據可視化.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd
from matplotlib import pyplot as pltfrom statsmodels.tsa.seasonal import seasonal_decomposedata_name = 'zgpa_train'# 獲取數據
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)# 重置索引,創建一個新的整數索引
data = data.reset_index(drop=True)data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()data['volume'] = data['volume'].fillna(data['moving_avg'])data['z-score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()data.loc[data['z-score'].abs() > 1.5, 'volume'] = data['moving_avg']# 可視化原始數據
data.plot()
plt.title('original data')
"""
plt.tight_layout() 是 Matplotlib 庫中的一個方法,用于自動調整子圖參數,以便讓子圖、軸標簽、標題和刻度標簽更好地適應圖形區域。其目的是解決默認情況下子圖可能會重疊或布局不佳的問題。
"""
plt.tight_layout()
plt.savefig(fr'E:\07-code\time_series_study\data\{data_name}_visual.png')
plt.show()
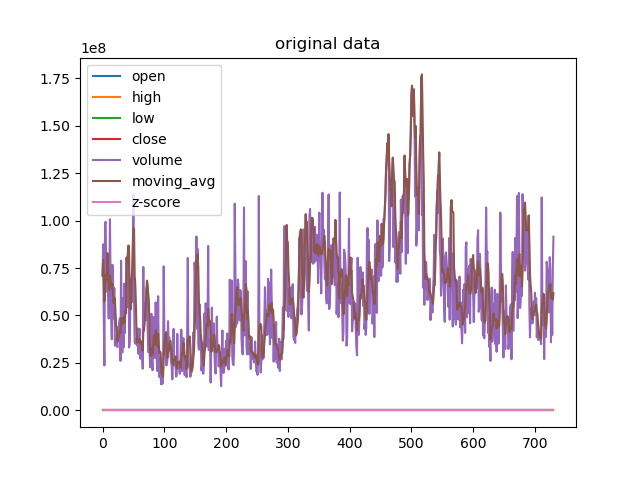
4.2.Python 庫 – statsmodels
Python statsmodels是一個強大的統計分析庫,提供了豐富的統計模型和數據處理功能,可用于數據分析、預測建模等多個領域。本文將介紹statsmodels庫的安裝、特性、基本功能、高級功能、實際應用場景等方面。
安裝statsmodels庫非常簡單,可以使用pip命令進行安裝:
pip install statsmodels
4.2.3.特性
- 提供了多種統計模型:包括線性回歸、時間序列分析、廣義線性模型等多種統計模型。
- 數據探索和可視化:提供了豐富的數據探索和可視化工具,如散點圖、箱線圖、直方圖等。
- 假設檢驗和統計推斷:支持各種假設檢驗和統計推斷,如t檢驗、方差分析等。
4.2.4.基本功能
-
線性回歸分析
Python statsmodels庫可以進行線性回歸分析,通過最小二乘法擬合數據,得到回歸系數和模型評估指標。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:44 @FileName:5數據分析-statsmodels庫-線性回歸分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import statsmodels.api as sm import numpy as np# 構造數據 x = np.array([1, 2, 3, 4, 5]) y = np.array([2, 3, 4, 5, 6])# 添加常數項 X = sm.add_constant(x)# 擬合線性回歸模型 model = sm.OLS(y, X) results = model.fit()# 打印回歸系數和模型評估指標 print(results.summary()) -
時間序列分析
Python statsmodels庫支持時間序列分析,包括ADF檢驗、ARIMA模型等功能,可用于時間序列數據的預測和建模。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:53 @FileName:5數據分析-statsmodels庫-時間序列分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import numpy as np import pandas as pd import statsmodels.api as sm# 構造時間序列數據 dates = pd.date_range('2020-01-01', periods=100) data = pd.DataFrame(np.random.randn(100, 2), index=dates, columns=['A', 'B'])# 進行時間序列分析 model = sm.tsa.ARIMA(data['A'], order=(1, 1, 1)) results = model.fit()# 打印模型預測結果 print(results.summary())
4.2.5.高級功能
-
多元線性回歸分析
Python statsmodels庫支持多元線性回歸分析,可以處理多個自變量和響應變量的回歸分析問題。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:55 @FileName:5數據分析-statsmodels-多元線性回歸分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import statsmodels.api as sm import numpy as np# 構造數據 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([2, 3, 4, 5])# 添加常數項 X = sm.add_constant(X)# 擬合多元線性回歸模型 model = sm.OLS(y, X) results = model.fit()# 打印回歸系數和模型評估指標 print(results.summary()) -
時間序列預測
Python statsmodels庫可以進行時間序列預測,通過歷史數據構建模型,并預測未來的數據趨勢。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:56 @FileName:5數據分析-statusmodels-時間序列預測.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import numpy as np import pandas as pd import statsmodels.api as sm# 構造時間序列數據 dates = pd.date_range('2020-01-01', periods=100) data = pd.DataFrame(np.random.randn(100, 2), index=dates, columns=['A', 'B'])# 進行時間序列預測 model = sm.tsa.ARIMA(data['A'], order=(1, 1, 1)) results = model.fit()# 預測未來數據 forecast = results.forecast(steps=10) print(forecast)
4.2.6.實際應用
Python statsmodels庫在實際應用中有著廣泛的用途,特別是在數據分析、金融建模、經濟學研究等領域,可以幫助分析師和研究人員進行數據探索、模型建立和預測分析。
-
數據探索和可視化
在數據分析過程中,經常需要對數據進行探索性分析和可視化,以便更好地理解數據的特征和關系。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:58 @FileName:5數據分析-statusmodels-數據探索和可視化.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import pandas as pd import statsmodels.api as sm import matplotlib.pyplot as plt# 導入數據 data = pd.read_csv(r'E:\07-code\time_series_study\data\electricity_test.csv')# 數據探索 print(data.head()) print(data.describe())# 繪制散點圖 plt.scatter(data['date'], data['OT']) plt.xlabel('X') plt.ylabel('Y') plt.title('Scatter Plot') plt.show() -
時間序列分析
在金融領域和經濟學研究中,時間序列分析是一項重要的工作,可以用來分析和預測時間序列數據的趨勢和周期性。
""" @Author: zhang_zhiyi @Date: 2024/7/4_12:01 @FileName:5數據分析-statusmodels-時間序列分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import pandas as pd import statsmodels.api as sm# 導入時間序列數據 data = pd.read_csv(r'E:\07-code\time_series_study\data\electricity_test.csv', parse_dates=['date'], index_col='date')# 進行時間序列分析 model = sm.tsa.ARIMA(data['OT'], order=(1, 1, 1)) results = model.fit()# 打印模型預測結果 print(results.summary())# 預測未來數據 forecast = results.forecast(steps=10) print(forecast) -
回歸分析
在經濟學研究和社會科學領域,回歸分析是常用的方法之一,可以用來研究變量之間的關系和影響因素。
""" @Author: zhang_zhiyi @Date: 2024/7/4_12:03 @FileName:5數據分析-statusmodels-回歸分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import pandas as pd import statsmodels.api as sm# 導入數據 data = pd.read_csv('regression_data.csv')# 進行線性回歸分析 X = data[['X1', 'X2']] y = data['Y'] X = sm.add_constant(X)model = sm.OLS(y, X) results = model.fit()# 打印回歸系數和模型評估指標 print(results.summary())
4.3.趨勢性分析
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_11:42
@FileName:6數據分析-趨勢性分析.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd
from matplotlib import pyplot as pltfrom statsmodels.tsa.seasonal import seasonal_decomposedata_name = 'zgpa_train'# 獲取數據
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)# 重置索引,創建一個新的整數索引
data = data.reset_index(drop=True)data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()data['volume'] = data['volume'].fillna(data['moving_avg'])data['z-score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()data.loc[data['z-score'].abs() > 1.5, 'volume'] = data['moving_avg']# 趨勢分析
"""
model : {"additive", "multiplicative"}, optionalType of seasonal component. Abbreviations are accepted.
"""
# 或者model='additive'取決于數據
# decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
trend = decomposition.trend
trend.plot()
plt.title('trend')
plt.tight_layout()
plt.savefig(fr'E:\07-code\time_series_study\data\{data_name}_trend.png')
plt.show()
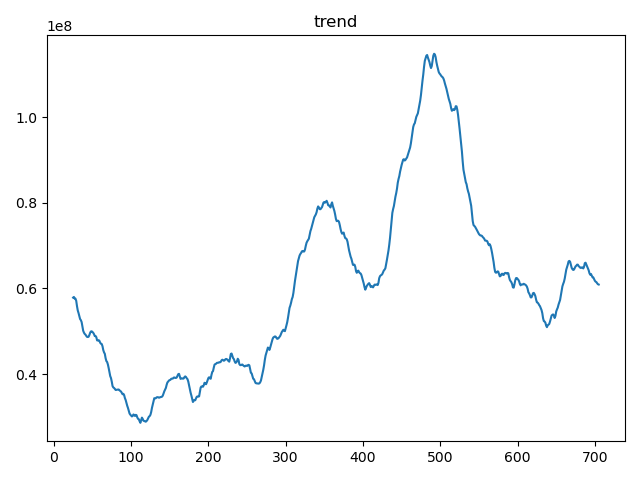
小結:
從這張趨勢圖上其中顯示數據存在波動,有局部上升趨勢,但整體相對穩定。我們看到數據點在某個水平線附近上下波動,這可能表示一個周期性的波動模式,而不是線性或單調的趨勢。
4.4.季節性分析
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_14:15
@FileName:7數據分析-季節性分析.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import osimport pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose# TODO:1.獲取數據
data_name = 'zgpa_train'
output_path = r'E:\07-code\time_series_study\data'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)# 重置索引,創建一個新的整數索引
data = data.reset_index(drop=True)# TODO:2.處理異常值
# 獲取移動平均值
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
# 處理Nan值
data['volume'] = data['volume'].fillna(data['moving_avg'])
# 根據Z-Score處理異常值
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']# TODO:3.季節性分析
# 季節性分析
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
seasonal = decomposition.seasonal
seasonal.plot()
plt.title('season')
plt.tight_layout()
plt.savefig(os.path.join(output_path, data_name) + '_season.png')
plt.show()
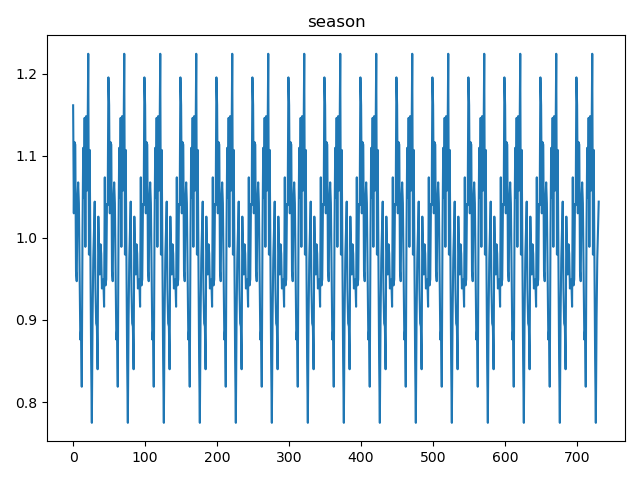
小結:
基于季節性分量圖像,我們可以使用橫坐標的數字來估計一個季節周期。通常,一個季節周期是指從一個峰值到下一個相同峰值的距離,或者從一個谷值到下一個相同谷值的距離。
通過觀察季節性分量圖像,我們可以估計:
- 從一個峰值到下一個峰值(或谷值到谷值)的距離看起來相對一致。
- 如果我們可以從圖像上精確讀取兩個相鄰峰值或谷值的橫坐標值,就可以通過它們的差來估算周期長度。
通過圖例可以看出季節周期大約為50個數據點**(這里設置的period=50,好像是有關系的?)**
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
4.5.周期性分析
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_15:18
@FileName:8數據分析-周期性分析.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import osimport pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose# TODO:1.獲取數據
data_name = 'zgpa_train'
output_path = r'E:\07-code\time_series_study\data'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)# 重置索引,創建一個新的整數索引
data = data.reset_index(drop=True)# TODO:2.處理異常值
# 獲取移動平均值
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
# 處理Nan值
data['volume'] = data['volume'].fillna(data['moving_avg'])
# 根據Z-Score處理異常值
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']# 確保數據沒有缺失值
# data['volume'] = data['volume'].fillna(method='ffill').fillna(method='bfill')# TODO:3.周期性分析
# 周期性分析(殘差)
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
residual = decomposition.resid
residual.plot()
plt.title('Periodicity (residual)')
plt.tight_layout()
plt.savefig(os.path.join(output_path, data_name + '_residual.png'))
plt.show()
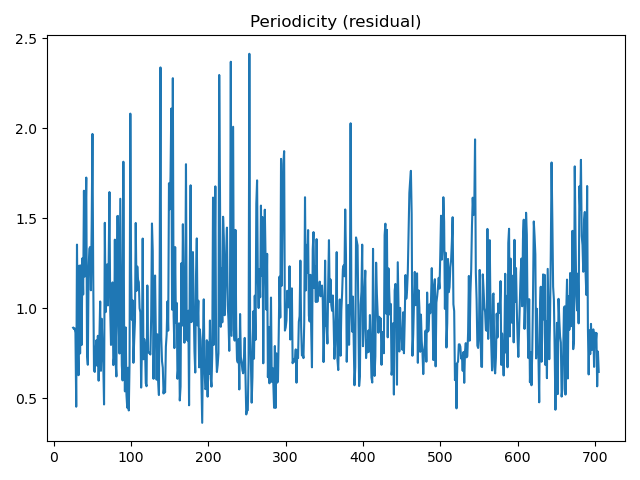
小結:
周期性殘差的波動表明除了季節性之外,可能還存在其他非固定周期的影響因素,這些可能是因為其他因素引起的所以我們最好可以增加一些其它變量。
4.6.整合圖
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_17:25
@FileName:9數據分析-整合圖例.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import os
import pandas as pdfrom matplotlib import pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose# TODO:1.獲取數據
output_path = r'E:\07-code\time_series_study\data'
data_name = 'zgpa_train'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv', index_col=['date'], parse_dates=['date'])
data = data.reset_index(drop=True)
# TODO:2.去除異常數據
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
data['volume'] = data['volume'].fillna(data['moving_avg'])
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']
# TODO:3.數據分析
result = seasonal_decompose(data['volume'], model='multiplicative', period=50)result.plot()
plt.title(f"{data_name} Data Analysis Result")
plt.tight_layout()
plt.savefig(os.path.join(output_path, data_name) + "_seasonal_decompose.png")
plt.show()

4.7. ACF和PACF
ACF和PACF的概念理解見7.ARIMA模型分析流程
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_17:50
@FileName:10ACF和PACF.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description: 自相關和偏自相關圖
"""
import os
import pandas as pd
from matplotlib import pyplot as plt
import statsmodels.api as sm# TODO:1.獲取數據
output_path = r'E:\07-code\time_series_study\data'
data_name = 'zgpa_train'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv', index_col=['date'], parse_dates=['date'])
data = data.reset_index(drop=True)# TODO:2.去除異常數據
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
data['volume'] = data['volume'].fillna(data['moving_avg'])
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']# TODO:3.自相關和偏自相關
# 自相關和偏自相關圖
fig, ax = plt.subplots(2, 1, figsize=(12,8))
sm.graphics.tsa.plot_acf(data['volume'].dropna(), lags=40, ax=ax[0])
sm.graphics.tsa.plot_pacf(data['volume'].dropna(), lags=40, ax=ax[1])plt.tight_layout()
plt.savefig(os.path.join(output_path, data_name) + '_ACK_PACK')
plt.show()
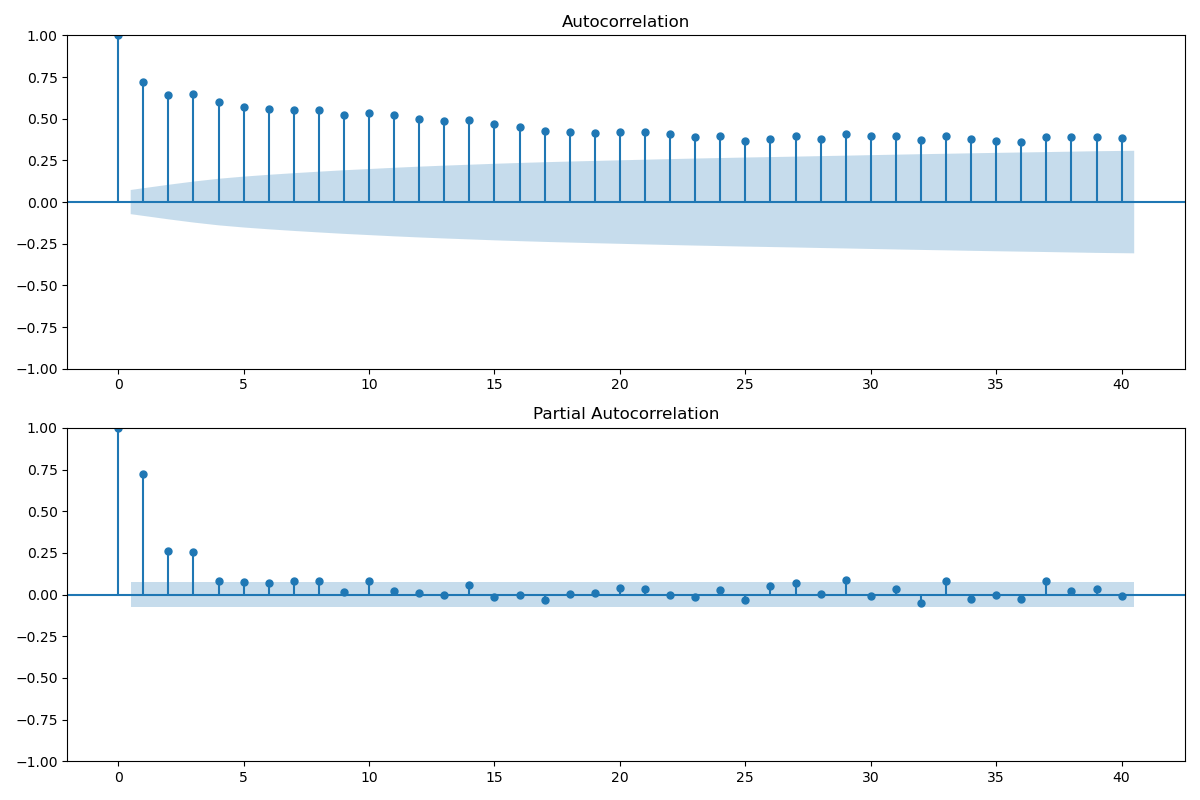
ACK:
PACK:
- PACF 圖在第一個滯后處顯示了一個顯著的尖峰,之后迅速下降至不顯著,這是典型的AR(1)過程的特征,意味著一個數據點主要受到它前一個數據點的影響。
- 在第一滯后之后,大多數滯后的PACF值都不顯著(即在藍色置信區間內),這表明一個階的自回歸模型可能足以捕捉時間序列的相關結構。
4.8.平穩性檢驗
Augmented Dickey-Fuller (ADF) 測試的結果提供了是否拒絕時間序列具有單位根的依據,即時間序列是否是非平穩的。ADF測試的兩個關鍵輸出是:
- ADF 統計量:這是一個負數,它越小,越有可能拒絕單位根的存在。
- p-值:如果p-值低于給定的顯著性水平(通常為0.05或0.01),則拒絕單位根的假設,表明時間序列是平穩的。
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_17:59
@FileName:11平穩性檢測.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd
from statsmodels.tsa.stattools import adfuller# TODO:1.獲取數據
output_path = r'E:\07-code\time_series_study\data'
data_name = 'zgpa_train'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv', index_col=['date'], parse_dates=['date'])
data = data.reset_index(drop=True)# TODO:2.去除異常數據
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
data['volume'] = data['volume'].fillna(data['moving_avg'])
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']# TODO:3.平穩性檢測
# 平穩性檢測
adf_test = adfuller(data['volume'])
print('ADF 統計量: ', adf_test[0])
print('p-值: ', adf_test[1])
小結:
如上圖所示:
? ADF統計量為:-3.1400413587267337
? p-值為:0.023728394879258534
由于p-值介于0.01和0.05之間,說明我們不足以拒絕單位根的存在,所以數據可能是非平穩的,這意味著時間序列數據中可能存在隨時間變化的趨勢或者季節性成分,需要通過適當變換(如差分)去除
備注:
平穩的時序數據適合使用ARIMA或類似的自回歸模型來進行建模和預測。
(PS:electricity數據集是平穩的,但是數據量有些大)
5.模型訓練
以ARIMA模型為例
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_18:12
@FileName:12模型訓練.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description: 以ARIMA模型為例
"""
from math import sqrt
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from pmdarima import auto_arima
from sklearn.metrics import mean_squared_error
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.stattools import adfullerdata = pd.read_csv(r"E:\07-code\time_series_study\data\zgpa_train.csv", index_col=['date'], parse_dates=['date'])data = data.reset_index(drop=True)data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
data['volume'] = data['volume'].fillna(data['moving_avg'])# 計算 Z-Score
data['z_score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.reset_index(drop=True, inplace=True)
# 將異常值替換為移動平均值
data.loc[data['z_score'].abs() > 1.5, 'volume'] = data['moving_avg']# 可視化原始數據
data.plot()
plt.title('original data')
plt.tight_layout()
plt.show()# 趨勢分析
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50) # 或者model='multiplicative'取決于數據
trend = decomposition.trend
trend.plot()
plt.title('trend')
plt.tight_layout()
plt.show()# 季節性分析
seasonal = decomposition.seasonal
seasonal.plot()
plt.title('season')
plt.tight_layout()
plt.show()# 周期性分析(殘差)
residual = decomposition.resid
residual.plot()
plt.title('Periodicity (residual)')
plt.tight_layout()
plt.show()# 自相關和偏自相關圖
fig, ax = plt.subplots(2, 1, figsize=(12, 8))
sm.graphics.tsa.plot_acf(data['volume'].dropna(), lags=40, ax=ax[0])
sm.graphics.tsa.plot_pacf(data['volume'].dropna(), lags=40, ax=ax[1])
plt.show()# 平穩性檢測
adf_test = adfuller(data['volume'])
print('ADF 統計量: ', adf_test[0])
print('p-值: ', adf_test[1])# 劃分數據集
train_ds = data['volume'][:int(0.9 * len(data))]
test_ds = data['volume'][-int(0.1 * len(data)):]# 將從上面分析過來的結果輸入的auto_arima里面進行模型的擬合
model = auto_arima(train_ds, trace=True, error_action='ignore', suppress_warnings=True, seasonal=True, m=50,stationary=False, D=2)model.fit(train_ds)
forcast = model.predict(n_periods=len(test_ds))
# forcast = pd.DataFrame(forcast, index=test_ds.index, columns=['Prediction'])rms = sqrt(mean_squared_error(test_ds, forcast))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15, 7))
# plt.figure('Forecast')
plt.title("forecast value as real")
plt.plot(range(len(train_ds)), train_ds, label='Train')
plt.plot(range(len(train_ds), len(train_ds) + len(test_ds)), test_ds.values, label='Test')
plt.plot(range(len(train_ds), len(train_ds) + len(test_ds)), forcast.values, label='Prediction')
plt.legend()
plt.tight_layout()
plt.show()
6.Python庫 – pdmarima
pmdarima 是一個 Python 庫,全名是 “Python AutoRegressive Integrated Moving Average (ARIMA)(自回歸整合滑動平均)” 模型的封裝庫。它構建在 statsmodels 和 scikit-learn 的基礎上,并提供了一種簡單而強大的方式來選擇和擬合時間序列模型。
6.1.主要功能
- 自動模型選擇:pmdarima 可以自動選擇合適的 ARIMA 模型,無需手動調整超參數。這減少了時間序列建模的繁瑣性。
- 模型擬合:一旦選擇了模型,pmdarima 可以對時間序列數據進行擬合,并提供有關擬合質量的信息。
- 季節性分解:pmdarima 允許對具有季節性成分的時間序列進行分解,以更好地理解數據。
- 交叉驗證:您可以使用交叉驗證來評估模型的性能,以確保模型對未來數據的泛化效果。
- 可視化工具:pmdarima 提供了可視化工具,幫助您直觀地了解模型的性能和預測結果。
6.2.基本用法
"""
@Author: zhang_zhiyi
@Date: 2024/7/5_9:25
@FileName:13pmdarima庫-基礎用法.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import numpy as np
from pmdarima import auto_arima
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 設置默認字體為SimHei
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題# TODO:1.pmdarima的基本用法
# 生成一個時序數據
np.random.seed(0)
data = np.random.randn(100) # 100個數據點的時間序列# print("原始數據:")
# print(data)# 使用auto_arima選擇ARIMA模型, pmdarima 自動選擇了適合數據的 ARIMA 模型,并返回了擬合的模型對象。
model = auto_arima(data, seasonal=True, m=12) # 帶季節性的 ARIMA 模型,季節周期為12# 預測未來12個時間點的值
"""
def predict(self,n_periods=10,X=None,return_conf_int=False,alpha=0.05,
)
Parameters:n_periods : int, optional (default=10) The number of periods in the future to forecast.X : array-like, shape=[n_obs, n_vars], optional (default=None) An optional 2-d array of exogenous variables. return_conf_int : bool, optional (default=False) Whether to get the confidence intervals of the forecasts.alpha : float, optional (default=0.05) The confidence intervals for the forecasts are (1 - alpha) %
Return:forecasts : array-like, shape=(n_periods,) The array of fore-casted values.conf_int : array-like, shape=(n_periods, 2), optional The confidence intervals for the forecasts. Only returned if return_conf_int is True.
"""
# forecast 變量包含了未來時間點的預測值,而 conf_int 變量包含了置信區間。
forecast, conf_int = model.predict(n_periods=12, return_conf_int=True)
print('conf_int:', conf_int)
print('conf_int[:, 0]:', conf_int[:, 0])
print('conf_int[:, 1]:', conf_int[:, 1])
# print("預測數據:")
# print(forcast)
# print(conf_int)# 可視化預測結果
plt.plot(data, label='觀測數據')
plt.plot(range(len(data), len(data) + len(forecast)), forecast, label='預測值', color='red')
"""matplotlib.pyplot.fill_between Fill the area between two horizontal curves.
"""
plt.fill_between(range(len(data), len(data) + len(forecast)), conf_int[:, 0], conf_int[:, 1], color='pink', alpha=0.5, label='置信區間')
plt.legend()
plt.xlabel('時間步')
plt.ylabel('值')
plt.title('時間序列預測')
plt.tight_layout()
plt.show()
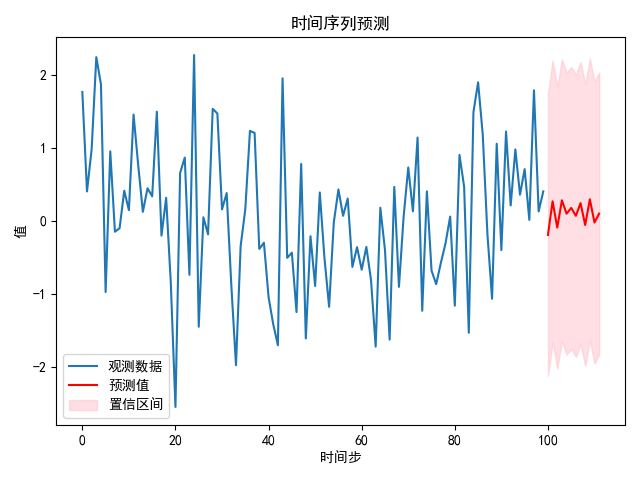 6.3.高級用法
6.3.高級用法
"""
@Author: zhang_zhiyi
@Date: 2024/7/5_10:23
@FileName:14pmdarima庫-高級用法.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import numpy as np
from pmdarima import ARIMA
from pmdarima.model_selection import cross_val_score# TODO:2.高級用法
# 生成一個時序數據
np.random.seed(0)
data = np.random.randn(100) # 100個數據點的時間序列# 雖然 pmdarima 提供了自動模型選擇的功能,但也可以手動指定模型的超參數,以更精細地控制建模過程。
# 手動指定ARIMA模型
"""
Parameters:order : iterable or array-like, shape=(3,)The (p,d,q) order of the model for the number of AR parameters, differences, and MA parameters to use.order : iterable or array-like, shape=(3,)The (P,D,Q,s) order of the seasonal component of the model for the AR parameters, differences, MA parameters, and periodicity. seasonal_order : array-like, shape=(4,), optional (default=(0, 0, 0, 0))The (P,D,Q,s) order of the seasonal component of the model for the AR parameters, differences, MA parameters, and periodicity.
"""
model = ARIMA(order=(1, 1, 1), seasonal_order=(0, 1, 1, 12))
"""
fit(y, X=None, **fit_args)Fit an ARIMA to a vector, y, of observations with an optional matrix of X variables.
"""
model.fit(data)# 交叉驗證是評估模型性能的重要方法。pmdarima 可以執行交叉驗證來評估模型的泛化性能。
# 執行交叉驗證
# scores = cross_val_score(model, data, cv=5) # 使用5折交叉驗證
"""scoring : str or callable, optional (default=None)The scoring metric to use. If a callable, must adhere to the signature``metric(true, predicted)``. Valid string scoring metrics include:- 'smape'- 'mean_absolute_error'- 'mean_squared_error'
"""
scores = cross_val_score(model, data, scoring='smape')
"""
觀察值太少:用于估計季節性ARMA模型的起始參數的觀察值太少,除了方差以外的所有參數都將設置為零。
UserWarning: Too few observations to estimate starting parameters for seasonal ARMA.
All parameters except for variances will be set to zeros.warn('Too few observations to estimate starting parameters%s.'非可逆的起始季節性移動平均參數:使用零作為起始參數。
UserWarning: Non-invertible starting seasonal moving average Using zeros as starting parameters.warn('Non-invertible starting seasonal moving average'最大似然優化未收斂:最大似然優化未能收斂,可能是由于數據不足或模型參數不合適。
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals warnings.warn("Maximum Likelihood optimization failed to "解決方案增加數據量:嘗試使用更多的數據點進行模型訓練。調整模型參數:檢查并調整模型的參數,以提高擬合的穩定性。檢查數據的季節性:確保數據具有足夠明顯的季節性特征,并且季節周期設置正確。
"""
print(scores)
# from pmdarima import seasonal_decompose
# 季節性分解
# result = seasonal_decompose(data, model='multiplicative', freq=12)
7.ARIMA模型分析流程
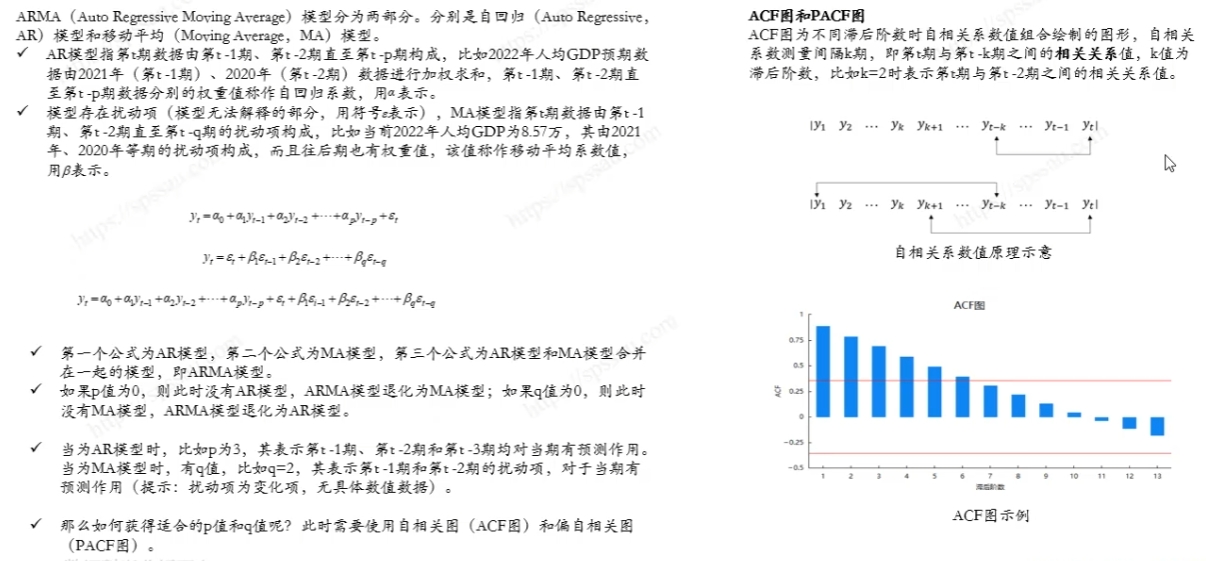
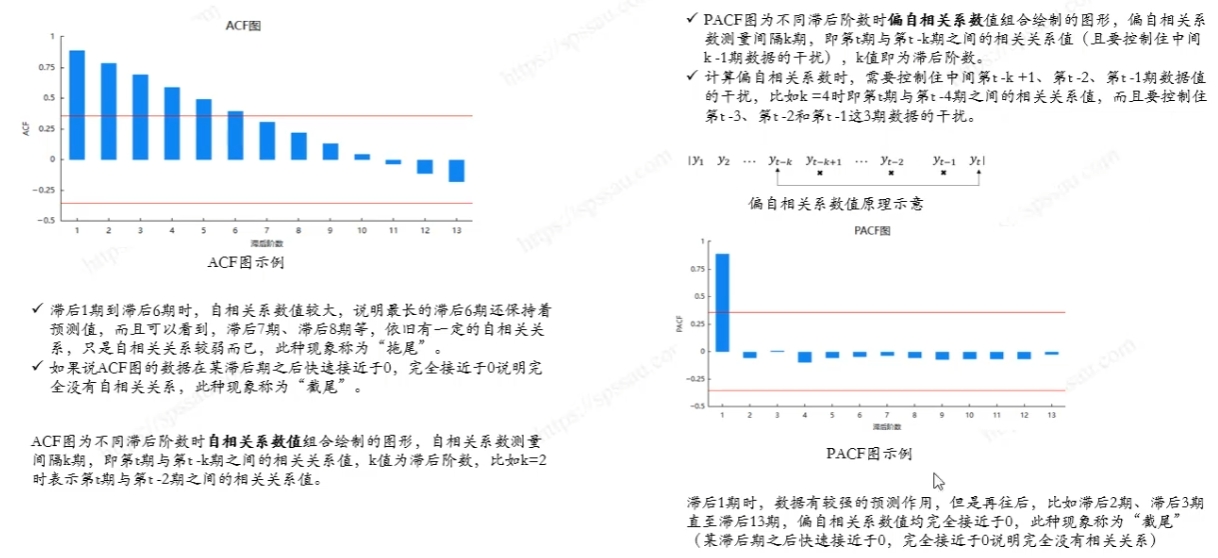
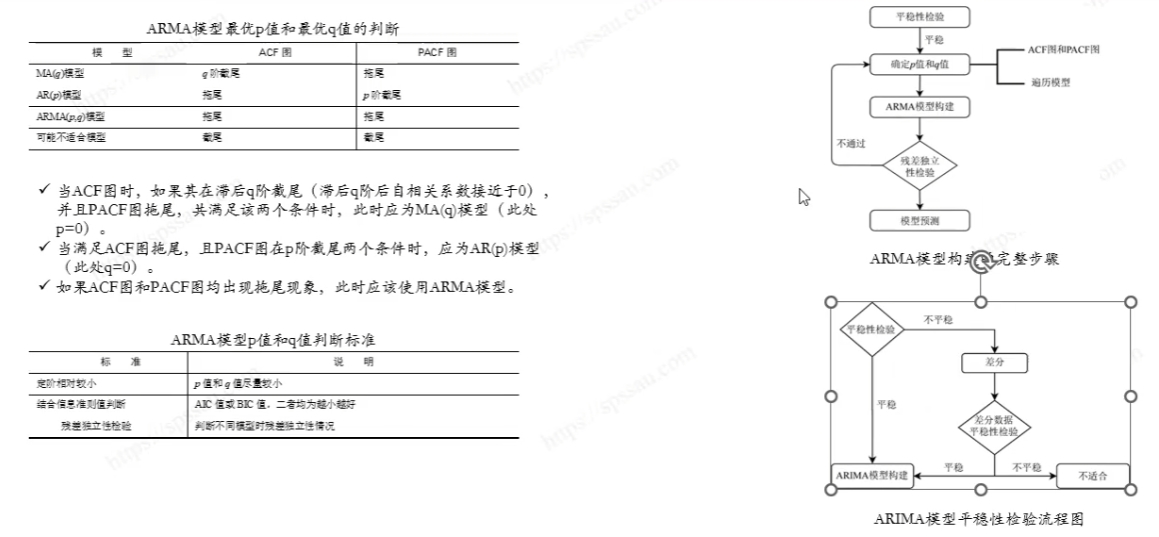







)
)





)




