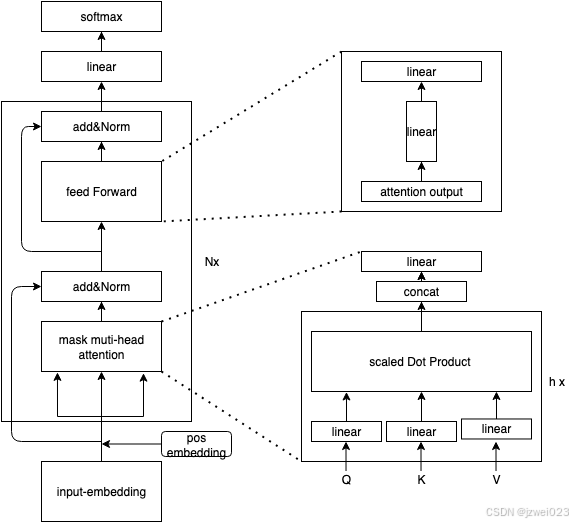
Transformer 的?Decoder-Only?架構(如 GPT 系列模型)是當前大語言模型的主流架構,其參數量主要由以下幾個部分組成:
- 嵌入層(Embedding Layer)
- 自注意力層(Self-Attention Layers)
- 前饋網絡(Feed-Forward Network, FFN)
- Layer Normalization 和偏置項
| Operation | Parameters |
| Embedding | ( n_vacab +?n_ntx )?× d_model? |
| Attention:QKV | 3 × n_layer?× d_model × d_attn |
| Attention:Project | n_layer?× d_model × d_attn |
| Feedforward | 2? ×?n_layer × d_model × d_ff |
| Layer Normalization 和偏置項 | 4 ×?n_layer × d_model |
| Total(Attention + Feedforward) | 2? ×?n_layer × d_model × ( 2 ×?d_attn +?d_ff ) ≈? 12? ×?n_layer? × d_model^2? 假設d_attn =?d_model,d_ff = 4?× d_model |
參數定義:
d_mdole:模型維度;
n_layer:層數;
d_attn:注意力輸出維度;
d_ff:前饋網絡維度;
n_ntx:最大上下文長度(token)
n_head:注意力頭數
n_vacab:詞匯表大小
1.?嵌入層(Embedding Layer)
嵌入層的作用是將輸入 token 轉換為高維向量表示。參數量為:n_vacab?× d_model
此外,絕對位置編碼通常由可學習的嵌入矩陣實現,其權重維度為: n_ntx × d_model
此外,在語言模型中,輸出層通常與嵌入層共享權重矩陣(Tie Embedding),因此不需要額外計算輸出層的參數量。
所以嵌入層總參數數:( n_vacab +?n_ntx )?× d_model?
備注:假設輸入 x_i =? (w_1, w_2,..., w_n_ntx),長度為n_ntx,batch 大小為b,則原始輸入維度為:(b,n_ntx),經過embedding后輸出維度為(b, n_ntx, d_model)
2.?自注意力層(Self-Attention Layers)
每個 Transformer 層包含一個多頭自注意力機制(Multi-Head Self-Attention, MHSA),其參數量主要來自以下三部分:
- 線性變換矩陣:生成 Query、Key、Value
- 輸出投影矩陣:將多頭結果拼接后進行線性變換
假設:
- 輸入的維度為?
d_model - 注意力頭數為?
h - 每個頭的維度為?
d_k(通常滿足?d_k = d_attn / h) - QKV輸出維度d_attn,然后經過投影,輸出維度 d_model
(1)?生成 Query、Key、Value 的線性變換矩陣
每個頭的?Q、K、V?都需要一個獨立的線性變換矩陣,因此總的參數量為:
Attention QKV?Parameters = 3 × d_model × d_attn
(2)?輸出投影矩陣
多頭注意力的結果需要通過一個線性投影矩陣轉換回?d_model?維度,因此參數量為:
Attention Project?Parameters =? d_attn × d_model?
(3)?總自注意力層參數量
單個自注意力層的參數量為:
Self-Attention?Parameters = 3 × d_model × d_attn?+ d_attn?× d_model = 4?× d_model × d_attn
如果有?n_layer?個 Transformer 層,則總的自注意力層參數量為:
Total?Self-Attention?Parameters =?4?× n_layer?× d_model × d_attn
備注:嵌入層輸出的 x維度是(b, n_ntx, d_model),W_Q維度是(d_model, d_attn),則Q = x * W_Q維度是(b, n_ntx, d_attn),通過self-attention后,輸出維度為(b, n_ntx, d_attn),然后通過attention project后維度是(b, n_ntx, d_model)
3.?前饋網絡(Feed-Forward Network, FFN)
每個 Transformer 層包含一個兩層的前饋網絡(FFN),其參數量主要來自以下兩部分:
- 第一層從?
d_model?映射到?d_ff(通常是?d_model?的 4 倍)。 - 第二層從?
d_ff?映射回?d_model。
(1)?第一層參數量
第一層將?d_model?映射到?d_ff,因此參數量為:
First?Layer?Parameters=d_model × d_ff
(2)?第二層參數量
第二層將?d_ff?映射回?d_model,因此參數量為:
Second?Layer?Parameters=d_ff × d_model
(3)?總前饋網絡參數量
單個前饋網絡的參數量為:
FFN?Parameters=d_model ×d_ff + d_ff × d_model = 2 × d_model × d_ff
如果有?n_layer?個 Transformer 層,則總的前饋網絡參數量為:
Total?FFN?Parameters = 2? × n_layer?× d_model × d_ff
備注:(b, n_ntx, d_model)經過FFN后輸出維度是(b, n_ntx, d_model)
4.?Layer Normalization 和偏置項
每個 Transformer 層包含兩個 Layer Normalization 操作(分別在自注意力和前饋網絡之后),每個 Layer Normalization 包含兩個可學習參數(縮放因子和偏移因子)。
總的 Layer Normalization 參數量為:
LayerNorm?Parameters = n_layer?× 2 × 2 × d_model = 4 × n_layer?× d_model
5. 總參數量
Total?Parameters =?( n_vacab +?n_ntx )?× d_model? ?+?4?× n_layer?× d_model × d_attn ?+?2? × n_layer?× d_model × d_ff +?4 × n_layer?× d_model?
Total?Parameters?≈??4?× n_layer?× d_model × d_attn ?+?2? × n_layer?× d_model × d_ff =?2? ×?n_layer × d_model × ( 2 ×?d_attn +?d_ff )
假設d_attn =?d_model, 以及d_ff = 4?× d_model,則
Total?Parameters ≈? 12? ×?n_layer? × d_model^2
6.?實際例子
以 GPT-3 為例:
- 詞匯表大小?n_vacab = 50257?
- 模型維度?d_model = 12288
- 前饋網絡維度?d_ff=4 × d_model = 49152
- 層數?n_layer = 96?
- 最大上下文長度 (token)n_ntx = 2048
代入公式:
Total?Parameters = (50257 +?2048) ×12288 + 96×(4×122882+8×122882) + 4×96×12288
計算結果約為 175B 參數,與 GPT-3 的實際參數量一致。
Java學習-5.8(總結,springboot))
))

:雙邊市場模式的挑戰、策略與創業階段關聯)









:Clocking Wizard 動態配置)

操作的一個函數 flip())



