文章目錄
- 前言
- 理論部分
- 堆的模擬實現:(這里舉的大根堆)
- 堆的創建
- 二叉樹的遍歷
- 二叉樹的一些其他功能實現
- 作業部分
前言
這期的話講解的是堆和二叉樹的理論部分和習題部分
理論部分
二叉樹的幾個性質:1.對于任意一個二叉樹,度為0的節點比度為2的節點多一個
2.對于完全二叉樹,度為1的節點要么是1,要么是03.表示二叉樹的值在數組位置中父子下標關系:parent = (child-1)/2 leftchild = parent
*2+1 rightchild = parent*2+2前提:二叉樹的根節點是下標為0,是第1個
此外,數組存儲二叉樹只適合完全二叉樹(較滿的),不然浪費的空間太多了
二叉樹的第n層有2n-1個節點
節點的個數=邊數+1 邊數 = 節點的度相加之和
陌生的名詞:
樹度:也就是樹的度,是樹中節點度的最大值
堆是完全二叉樹
小根堆:樹中所有的父親的值都小于等于孩子(最小的在根節點)
大根堆:樹中所有的父親的值都大于等于孩子(最大的在根節點)
跟二叉搜索樹要區分一樣(那個對左右孩子放法也有要求)
堆的模擬實現:(這里舉的大根堆)
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>// 大堆
typedef int HPDataType;
typedef struct Heap
{HPDataType* a;int size;int capacity;
}HP;void HeapInit(HP* php);
void HeapPush(HP* php, HPDataType x);
void HeapPop(HP* php);
int HeapSize(HP* php);
void AdjustUp(HPDataType* a, int child);
void AdjustDown(HPDataType* a, int n, int parent);
void Swap(HPDataType* p1, HPDataType* p2);void HeapInit(HP* php)
{assert(php);php->a = (HPDataType*)malloc(sizeof(HPDataType)*4);if (php->a == NULL){perror("malloc fail");return;}php->size = 0;php->capacity = 4;
}void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType x = *p1;*p1 = *p2;*p2 = x;
}
// 除了child這個位置,前面數據構成堆
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;//while (parent >= 0)while(child > 0){if (a[child] > a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
void HeapPush(HP* php, HPDataType x)
{assert(php);if (php->size == php->capacity){HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * php->capacity*2);if (tmp == NULL){perror("realloc fail");return;}php->a = tmp;php->capacity *= 2;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size - 1);
}
注意:這種模擬實現操作的php->a[php->size]還沒存數據
如果要是小堆的話,就把判斷條件的的a[child]>a[parent]改成a[child]<a[parent]即可
// 左右子樹都是大堆/小堆
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){// 選出左右孩子中大的那一個if (child + 1 < n && a[child+1] < a[child]){++child;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}void HeapPop(HP* php)
{assert(php);assert(!HeapEmpty(php));//這種一般表示為空就報錯// 刪除數據Swap(&php->a[0], &php->a[php->size - 1]);php->size--;AdjustDown(php->a, php->size, 0);
}int HeapSize(HP* php)
{assert(php);return php->size;
}
上面AdjustDown里面的n表示的是數組的長度
size表示當前已存長度 size-1時那個最后的下標 size是還沒存數據的那個的下標
堆的創建
想給數組排升序的話,要建大堆去搞
代碼實現:(這里的時間復雜度是N*logN)
void HeapSort(int*a,int n)
{
//向下調整建堆:
for(int i = (n-1-1)/2;i>=0;--i)
AdjustDown(php->a,php->size,i);int end = n-1;
while(end>0){Swap(&a[end],&a[0]);AdjustDown(a,end,0);
--end;}}
建堆方式有兩種:(N為節點個數)
1.向上調整建堆 時間復雜度為N*logN
2.向下調整建堆 時間復雜度為N(一般用這個)
這里的數組是從0開始存數的
向上調整建堆代碼實現:
for(int i = 1;i<n;i++)
Adjustup(a,i);向下調整建堆代碼實現:
for(int i = (n-1-1)/2;i>=0;--i)
AdjustDown(php->a,php->size,i);
TOPK問題:即求數據結合中前K個最大的元素或者最小的元素(一般情況下數據量都比較大)
方法:
1.用數據集合中的前k個來建堆a.求前k個最大的元素,需要建小堆b.求前k個最小的元素,需要建大堆
2.用剩余的N-k個元素依次和堆頂元素來比較還要向下調整,滿足則替換堆頂元素
這里的滿足是指比小堆堆頂大,比大堆堆頂小
二叉樹的遍歷
二叉樹的遍歷:
1.前序遍歷:根左右
2.中序遍歷:左根右
3.后序遍歷:左右根
(前中后是針對的根,左右的關系全是左在右的左邊)
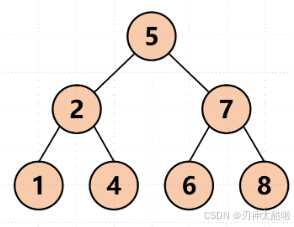
這里拿中序遍歷來舉例理解:對于每一棵樹,都先去遍歷他的左子樹,然后再寫他的根,然后再遍歷其右子樹
比如下面這個圖:就是 1 2 4 5 6 7 8
(用代碼寫的話,沒有的位置要寫NULL來代替,比如1的兩個子樹是NULL)4.層序遍歷:就是每層從左到右,然后一層遍歷完了就去下一層
代碼實現:
struct BTNode{TreeData data;struct BTNode *left;struct BTNode *right;};void PreOrder(BTNode* root) {if (root == NULL) {printf("NULL ");return;}printf("%d ", root->data);PreOrder(root->left);PreOrder(root->right);
}//先序遍歷void InOrder(BTNode* root) {if (root == NULL) {printf("NULL ");return;}InOrder(root->left);printf("%d ", root->data);InOrder(root->right);
}//中序遍歷void PostOrder(BTNode* root)
{if (root == NULL){printf("NULL ");return;}PostOrder(root->left);PostOrder(root->right);printf("%d ", root->data);
}//后序遍歷void LevelOrder(BTNode* root)
{Queue q;QueueInit(&q);if (root)QueuePush(&q, root);while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);printf("%d ", front->data);if(front->left)QueuePush(&q, front->left);if (front->right)QueuePush(&q, front->right);}QueueDestroy(&q);
}//堆的層序遍歷:就是打印一個節點之后,把他的孩子節點加進隊列中去注意:一般題目是不要那個printf("NULL");的
自己這個方法遍歷是會出現NULL的,要注意二叉樹的一些其他功能實現
二叉樹的銷毀
void TreeDestory(BTNode* root)
{if (root == NULL)return;TreeDestory(root->left);TreeDestory(root->right);free(root);
}求二叉樹節點的個數
int TreeSize(BTNode* root)
{return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;//可以這樣寫,不用續行符
}求二叉樹的深度
int TreeHeight(BTNode* root)
{if (root == NULL)return 0;int leftHeight = TreeHeight(root->left);int rightHeight = TreeHeight(root->right);return leftHeight > rightHeight ? leftHeight + 1 : rightHeight + 1;
}//遞歸如果不好想的話要畫圖去理解特別注意,不要寫成這樣:
//int TreeHeight(BTNode* root)
//{//if (root == NULL)// return 0;//return TreeHeight(root->left) > TreeHeight(root->right)// ? TreeHeight(root->left) + 1 : TreeHeight(root->right) + 1;
//}
這樣寫的話會求很多次eg:TreeHeight(root->left)求二叉樹第k層有多少個節點
int TreeKLevel(BTNode* root, int k)//剛開始傳進來的是根節點
{assert(k > 0);if (root == NULL)return 0;if (k == 1)return 1;return TreeKLevel(root->left, k - 1)+ TreeKLevel(root->right, k - 1);
}二叉樹查找首個值為x的結點(先序遍歷的話)
BTNode* TreeFind(BTNode* root, BTDataType x)
{if (root == NULL)return NULL;if (root->data == x)return root;BTNode* lret = TreeFind(root->left, x);if (lret)return lret;//這個辦法好,解決了遞歸深層的想return出去的東西出不去的問題BTNode* rret = TreeFind(root->right, x);if (rret)return rret;return NULL;
}判斷二叉樹是否是完全二叉樹
bool TreeComplete(BTNode* root)
{
//把二叉樹放入隊列Queue q;QueueInit(&q);if (root)QueuePush(&q, root);while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front == NULL){break;//這里不是continue,遇到第一個NULL就可以停了}else{QueuePush(&q, front->left);QueuePush(&q, front->right);}}//判斷是不是完全二叉樹while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);// 后面有非空,說明非空節點不是完全連續if (front){QueueDestroy(&q);return false;}}QueueDestroy(&q);//free空指針也沒事return true;
}
全局變量定義在函數聲明后面,函數定義前面的話,可以直接在函數里面用
局部變量的話不行,必須傳參過去(只用在函數調用之前生成就行了)
工程中很少用全局變量和靜態變量(如果用了,要特別注意),一般用指針去代替
關于續行符:一般只有字符串需要使用續行符
作業部分
在用樹表示的目錄結構中,從根目錄到任何數據文件,有(A)通道
A.唯一一條
B.二條
C.三條
D.不一定
下列關鍵字序列中,序列(D )是堆。
A.{16,72,31,23,94,53}
B.{94,23,31,72,16,53}
C.{16,53,23,94,31,72}
D.{16,23,53,31,94,72}
這種題的話是把這些數據從左到右來按堆從上到下去排
力扣 單值二叉樹
力扣 單值二叉樹
做法:遍歷二叉樹,然后讓左右節點和自己的根節點比較(注意考慮節點為NULL的情況!)代碼實現:
bool isUnivalTree(struct TreeNode* root) {if(root == NULL){return true;}if(root->left){if(root->val!=root->left->val)return false;}if(root->right){if(root->val!=root->right->val)return false;}return isUnivalTree(root->left)&&isUnivalTree(root->right);}
力扣 相同的樹
力扣 相同的樹(這個好)
注意:不能對NULL進行解引用和->
做法:要單獨檢驗是否為空 然后遞歸return的是左子樹相等&&右子樹相等
代碼實現:
bool isSameTree(struct TreeNode*p,struct TreeNode*q)
{
//兩個都為空if(p == NULL&&q == NULL) return true;
//一個為空if(p == NULL ||q == NULL) return false;
//都不為空
if(p->val!=q->val) return false;return isSameTree(p->left,q->left)&&isSameTree(p->right,q->right);}
力扣 對稱二叉樹
做法;把除根外的二叉樹分成兩部分,然后把isSameTree的最后一句改成
return isSameTree(p->left,q->right)&&isSameTree(p->right,q->left);即可
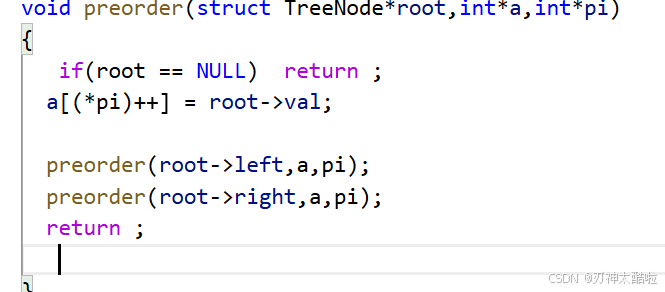
力扣 前序遍歷
力扣 前序遍歷
注意:a[(*pi)++]的這個括號不能省略 那個pi要是指針才對
下面這個只是代碼的一部分
要注意的是,題目要求的返回值要是int*類型的,那就要返回數組名了
延伸出的一些問題:1.指針在定義和初始化一起搞的時候,eg:int*pi,要給他賦值地址才行,并且指針要是不初始化的話是不行的,要么就malloc一下,要么就給他一個量(不能是字面常量)的地址
2.void類型的自定義函數的返回只能返回return ;不能return 0;
代碼實現:
int TreeSize(struct TreeNode* root)
{return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;//可以這樣寫,不用續行符
}
void preorder(struct TreeNode*root,int*a,int*pi)
{if(root == NULL) return ;a[(*pi)++] = root->val;preorder(root->left,a,pi);preorder(root->right,a,pi);return ;}int* preorderTraversal(struct TreeNode* root, int* returnSize) {* returnSize = TreeSize(root);int *a = malloc(*returnSize * sizeof(int));int*pi = malloc(sizeof(int*));*pi = 0;preorder(root,a,pi);
return a;
}
力扣 另一棵樹的子樹
力扣 另一棵樹的子樹
做法:把左邊樹的每一個結點對應的樹跟目標樹比較
(這里的isSameTree是自己實現的比較兩個樹相等的)
代碼實現:
bool isSameTree(struct TreeNode*p,struct TreeNode*q)
{
//兩個都為空if(p == NULL&&q == NULL) return true;
//一個為空if(p == NULL ||q == NULL) return false;
//都不為空
if(p->val!=q->val) return false;return isSameTree(p->left,q->left)&&isSameTree(p->right,q->right);}bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot) {if(root == NULL) return false;if(isSameTree(root,subRoot)) return true;
return isSubtree(root->left,subRoot)||isSubtree(root->right,subRoot);
}
錯誤寫法:
bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot) {if(root == NULL) return false;isSubtree(root->left,subRoot);isSubtree(root->right,subRoot);//中間這兩步讓程序經過了正確的,但沒有返回值產生反饋return isSameTree(root,subRoot);
}
牛客網 KY11二叉樹遍歷
牛客網 KY11二叉樹遍歷
注意:這題要求打印中序遍歷,但是給的是前序遍歷的數組,要注意
易忘把樹連接起來:
root->left = PreOrder(); // 構建左子樹
root->right = PreOrder(); // 構建右子樹
//轉換成二叉樹的代碼:
BTNode* PreOrder() {if (i >= s1.size()) return NULL;char ch = s1[i++];if (ch == '#') return NULL;//還是要轉換成NULLBTNode* node = (BTNode*)malloc(sizeof(BTNode));node->data = ch;node->left = PreOrder(); // 構建左子樹node->right = PreOrder(); // 構建右子樹return node;
}
代碼實現:
#include<bits/stdc++.h>
using namespace std;
string s1;
int i;
struct BTNode{char data;struct BTNode *left;struct BTNode *right;};
BTNode* PreOrder() {if (i >= s1.size()) return NULL;char ch = s1[i++];if (ch == '#') return NULL;BTNode* node = (BTNode*)malloc(sizeof(BTNode));node->data = ch;node->left = PreOrder(); // 構建左子樹node->right = PreOrder(); // 構建右子樹return node;
}void InOrder(BTNode* root) {if (root == NULL) {return;}InOrder(root->left);printf("%c ", root->data);InOrder(root->right);
}int main()
{cin>>s1;BTNode*root = PreOrder();InOrder(root);return 0;
}
引伸:開辟的空間不會因為函數的結束而自動銷毀,只有程序結束才會自動銷毀
如果一顆二叉樹的前序遍歷的結果是ABCD,則滿足條件的不同的二叉樹有( B)種
A.13
B.14
C.15
D.16
技巧:可以先判斷出二叉樹的層數
假設有n個節點(不包含NULL),可以算出層數范圍
一棵非空的二叉樹的先序遍歷序列與后序遍歷序列正好相反,則該二叉樹一定滿足( C)
A.所有的結點均無左孩子
B.所有的結點均無右孩子//是錯的,因為在子樹只有一個孩子時,取左和取右是都是成立的
C.只有一個葉子結點
D.至多只有一個結點
已知某二叉樹的中序遍歷序列為JGDHKBAELIMCF,后序遍歷序列為JGKHDBLMIEFCA,
則其前序遍歷序列為(B)
A.ABDGHJKCEFILM
B.ABDGJHKCEILMF
C.ABDHKGJCEILMF
D.ABDGJHKCEIMLF通用做法:像這種題的話,一般來說,都是中序遍歷用來確定根的左右區間有啥先或者后序遍歷用來確定每個"子樹"的根是啥
eg:
A的左子樹:JGDHKB A的右子樹:ELIMCFA的左子樹的根:B …………B的左子樹:JGDHK B的右子樹:空 (因為JGDHKB 在B右邊的為空) ……………………
B的左子樹的根為:D …………









)









