作者:來自 Elastic?Gustavo Llermaly
了解如何利用語義搜索和 ELSER 構建一個強大且視覺上吸引人的問答體驗,而無需使用 LLMs。
想要獲得 Elastic 認證?查看下一期 Elasticsearch Engineer 培訓的時間!
Elasticsearch 擁有眾多新功能,幫助你為你的用例構建最佳搜索解決方案。深入學習我們的示例筆記本,了解更多信息,開始免費云試用,或立即在本地機器上嘗試 Elastic。
你可能聽說過 RAG(Retrieval Augmented Generation - 檢索增強生成),這是一種將你自己的文檔與 LLM 結合,以生成類人回答的常用策略。在本文中,我們將探討如果不使用 LLM,僅依靠語義搜索和 ELSER,能實現多大的效果。
如果你是 RAG 新手,可以閱讀這篇關于 Azure 和 AI 上 RAG 的文章,這篇關于使用 Mistral 的 RAG 的文章,或這篇關于使用 Amazon Bedrock 構建 RAG 應用的文章。
大語言模型的缺點
雖然 LLM 能提供類人語言的回答,而不僅僅是返回文檔,但在實現它們時需要考慮以下幾點:
- 成本:使用 LLM 服務會按 token 收費,或者如果你想在本地運行模型,則需要專用硬件
- 延遲:增加 LLM 步驟會增加響應時間
- 隱私:在使用云端模型時,你的信息會被發送給第三方,涉及到各種隱私問題
- 管理:引入 LLM 意味著你需要處理一個新的技術組件,包括不同的模型提供商和版本、提示詞工程、幻覺等問題
只需要 ELSER 就夠了
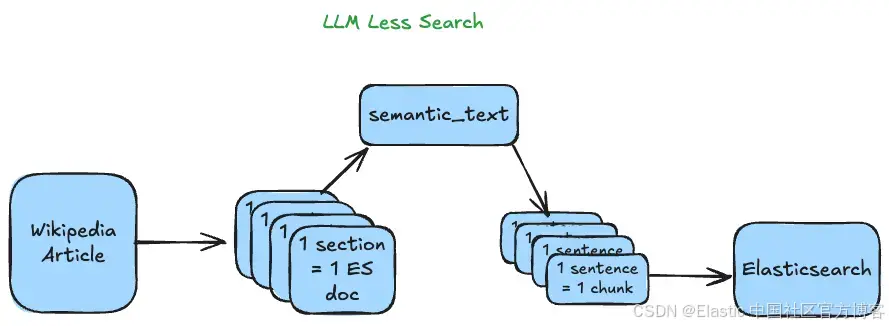
如果你仔細想想,一個 RAG 系統的效果取決于背后的搜索引擎。雖然搜索后直接讀到一個合適的答案比得到一串結果要好,但它的價值體現在:
-
可以用問題來查詢,而不是關鍵詞,這樣你不需要文檔中有完全相同的詞,因為系統 “理解” 意思。
-
不需要讀完整篇文本就能獲取所需信息,因為 LLM 會在你提供的上下文中找到答案并將其展示出來。
考慮到這些,我們可以通過使用 ELSER 來進行語義搜索獲取相關信息,并對文檔進行結構化,使用戶在輸入問題后,界面能直接引導他們找到答案,而無需閱讀全文,從而實現非常好的效果。
為了獲得這些好處,我們會使用 semantic_text 字段、文本分塊 和 語義高亮。想了解最新的 semantic_text 特性,推薦閱讀這篇文章。
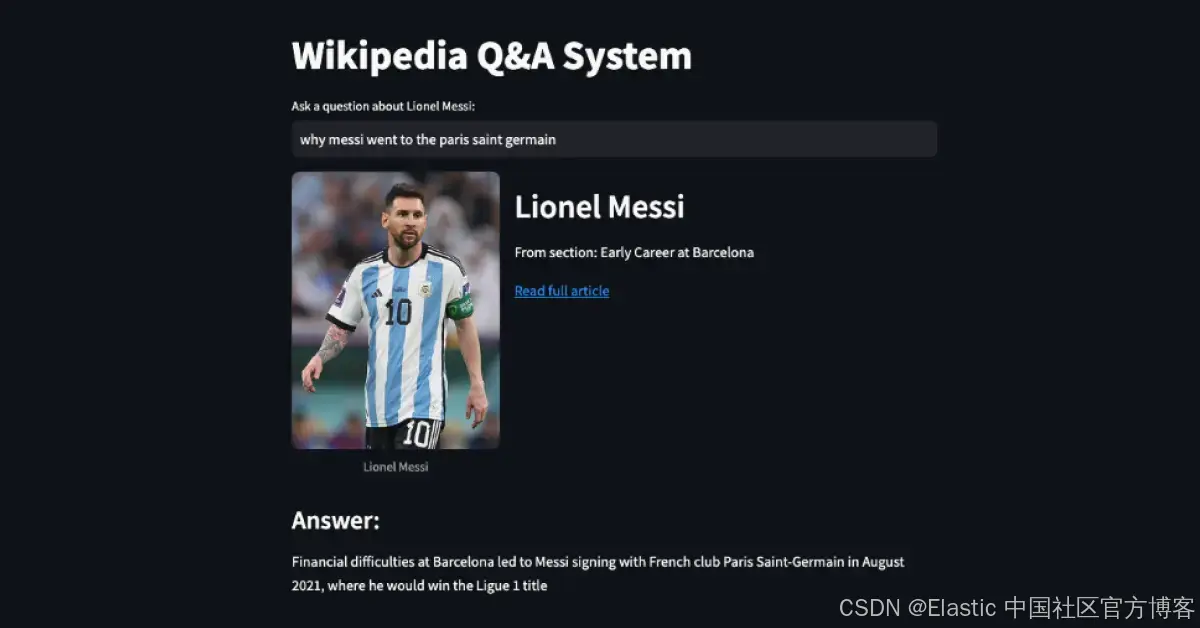
我們會用 Streamlit 創建一個應用,把所有內容整合起來。它應該看起來像這樣:
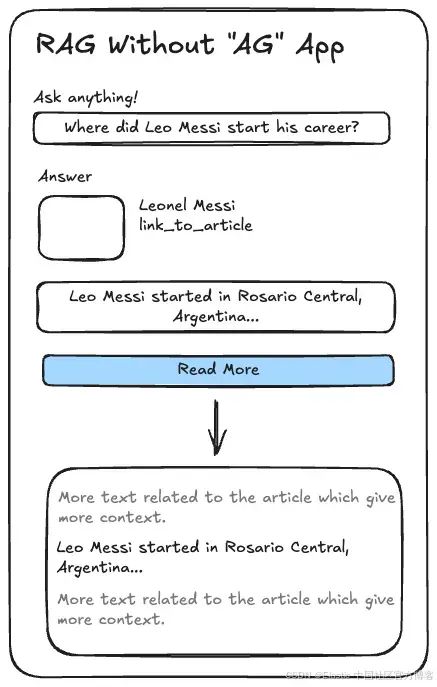
目標是提問后,從原始文檔中獲取回答問題的句子,并通過一個按鈕查看該句子的上下文。為了提升用戶體驗,我們還會添加一些元數據,比如文章縮略圖、標題和來源鏈接。這樣,根據不同的文章,展示答案的卡片也會有所不同。
要求:
-
Elastic Serverless 實例。可以在這里開始試用
-
Python
關于文檔結構,我們會索引 Wikipedia 頁面,使每篇文章的每個部分成為一個 Elasticsearch 文檔,然后每個文檔再被分割成句子。這樣,我們就能精準定位回答問題的句子,并能參考該句子的上下文。
以下是創建和測試應用的步驟:
-
配置 Inference endpoint
-
配置 mappings
-
上傳文檔
-
創建應用
-
最終測試
本文只包含主要模塊,你可以在這里訪問完整的代碼倉庫。
配置推理端點
導入依賴項
from elasticsearch import Elasticsearch
import osos.environ["ELASTIC_ENDPOINT"] = ("your_es_endpoint"
)
os.environ["ELASTIC_API_KEY"] = ("your_es_key"
)es = Elasticsearch(os.environ["ELASTIC_ENDPOINT"],api_key=os.environ["ELASTIC_API_KEY"],
)INDEX_NAME = "wikipedia"首先,我們將配置推理端點,在這里我們將定義 ELSER 作為我們的模型,并建立分塊設置:
- strategy:可以是 “sentence” 或 “word”。我們選擇 “sentence” 以確保所有分塊都有完整的句子,因此高亮會作用于短語而不是單詞,使答案更流暢。
- max_chunk_size:定義每個分塊的最大單詞數。
- sentence_overlap:重疊的句子數。范圍從 1 到 0。我們將其設置為 0,以提高高亮精度。當你想捕捉相鄰內容時,建議使用 1。
你可以閱讀這篇文章了解更多關于分塊策略的內容。
es.options(request_timeout=60, max_retries=3, retry_on_timeout=True).inference.put(task_type="sparse_embedding",inference_id="wiki-inference",body={"service": "elasticsearch","service_settings": {"adaptive_allocations": {"enabled": True},"num_threads": 1,"model_id": ".elser_model_2",},"chunking_settings": {"strategy": "sentence","max_chunk_size": 25,"sentence_overlap": 0,},},
)配置映射
我們將配置以下字段來定義我們的映射:
mapping = {"mappings": {"properties": {"title": {"type": "text"},"section_name": {"type": "text"},"content": {"type": "text", "copy_to": "semantic_content"},"wiki_link": {"type": "keyword"},"image_url": {"type": "keyword"},"section_order": {"type": "integer"},"semantic_content": {"type": "semantic_text","inference_id": "wiki-inference",},}}
}# Create the index with the mapping
if es.indices.exists(index=INDEX_NAME):es.indices.delete(index=INDEX_NAME)es.indices.create(index=INDEX_NAME, body=mapping)確保將內容字段復制到我們的 semantic_content 字段中,以便進行語義搜索。
上傳文檔
我們將使用以下腳本上傳來自關于 Lionel Messi 的 Wikipedia 頁面上的文檔。
# Define article metadata
title = "Lionel Messi"
wiki_link = "https://en.wikipedia.org/wiki/Lionel_Messi"
image_url = "https://upload.wikimedia.org/wikipedia/commons/b/b4/Lionel-Messi-Argentina-2022-FIFA-World-Cup_%28cropped%29.jpg"# Define sections as array of objects
sections = [{"section_name": "Introduction","content": """Lionel Andrés "Leo" Messi (Spanish pronunciation: [ljo?nel an?d?es ?mesi] ?; born 24 June 1987) is an Argentine professional footballer who plays as a forward for and captains both Major League Soccer club Inter Miami and the Argentina national team. Widely regarded as one of the greatest players of all time, Messi set numerous records for individual accolades won throughout his professional footballing career such as eight Ballon d'Or awards and eight times being named the world's best player by FIFA. He is the most decorated player in the history of professional football having won 45 team trophies, including twelve Big Five league titles, four UEFA Champions Leagues, two Copa Américas, and one FIFA World Cup. Messi holds the records for most European Golden Shoes (6), most goals in a calendar year (91), most goals for a single club (672, with Barcelona), most goals (474), hat-tricks (36) and assists (192) in La Liga, most assists (18) and goal contributions (32) in the Copa América, most goal contributions (21) in the World Cup, most international appearances (191) and international goals (112) by a South American male, and the second-most in the latter category outright. A prolific goalscorer and creative playmaker, Messi has scored over 850 senior career goals and has provided over 380 assists for club and country.""",},{"section_name": "Early Career at Barcelona","content": """Born in Rosario, Argentina, Messi relocated to Spain to join Barcelona at age 13, and made his competitive debut at age 17 in October 2004. He gradually established himself as an integral player for the club, and during his first uninterrupted season at age 22 in 2008–09 he helped Barcelona achieve the first treble in Spanish football. This resulted in Messi winning the first of four consecutive Ballons d'Or, and by the 2011–12 season he would set La Liga and European records for most goals in a season and establish himself as Barcelona's all-time top scorer. The following two seasons, he finished second for the Ballon d'Or behind Cristiano Ronaldo, his perceived career rival. However, he regained his best form during the 2014–15 campaign, where he became the all-time top scorer in La Liga, led Barcelona to a historic second treble, and won a fifth Ballon d'Or in 2015. He assumed Barcelona's captaincy in 2018 and won a record sixth Ballon d'Or in 2019. During his overall tenure at Barcelona, Messi won a club-record 34 trophies, including ten La Liga titles and four Champions Leagues, among others. Financial difficulties at Barcelona led to Messi signing with French club Paris Saint-Germain in August 2021, where he would win the Ligue 1 title during both of his seasons there. He joined Major League Soccer club Inter Miami in July 2023.""",},{"section_name": "International Career","content": """An Argentine international, Messi is the national team's all-time leading goalscorer and most-capped player. His style of play as a diminutive, left-footed dribbler, drew career-long comparisons with compatriot Diego Maradona, who described Messi as his successor. At the youth level, he won the 2005 FIFA World Youth Championship and gold medal in the 2008 Summer Olympics. After his senior debut in 2005, Messi became the youngest Argentine to play and score in a World Cup in 2006. Assuming captaincy in 2011, he then led Argentina to three consecutive finals in the 2014 FIFA World Cup, the 2015 Copa América and the Copa América Centenario, all of which they would lose. After initially announcing his international retirement in 2016, he returned to help his country narrowly qualify for the 2018 FIFA World Cup, which they would exit early. Messi and the national team finally broke Argentina's 28-year trophy drought by winning the 2021 Copa América, which helped him secure his seventh Ballon d'Or that year. He then led Argentina to win the 2022 Finalissima, as well as the 2022 FIFA World Cup, his country's third overall world championship and first in 36 years. This followed with a record-extending eighth Ballon d'Or in 2023, and a victory in the 2024 Copa América.""",},# Add more sections as needed...
]# Load each section as a separate document
for i, section in enumerate(sections):document = {"title": title,"section_name": section["section_name"],"content": section["content"],"wiki_link": wiki_link,"image_url": image_url,"section_order": i,}# Index the documentes.index(index=INDEX_NAME, document=document)# Refresh the index to make documents searchable immediately
es.indices.refresh(index=INDEX_NAME)創建應用
我們將創建一個應用,用戶輸入問題后,應用會在 Elasticsearch 中搜索最相關的句子,并使用高亮顯示展示最相關的答案,同時顯示該句子來自的章節。這樣,用戶可以正確閱讀答案,然后通過類似 LLM 生成的答案中包含引文的方式深入了解。
安裝依賴
pip install elasticsearch streamlit st-annotated-text讓我們首先創建一個運行問題語義查詢的函數:
# es.py
from elasticsearch import Elasticsearch
import osos.environ["ELASTIC_ENDPOINT"] = ("your_serverless_endpoint"
)
os.environ["ELASTIC_API_KEY"] = ("your_search_key"
)es = Elasticsearch(os.environ["ELASTIC_ENDPOINT"],api_key=os.environ["ELASTIC_API_KEY"],
)INDEX_NAME = "wikipedia"# Ask function
def ask(question):print("asking question")print(question)response = es.search(index=INDEX_NAME,body={"size": 1,"query": {"semantic": {"field": "semantic_content", "query": question}},"highlight": {"fields": {"semantic_content": {}}},},)print("Hits",response)hits = response["hits"]["hits"]if not hits:print("No hits found")return Noneanswer = hits[0]["highlight"]["semantic_content"][0]section = hits[0]["_source"]return {"answer": answer, "section": section}在 ask 方法中,我們將返回第一個對應完整章節的文檔作為完整上下文,并將來自高亮部分的第一個片段作為答案,按 _score 排序,也就是說,最相關的將是最優先的。
現在,我們將所有內容組合在一個 Streamlit 應用中。為了突出顯示答案,我們將使用 annotated_text,這是一個組件,可以更容易地為高亮文本添加顏色并進行標記。
# ui.py
import streamlit as st
from es import ask
from annotated_text import annotated_textdef highlight_answer_in_section(section_text, answer):"""Highlight the answer within the section text using annotated_text"""before, after = section_text.split(answer, 1)# Return the text with the answer annotatedreturn annotated_text(before,(answer, "", "rgb(22 97 50)"),after)def main():st.title("Wikipedia Q&A System")question = st.text_input("Ask a question about Lionel Messi:")if question:try:# Get response from elasticsearchresult = ask(question)if result and "section" in result:section = result["section"]answer = result["answer"]# Display article metadatacol1, col2 = st.columns([1, 2])with col1:st.image(section["image_url"],caption=section["title"],use_container_width=True,)with col2:st.header(section["title"])st.write(f"From section: {section['section_name']}")st.write(f"[Read full article]({section['wiki_link']})")# Display the answerst.subheader("Answer:")st.markdown(answer)# Add toggle button for full contexton = st.toggle("Show context")if on:st.subheader("Full Context:")highlight_answer_in_section(section["content"], answer)else:st.error("Sorry, I couldn't find a relevant answer to your question.")except Exception as e:st.error(f"An error occurred: {str(e)}")st.error("Please try again with a different question.")if __name__ == "__main__":main()最終測試
要進行測試,我們只需要運行代碼并提出我們的提問:
streamlit run ui.py
不錯!答案的質量將取決于我們的數據以及問題與可用句子之間的相關性。
結論
通過良好的文檔結構和優秀的語義搜索模型如 ELSER,能夠構建一個無需 LLM 的問答體驗。盡管它有一些局限性,但它是一個值得嘗試的選項,幫助我們更好地理解數據,而不僅僅是將一切交給 LLM 并寄希望于它。
在本文中,我們展示了通過使用語義搜索、語義高亮和一些 Python 代碼,如何在不使用 LLM 的情況下接近 RAG 系統的結果,而沒有其缺點,如成本、延遲、隱私和管理等。
文檔結構和用戶界面中的用戶體驗等元素有助于彌補你從 LLM 合成答案中獲得的 “人性化” 效果,專注于向量數據庫找到回答問題的確切句子的能力。
一個可能的下一步是補充其他數據源來創建更豐富的體驗,其中 Wikipedia 只是用于回答問題的多個數據源之一,類似于 Perplexity 的做法。
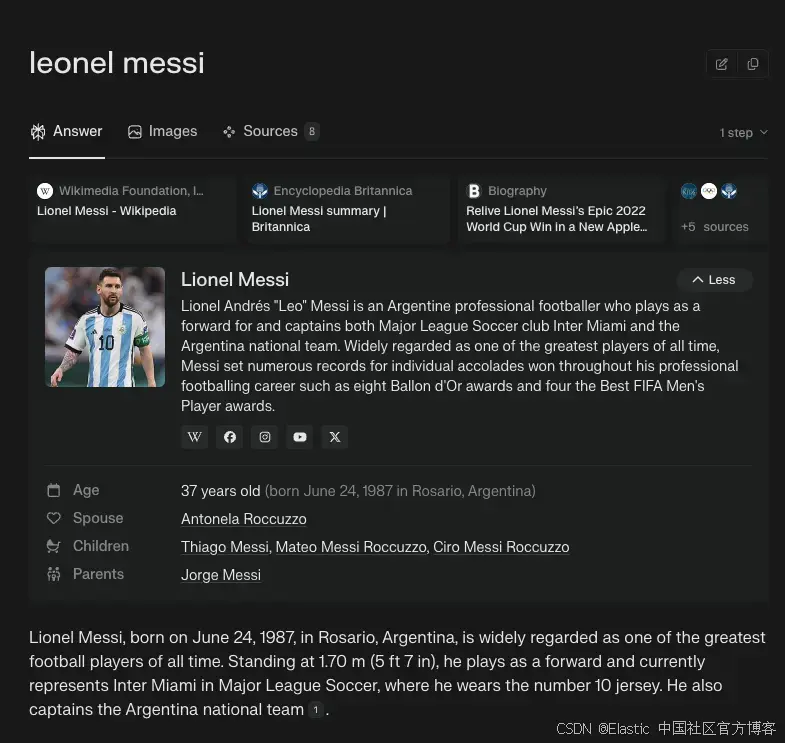
這樣,我們可以創建一個應用,利用不同的平臺提供你搜索的人或實體的 360° 視圖。
你準備好試試嗎?
原文:RAG without “AG”? - Elasticsearch Labs



![[STM32] 4-2 USART與串口通信(2)](http://pic.xiahunao.cn/[STM32] 4-2 USART與串口通信(2))



詳解)



 13980+真車 超跑 大型載具MOD整合包+最新GTA6大型地圖MOD 5月最新更新)



)

)
)
