【題目】:SOTR: Segmenting Objects with Transformers
【引用格式】:Guo R, Niu D, Qu L, et al. Sotr: Segmenting objects with transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 7157-7166.
【網址】:https://openaccess.thecvf.com/content/ICCV2021/papers/Guo_SOTR_Segmenting_Objects_With_Transformers_ICCV_2021_paper.pdf
【開源代碼】:https://github.com/easton-cau/SOTR
目錄
一、瓶頸問題
二、本文貢獻
三、解決方案
1、模型架構
2、Transformer
2.1 雙注意力機制(Twin attention)
2.2 Transformer層
2.3 功能頭(Functional heads)
3、Mask
3.1 多級上采樣模塊
3.2 實例掩碼預測
四、實驗結果
1、實驗設置
2、消融實驗
3、定量和定性結果
一、瓶頸問題
- 傳統 CNN 在實例分割中的局限:基于 CNN 的實例分割方法(遵循檢測 - 然后 - 分割范式)存在不足。CNN 因有限的感受野,在高級視覺語義信息中特征連貫性相對缺乏,難以關聯實例,對大物體分割效果欠佳;并且分割質量和推理速度過度依賴目標檢測器,在復雜場景下性能較差。
- 自底向上方法的缺陷:為克服傳統 CNN 方法的缺點,一些自底向上的實例分割策略被提出,這類方法雖能保留位置和局部連貫信息,但存在聚類不穩定(如掩碼碎片化、粘連)以及在不同場景數據集上泛化能力差的問題。
- Transformer 在視覺應用中的不足:受 Transformer 在自然語言處理中的成功啟發,其在視覺任務應用中展現出一定優勢,然而典型 Transformer 在提取低級特征方面表現不佳,對小物體預測易出錯;同時由于特征圖規模大,在訓練階段需要大量內存和時間。
二、本文貢獻
- 提出創新的混合框架:引入了名為 SOTR 的 CNN - Transformer 混合實例分割框架。該框架利用 CNN 骨干網絡和 Transformer 編碼器,有效對局部連接性和長距離依賴關系建模,表現力強;且直接分割對象實例,不依賴邊界框檢測,簡化了整體流程。
- 設計新的注意力機制:設計了雙注意力機制(twin attention),這是一種位置敏感的自注意力機制,專為模型中的 Transformer 定制。相比原始 Transformer,在計算和內存上有顯著節省,尤其適用于實例分割這類對大輸入進行密集預測的任務。
- 降低對大規模預訓練的依賴:SOTR 無需在大型數據集上進行預訓練就能很好地泛化歸納偏差,更易于應用在數據量不足的場景,克服了純 Transformer 模型對大規模預訓練的依賴問題。
- 取得優異的實驗結果:在 MS COCO 基準測試中,使用 ResNet - 101 - FPN 骨干網絡的 SOTR 模型 AP 達到 40.2% ,精度超越多數現有方法。在中等和大尺寸物體上,AP 分別達到 59.0% 和 73.0% ,展現出在不同尺寸物體分割上的優勢。
三、解決方案
1、模型架構
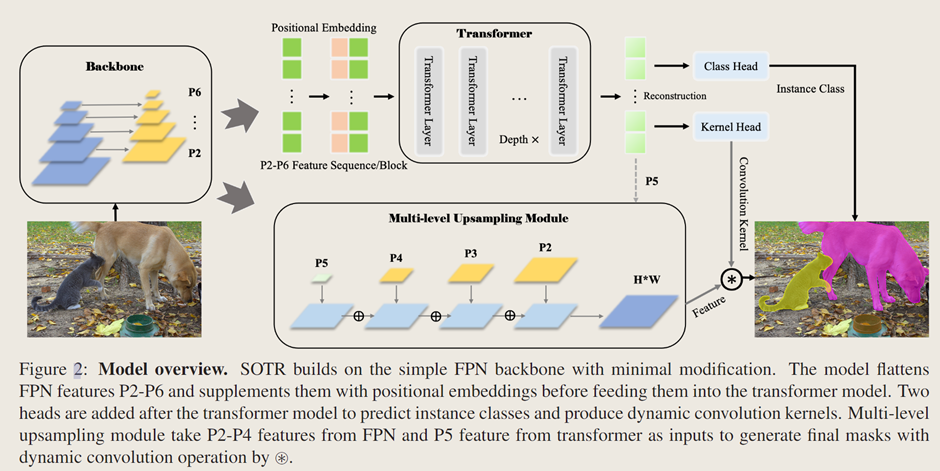
????????SOTR 是一種 CNN-Transformer 混合實例分割模型,它能夠同時學習二維表示,并輕松捕捉長距離信息。它遵循直接分割范式,首先將輸入特征圖劃分為圖塊,然后在動態分割每個實例的同時預測每個圖塊的類別【Transformer模塊】。具體來說,模型主要由三個部分組成:1)一個骨干網絡(from detectron2.modeling.backbone import build_backbone),用于從輸入圖像中提取圖像特征,尤其是低級和局部特征;2)一個 Transformer,用于對全局和語義依賴關系進行建模,它附加了功能頭,分別用于預測每個圖塊的類別和卷積核;3)一個多級上采樣模塊,通過在生成的特征圖和相應的卷積核之間執行動態卷積操作來生成分割掩碼。
2、Transformer
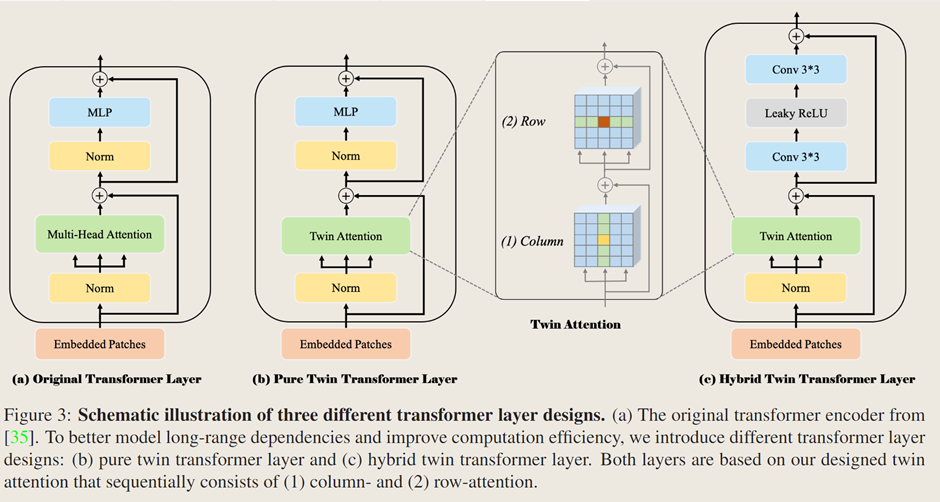
2.1 雙注意力機制(Twin attention)
自注意力機制的問題:能夠捕捉全圖上下文和長距離交互關系,但時間和內存復雜度為二次方,處理圖像等高維序列是計算成本高,阻礙模型擴展性。
雙注意力機制策略:通過稀疏表示簡化注意力矩陣,將感受野限制在固定步長的塊模式內。先在每列內計算注意力(聚合水平尺度上元素間上下文信息),再在每行內計算(利用垂直尺度特征交互),兩個尺度注意力順序連接【通道維度連接】形成最終注意力,具有全局感受野,并涵蓋了兩個維度上的信息。
具體計算過程:對于 FPN 第i層特征圖,先分割成 N×N 圖塊
并堆疊成塊,添加位置嵌入(列位置嵌入空間1×N×C,行位置嵌入空間N×1×C )。注意力層采用多頭注意力機制,子層輸出 N×N×C ,可將計算復雜度從降至
。
2.2 Transformer層
原始Transformer層(圖3 a):類似 NLP 中編碼器,由層歸一化后的多頭自注意力機制和多層感知器兩部分組成,用殘差連接相連,經K個串行連接輸出多維序列特征用于后續預測。
純雙 Transformer 層(圖3 b):遵循原始設計,僅將多頭注意力替換為雙注意力機制,以平衡計算成本和特征提取效果。
混合雙 Transformer 層(圖3 c):在每個雙注意力模塊添加兩個由 Leaky ReLU 層連接的3×3卷積層,補充注意力機制,更好捕捉局部信息,增強特征表示。
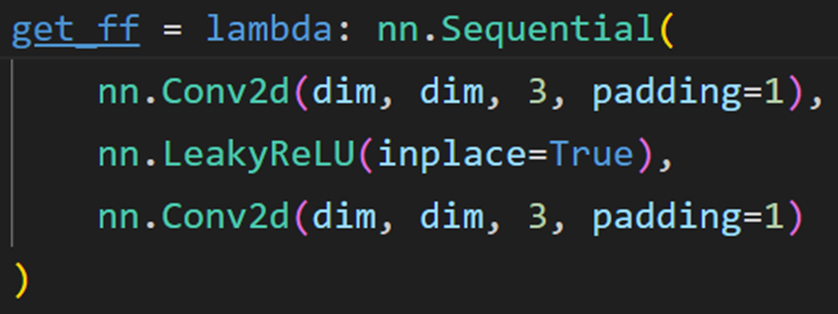
2.3 功能頭(Functional heads)
類別頭(class head):含單個線性層,輸出N×N×M分類結果(M為類別數)。每個圖塊為中心落入的單個目標分配一個類別,采用多級預測并在不同特征層級共享頭,提升不同尺度目標性能和效率。訓練時用 Focal Loss 計算分類損失。
核心頭(kernel head):由線性層組成,與類別頭并行,輸出N×N×D張量(表示N×N卷積核及D個參數)用于掩碼生成。訓練時卷積核監督來自最終掩碼損失。

3、Mask
3.1 多級上采樣模塊
從 Transformer 模塊獲取帶位置信息的低分辨率特征圖,與 FPN 中
?融合。對各尺度特征圖先進行3×3卷積、Group Norm 和 ReLU 操作,
分別雙線性上采樣到
分辨率,將處理后
相加,經逐點卷積和上采樣生成統一H × W特征圖,構建掩碼特征表示。
3.2 實例掩碼預測
SOTR 對統一特征圖執行動態卷積操作生成每個圖塊掩碼。核心頭預測卷積核,每個核負責對應圖塊實例掩碼生成,操作表示為
。
,其中 λ 為卷積核的尺寸
- 最終實例分割掩碼由 Matrix NMS 生成,每個掩碼由 Dice Loss 獨立監督
四、實驗結果
1、實驗設置
在具有挑戰性的 MS COCO 數據集上實驗,該數據集含 12.3 萬張圖像、80 類實例標簽。模型在 train2017 子集訓練,test-dev 子集評估,報告標準 COCO 指標(AP、AP50、AP75、APs、APm、APl)。訓練使用 SGD,初始學習率 0.01,1000 次迭代熱身,權重衰減,動量 0.9。消融實驗訓練 30 萬次迭代,在 21 萬次和 25 萬次時學習率降為十分之一。模型在 4 塊 32G 內存的 V100 GPU 上訓練,批量大小 8,用 Python 編程,基于 PyTorch 和 Detectron2 框架。
2、消融實驗
主干網絡架構:
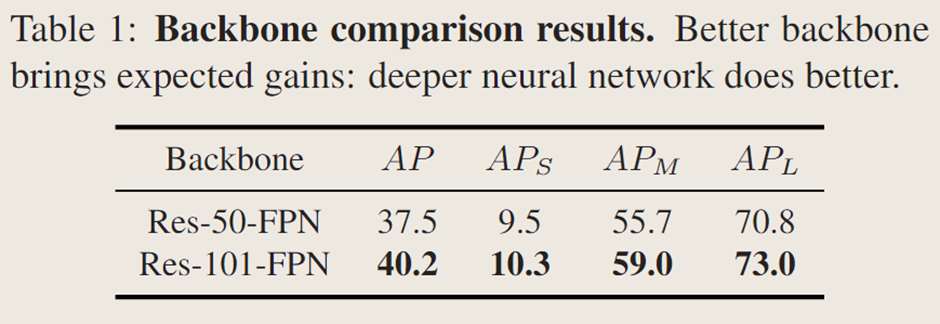
比較不同主干網絡特征提取性能,發現 Res-50FPN 的 SOTR 在 COCO 上 AP 達 37.5%,大物體上 AP 為 70.8%,且 SOTR 從更深或先進的 CNN 主干網絡中自動受益,更好的主干網絡可提升性能。
用于特征編碼的 Transformer:

用三種不同 Transformer 衡量模型性能,純雙注意力 Transformer 和混合雙注意力 Transformer 在指標上大幅超過原始 Transformer,表明雙注意力 Transformer 架構能捕捉長距離依賴,更適合與 CNN 主干結合,且混合雙注意力 Transformer 效果更好,因為 3×3 卷積能提取局部信息、增強特征表達。
Transformer 深度:
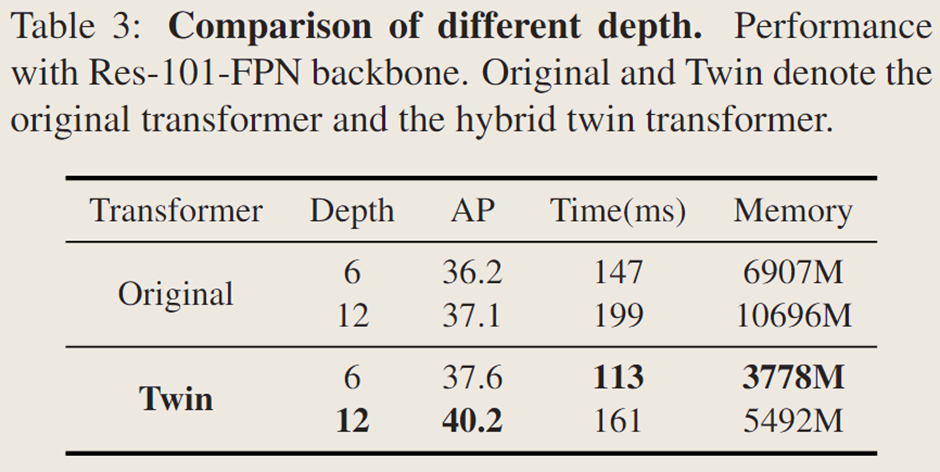
對原始 Transformer 和混合雙注意力 Transformer 進行深度消融實驗,發現增加深度可提升 AP 但犧牲推理時間和內存,雙注意力 Transformer 相比原始 Transformer 帶來 3.1% 的 AP 提升,內存占用減少約 50%,但深度增加會導致注意力坍塌,阻礙性能提升,后續實驗中基準模型使用深度為 12 的混合雙注意力 Transformer。
多級上采樣模塊:
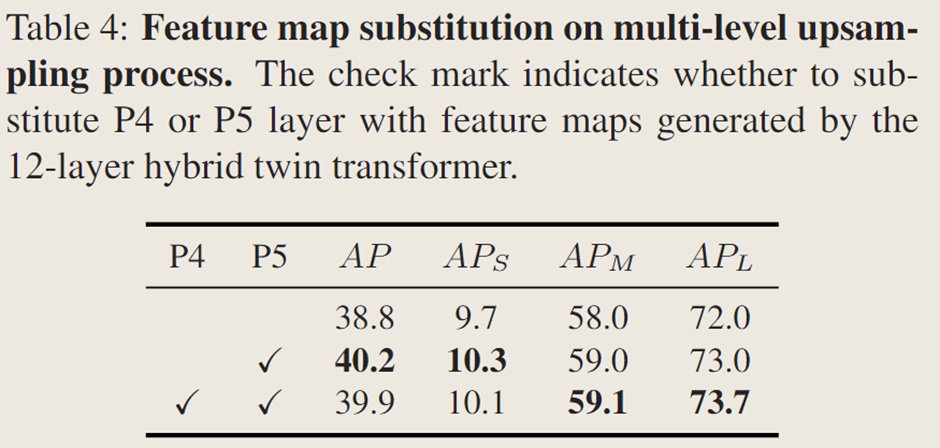
探究 Transformer 生成的特征圖對多級上采樣模塊的影響,僅用 Transformer 生成的特征圖替換 FPN 的層時模型 AP 最高,同時替換
和
層 AP 略降,表明更多層使用生成特征圖未顯著提升整體 AP,Transformer 的
已使預測具有良好位置敏感性,Transformer 的
因攜帶更多全局和大物體特征使
和
略有提升,SOTR 用 Transformer 替代 SOLOv2 中
層的 Coordconv 獲取位置信息。
動態卷積:
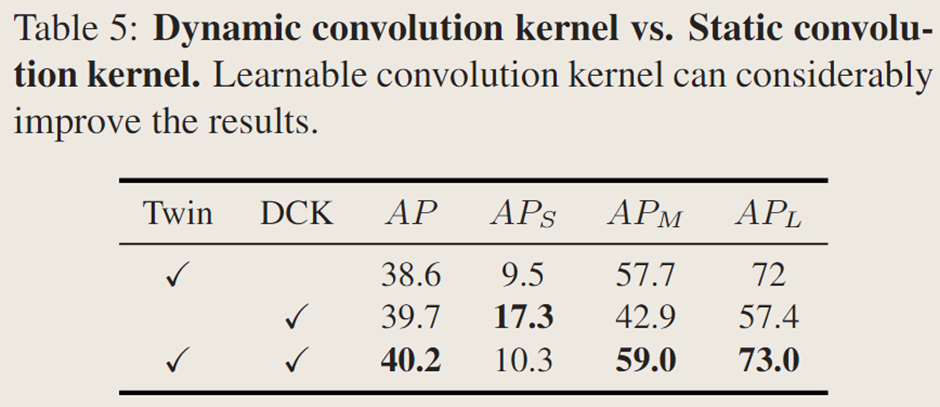
掩碼生成有靜態卷積直接輸出實例掩碼和動態卷積持續分割對象兩種方式,比較發現無雙注意力 Transformer 的 SOTR 模型 AP 為 39.7%,雙注意力 Transformer 帶來 0.5% 的提升,動態卷積策略使 AP 提升近 1.5%,因為動態卷積的非線性顯著增強了特征表示能力。
實時模型及比較:
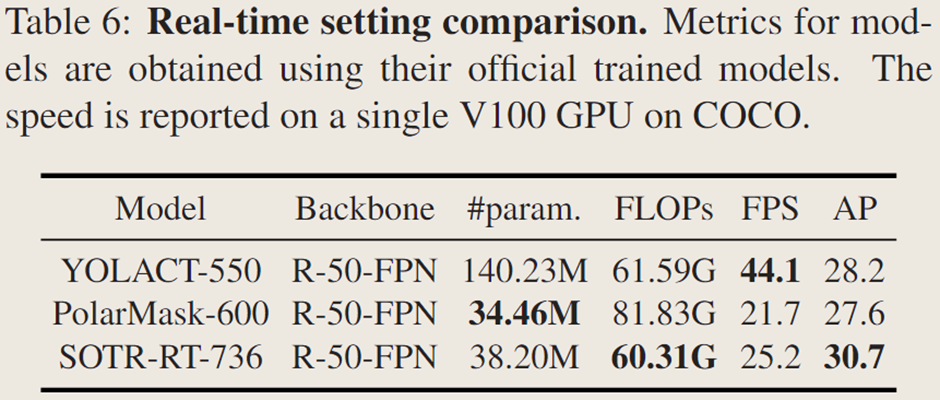
SOTR 可修改為實時模型 SOTR-RT(犧牲一定準確性),其 Transformer 層數減為兩層,輸入短邊為 736【圖像輸入的短邊分辨率】
3、定量和定性結果
定量結果:
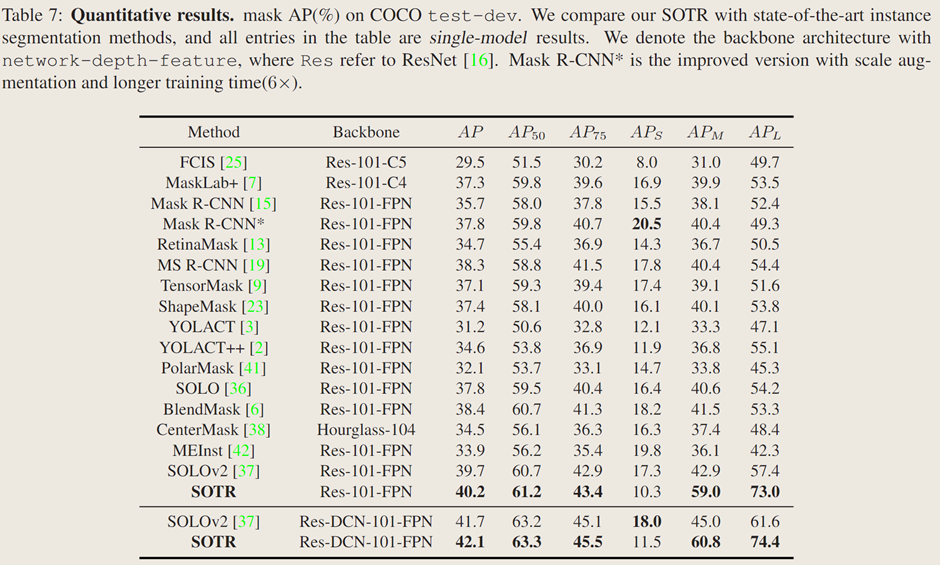
在 MS COCO 測試開發集上,配備 ResNet-101-FPN 的 SOTR 模型掩碼 AP 達 40.2%,優于其他現代實例分割方法,與 Mask R-CNN 相比預測精度更高,在中等和大目標檢測上有顯著提升,與無邊界框算法 SOLO 和 PolarMask 相比也有明顯改進,且是首個在中等大小目標上 AP 接近 60%、中等和大目標上 AP 超 70% 的方法。
定性結果:

將 SOTR 與 Mask R-CNN、BlendMask 和 SOLOv2 比較,SOTR 在形狀精細易被忽略的物體和相互重疊物體的分割上優于 Mask R-CNN 和 BlendMask,能預測出邊界更清晰的掩碼;相比 SOLOv2,SOTR 避免了將目標分割成獨立部分和誤將背景判定為實例的問題,因引入 Transformer 能更好獲取全局信息。

















![[ 設計模式 ] | 單例模式](http://pic.xiahunao.cn/[ 設計模式 ] | 單例模式)

