視頻:https://www.bilibili.com/video/BV1Z14y1Z7LJ/?spm_id_from=333.337.search-card.all.click&vd_source=7a1a0bc74158c6993c7355c5490fc600
別人的筆記:https://zhuanlan.zhihu.com/p/626966526
6. 轉換任務(Transforming)
大型語言模型非常擅長將輸入轉換為不同的格式。
例如輸入一種語言的文本,將其轉換或翻譯為另一種語言,或者幫助進行拼寫和語法的檢查和修改。因此,將一段不完全符合語法的文本作為輸入,可以讓它幫助你x糾正拼寫和語法。或者用來轉換文本格式,例如輸入 HTML ,讓它輸出 JSON 格式的文本。
我以前編寫應用程序的時候,要非常辛苦編寫一堆正則表達式。現在通過大語言模型和一些提示,就可以更簡單地實現。
是的,我現在基本上使用 ChatGPT 來校對我寫的任何東西,所以我很高興能向你展示 Notebook 中的更多例子。
6.1 文本翻譯
ChatGPT使用多種語言的源代碼進行訓練。這使模型能夠進行翻譯。以下是一些如何使用此功能的示例。
首先,我們導入 OpenAI,使用我們在本視頻中一直使用的 get_completion 輔助函數。
import openai
import os
from openai import OpenAI# 1. 根據環境變量獲取 openai key
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())openai.api_key = os.getenv('OPENAI_API_KEY') client = OpenAI()# 2. 定義 get_completion 方法
def get_completion(prompt, instructions=None, model="gpt-3.5-turbo"):response = client.responses.create(model=model,instructions=instructions,input=prompt,temperature=0, # this is the degree of randomness of the model's output)return response.output_text
我們要做的第一件事是翻譯任務。大型語言模型是在許多來源的大量文本上訓練出來的,其中很多內容來自互聯網,這當然會有許多不同的語言。因此, 這使模型具有翻譯能力。模型以不同程度的熟練掌握數百種語言。我們將通過一些例子來介紹如何使用這種能力。
讓我們從簡單的問題開始。在第一個例子中,提示是將以下英文文本翻譯成西班牙語: “Hi, I would like to order a blender”。
prompt = f"""
Translate the following English text to Spanish: \
```Hi, I would like to order a blender```
"""response = get_completion(prompt)print(response)
模型的預期回答是“Hola,me gustaría ordenar una licuadora”。
很遺憾,我沒學過西班牙語,你肯定能看出來。
好,讓我們嘗試另一個例子。在這個例子中,提示是,告訴我這是什么語言。然后這是一句法語 “Combien co?te la lampe d’air”。
prompt = f"""
Tell me which language this is:
```Combien co?te le lampadaire?```
"""
response = get_completion(prompt)
print(response)
我們來運行一下。
This is French.
模型已經識別出這是法語。
模型也可以同時進行多種翻譯。在這個例子中,提示要求,將以下文本翻譯成法語和西班牙語,再加一個“海盜英語”。這段文本是,“我想訂購一個籃球”。
prompt = f"""
Translate the following text to French and Spanish
and English pirate: \
```I want to order a basketball```
"""
response = get_completion(prompt)
print(response)
模型的輸出,這里是法語,西班牙語,還有海盜英語。
French: Je veux commander un ballon de basket
Spanish: Quiero ordenar un balón de baloncesto
English pirate: I be wantin' to order a basketball
在一些語言中,翻譯可能會因說話者與聽眾的關系而變化。你也可以向語言模型解釋這一點,這樣它就能進行相應的翻譯。
在這個例子中,我們提示要求,將以下文本翻譯成西班牙語,分別用正式的和非正式的用法表達,“你想訂購一個枕頭嗎?”。
prompt = f"""
Translate the following text to Spanish in both the \
formal and informal forms:
'Would you like to order a pillow?'
"""
response = get_completion(prompt)
print(response)
請注意,為了進行區別,我們在這里使用了不同于重音符的分隔符,而不是雙引號。使用什么分隔符并不重要,只要能實現清晰的分隔就可以。
Formal: ?Le gustaría ordenar una almohada?
Informal: ?Te gustaría ordenar una almohada?
模型的輸出,在這里有正式和非正式用法的區別。正式用法是指當你和比你資深的人交談或者在專業環境下使用的語氣,而非正式用法是指你和朋友說話時所使用的語氣。我其實不會說西班牙語,但是我爸爸會,他說這是正確的。
6.2 通用翻譯器
下一個例子,假設我們負責一家跨國電商公司,用戶發來的信息將會是各種不同的語言,因此他們會用各種不同的語言,告訴我們關于 IT 的問題。因此,我們需要一個通用的翻譯器。
首先,我們將粘貼一個各種不同語言的用戶信息的列表,然后我們將循環遍歷每一條用戶消息。
user_messages = ["La performance du système est plus lente que d'habitude.", # System performance is slower than normal "Mi monitor tiene píxeles que no se iluminan.", # My monitor has pixels that are not lighting"Il mio mouse non funziona", # My mouse is not working"Mój klawisz Ctrl jest zepsuty", # My keyboard has a broken control key"我的屏幕在閃爍" # My screen is flashing
]
對于用戶消息中的問題,我將復制這個稍長一點的代碼塊。我們首先讓模型告訴我們,這個問題用的是什么語言,然后打印出原始消息使用的語言和問題的內容,然后我們要求模型將其翻譯成英語和韓語。
for issue in user_messages:prompt = f"Tell me what language this is: ```{issue}```"lang = get_completion(prompt)print(f"Original message ({lang}): {issue}")prompt = f"""Translate the following text to English \and Korean: ```{issue}```"""response = get_completion(prompt)print(response, "\n")
讓我們運行一下。
Original message (This text is in French.): La performance du système est plus lente que d’habitude.
English: “The system performance is slower than usual.”
Korean: “??? ??? ???? ????.”
Original message (This sentence is in Spanish.): Mi monitor tiene píxeles que no se iluminan.
English: “My monitor has pixels that do not light up.”
Korean: “? ????? ??? ?? ??? ????.”
Original message (This phrase is in Italian. It translates to “My mouse is not working” in English.): Il mio mouse non funziona
English: My mouse is not working
Korean: ? ???? ???? ???
Original message (This text is in Polish.): Mój klawisz Ctrl jest zepsuty
English: My Ctrl key is broken
Korean: ? Ctrl ?? ?? ???
Original message (This text is in Chinese.): 我的屏幕在閃爍
English: My screen is flickering
Korean: ? ??? ??????
模型的輸出是,這條原始消息是法語,還有各種語言的消息,然后模型將它們翻譯成英語和韓語。你可以在這里看到,模型的輸出是 “This is French”, 這是因為此在提示中要求的響應格式是“This is French”。如果你希望只用一個單詞或不用句子來回答,你可以試著編輯這個提示。或者你也可以要求它以 JSON 格式或類似的方式,這將會鼓勵它不要使用整個句子來回答。
令人驚嘆的是,你剛剛構建了一款通用翻譯器。你可以隨時暫停視頻,在這里添加任何你想嘗試語言,也許是你自己說的語言,看看模型的表現如何。
6.3語氣和風格變換
ChatGPT可以產生不同的風格(語氣)。
接下來我們要深入探討的是風格轉換。
寫作可以根據預期的受眾不同而變化,我給同事或教授寫郵件的方式,顯然會與我給弟弟發短信的方式大不相同。ChatGPT 也可以幫助產生不同的語氣。
讓我們看一些例子。在第一個例子中,提示是,將以下俚語翻譯成商業信函:“老兄,這是喬,看看這盞落地燈的規格。”
prompt = f"""
Translate the following from slang to a business letter:
'Dude, This is Joe, check out this spec on this standing lamp.'
"""
response = get_completion(prompt)
print(response)
我們來執行一下。
Dear Sir/Madam,
I am writing to bring to your attention the specifications of the standing lamp.
Sincerely,
Joe
正如你所看到的,我們得到了一封更正式的商業信函,提出關于落地燈規格的建議。
6.4 文本格式轉換
接下來我們要做的是在不同的格式之間進行轉換。
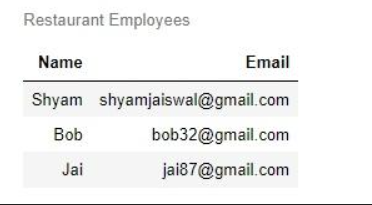
ChatGPT 非常擅長在不同的格式之間進行轉換,比如從 JSON 到 HTML,XML,markdown,等等。 在提示中,我們將描述輸入和輸出格式。這里有一個例子。因此,我們一個 JSON 格式,包含一個餐廳員工的名單,包括他們的名字和電子郵件。
在提示中,我們要求模型將其從 JSON 轉換為 HTML,提示是:將以下的 Python 字典從 JSON 轉換為具有列頭和標題行的 HTML 表格。然后我們將從模型中獲得響應并將其打印出來。
data_json = { "resturant employees" :[ {"name":"Shyam", "email":"shyamjaiswal@gmail.com"},{"name":"Bob", "email":"bob32@gmail.com"},{"name":"Jai", "email":"jai87@gmail.com"}]
}prompt = f"""
Translate the following python dictionary from JSON to an HTML \
table with column headers and title: {data_json}
"""
response = get_completion(prompt)
print(response)
模型的輸出如下。
<table><caption>Restaurant Employees</caption><thead><tr><th>Name</th><th>Email</th></tr></thead><tbody><tr><td>Shyam</td><td>shyamjaiswal@gmail.com</td></tr><tr><td>Bob</td><td>bob32@gmail.com</td></tr><tr><td>Jai</td><td>jai87@gmail.com</td></tr></tbody>
</table>
我們得到了HTML格式,顯示所有員工的名字和電子郵件。讓我們看看是否可以實際查看這個 HTML。我們將使用 Python 庫中的顯示函數,來顯示 HTML 響應。
from IPython.display import display, Markdown, Latex, HTML, JSON
display(HTML(response))
預期可以看到下面格式的 HTML 表格。
6.5 拼寫檢查/語法檢查
我們的下一個轉換任務是拼寫檢查和語法檢查。
這是 ChatGPT 的一個非常流行的用途。我強烈推薦這樣做。我一直都這樣做。當你在非母語語言中工作時,特別有用。
這里有一些常見的語法和拼寫問題的例子,這個例子展示語言模型如何幫助解決這些問題。
我將粘貼一個有一些語法或拼寫錯誤的句子列表,然后我們將循環遍歷每個句子,要求模型校對并進行糾正。我們要使用一些分隔符。最后獲取響應并將其打印出來。
text = [ "The girl with the black and white puppies have a ball.", # The girl has a ball."Yolanda has her notebook.", # ok"Its going to be a long day. Does the car need it’s oil changed?", # Homonyms"Their goes my freedom. There going to bring they’re suitcases.", # Homonyms"Your going to need you’re notebook.", # Homonyms"That medicine effects my ability to sleep. Have you heard of the butterfly affect?", # Homonyms"This phrase is to cherck chatGPT for speling abilitty" # spelling
]for t in text:prompt = f"Proofread and correct: ```{t}```"response = get_completion(prompt)print(response)
運行程序,模型輸出如下。
The girl with the black and white puppies has a ball.
Yolanda has her notebook.
"It's going to be a long day. Does the car need its oil changed?"
Here is the corrected version: "There goes my freedom. They are going to bring their suitcases."
You're going to need your notebook.
"That medicine affects my ability to sleep. Have you heard of the butterfly effect?"
This phrase is to check ChatGPT for spelling ability.
就這樣,這個模型能夠糾正所有這些語法錯誤。
我們可以使用一些我們在之前討論過的技術來改進提示。為了改進提示,我們可以說,校對和糾正以下文本, 并重寫整個校正后的版本。如果沒有發現任何錯誤,只需輸出“沒有發現錯誤”。
text = [ "The girl with the black and white puppies have a ball.", # The girl has a ball."Yolanda has her notebook.", # ok"Its going to be a long day. Does the car need it’s oil changed?", # Homonyms"Their goes my freedom. There going to bring they’re suitcases.", # Homonyms"Your going to need you’re notebook.", # Homonyms"That medicine effects my ability to sleep. Have you heard of the butterfly affect?", # Homonyms"This phrase is to cherck chatGPT for speling abilitty" # spelling
]for t in text:prompt = f"""Proofread and correct the following textand rewrite the corrected version. If you don't findand errors, just say "No errors found". Don't use any punctuation around the text:```{t}```"""response = get_completion(prompt)print(response)
讓我們來試試這個提示。通過這種方式,我們能夠. . . 哦,這里還在使用引號。
The girl with the black and white puppies has a ball.
No errors found
It's going to be a long day. Does the car need its oil changed?
No errors found
You're going to need your notebook.
No errors found
This phrase is to check ChatGPT for spelling ability.
通過這種方式,我們能夠. . . 哦,這里還在使用引號。
但你可以想象,通過一點點迭代地進行提示開發,你能夠找到一個更加可靠的提示方式,每一次都能更好地工作。
現在我們再舉一個例子。在你把文本發布到公共論壇之前,檢查一下總是很有用的。因此,我們將舉一個檢查評論的例子。下面是一篇關于毛絨熊貓玩具的評論。我們將要求模型校對和糾正這篇評論。
text = f"""
Got this for my daughter for her birthday cuz she keeps taking \
mine from my room. Yes, adults also like pandas too. She takes \
it everywhere with her, and it's super soft and cute. One of the \
ears is a bit lower than the other, and I don't think that was \
designed to be asymmetrical. It's a bit small for what I paid for it \
though. I think there might be other options that are bigger for \
the same price. It arrived a day earlier than expected, so I got \
to play with it myself before I gave it to my daughter.
"""prompt = f"proofread and correct this review: ```{text}```"
response = get_completion(prompt)
print(response)
很好。所以我們有了這個糾正的版本。
I got this for my daughter for her birthday because she keeps taking mine from my room. Yes, adults also like pandas too. She takes it everywhere with her, and it’s super soft and cute. One of the ears is a bit lower than the other, and I don’t think that was designed to be asymmetrical. It’s a bit small for what I paid for it though. I think there might be other options that are bigger for the same price. It arrived a day earlier than expected, so I got to play with it myself before I gave it to my daughter.
我們還可以做一個很酷的事情,就是找到原始評論和模型輸出之間的差異。我們將使用 RedLines Python 包來實現這個功能。我們將獲取評論的原始文本和模型輸出之間的差異,然后顯示出來。
from redlines import Redlinesdiff = Redlines(text,response)
display(Markdown(diff.output_markdown))
預期在下面可以看到原始評論和模型輸出之間的差異,以及已經糾正的內容(紅色)。我們在這里使用的提示是,校對并更正這篇評論。

你也可以做一些更戲劇性的改變,例如語氣的改變等等。讓我們再嘗試一下。
在這個提示中,我們要求模型校對和更正這篇相同的評論,但也要求對內容進行修改使其更有說服力,并確保它遵循 APA 風格。針對高級讀者。我們還將要求以 markdown 格式輸出。在這里我們使用與原始評論相同的文本。
prompt = f"""
proofread and correct this review. Make it more compelling.
Ensure it follows APA style guide and targets an advanced reader.
Output in markdown format.
Text: ```{text}```
"""response = get_completion(prompt)
display(Markdown(response))
我們來執行這個操作。
預期有一個擴展的 APA 樣式的評論,關于毛絨熊貓。如下:

這就是關于文本轉換任務的全部內容。接下來,我們將進行擴寫任務,我們將使用較短的提示,從語言模型中生成更長、更自由的響應。

:STM32F103加入AFIO控制器)

:TOGAF ADM架構愿景的核心價值)











)
)


