《WiseAD: Knowledge Augmented End-to-End Autonomous Driving with Vision-Language Model》2024年12月發表,來自新加坡國立和浙大的論文。

在快速發展的視覺語言模型(VLM)中,一般人類知識和令人印象深刻的邏輯推理能力的出現,促使人們越來越有興趣將VLM應用于高級自動駕駛任務,如場景理解和決策。然而,對知識水平(尤其是基本駕駛專業知識)與閉環自動駕駛性能之間關系的深入研究需要進一步探索。在這篇論文中,我們研究了基礎駕駛知識的深度和廣度對閉環軌跡規劃的影響,并介紹了WiseAD,這是一種專為端到端自動駕駛量身定制的專用VLM,能夠進行駕駛推理、動作論證、對象識別、風險分析、駕駛建議和跨不同場景的軌跡規劃。我們對駕駛知識和規劃數據集進行聯合訓練,使模型能夠相應地執行知識對齊的軌跡規劃。大量實驗表明,隨著駕駛知識多樣性的擴大,嚴重事故顯著減少,在卡拉閉環評估中,駕駛分數和路線完成率分別提高了11.9%和12.4%,達到了最先進的性能。此外,WiseAD在域內和域外數據集的知識評估方面也表現出了顯著的性能。
研究背景與動機
自動駕駛技術近年來從傳統規則系統轉向端到端解決方案,但仍面臨場景理解不足和駕駛知識利用不充分的問題。視覺語言模型(VLM)在通用知識和邏輯推理方面表現出色,但直接應用于自動駕駛時存在兩大挑戰:
-
駕駛導向知識不足:通用VLM缺乏對駕駛場景、經驗和因果推理的深度理解。
-
知識與軌跡規劃未對齊:現有方法多模仿預定義駕駛行為,缺乏對知識(如“減速以規避行人突然出現”)的顯式嵌入,導致決策透明度低。
核心貢獻
提出?WiseAD,一種專為自動駕駛設計的知識增強VLM,具備以下能力:
-
多任務支持:場景描述、物體識別、風險分析、駕駛建議、軌跡規劃等。
-
聯合訓練策略:結合駕駛知識(LingoQA、DRAMA等)與軌跡規劃(Carla數據集)進行聯合學習,避免知識遺忘。
-
性能提升:在Carla閉環評估中,駕駛分數(DS)提升11.9%,路線完成率(RC)提升12.4%,關鍵事故(碰撞、闖紅燈)顯著減少。
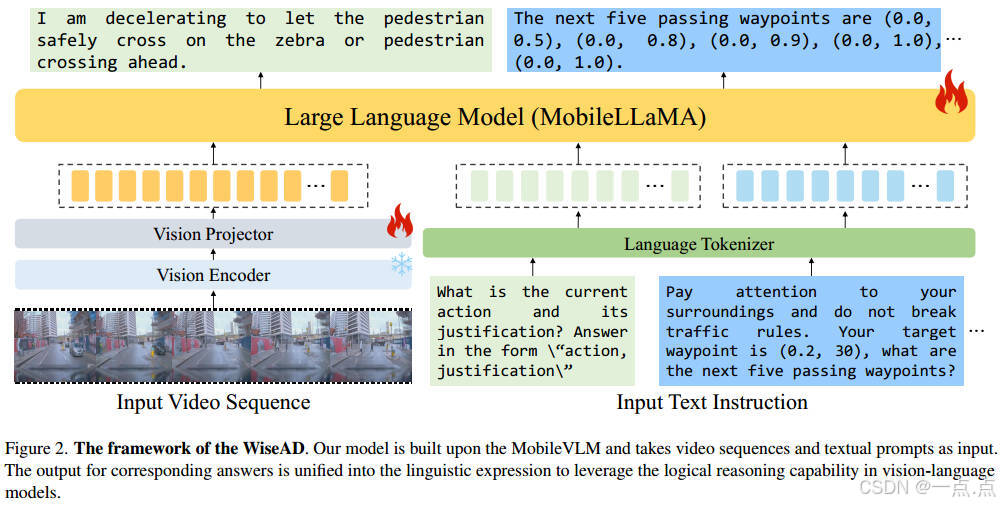
方法細節
-
模型架構:
-
視覺編碼:基于CLIP ViT-L/14提取視頻幀特征,投影為與文本對齊的視覺標記。
-
語言模型:采用輕量級MobileLLaMA(1.7B參數),支持多模態輸入(視頻+文本)。
-
輸出對齊:軌跡規劃結果以文本形式表達(如“下一個五個路徑點為(x1, y1), (x2, y2)…”),便于利用VLM的邏輯推理能力。
-
-
數據構建:
-
駕駛知識:整合LingoQA(駕駛推理、物體識別)、DRAMA(風險分析、駕駛建議)、BDDX(動作解釋)等數據集,覆蓋多樣化場景與任務。
-
軌跡規劃:使用Carla模擬器采集軌跡數據,目標點以文本形式輸入(如“目標點為(x, y),生成后續五個路徑點”)。
-
-
訓練策略:
-
聯合學習:混合知識問答與軌跡規劃數據,避免分階段訓練導致的知識遺忘。
-
注意力前綴提示:在推理階段加入提示(如“注意周圍環境,遵守交規”),顯式引導模型調用駕駛知識。
-
實驗結果
-
閉環駕駛性能(Carla評估):
-
SOTA對比:WiseAD在駕駛分數(69.88 vs 65.26)和路線完成率(93.79% vs 88.24%)上超越Roach、VAD等模型。
-
關鍵事故減少:碰撞次數從2.35降至1.43,闖紅燈次數從2.60降至2.14。
-
-
知識評估(零樣本測試):
-
LingoQA:L-Judge評分60.4(對比LLaVA-7B的38.0),顯示對駕駛知識的深度掌握。
-
跨數據集泛化:在BDDX(動作識別)、DriveLM(物體識別)、HAD(駕駛注意力)任務中均表現優異。
-
-
消融實驗:
-
注意力前綴提示:移除后路線完成率下降8.4%(93.79→85.35),驗證其關鍵作用。
-
知識廣度影響:引入DRAMA風險分析數據后,駕駛分數提升3.08(66.02→69.88)。
-
創新點與意義
-
知識驅動的端到端框架:首次將VLM與駕駛知識深度融合,提升決策可解釋性與安全性。
-
輕量化與高效性:基于MobileVLM(1.7B參數),適合實時自動駕駛場景。
-
數據與訓練范式創新:通過混合訓練與注意力提示,實現知識與規劃的高效對齊。
未來方向
-
擴展知識邊界:引入更多長尾場景(如極端天氣、復雜路口)的知識標注。
-
多模態融合:結合激光雷達等多傳感器數據,增強環境感知魯棒性。
-
實際部署驗證:在真實道路測試中驗證模型泛化能力與實時性。
WiseAD為自動駕駛領域提供了一種知識增強的新范式,通過顯式嵌入駕駛邏輯與經驗,推動端到端系統向“類人類駕駛”邁進。
如果此文章對您有所幫助,那就請點個贊吧,收藏+關注 那就更棒啦,十分感謝!!!?


)
)












)


