KWDB介紹
KWDB數據庫是由開放原子開源基金會孵化的分布式多模數據庫,專為AIoT場景設計,支持時序數據、關系數據和非結構化數據的統一管理。其核心架構采用多模融合引擎,集成列式時序存儲、行式關系存儲及自適應查詢優化器,實現跨模型數據的高效關聯查詢與實時分析。通過動態分片、智能副本及改進的兩階段提交協議,具備千萬級設備接入能力和百萬級/秒的寫入吞吐,同時保障分布式環境下數據一致性與高可用性。內置納秒級時序處理引擎、Delta-Zip跨模壓縮算法及分層存儲策略,顯著降低存儲成本并提升查詢效率,已在工業物聯網、智能電網等領域驗證其技術優勢,支持毫秒級實時監控與復雜分析場景。作為開源項目,其生態持續擴展,為多源異構數據處理提供高性價比解決方案。
官網鏈接:https://www.kaiwudb.com/
一、多模架構設計:統一數據模型與跨模協同
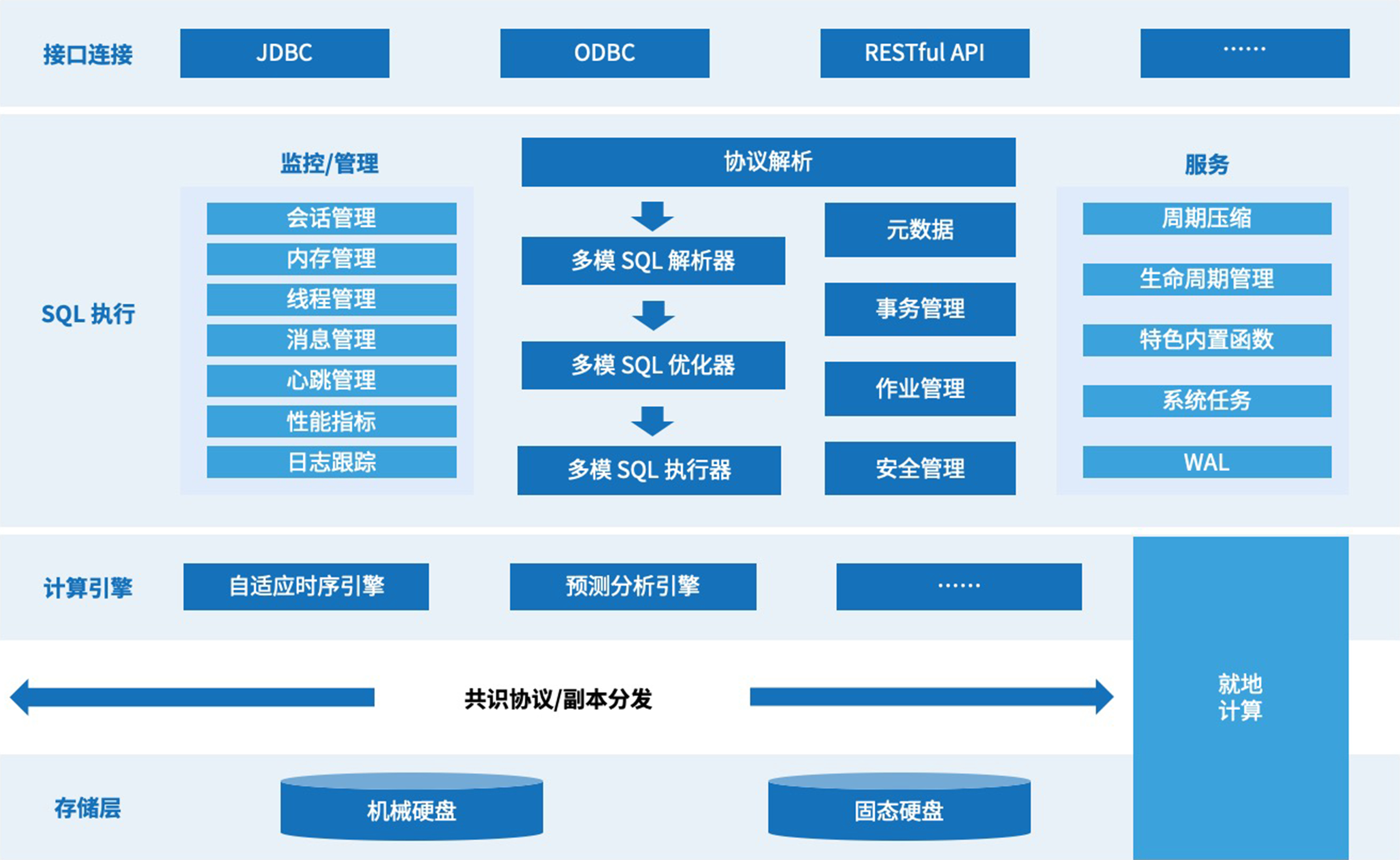
1.1 多模融合的核心機制
KWDB 2.2.0 通過多模融合架構實現對時序數據、關系數據和非結構化數據的統一管理。其核心設計包括以下技術組件:
- 統一元數據層:通過抽象時序庫(TS DATABASE)和關系庫的元數據模型,實現跨模數據的一致性管理。例如,創建時序表時需顯式標記
TS DATABASE,并限制不支持的數據類型(如DECIMAL)。- 混合存儲引擎:時序數據采用列式存儲與壓縮算法(存儲效率提升40%),關系數據使用行式存儲,并通過主鍵索引優化事務處理。
- 自適應查詢優化器:自動識別查詢涉及的數據模型,生成邏輯執行計劃。例如,跨模關聯查詢時,優先將關系數據下推到時序引擎過濾(outside-in優化),或提前聚合時序數據(inside-out優化)。
案例:跨模數據關聯查詢
-- 創建時序表
CREATE TS DATABASE factory_monitor;
CREATE TABLE factory_monitor.sensor_data (k_timestamp TIMESTAMP NOT NULL,device_id STRING,temperature FLOAT
) ATTRIBUTES (location STRING,status STRING
) PRIMARY TAGS (device_id) ACTIVETIME 3h;-- 創建關系表
CREATE TABLE device_metadata (device_id STRING PRIMARY KEY,model STRING,install_date DATE
);-- 跨模關聯查詢
SELECT s.k_timestamp, s.temperature, d.model
FROM factory_monitor.sensor_data s
JOIN device_metadata d ON s.device_id = d.device_id
WHERE s.temperature > 30.0;
此查詢通過時序引擎的 PRIMARY TAGS 索引快速定位設備數據,再與關系表 device_metadata 進行哈希關聯,減少數據傳輸量。
二、時序數據處理:納秒級精度與高效分析
2.1 時序引擎關鍵技術
- 高精度時間戳:支持微秒和納秒級時間精度,適用于工業物聯網的納秒級數據追蹤場景。新增函數
time_bucket支持納秒級時間窗口聚合。- 向量化執行引擎:通過 SIMD 指令集優化查詢性能,點查速度提升3倍。例如,執行
SELECT temperature FROM sensor_data WHERE device_id='DEV001'時,直接通過設備索引定位數據塊。- 流式處理支持:集成時間窗口(如
SESSION WINDOW)和狀態函數(如ELAPSED),實現實時數據分析:
-- 計算設備連續運行時間
SELECT device_id, ELAPSED(k_timestamp)
FROM factory_monitor.sensor_data
WHERE status='active'
GROUP BY device_id;
2.2 存儲與壓縮優化
- 時序壓縮算法:采用差值編碼(Delta Encoding)和游程編碼(RLE),存儲效率較上一版本提升40%。
- 分層存儲策略:熱數據保留在內存列式緩存(ActiveTime=3h),冷數據自動歸檔至對象存儲。
三、分布式架構:一致性協議與彈性擴展
3.1 Shared-Nothing 架構設計
KWDB 采用無共享架構,每個節點獨立處理本地數據。關鍵技術包括:
- 動態分片(Dynamic Sharding):根據數據量和負載自動調整分片策略,避免熱點問題。例如,時序數據按設備ID哈希分片,關系數據按主鍵范圍分片。
- 兩階段提交優化:改進傳統2PC協議,通過異步提交提升事務吞吐量。協調器(TransactionCoordinator)在準備階段收集所有參與者響應,僅需半數確認即可提交。
// 分布式事務協調器核心邏輯(簡化)
func (tc *TransactionCoordinator) ExecuteDistributedTx(tx *Transaction) error {prepareResults := make(chan bool, len(tc.participants))for _, p := range tc.participants {go func(p *Participant) { prepareResults <- p.Prepare(tx) }(p)}allPrepared := truefor range tc.participants {if !<-prepareResults { allPrepared = false }}if allPrepared {for _, p := range tc.participants { go p.Commit(tx) }return nil} else {for _, p := range tc.participants { go p.Rollback(tx) }return errors.New("prepare failed")}
}
3.2 一致性保障與擴展性
- 智能副本機制:基于機器學習預測節點故障概率,動態調整副本分布。例如,高負載節點自動增加副本數量。
- 水平擴展能力:實測3節點集群可支撐千萬級設備接入,寫入吞吐量達百萬條/秒,讀取延遲低于10ms。
四、優勢與改進空間
5.1 技術優勢
- 多模統一管理:簡化物聯網場景下的數據架構,降低運維復雜度。
- 時序處理性能:納秒級精度和向量化引擎滿足工業實時性需求。
- 分布式彈性:動態分片和智能副本支持千萬級設備接入。
5.2 潛在改進點
- 生態兼容性:部分依賴(如libprotobuf)需手動升級,增加部署復雜度。
- 文檔完整性:操作系統適配列表和內核參數配置缺乏詳細說明。
- 邊緣計算支持:當前邊緣節點功能較基礎,需增強輕量化部署能力。
總結
KWDB 2.2.0 通過多模融合架構、高效時序處理和分布式優化,成為AIoT場景下的理想數據庫解決方案。其在金融、工業等領域的成功實踐驗證了技術可行性,但需在生態兼容性和邊緣計算方面持續改進。



)















