問題描述:分析下列代碼,分別能產生多少a?
// 1
for(int i=0; i<3; i++){
printf("a\n");
fork();
}// 2
for(int i=0; i<3; i++){
fork();
printf("a\n");
}// 3
for(int i=0; i<3; i++){
fork();
printf("a");
}
fflush(stdout);// 4
for(int i=0; i<3; i++){
printf("a");
fork();
}分析:
【問題1】第0次循環:此時只有p0主進程,直接輸出a,然后執行fork();產生一個子進程p1;現在有一個a
? ? ? ? 第1次循環:此時有兩個進程p0,p1;都輸出一個a ,共兩個a;然后執行fork();分別產生p2,p3,兩個子進程;目前終端輸出三個a,有四個進程p0,p1,p2,p3;
? ? ? ? 第2次循環:此時四個進程各輸出一個 a ;隨后產生四個進程,程序結束;終端上一共有1+2+4 = 7 個a。
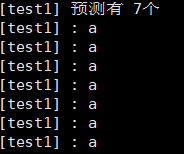
【問題2】第0次循環:此時只有p0主進程,執行fork(),生成子進程p1,兩個進程各自在終端輸出一個a,此時終端共兩個a;
? ? ? ? 第1次循環:此時有p0,p1進程,執行fork(),生成子進程p2,p3,共四個進程,各自輸出一個a,此時終端共有 2+4 = 6 個a;
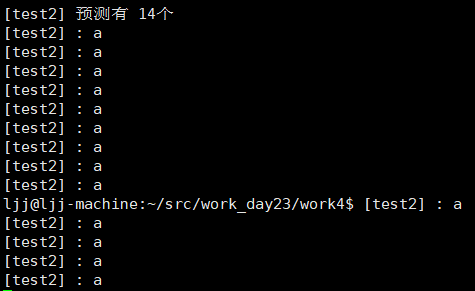
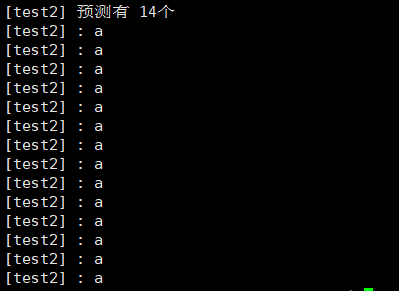
? ? ? ? 第2次循環:此時有p0,p1,p2,p3進程,執行fork(),生成四個子進程,共八個子進程,各自在終端輸出8個子進程,此時共有 2+ 4+8 = 14個a;
? ? ? ? 但是在終端上出現如下情況,原因為各進程間結束時間不一致,當主進程結束時,部分子進程還未結束,會繼續向終端輸出a;
?此時只要在for循環后加sleep();等待進程全結束即可得到規整的輸出:
void test2(){12 printf("[test2] 預測有 14個\n");13 for(int i=0;i<3;i++){14 fork();15 printf("[test2] : a\n");16 }17 18 sleep(1); 19 }
?【問題3】(注:本題以及問題4涉及緩存相關知識)
? ? ? ? 第0次循環:主進程p0執行fork()后產生子進程p1,隨后執行滿緩存輸出,此時將a輸出當進程p0、p1的緩沖區中,并不直接輸出到終端(后兩次循環也是一樣);
? ? ? ? 第1次循環:p0,p1執行fork()后產生p2,p3子進程,隨后執行printf(),將a輸出到各進程的緩沖區中,此時p0,p1,p2,p3中的緩沖區都存在兩個但還未輸出;
? ? ? ? 第2次循環:同理第1次循環,會產生四個子進程,共八個進程,隨后的printf()在各自的進程緩存空間中輸出a,當進程結束時,標準輸出會刷新緩存,將每個進程中的三個a輸出到終端;程序結束后,終端上會顯示 3*8 = 24個 a;
?若出現輸出在命令行之后的情況,原因同問題2,各個進程結束時間不一致導致,使用sleep()就可以解決。

【4】
? ? ? ? 第0次循環:主進程p0執行printf()后并未直接輸出,而是將a輸出到p0的緩存中。隨后執行fork(),產生的子進程p1會復制p0的用戶態地址空間;這里有個小知識點fork()采用寫時復制,在隨后對共享頁中i++時候才真正復制p0的棧堆數據等,此時才將p0中的緩存復制一份,這是區別與問題3的;問題3是在各自緩存中加了一個a,問題4是在父進程緩存中先加了一個a,隨后復制到各子進程(后兩次不作過多贅述,fork()寫時復制策略放在最后);此時p0,p1緩存中各有一個a;
? ? ? ? 第1次循環:p0,p1執行printf(),將a輸出到各進程的緩沖區中,緩存中各自有兩個a,執行fork(),產生p2,p3,此時p0,p1,p2,p3中的緩沖區都存在兩個a但還未輸出;
? ? ? ? 第2次循環:同理上次循環,會產生四個子進程,共八個進程,并且在fork()前的printf()在各自的進程緩存空間中輸出a,各個進程緩存中存在3個a,當進程結束時,標準輸出會刷新緩存,將每個進程中的三個a輸出到終端;程序結束后,終端上會顯示 3*8 = 24個 a;
?

寫時復制
為了減少數據復制的開銷, 優化內存管理, fork采用是寫時復制(Copy-On-Write,簡稱COW)的策略。
- 在fork()執行時,操作系統并不立即復制父進程的整個內存空間給子進程。操作系統使父進程和子進程暫時共享相同的物理內存頁。
- 這些共享的頁面在內存中被標記為只讀。如果父進程或子進程嘗試寫入這些共享的頁面(以頁為單位),操作系統會為發起寫操作的進程(父進程或子進程)分配一個新的物理內存頁, 并復制數據到這個頁。
寫時復制機制確保只有在必要時才復制數據頁,這極大地減少了內存使用和提高了效率。
?
)

)

 電機驅動的本質分析以及與磁相關的使用場景)


深度學習---神經網絡原理與實現)
![[Java實戰]Spring Boot 整合 Swagger2 (十六)](http://pic.xiahunao.cn/[Java實戰]Spring Boot 整合 Swagger2 (十六))



)
:探秘滑塊的計算邏輯)



)

