25年3月來自北京通用 AI 國家重點實驗室、清華大學和北大的論文“ManipTrans: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning”。
人手在交互中起著核心作用,推動著靈巧機器人操作研究的不斷深入。數據驅動的具身智能算法需要精確、大規模、類似人類的操作序列,而這通過傳統的強化學習或現實世界的遙操作難以實現。為了解決這個問題,引入 MANIPTRANS,一種兩階段方法,用于在模擬中將人類的雙手技能有效地遷移到靈巧的機械手上。MANIPTRANS 首先預訓練一個通才軌跡模擬器來模仿手部運動,然后在交互約束下微調特定的殘差模塊,從而實現高效學習和復雜雙手任務的準確執行。實驗表明,MANIPTRANS 在成功率、保真度和效率方面均超越最先進的方法。利用 MANIPTRANS,將多個手-目標數據集遷移到機械手,創建 DEXMANIPNET 大型數據集,其中包含一些此前從未探索過的任務,例如蓋筆帽(pen capping)和擰開瓶子(bottle unscrewing)。DEXMANIPNET 包含 3.3K 個機器人操作場景,易于擴展,有助于進一步訓練靈巧手的策略,并實現實際部署。
近年來,具身人工智能 (EAI) 發展迅速,人們致力于使人工智能驅動的具身能夠與物理或虛擬環境交互。正如人手在交互中至關重要一樣,EAI 領域的許多研究也聚焦于靈巧機器人手操作 [4, 16– 22, 41, 46, 52, 58, 59, 63, 65, 66, 68, 70, 72, 75, 77, 81, 82, 104, 113, 115, 118, 130, 131]。在復雜的雙手任務中達到類似人類的熟練程度具有重要的研究價值,對于通用人工智能的進步至關重要。
因此,快速獲取精確、大規模、類人靈巧操作序列,用于數據驅動的具身智體訓練 [11, 12, 25, 83, 133] 變得越來越緊迫。一些研究使用強化學習 (RL) [54, 99] 來探索和生成靈巧的手部動作 [27, 69, 77, 111, 121, 135, 136],而另一些研究則通過遙操作收集人-機配對數據 [26, 44, 45, 82, 103, 113, 128]。這兩種方法都有局限性:傳統的 RL 需要精心設計、針對特定任務的獎勵函數 [78, 135],這限制可擴展性和任務復雜性;而遙操作則是勞動密集型且成本高昂的,只能產生特定于具身智體的數據集。一個有前景的解決方案是通過模仿學習 [71, 80, 93, 112, 139] 將人類操作動作遷移到模擬環境中的靈巧機械手上。這種方法有幾個優點。首先,模仿人類操作軌跡可以創建自然的手部與目標的交互,從而實現更流暢、更像人類的動作。其次,豐富的動作捕捉 (MoCap) 數據集 [10, 14, 32, 37, 39, 57, 62, 73, 74, 107, 119, 125, 134] 和手勢估計技術 [13, 43, 67, 87, 108, 120, 122–124, 126] 使得從人類演示中提取操作知識變得容易 [93, 102]。第三,模擬提供一種經濟高效的驗證方法,為現實世界的機器人部署提供捷徑 [41, 44, 51]。
然而,實現精確高效的遷移并非易事。如圖所示,人手和機械手之間的形態差異導致直接的姿態重定向效果不佳。此外,盡管 MoCap 數據相對準確,但在執行高精度任務時,誤差累積仍然可能導致嚴重故障。此外,雙手操作引入高維動作空間,顯著增加高效策略學習的難度。因此,大多數開創性工作通常停留在單手抓和舉的任務 [27, 111, 121, 135],而諸如擰開瓶子(bottle unscrewing)或蓋筆帽(pen capping)等復雜的雙手活動則基本未被探索。
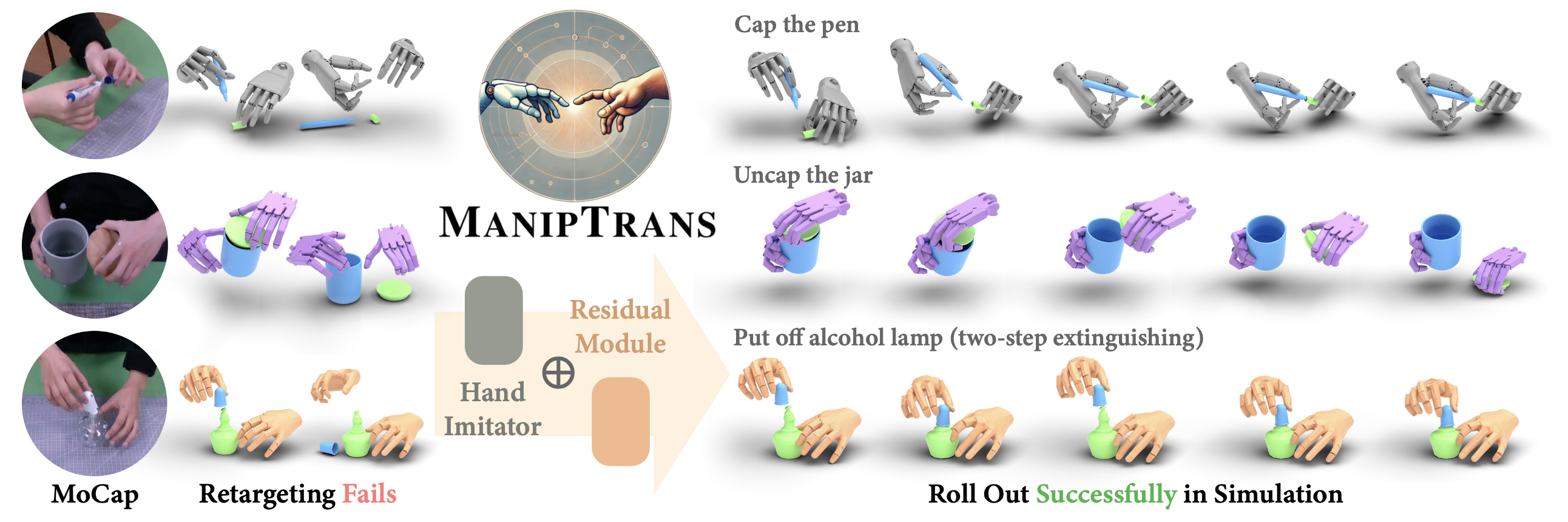
通過人類演示實現靈巧操作。從人類演示中學習操作技能,為將人類能力遷移給機器人提供一種直觀有效的方法 [6, 31, 129, 132]。模仿學習在實現這種遷移方面已顯示出巨大的潛力 [7, 23, 64, 71, 80, 89, 90, 109, 112, 139, 142]。近期研究重點關注學習由目標軌跡引導的強化學習策略 [21, 22, 72, 77, 142]。QuasiSim [72] 通過參數化的準物理模擬器將參考手部動作直接遷移到機械手,從而改進這種方法。然而,這些方法僅限于較簡單的任務,并且計算量巨大。最近,針對諸如雙手扭開蓋子之類的挑戰性任務,已經開發出使用特定任務獎勵函數的定制解決方案 [68, 70]。
靈巧手數據集。目標操作是具身智體的基礎。目前已有許多基于 MANO 的 [96] 手-目標交互數據集 [9, 10, 14, 28, 32, 36, 37, 39, 40, 42, 55, 57, 60–62, 73, 74, 93, 100, 107, 119, 125, 134, 141, 143]。然而,這些數據集通常優先考慮與二維圖像的姿態對齊,而忽略物理約束,從而限制它們在機器人訓練中的適用性。遙操作方法 [26, 44, 45, 92, 113, 117, 128, 140] 使用 AR/VR 系統 [15, 24, 30, 52, 86] 或基于視覺的動作捕捉 (MoCap) [94, 113, 114] 在線收集人-機的手匹配數據,以便在人類參與的情況下進行實時數據采集和校正。然而,遙操作勞動密集且耗時,而且缺乏觸覺反饋常常會導致動作僵硬、不自然,阻礙精細的操作。
殘差學習。由于強化學習訓練的樣本效率低下和耗時,殘差策略學習 [53, 98, 106](一種逐步改進動作控制的方法)被廣泛采用,以提高效率和穩定性。在靈巧手操作領域,多項研究探索針對特定任務的殘差策略 [5, 21, 29, 38, 98, 118, 138, 139]。例如,[38] 在殘差策略訓練期間集成用戶輸入,而 [51] 從人類示范中學習糾正動作。GraspGF [118] 采用預訓練的基于分數生成模型作為基礎,[21] 將模仿任務分解為手腕跟隨和手指運動控制,并集成殘差手腕控制策略。此外,[48] 利用殘差學習構建一個混合專家系統 [49],而 DexH2R [139] 將殘差學習直接應用于重定向的機器人手動作。
本文提出一種簡單但有效的方法,MANIPTRANS,有助于將手部操作技能(尤其是雙手動作)遷移到模擬中的靈巧機械手,從而能夠準確跟蹤參考運動。利用 MANIPTRANS 將多個具有代表性的手-目標操作數據集 [62, 134] 遷移到 Isaac Gym 模擬器 [79] 中的靈巧機械手,其構建 DEXMANIPNET 數據集,在運動保真度和順應性方面取得顯著提升。目前,DEXMANIPNET 包含 3.3K 個事件和 134 萬幀的機械手操作數據,涵蓋此前未曾探索過的任務,例如蓋筆帽(pen capping)、擰開瓶蓋(bottle unscrewing)和化學實驗。
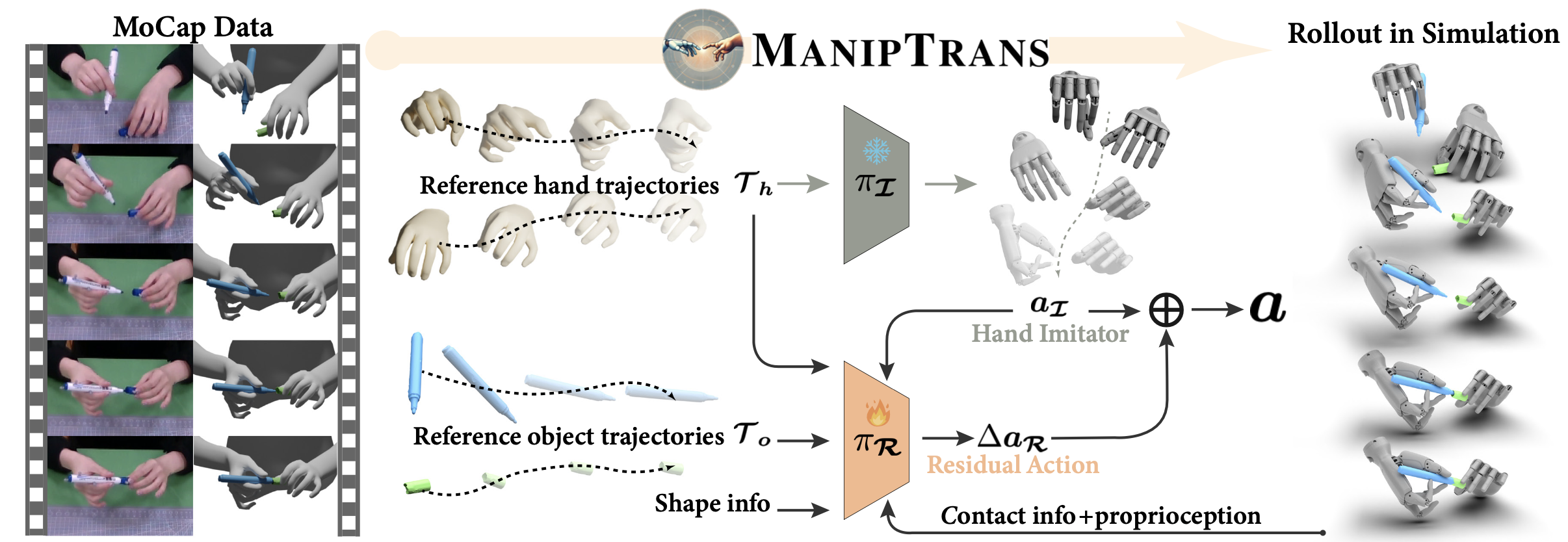
如圖所示概述本文方法。給定參考的人手-目標交互軌跡,目標是學習一種策略,使靈巧的機械手能夠在模擬中精確復制這些軌跡,同時滿足任務的語義操作約束。為此,提出一個兩階段框架:第一階段訓練通用的手部軌跡模仿模型;第二階段采用殘差模型將初始粗略運動細化為符合任務要求的動作。
準備工作
為了不失一般性,在一個復雜的雙手環境中構建操作遷移問題。其中左右靈巧手 d = {d_l, d_r} 旨在模擬人手 h = {h_l, h_r} 的行為。人手 h = {h_l, h_r} 與兩個目標 o = {o_l, o_r} 以協作的方式進行交互(例如,在筆帽任務中,一只手握住筆帽,另一只手握住筆身)。來自人類演示的參考軌跡定義為 T_h = {τt_h} 和 T_o = {τ^t_o},其中 T 表示總幀數。每只手的軌跡 τ_h 包括手腕的 6-DoF 姿態 w_h、線速度和角速度 w ?_h = {v_h, u_h},以及由 MANO [96] 定義的手指關節位置 j ?_h,以及它們各自的速度 j ?_h = {v_j, u_j};這里,F 表示手部關鍵點的數量,包括指尖。類似地,每個目標的目標軌跡 τ_o 包括其 6-DoF 姿態 p_o 以及相應的線速度和角速度 p ?_o = {v_o, u_o}。為了降低空間復雜度,對所有相對于靈巧手手腕位置的平移進行歸一化,同時保留原始旋轉以保持正確的重力方向。
將該問題建模為隱式馬爾可夫決策過程 (MDP) M = ?S, A, T, R, γ?,其中 S 表示狀態空間,A 表示動作空間,T 表示轉換動力學,R 表示獎勵函數,γ 表示折扣因子。每個靈巧手在時間 t 的動作記為 a_t,包括用于比例-微分 (PD) 控制的每個靈巧手關節 at_q 的目標位置(target position),以及施加于機器人手腕的 6-DoF 力 at_w,類似于先前的研究 [48, 111, 121],其中 K 表示機器人手旋轉關節的總數(即 DoF)。本文方法將遷移過程分為兩個階段:1)預訓練的純手軌跡模仿模型 I;2)殘差模塊 R,用于微調粗略動作以確保任務合規性。每個階段在時間 t 的狀態分別定義為 st_I 和 st_R,對應的獎勵函數分別為 rt_I = R(st_I, at_I) 和 rt_R = R(st_R, a^t_R)。對于這兩個階段,都采用近端策略優化 (PPO) [99] 來最大化折扣獎勵,這也借鑒先前的方法 [19, 89]。
手部軌跡模仿
在此階段,目標是學習一個通用的手部軌跡模仿模型 I,使其能夠精確復制人類手指的精細運動。每個靈巧手在時間 t 的狀態定義為 st_I = {τt_h, st_prop},其中包括目標手部軌跡 τt_h 和當前本體感覺 st_prop = {qt_d, q ?t_d, wt_d, w ?t_d}。其中,qt_d 和 wt_d 分別表示關節角度和手腕姿勢,以及它們對應的速度。目標是使用強化學習訓練策略 π_I (at | st_I, at?1),以確定動作 a^t_I。
獎勵函數。獎勵函數 rt_I 旨在鼓勵靈巧手跟蹤參考手軌跡 τt_h,同時確保穩定性和平滑度。它包含三個部分:1)腕部跟蹤獎勵 rt_wrist:此獎勵最小化差異 wt_d ? wt_h 和 w ?t_d ? w ?t_h,? 表示 SE(3) 空間中的差異。2)手指模仿獎勵 rt_finger:此組件鼓勵靈巧手緊密跟隨參考手指關節位置。手動選擇與 MANO 模型相對應的靈巧手上 F 個手指關鍵點,表示為 j_d。權重 w_f 和衰減率 λ_f 根據經驗設置,以強調指尖,特別是拇指、食指和中指的指尖。這種設計有助于減輕人手和機器手之間形態差異的影響。3) 平滑度獎勵 rt_smooth:為了緩解運動不順暢的問題,引入平滑度獎勵,懲罰施加在每個關節上的力,其定義為關節速度和力矩的逐元乘積,類似于 [76] 中的方法。總獎勵定義為:rt_I = w_wrist · rt_wrist + w_finger · rt_finger + w_smooth · r^t_smooth。
訓練策略。將手的模仿與目標交互分離,提供額外的優勢;具體來說,π_I 不需要難以獲取的操作數據。使用純手數據集訓練該策略,包括現有的手動作集合 [14, 36, 62, 107, 134, 137, 144] 和通過插值生成的合成數據 [105]。為了平衡左右手之間的訓練數據,將這些數據集鏡像。為了提高效率,采用參考狀態初始化 (RSI) 和提前終止 [88, 89] 的技術。如果靈巧手關鍵點 j_d 的偏差超過閾值 ε_finger,則該回合將提前終止并重置為隨機采樣的 MoCap 狀態。還利用課程學習 [8],逐漸降低 ε_finger 以鼓勵廣泛的探索,然后專注于細粒度的手指控制。
殘差學習在交互中的應用
基于預訓練的π_I,使用殘差模塊 R 來細化粗略動作并滿足特定任務的約束。
狀態空間擴展在交互中的應用。為了解釋靈巧手與目標之間的交互,通過合并與交互相關的其他信息,將狀態空間擴展到手相關狀態st_I之外。首先,從 MoCap 數據中計算物體網格 o 的凸包[116],以在模擬環境中生成可碰撞目標 o?。為了沿著參考軌跡 T_o 操縱目標,引入目標的位置 p_o?(相對于手腕位置 w_d)和速度 p ?_o?、質心m_o? 和重力矢量 G_o?。為了更好地編碼目標的形狀,利用 BPS 表征[91]。此外,為了增強感知,使用距離度量 D(j^t_d, p^t_o?) 來編碼雙手與目標之間的空間關系,該度量測量靈巧手關鍵點與目標位置之間的平方歐氏距離。此外,還明確包含從模擬中獲得的接觸力 C,以捕捉指尖與目標表面之間的相互作用。這種觸覺反饋對于穩定的抓握和操控至關重要,可確保在復雜任務中實現精確控制。
殘差動作組合策略。給定組合狀態 st_R = st_I ∪ st_interact,目標是學習殘差動作 ?at_R,以改進初始模仿動作 at_I,確保符合任務要求。在操作過程的每個步驟中,首先采樣模仿動作 at_I ~ π_I (at |st_I, at?1)。在此動作的條件下,再采樣殘差校正 ?at_R ~ π_R (?at |st_R, at_I, at?1)。最終動作計算為:at = at_I + ?at_R,其中殘差動作逐元素相加。然后對得到的動作 a^t 進行裁剪,使其符合靈巧手的關節極限。在訓練開始時,由于靈巧手動作已經近似于參考手軌跡,因此殘差動作預計接近于零。這種初始化有助于防止模型崩潰并加速收斂。通過使用零均值高斯分布初始化殘差模塊,并采用預熱策略逐步激活其訓練,來實現這一點。
獎勵函數。目標是以與任務無關的方式將人類的雙手操作技能高效地遷移到靈巧的機械手上。為此,避免針對特定任務的獎勵工程,盡管這有利于單個任務,但可能會限制泛化。因此,獎勵設計保持簡單且通用。除了手模仿獎勵 rt_I 之外,還引入兩個附加組件:1) 目標跟蹤獎勵 rt_object:最小化模擬目標與其參考軌跡之間的位置和速度差異,具體而言,pt_o? ? pt_o 和 p ?t_o? ? p ?t_o。 2) 接觸力獎勵 rt_contact:當 MoCap 數據集中手與目標之間的距離低于指定閾值 ξ_c 時,鼓勵施加適當的接觸力。該獎勵取決于 D(jt_h_f, pt_o · o),即指尖 h_f 與變換后的目標表面之間最小距離,和 Ct_d_f,即指尖處的接觸力。殘差階段的總獎勵定義為 rt_R = rt_I + w_object · rt_object + w_contact · r^t_contact。
訓練策略。受先前研究 [72, 84, 85] 的啟發,該研究利用準物理模擬器在訓練過程中放松約束并避免局部最小值,在殘差學習階段引入一種放松機制。與采用自定義模擬的 [72] 不同,其直接在 Isaac Gym 環境 [79] 中調整物理約束,以提高訓練效率。具體來說,最初將引力常數 G 設置為零,并將摩擦系數 F 設置為一個較高的值。這種設置使機械手在訓練早期能夠牢固地抓握目標并有效地與參考軌跡對齊。隨著訓練的進展,逐漸將 G 恢復到其真實值,并將 F 降低到合適的值,以近似真實的交互。與模仿階段類似,采用 RSI、提前終止和課程學習策略。每個episode 都通過從預處理軌跡中隨機選擇一個非碰撞的近目標狀態來初始化機械手。在訓練期間,如果目標的姿態 pt_o? 偏離預定義閾值 ε_object,則 episode 會提前終止。逐步降低 ε_object 以鼓勵更精確的目標操作。此外,引入接觸終止條件:如果 MoCap 數據顯示人手牢牢抓握(即 D(jt_h_f, pt_o · o) < ξ_t,其中 ξ_t 為終止閾值),則接觸力 C^t_d_f 必須非零。不滿足此條件則會導致提前終止。此機制確保智體學習控制接觸力,從而實現穩定的目標操控。
DEXMANIPNET 數據集
使用 MANIPTRANS 生成 DEXMANIPNET 數據集,該數據集源自兩個具有代表性的大規模手-目標交互數據集:FAVOR [62] 和 OakInk-V2 [134]。FAVOR 采用基于 VR 的遙操作技術,并結合人-在-環校正,專注于目標重排列等基礎任務。相比之下,OakInk-V2 采用基于光學追蹤的動作捕捉技術,專注于更復雜的交互,例如蓋筆帽和擰開瓶子。
由于靈巧機械手缺乏標準化,采用 Inspire Hand [3] 作為主要平臺,因為它具有高靈活性、穩定性、成本效益以及廣泛的先前應用 [24, 35, 52]。為了解決雙手任務的復雜性,采用模擬的 12 自由度 Inspire Hand 配置,與現實世界的 6 自由度機制相比,其靈活性更高。
DEXMANIPNET 涵蓋 [134] 中定義的 61 個多樣化且具有挑戰性的任務,包括 3.3K 個機械手操作場景,涉及 1.2K 個目標,總計 134 萬幀,其中包括 ~ 600 個涉及復雜雙手任務的序列。每個場景在 Isaac Gym 模擬中執行精確 [79]。相比之下,最近通過自動增強生成的數據集 [52] 僅包含 9 個任務的 60 個來源人類演示。
在 MANIPTRANS 中,對每個靈巧機械手,手動選擇 F = 21 個關鍵點,分別對應人手的指尖、手掌和指骨位置,以減輕形態差異。對于訓練,用課程學習策略。初始閾值 ε_finger 設置為 6 厘米,然后衰減到 4 厘米。目標對齊閾值 ε_object 起始于 90° 和 6 厘米(用于旋轉和平移),逐漸減小到 30° 和 2 厘米。用 Actor-Critic PPO 算法 [99] 訓練模仿模塊 I 和殘差模塊 R,訓練范圍為 32 幀,小批量大小為 1024,折扣因子 γ = 0.99。優化采用 Adam [56],初始學習率為 5 × 10^?4,并采用衰減調度程序。所有實驗均在 Isaac Gym [79] 中進行,在配備 NVIDIA RTX 4090 GPU 和 Intel i9-13900KF CPU 的個人計算機上以 1/60 秒的時間步長模擬 4096 個環境。
如圖所示,使用兩個 7 自由度 Realman 機械臂 [95] 和一對升級版 Inspire 機械手(配置相同,但增加觸覺傳感器)進行實驗。為了彌補模擬的 12 自由度機械手與 6 自由度真實硬件之間的差距,采用一種基于擬合的方法,優化真實機器人的關節角度 q_d ?(表示為 ?·)以實現指尖對齊,并額外增加時間平滑度損失。通過求解逆運動學來控制機械臂,使機械臂的凸緣(flange)與靈巧手的手腕 w_d 對齊。在回放過程中,不會強制執行嚴格的時間對齊,因為真實機器人的操作速度并不總是像人手那樣快。



)

:Node.js 服務端核心邏輯實現)

(C/C++))









)


