《Large Language Model guided Deep Reinforcement Learning for Decision Making in Autonomous Driving》2024年12月發表,來自北理工的論文。
????????深度強化學習(DRL)在自動駕駛決策方面顯示出巨大的潛力。然而,由于DRL的學習效率低,它需要大量的計算資源來在復雜的駕駛場景中實現合格的策略。此外,利用人類的專家指導來提高日間行車燈的性能會導致過高的勞動力成本,這限制了其實際應用。在這項研究中,我們提出了一種新的大型語言模型(LLM)引導的深度強化學習(LGDRL)框架,用于解決自動駕駛汽車的決策問題。在此框架內,一位基于LLM的駕駛專家被整合到DRL中,為DRL的學習過程提供智能指導。隨后,為了有效地利用LLM專家的指導來提高DRL決策政策的性能,通過創新的專家政策約束算法和新穎的LLM干預交互機制來增強DRL的學習和交互過程。實驗結果表明,與最先進的基線算法相比,我們的方法不僅實現了90%任務成功率的卓越駕駛性能,而且顯著提高了學習效率和專家指導利用效率。此外,所提出的方法使DRL代理能夠在沒有LLM專家指導的情況下保持一致和可靠的性能。
研究背景與問題
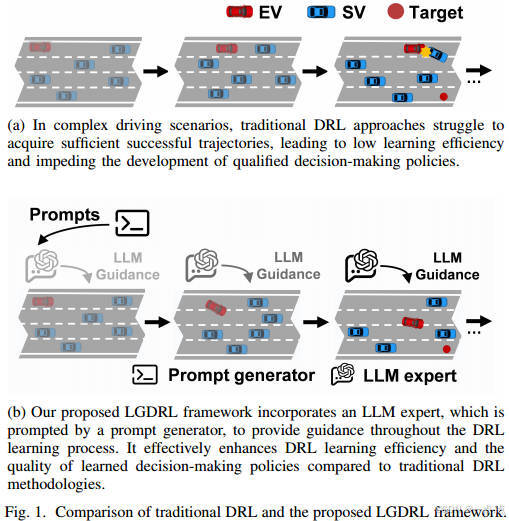
自動駕駛決策系統需在復雜動態交通場景中生成安全、合理的駕駛行為。傳統基于規則的方法適應性不足,而深度強化學習(DRL)雖在決策任務中表現優異,但存在學習效率低和依賴人類專家指導成本高的問題。
-
DRL的局限性:需通過大量環境交互優化策略,在復雜場景中難以積累有效軌跡,導致策略優化緩慢。
-
現有專家指導的不足:依賴人類專家實時干預或演示數據,成本高昂且效率低下。
 ?
?
核心貢獻
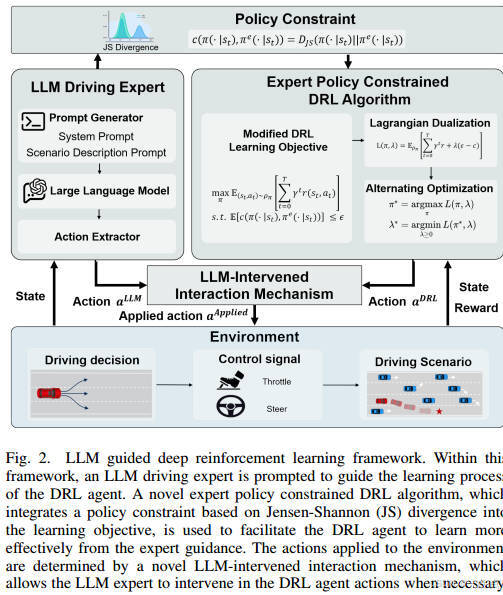
作者提出LLM引導的深度強化學習框架(LGDRL),通過以下創新點解決問題:
-
LLM駕駛專家:替代人類專家,提供低成本、高質量的決策指導。
-
專家策略約束算法:基于Jensen-Shannon(JS)散度的策略約束,限制DRL策略與LLM專家策略的差異,提升知識吸收效率。
-
LLM干預互動機制:允許LLM在訓練階段間歇性干預DRL代理的動作,避免災難性行為,同時保留自主探索能力。
方法細節
 ?
?
 ?
?
-
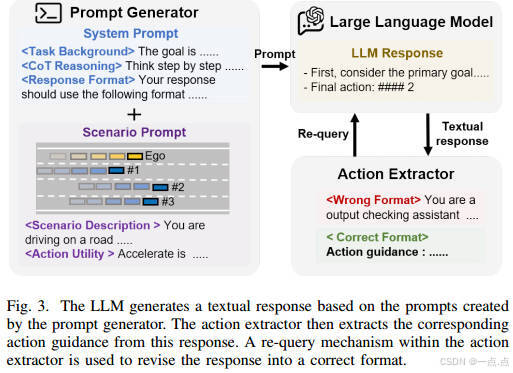
LLM專家構建
-
基于ChatGPT-4o構建,通過提示生成文本響應,提取動作指導。
-
包含重查詢機制,確保動作格式正確性。
-
-
專家策略約束算法
-
優化目標:最大化累積獎勵,同時約束DRL策略與專家策略的JS散度(公式11-15)。
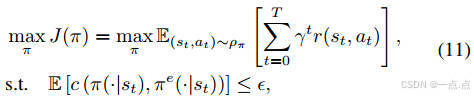
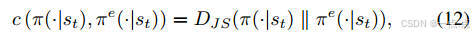
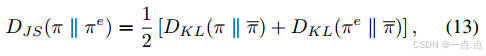
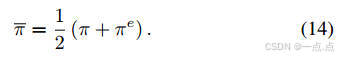
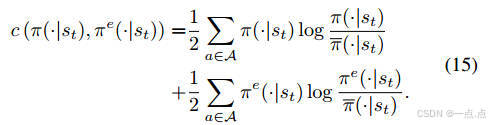
-
實現:結合拉格朗日對偶理論,通過交替優化策略和拉格朗日乘子(公式16-18)。
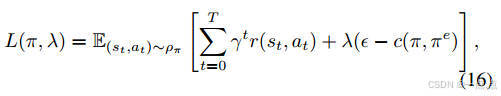
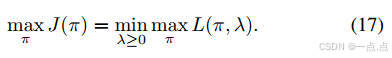
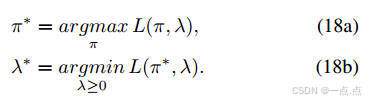
-
策略更新:Actor-Critic框架中,Critic網絡評估動作值函數,Actor網絡優化策略(公式19-25)。
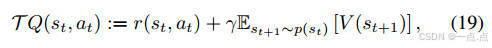
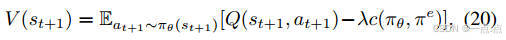
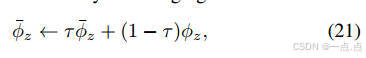
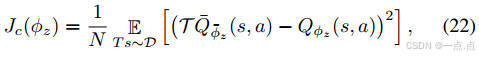
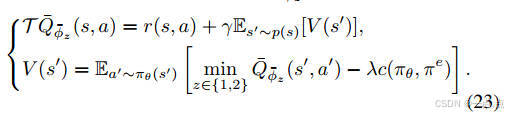
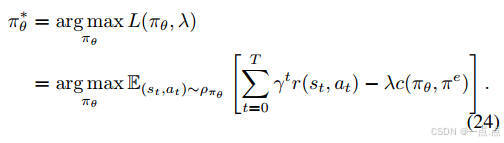
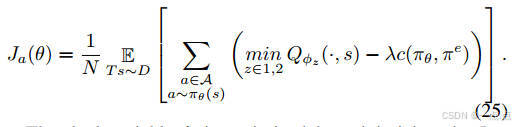
-
-
LLM干預機制
-
動作替換條件:基于時間到碰撞(TTC)的安全評估和間歇性干預權限(公式29)。

-
間歇模式:僅在部分訓練回合允許干預,平衡專家指導與自主探索。
-
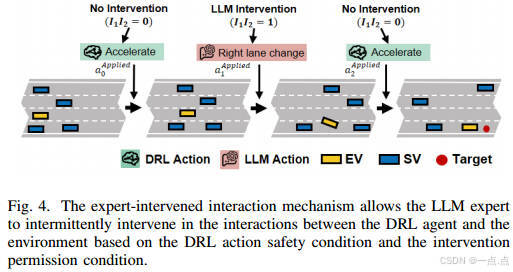
實驗與結果
-
實驗場景
-
使用
highway-env模擬四車道高速公路,目標為右車道500米處,周圍車輛隨機生成。 -
對比基線包括Vanilla-SAC、SAC+RP、SAC+BC、SAC+Demo。
-
-
訓練性能
-
回報與成功率:LGDRL在218回合內達到基線最大回報,成功率82%,顯著優于其他方法(圖7)。
-
專家指導利用率:干預次數和率最低(圖8),表明高效吸收專家知識。
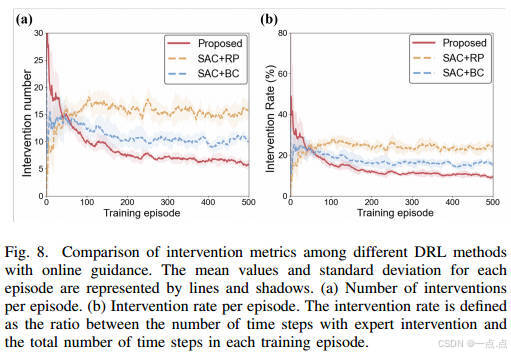
-
-
測試性能
-
任務成功率90%,碰撞率10%,推理時間僅0.01秒/步,優于LLM專家的3.72秒(表VI-VII)。
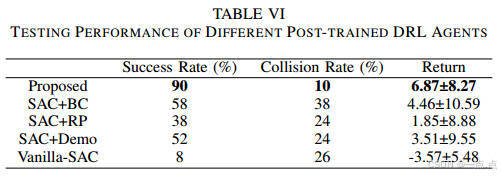
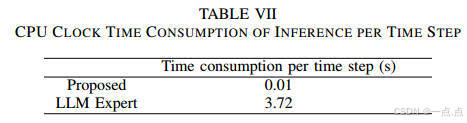
-
策略一致性:與LLM專家的JS散度最低(0.12),動作選擇高度一致(圖9-10)。
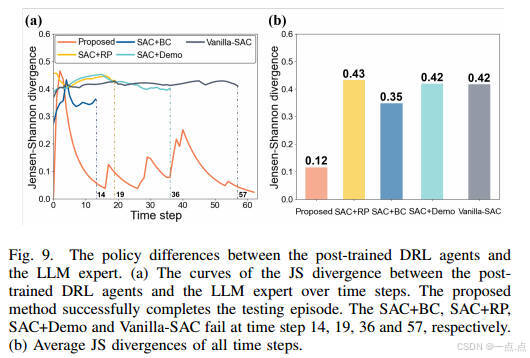
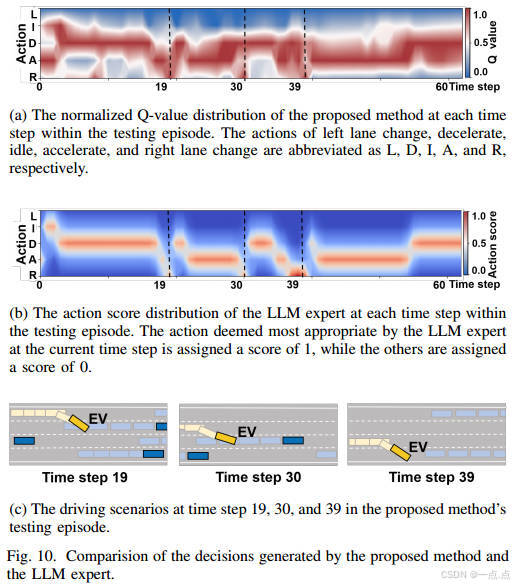
-
-
干預模式與消融實驗
-
間歇干預優于持續干預,避免過度依賴專家,保持自主探索能力(表VIII)。
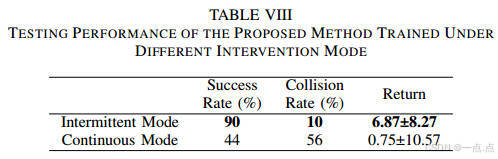
-
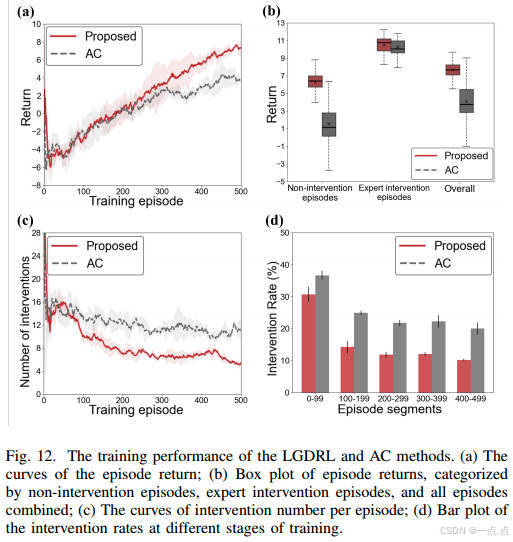
策略約束組件顯著提升訓練性能,干預需求減少(圖12)。
-
?
創新與不足
創新點:
-
首次將LLM作為專家融入DRL訓練閉環,降低對人類專家的依賴。
-
通過策略約束和間歇干預機制,平衡學習效率與自主探索。
潛在不足:
-
LLM專家的安全性與泛化能力需進一步驗證,尤其在極端場景(如緊急避障)。
-
實驗環境較理想化,未涉及城市道路、行人交互等復雜場景。
-
LLM的實時推理依賴預訓練DRL代理,可能限制其動態適應性。
結論與展望
LGDRL框架通過LLM引導DRL,顯著提升自動駕駛決策的效率和安全性,任務成功率達90%,且具備實時推理能力。未來可擴展至多車協同、復雜城市道路等場景,并探索LLM與DRL的更深度融合(如多模態輸入)。該研究為自動駕駛決策系統提供了一種高效、低成本的新范式。
如果此文章對您有所幫助,那就請點個贊吧,收藏+關注 那就更棒啦,十分感謝!!!?

)




)
 - 隨筆)
)




![[git]如何關聯本地分支和遠程分支](http://pic.xiahunao.cn/[git]如何關聯本地分支和遠程分支)


:實際案例)


