在 ARM 架構的微控制器(MCU)中,總線矩陣(Bus Matrix) 是總線系統的核心互連結構,負責協調多個主設備(如 CPU、DMA、以太網控制器等)對多個從設備(如 Flash、SRAM、外設等)的并發訪問。其設計目標是提升系統吞吐量、降低訪問沖突,并支持并行操作。
—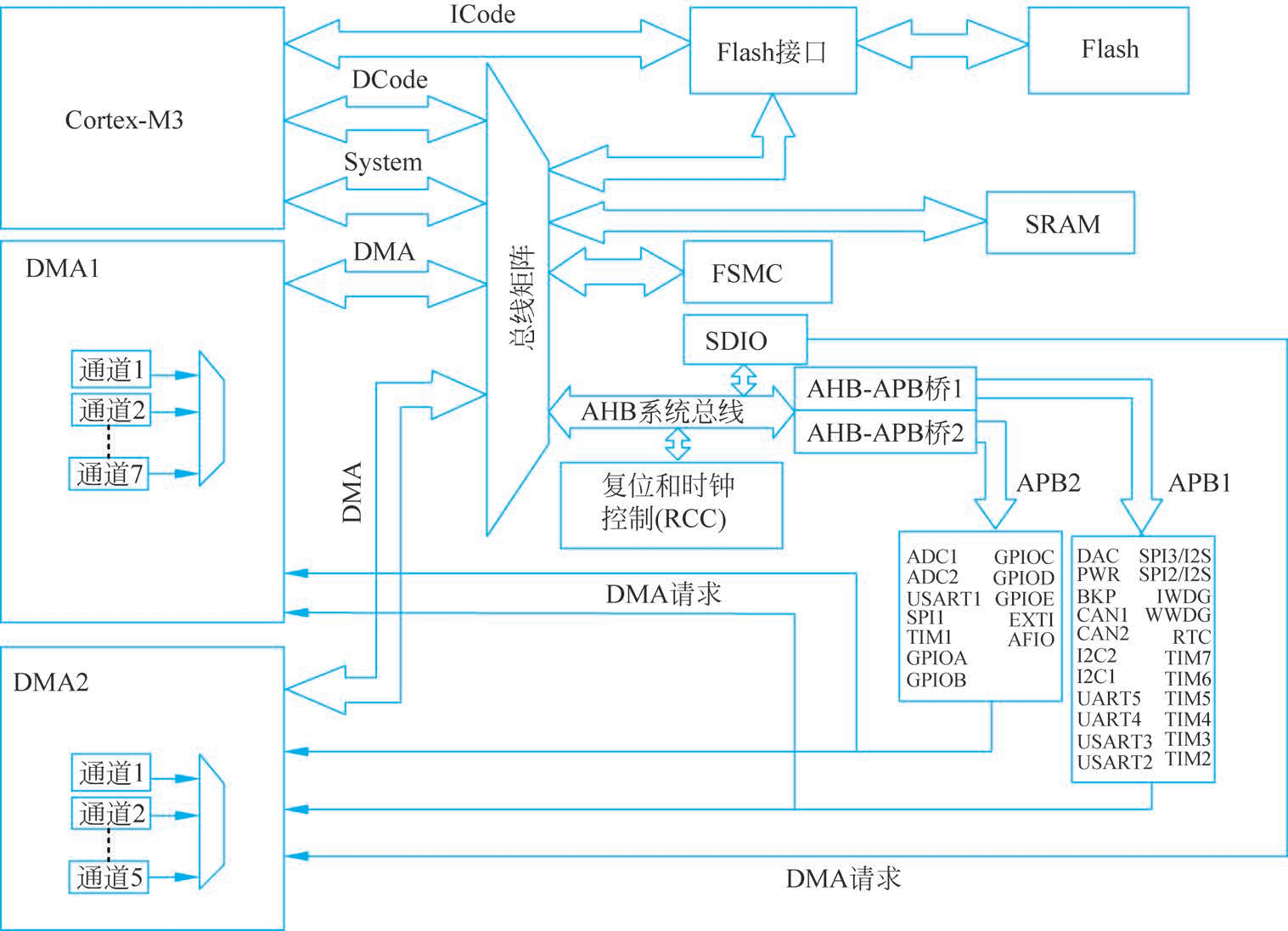
STM32F103系統架構圖
總線矩陣的核心功能
- 多主設備并發訪問
允許多個主設備同時訪問不同的從設備(例如:CPU 讀取 Flash 時,DMA 可以同時寫 SRAM)。 - 優先級仲裁
當多個主設備請求同一從設備時,仲裁器根據預設優先級分配訪問權。 - 地址解碼與路由
將主設備的請求路由到目標從設備(如地址范圍決定訪問 Flash 還是外設)。 - 低延遲與高帶寬
通過并行路徑減少總線爭用,提升實時性。
總線矩陣的典型結構
1. 主端口(Master Ports)
連接需要發起總線操作的主設備,例如:
- CPU 核心(Cortex-M)
- DMA 控制器
- 高速外設(如以太網 MAC、USB 控制器)
2. 從端口(Slave Ports)
連接被訪問的從設備,例如:
- Flash 控制器
- SRAM 控制器
- AHB-APB 橋(連接低速外設)
- 外設寄存器
3. 仲裁器(Arbiter)
- 當多個主設備請求同一從設備時,決定訪問順序。
- 仲裁策略可以是固定優先級(如 DMA 優先級高于 CPU)或輪詢(Round-Robin)。
4. 地址解碼器(Decoder)
- 解析主設備的地址請求,確定目標從設備。
- 例如:地址
0x0000_0000–0x1FFF_FFFF映射到 Flash,0x2000_0000–0x3FFF_FFFF映射到 SRAM。
5. 數據路徑(Data Path)
- 提供物理連接通道,支持多路獨立傳輸路徑。
總線矩陣 vs. 傳統共享總線
| 特性 | 總線矩陣 | 傳統共享總線 |
|---|---|---|
| 并發性 | 多主設備同時訪問不同從設備 | 單主設備獨占總線 |
| 效率 | 高吞吐量,低延遲 | 易出現總線爭用,效率受限 |
| 復雜度 | 高(需要路由和仲裁邏輯) | 低 |
| 適用場景 | 多核/多主設備系統 | 簡單單主設備系統 |
總線矩陣的典型應用場景
- CPU 與 DMA 并行操作
- CPU 從 Flash 讀取代碼時,DMA 可以將 ADC 采集的數據寫入 SRAM。
- 多外設并發訪問
- 以太網控制器發送數據包時,USB 控制器可以同時接收數據。
- 實時性要求高的系統
- 避免因總線阻塞導致關鍵任務(如中斷響應)延遲。
總線矩陣的實現示例(以 Cortex-M7 為例)
主設備端:├── Cortex-M7 核心(通過 AHB 或 AXI 總線)├── DMA1 控制器├── DMA2 控制器└── 以太網 MAC從設備端:├── Flash 控制器(0x0800_0000)├── SRAM1(0x2000_0000)├── SRAM2(0x2001_0000)├── AHB-APB 橋(連接 APB 外設)└── 外部存儲器接口(FSMC/FMC)總線矩陣邏輯:└── 根據地址和仲裁規則,動態分配主設備到從設備的路徑。
總線矩陣的設計考量
- 時鐘域
- 主設備和從設備可能運行在不同時鐘頻率,需同步邏輯。
- 主設備數量
- 總線矩陣的復雜度隨主設備數量增加而顯著上升。
- 延遲與吞吐量
- 高頻系統中需優化數據路徑寬度(如 32-bit/64-bit)。
- 低功耗模式
- 空閑時關閉未使用的總線段以降低功耗。
總線矩陣的優勢
- 提升系統性能:通過并行操作最大化帶寬利用率。
- 增強實時性:避免關鍵任務因總線阻塞而延遲。
- 簡化系統設計:標準化接口(如 AHB/AXI)便于集成第三方 IP 核。
總結
總線矩陣是 ARM MCU 實現高效多主設備協同的核心機制,尤其在高性能 Cortex-M7/M33 或 Cortex-A 系列中廣泛應用。其靈活的路由和仲裁能力,使得復雜嵌入式系統(如實時控制系統、物聯網網關)能夠兼顧性能與實時性。




:C 語言強制類型轉換詳解)


 吳恩達版提示詞工程 6. 轉換 (翻譯,通用翻譯,語氣風格變換,文本格式轉換,拼寫檢查和語法檢查))

:STM32F103加入AFIO控制器)

:TOGAF ADM架構愿景的核心價值)







