
自AlexNet贏得2012年ImageNet競賽以來,每個新的獲勝架構通常都會增加更多層數以降低錯誤率。一段時間內,增加層數確實有效,但隨著網絡深度的增加,深度學習中一個常見的問題——梯度消失或梯度爆炸開始出現。
梯度消失問題會導致梯度值變得非常小,幾乎趨近于零;而梯度爆炸問題則會導致梯度值變得非常大。這兩種情況都會增加訓練難度,并導致錯誤率上升,隨著層數的增加,模型在訓練和測試數據上的性能都會受到影響。
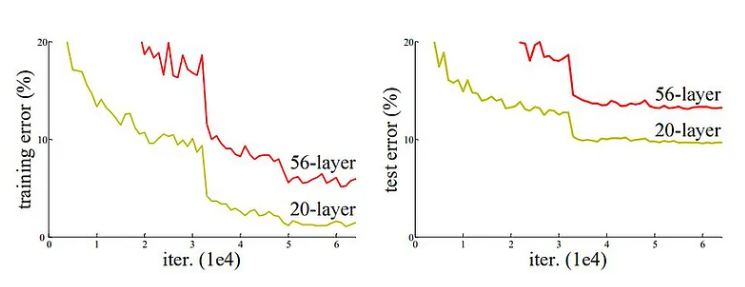
從下圖可以看出,20層CNN 架構在訓練和測試數據集上的表現均優于56層CNN架構。作者進一步分析了錯誤率,認為錯誤率是由梯度消失/爆炸引起的。
2015 年,微軟研究院提出了一個劃時代的網絡結構——ResNet(殘差網絡),并提出了一個非常簡單卻極其有效的思想:
“如果某些層學不到什么有用特征,那不如直接跳過它們。”
一、ResNet簡介
ResNet 的突破源于其使用了跳躍(或殘差)連接,解決了長期存在的梯度消失和爆炸問題。這些連接使 ResNet 成為第一個成功訓練超過 100 層的模型的網絡,并在 ImageNet 和COCO目標檢測任務上取得了最佳效果。
-
深度網絡的挑戰
在 ResNet 之前,非常深的神經網絡面臨兩大挑戰:
-
梯度消失:隨著網絡深度增加,反向傳播過程中的梯度值趨于減小。這會減慢前幾層的學習速度,從而限制網絡在深度增加時學習有用特征的能力。
-
梯度爆炸:有時,在非常深的網絡中,梯度會呈指數增長,導致數值不穩定,權重變得太大,從而導致模型失敗。
這些問題導致深層模型的性能不如淺層模型。這種現象被稱為“退化”,意味著添加更多層并不一定能提高準確率,反而往往會導致性能下降。
二、ResNet的創新點:跳過(殘差)連接
跳過連接(或殘差連接)的工作原理是,將較早層(例如,第 n-1 層)的輸出直接添加到較晚層(例如,第 n+1 層)的輸出。添加后,對結果應用 ReLU 激活函數。這意味著第 n 層實際上被“跳過”,從而使信息更容易在網絡中流動。
這里 f(Xn-1) 表示卷積層 (n-1) 的輸出被傳遞給 ReLU 激活函數
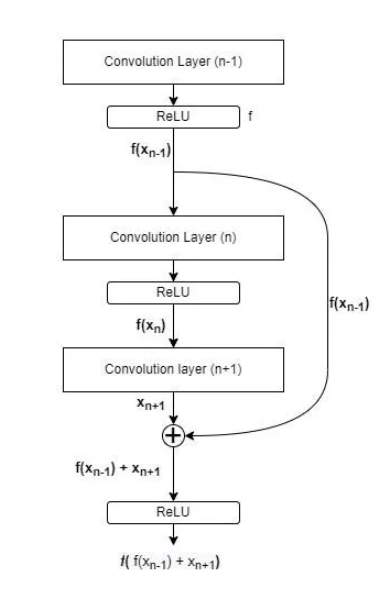
跳過連接的作用是確保即使第 n 層沒有學到任何有用的信息(或輸出為零),我們也不會丟失重要信息。相反,第 (n-1) 層的輸出會向前傳遞,并與第 (n+1) 層的輸出合并。
如果第 n 層沒有增加價值,網絡可以“跳過”它,從而保持一致的性能。如果兩層都提供了有用的信息,那么將它們結合起來,就能利用兩種信息源來提升網絡的整體性能。
三、Resnet 的架構
以下是 Resnet-18 的架構和層配置,取自研究論文《圖像識別的深度殘差學習》(論文地址:https://arxiv.org/abs/1512.03385)
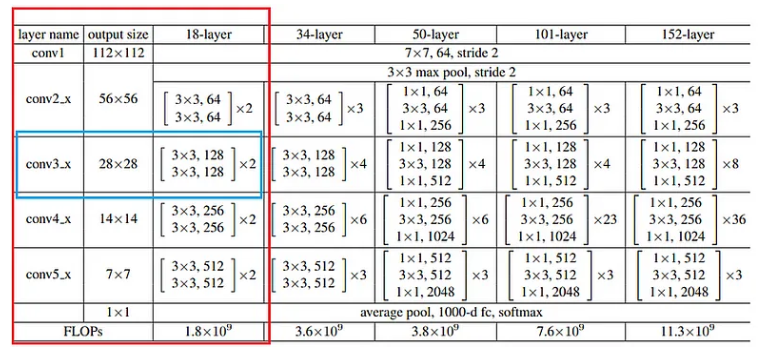
讓我們選擇 Conv3_x 塊,并嘗試了解其內部發生的情況。讓我們使用卷積塊和恒等塊來理解這一點。
-
卷積塊
目的:當輸入和輸出的尺寸(形狀)不同時,使用卷積塊,原因如下:
-
空間大小(特征圖的高度和寬度)的變化。
-
頻道數量的變化。
-
身份區塊
目的:當輸入和輸出的尺寸(形狀)相同時,使用身份塊,允許將輸入直接添加到輸出而無需任何轉換。
通過示例理解卷積和身份塊,使用卷積和身份塊的 Conv3_x 塊數據流
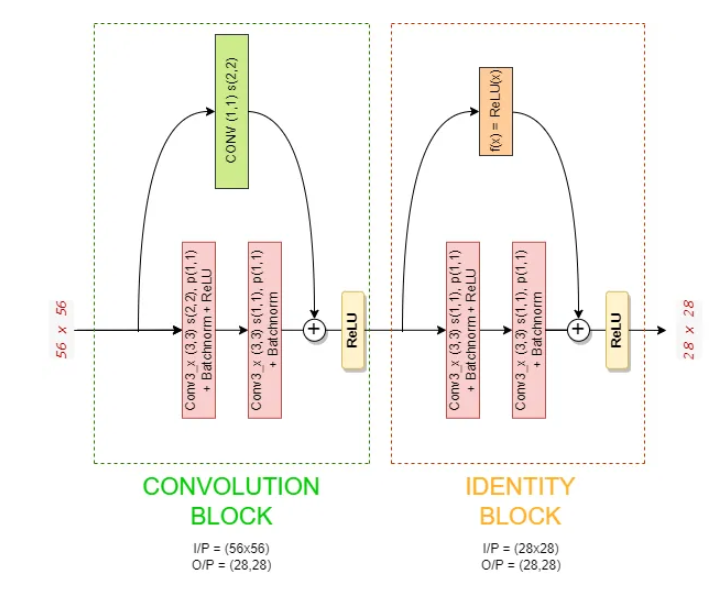
上圖告訴我們 56x56 圖像如何通過 Conv3_x 塊傳播的細節,現在我們將看看圖像在這些塊內的每個步驟中是如何轉換的。
-
代碼
class ResNet18(nn.Module):def __init__(self, n_classes):super(ResNet18, self).__init__()self.dropout_percentage = 0.5self.relu = nn.ReLU()# BLOCK-1 (starting block) input=(224x224) output=(56x56)self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(7,7), stride=(2,2), padding=(3,3))self.batchnorm1 = nn.BatchNorm2d(64)self.maxpool1 = nn.MaxPool2d(kernel_size=(3,3), stride=(2,2), padding=(1,1))# BLOCK-2 (1) input=(56x56) output = (56x56)self.conv2_1_1 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_1_1 = nn.BatchNorm2d(64)self.conv2_1_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_1_2 = nn.BatchNorm2d(64)self.dropout2_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-2 (2)self.conv2_2_1 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_2_1 = nn.BatchNorm2d(64)self.conv2_2_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm2_2_2 = nn.BatchNorm2d(64)self.dropout2_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-3 (1) input=(56x56) output = (28x28)self.conv3_1_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm3_1_1 = nn.BatchNorm2d(128)self.conv3_1_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_1_2 = nn.BatchNorm2d(128)self.concat_adjust_3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout3_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-3 (2)self.conv3_2_1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_2_1 = nn.BatchNorm2d(128)self.conv3_2_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm3_2_2 = nn.BatchNorm2d(128)self.dropout3_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-4 (1) input=(28x28) output = (14x14)self.conv4_1_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm4_1_1 = nn.BatchNorm2d(256)self.conv4_1_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_1_2 = nn.BatchNorm2d(256)self.concat_adjust_4 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout4_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-4 (2)self.conv4_2_1 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_2_1 = nn.BatchNorm2d(256)self.conv4_2_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm4_2_2 = nn.BatchNorm2d(256)self.dropout4_2 = nn.Dropout(p=self.dropout_percentage)# BLOCK-5 (1) input=(14x14) output = (7x7)self.conv5_1_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(3,3), stride=(2,2), padding=(1,1))self.batchnorm5_1_1 = nn.BatchNorm2d(512)self.conv5_1_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_1_2 = nn.BatchNorm2d(512)self.concat_adjust_5 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(1,1), stride=(2,2), padding=(0,0))self.dropout5_1 = nn.Dropout(p=self.dropout_percentage)# BLOCK-5 (2)self.conv5_2_1 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_2_1 = nn.BatchNorm2d(512)self.conv5_2_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3,3), stride=(1,1), padding=(1,1))self.batchnorm5_2_2 = nn.BatchNorm2d(512)self.dropout5_2 = nn.Dropout(p=self.dropout_percentage)# Final Block input=(7x7) self.avgpool = nn.AvgPool2d(kernel_size=(7,7), stride=(1,1))self.fc = nn.Linear(in_features=1*1*512, out_features=1000)self.out = nn.Linear(in_features=1000, out_features=n_classes)# ENDdef forward(self, x):# block 1 --> Starting blockx = self.relu(self.batchnorm1(self.conv1(x)))op1 = self.maxpool1(x)# block2 - 1x = self.relu(self.batchnorm2_1_1(self.conv2_1_1(op1))) # conv2_1 x = self.batchnorm2_1_2(self.conv2_1_2(x)) # conv2_1x = self.dropout2_1(x)# block2 - Adjust - No adjust in this layer as dimensions are already same# block2 - Concatenate 1op2_1 = self.relu(x + op1)# block2 - 2x = self.relu(self.batchnorm2_2_1(self.conv2_2_1(op2_1))) # conv2_2 x = self.batchnorm2_2_2(self.conv2_2_2(x)) # conv2_2x = self.dropout2_2(x)# op - block2op2 = self.relu(x + op2_1)# block3 - 1[Convolution block]x = self.relu(self.batchnorm3_1_1(self.conv3_1_1(op2))) # conv3_1x = self.batchnorm3_1_2(self.conv3_1_2(x)) # conv3_1x = self.dropout3_1(x)# block3 - Adjustop2 = self.concat_adjust_3(op2) # SKIP CONNECTION# block3 - Concatenate 1op3_1 = self.relu(x + op2)# block3 - 2[Identity Block]x = self.relu(self.batchnorm3_2_1(self.conv3_2_1(op3_1))) # conv3_2x = self.batchnorm3_2_2(self.conv3_2_2(x)) # conv3_2 x = self.dropout3_2(x)# op - block3op3 = self.relu(x + op3_1)# block4 - 1[Convolition block]x = self.relu(self.batchnorm4_1_1(self.conv4_1_1(op3))) # conv4_1x = self.batchnorm4_1_2(self.conv4_1_2(x)) # conv4_1x = self.dropout4_1(x)# block4 - Adjustop3 = self.concat_adjust_4(op3) # SKIP CONNECTION# block4 - Concatenate 1op4_1 = self.relu(x + op3)# block4 - 2[Identity Block]x = self.relu(self.batchnorm4_2_1(self.conv4_2_1(op4_1))) # conv4_2x = self.batchnorm4_2_2(self.conv4_2_2(x)) # conv4_2x = self.dropout4_2(x)# op - block4op4 = self.relu(x + op4_1)# block5 - 1[Convolution Block]x = self.relu(self.batchnorm5_1_1(self.conv5_1_1(op4))) # conv5_1x = self.batchnorm5_1_2(self.conv5_1_2(x)) # conv5_1x = self.dropout5_1(x)# block5 - Adjustop4 = self.concat_adjust_5(op4) # SKIP CONNECTION# block5 - Concatenate 1op5_1 = self.relu(x + op4)# block5 - 2[Identity Block]x = self.relu(self.batchnorm5_2_1(self.conv5_2_1(op5_1))) # conv5_2x = self.batchnorm5_2_1(self.conv5_2_1(x)) # conv5_2x = self.dropout5_2(x)# op - block5op5 = self.relu(x + op5_1)# FINAL BLOCK - classifier x = self.avgpool(op5)x = x.reshape(x.shape[0], -1)x = self.relu(self.fc(x))x = self.out(x)return x實現后,我們可以直接創建此類的對象并傳遞數據集的輸出類的數量,并使用它在任何圖像數據上訓練我們的網絡。
-
這些塊為什么有用?
-
卷積塊處理空間分辨率或通道數量的變化,同時保留殘差連接。
-
身份塊專注于在不改變輸入維度的情況下學習附加特征。
-
它們共同作用,允許梯度流,即使某些層不能有效學習,也能使深度網絡有效地訓練
四、ResNet為何成為經典
ResNet的成功,不在于它堆了多少層,而在于它對“深層神經網絡如何訓練”這個根本問題給出了一個優雅解法:如果學不會,就跳過去!
這種看似簡單的思想,卻釋放了深度學習的潛力,也為后續模型設計開辟了全新路徑,DenseNet、Mask R-CNN、HRNet、Swin Transformer……都離不開它的殘差思想。
所以,ResNet 不只是一種網絡架構,更是一種范式的轉變——這,正是它成為經典的原因。








植物應對干旱的生理學反應 | The physiology of plant responses to drought)




)

:Node.js 服務端核心邏輯實現)

(C/C++))


