Crawl4AI 部署安裝及 n8n 調用,實現自動化工作流(保證好使)
簡介
Crawl4AI 的介紹
一、Crawl4AI 的核心功能
二、Crawl4AI vs?Firecrawl
Crawl4AI 的本地部署
一、前期準備
二、部署步驟
1、檢查系統的網絡環境
2、下載 Crawl4AI 源碼
3、Crawl4AI 環境變量與配置文件的修改
4、啟動 Crawl4AI
5、啟動 Crawl4AI(不使用 Docker Compose)
n8n 的調用
1、獲取網站的 sitemap.xml
2、在 n8n 中創建一個聊天消息觸發器,用于傳入對應的 sitemap.xml 的 URL
3、在 n8n 中獲取 sitemap.xml 并把 XML 格式轉化為 JSON 格式
4、對數據進行分割處理并限制 URL 數量
5、循環處理過濾后的每個 URL 并為每個 URL 生成 task_id
6、執行 task_id 指定的任務
7、對執行結果進行判斷并執行不同的動作
8、把輸出結果生成文件并映射到宿主機指定目錄
備份與加載 Crawl4AI 的鏡像
一、備份?Crawl4AI 的鏡像
二、加載 Crawl4AI 的鏡像
簡介
????????在大語言模型(LLM)和生成式 AI 爆發的今天,數據采集的效率與質量直接決定了 AI 應用的落地效果。傳統爬蟲工具在動態渲染處理、AI 友好輸出和大規模部署上的局限性日益凸顯,而專為 AI 設計的 Crawl4AI 框架正成為企業級數據管道的首選方案。
Crawl4AI 的介紹
????????Crawl4AI 是基于 Python 開發的開源智能爬蟲框架,其核心設計理念是“為 AI 應用構建專屬數據通道”。架構層面采用分層設計:
- 調度層:基于 asyncio 的自適應并發調度器,支持動態調整爬取并發數(單實例可穩定處理 5000 + 并發請求)
- 渲染層:深度集成 Playwright(默認)/Selenium,支持無頭 / 有頭模式,內置反反爬機制(UA 隨機化、請求間隔動態調整)
- 提取層:創新性引入 LLM 驅動的智能提取引擎,支持通過自然語言指令(如 "提取頁面中所有產品價格")生成結構化數據
- 輸出層:原生支持 Markdown/JSON/CSV 格式輸出,特別適配 LLM 的上下文輸入要求
一、Crawl4AI 的核心功能
| 功能模塊 | 技術實現 | 應用價值 |
|---|---|---|
| 動態渲染支持 | Playwright 內核,支持 JavaScript 完全執行,頁面加載超時智能重試(默認 3 次) | 完美處理 SPA 單頁應用、動態加載內容(如電商詳情頁、瀑布流頁面) |
| 智能數據提取 | 支持 JSON Schema/CSS 選擇器 / LLM 指令三種提取策略,內置正則表達式增強模塊 | 非技術人員可通過自然語言指令完成復雜數據提取,降低開發門檻 50% 以上 |
| 分布式部署 | 原生支持 Docker/Kubernetes,提供 Helm Chart 模板,支持分布式任務隊列(Redis/RabbitMQ) | 輕松擴展至數百節點集群,滿足日均億級頁面爬取需求 |
| 反爬機制 | 隨機 UA 池(內置 500 + 真實 UA)、代理 IP 輪換(支持 HTTP/SOCKS5)、請求間隔抖動算法 | 有效繞過 90% 以上的反爬系統,爬取成功率提升至 98% |
二、Crawl4AI vs?Firecrawl
????????Crawl4AI 與 Firecrawl 這兩個都是開源的爬蟲框架,但是他們之間會存在一些差異,主要體現在核心定位的不同
| 維度 | Crawl4AI | Firecrawl |
|---|---|---|
| 設計目標 | 面向 AI 應用的數據采集管道,深度適配 LLM 輸入要求 | 通用型爬蟲框架,側重基礎爬取功能 |
| 核心優勢 | LLM 智能提取、云原生部署、自適應并發調度 | 輕量級設計、快速原型開發 |
| 技術棧 | Python(asyncio/Playwright) | Python(Scrapy/Selenium) |
| 學習曲線 | 中高(需掌握 AI 提取策略) | 中等(傳統爬蟲語法) |
Crawl4AI 的本地部署
一、前期準備
環境要求:
| 組件 | 最低配置 | 推薦配置 |
|---|---|---|
| 操作系統 | Windows 10+/macOS 12+/Linux | Ubuntu 22.04+ |
| Python 版本 | 3.9+ | 3.11+ |
| 內存 | 8GB | 16GB+ |
| 存儲 | 50GB SSD | 200GB NVMe |
網絡環境:
- 本地網絡:部署時可以使用 VMware 的 NAT 模式,如果只是本機使用就已經無需調整了,如果是需要內網中為其他設備提供服務,那就需要配置成 bridge(橋接)模式了;如果使用 Docker 部署,可以直接通過使用 Docker Desktop 的默認網絡使用即可。
- 外部網絡:我們是把 Crawl4AI 部署在 Docker 中,所以構建時需要從網絡上拉去鏡像,國內雖然有鏡像源,但是并沒有外面的全,而且通常 github 上的 Dockerfile 都是使用 docker.io 這個官方源去拉取的,所以可能會導致超時導致構建失敗,所以提前準備一個靠譜的代理(科學上網)是非常必要的。
docke?r 的安裝:
? ? ? ? 關于 Linux 中 do?cker 的安裝在這里就不進行細說了,可以跟著這篇博客來操作:Ubuntu使用國內源安裝Docker,Mysql,Redis_ubuntu docker 國內源-CSDN博客
二、部署步驟
????????Crawl4AI 可以使用 Python 和 Docker 來部署,推薦使用 Docker 來進行部署,本篇也會基于 Docker 部署的方式來介紹部署步驟。
? ? ? ? Python 部署的方式可以看這個鏈接:Crawl4AI 的 Python 部署方法。
? ? ? ? 本次演示將會在 Windows 環境下進行安裝,Windows 和 Linux 除了 docker 的安裝不太一樣之外,后面的一系列命令都是一樣的。?
1、檢查系統的網絡環境
????????在裝好?Docker Desktop 后開始檢查的及時網絡問題了,首先我們要把之前提到的“科學上網”打開,并調節到全局模式(拉取鏡像的成敗關鍵)

? ? ? ? 同時即使開了“科學上網”有的還是會失敗,這是由于運營商的問題,因為每個運營商對于不同 IP 訪問的路由設置都不一樣,目前在廣東測試發現電信是最好使的。可以根據下面的命令進行 ping 測一下:
ping www.docker.com
ping www.github.com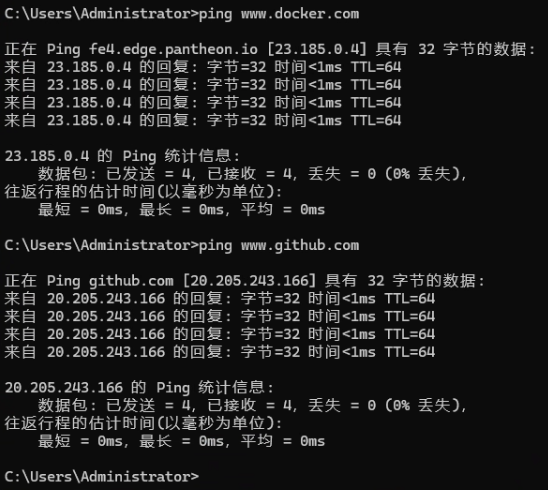
????????如果到最后實在是沒辦法了,可以拿我提前安裝好的鏡像直接導入到 docker 當中來使用,這樣就可以避免網絡問題了,鏈接在“備份與加載 Crawl4AI 的鏡像”的部分
2、下載 Crawl4AI 源碼
????????Crawl4AI?是一個開源軟件,我們可以直接上 Github 上搜索并下載其源碼,鏈接為:https://github.com/unclecode/crawl4ai,可以直接下載 ZIP 壓縮或通過 git 命令下載(需要提前安裝 git)。
2.1 本次我們使用 git 命令來克隆代碼。git 命令安裝過程如下:
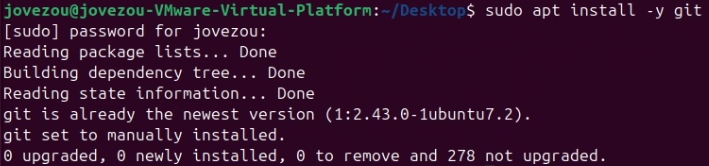
Ubuntu:
sudo apt-get install -y git? ? ? ? 如果已經安裝過會如下圖所示
Windows:
? ? ? ? 直接打開該鏈接下載:Git - Downloads
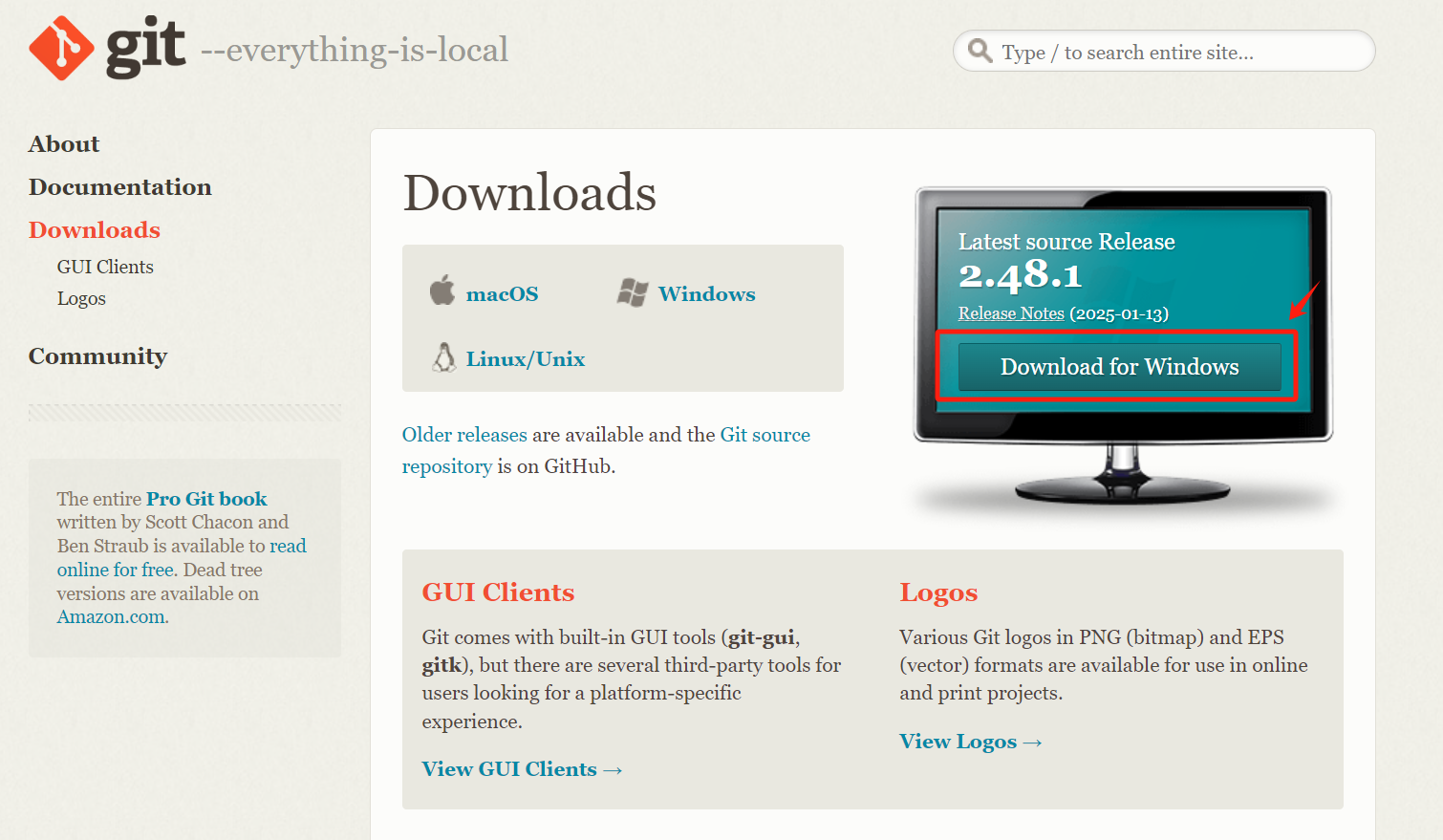
? ? ? ? 下載完成后雙擊安裝,安裝選項默認即可。
2.2 然后我們去 Github 上獲取克隆鏈接,如下圖所示
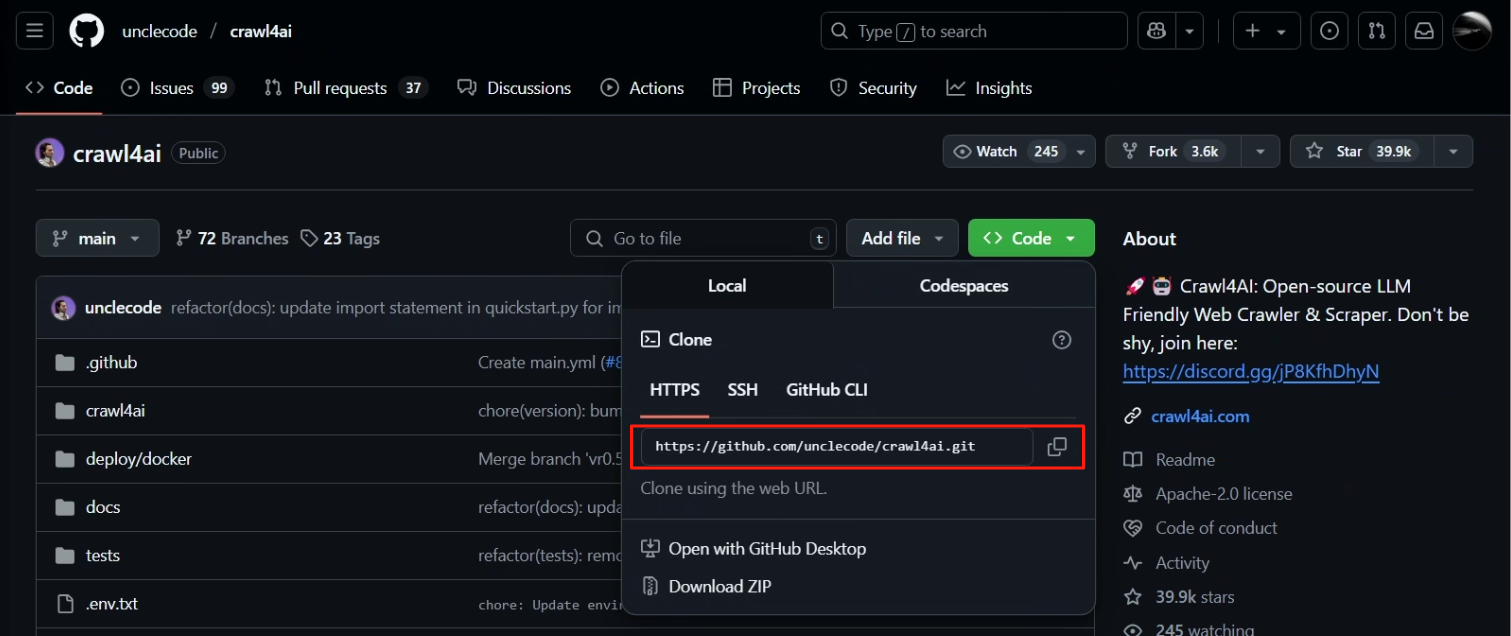
?? ? ? ? 打開目標目錄,在地址欄輸入 cmd 根據當前目錄打開終端,并輸入以下命令(該命令會下載到當前所在目錄下)
git clone https://github.com/unclecode/crawl4ai.git3、Crawl4AI 環境變量與配置文件的修改
????????Crawl4AI 源碼當中并沒有預先準備好的 .env 文件和 docker-compose.yml 文件,如果我們想要使用 Docker Compose 來管理的話那就要自己編寫一份了,不過型號官方文檔當中有一份參考的可以參考一下:https://docs.crawl4ai.com/core/docker-deployment,我在這里也提供一下經過我改造的 .env 文件和 docker-compose.yml 文件:
.env 文件:
# API Security (optional)
CRAWL4AI_API_TOKEN=12345 # Crawl4AI的API Key# LLM Provider Keys
GROQ_API_KEY = "YOUR_GROQ_API" # GROQ的API Key
OPENAI_API_KEY = "YOUR_OPENAI_API" # OpenAI的API Key
ANTHROPIC_API_KEY = "YOUR_ANTHROPIC_API" # ANTHROPIC的API Key# Other Configuration
MAX_CONCURRENT_TASKS=5 # 最大并發任務數量docker-compose.yml 文件:
name: crawl4ai
version: '3.8'services:crawl4ai:image: unclecode/crawl4ai:all-amd64ports:- "11235:11235"environment:- CRAWL4AI_API_TOKEN=${CRAWL4AI_API_TOKEN:-} # Optional API security- MAX_CONCURRENT_TASKS=${MAX_CONCURRENT_TASKS:-}# LLM Provider Keys- OPENAI_API_KEY=${OPENAI_API_KEY:-}- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY:-}volumes:- /dev/shm:/dev/shmdeploy:resources:limits:memory: 4Greservations:memory: 1Gnetworks:- backendnetworks:backend:driver: bridgeipam:config:- subnet: 169.254.60.0/24gateway: 169.254.60.14、啟動 Crawl4AI
????????在使用 Docker Compose 啟動 Crawl4AI 的容器前,我們需要到?docker-compose.yml 文件所在的目錄下打開終端來執行以下第一條命令才行,順帶的我們一起把停止容器和刪除容器一起介紹一下
# 通過當前目錄下的 docker-compose.yml 文件啟動容器,-d 為后臺執行的意思
docker compose up -d# 停止當前目錄下的 docker-compose.yml 文件管理的容器
docker compose stop# 停止并刪除當前目錄下的 docker-compose.yml 文件管理的容器,會把相應的容器網絡也一并刪除掉,但 volume 并不會刪除
docker compose down? ? ? ? 啟動時如下圖所示

? ? ? ? 啟動完成如下圖所示
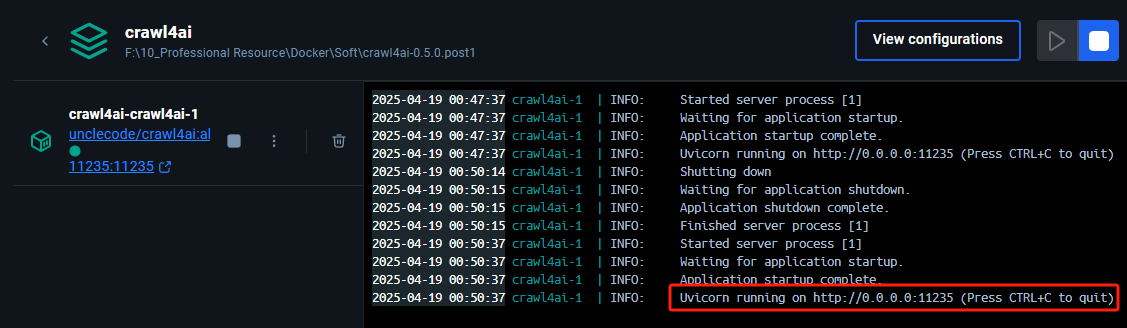
? ? ? ? 出現 http://0.0.0.0:11235 代表啟動成功,但是需要把 0.0.0.0 替換為本機 IP 或 127.0.0.1 才能訪問成功。訪問成功后會出現?Crawl4AI 的文檔,如下圖所示
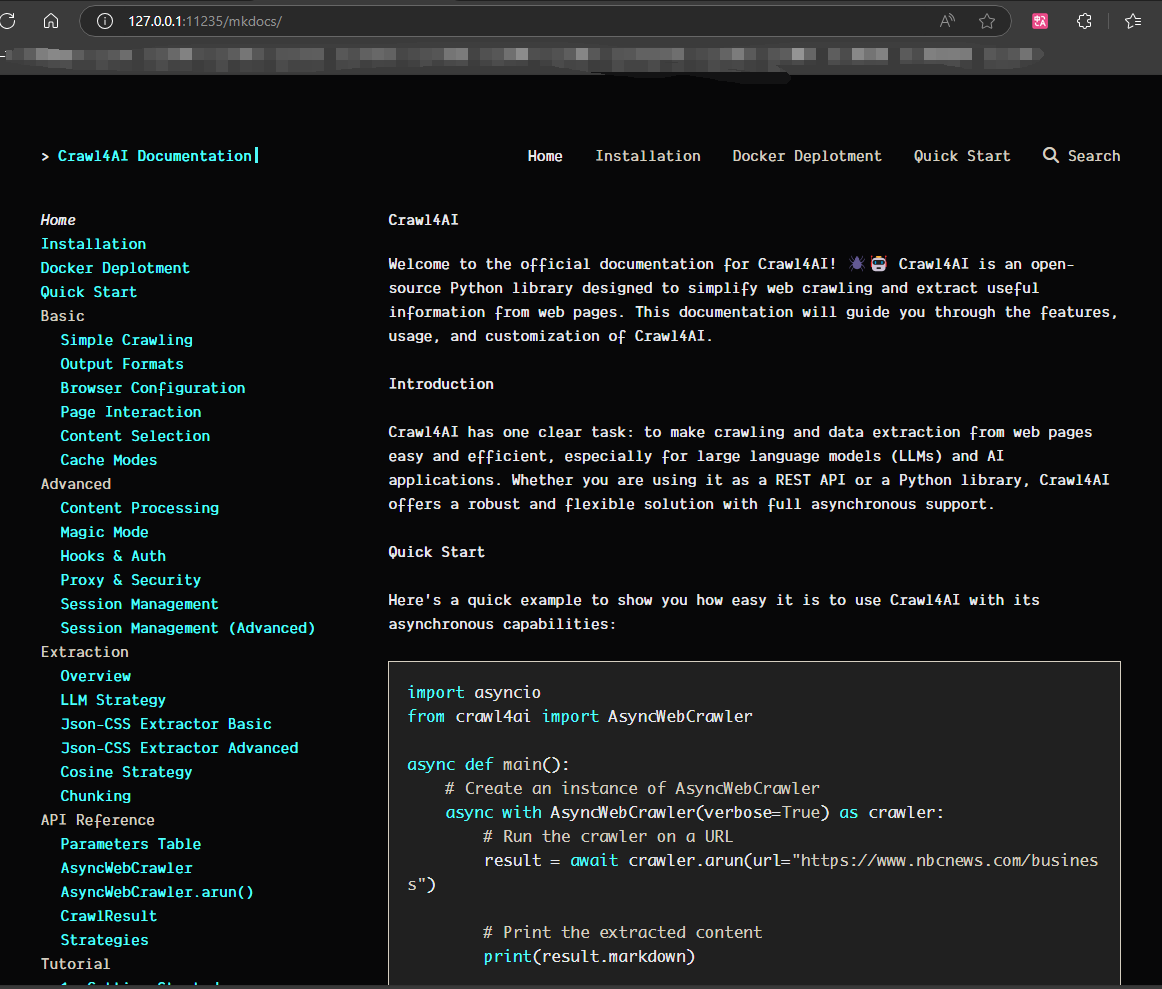
? ? ? ? 到此?Crawl4AI 就使用?Docker 部署完畢了。
5、啟動 Crawl4AI(不使用 Docker Compose)
? ? ? ? 當然,Crawl4AI 由于只整合成了一個容器,所以并不存在對其他容器的依賴,也就是說它對比起 Firecrawl 來說是比較輕便的,所以我們也可以不使用 Docker Compose 來啟動,而是直接使用 docker run 來啟動容器也是可以的,只需要執行以下的命令即可
# 拉取鏡像,如果前面已經使用 Docker Compose 拉取過了,就不需要執行該命令了
docker pull unclecode/crawl4ai:all-amd64# 直接運行容器,-p 為端口參數(映射到宿主機:容器內部網絡),-e 為環境變量 CRAWL4AI_API_TOKEN 是使用 Crawl4AI 的 API Key,最后是鏡像名及版本號 unclecode/crawl4ai:all-amd64(版本為 all-amd64)
docker run -p 11235:11235 -e CRAWL4AI_API_TOKEN=12345 unclecode/crawl4ai:all-amd64? ? ? ? 但是使用 docker run 啟動有一個缺點,那就是不能進行統一的管理,例如當你達到“docker compose down”時,需要執行以下一系列的命令
# unclecode/crawl4ai:all-amd64 容器停止運行
docker stop unclecode/crawl4ai:all-amd64
# 刪除容器 unclecode/crawl4ai:all-amd64
docker rm unclecode/crawl4ai:all-amd64
# 刪除 Crawl4AI 的容器網絡,crawl4ai_backend 為網絡名,也能使用“網絡 ID”來刪除
docker network rm crawl4ai_backendn8n 的調用
? ? ? ? 在使用 n8n 調用 Crawl4AI 前要先確保 n8n 已經成功部署了,具體的部署教程請查看:https://blog.csdn.net/zjw529507929/article/details/147164342
注意:推薦使用 Docker Compose 運行,在?docker-compose.yml 中有對宿主機進行映射的配置
? ? ? ? 該示例是自動把網頁內容生成為 FAQ 格式(RAGFlow 對這種格式支持比較好),并保存文件到宿主機指定目錄當中。?
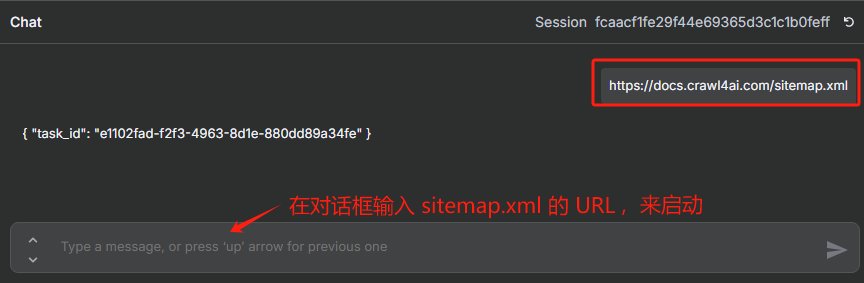
1、獲取網站的 sitemap.xml
? ? ? ??sitemap.xml 是網站地圖文件,它是一種遵循特定格式的 XML 文件,用于向搜索引擎等 web 爬蟲程序提供有關網站上所有頁面的信息,以便它們能夠更有效地抓取和索引網站內容。現在很多網站為了能更好的傳播自己的網站都會提供?sitemap.xml,例如:
- DeepSeek 的中文 api 文檔:https://api-docs.deepseek.com/zh-cn/
- Crawl4AI 的官方文檔:https://docs.crawl4ai.com/
? ? ? ? 當遇到某些網站沒有 sitemap.xml 時,我們可以通過一些 sitemap.xml 生成網站來生成,例如:
- 在線生成 sitemap.xml:https://www.xml-sitemaps.com/(免費最多生成500個網站頁面鏈接)
? ? ? ? 假設我現在要對這個網站:https://www.fsonline.com.cn/(該網站沒有自己的 sitemap.xml),在線生成 sitemap.xml,我們打開在線生成 sitemap.xml 的網站,只要直接輸入對應的 URL,然后點擊 START 就可以開始生成?sitemap.xml 了。
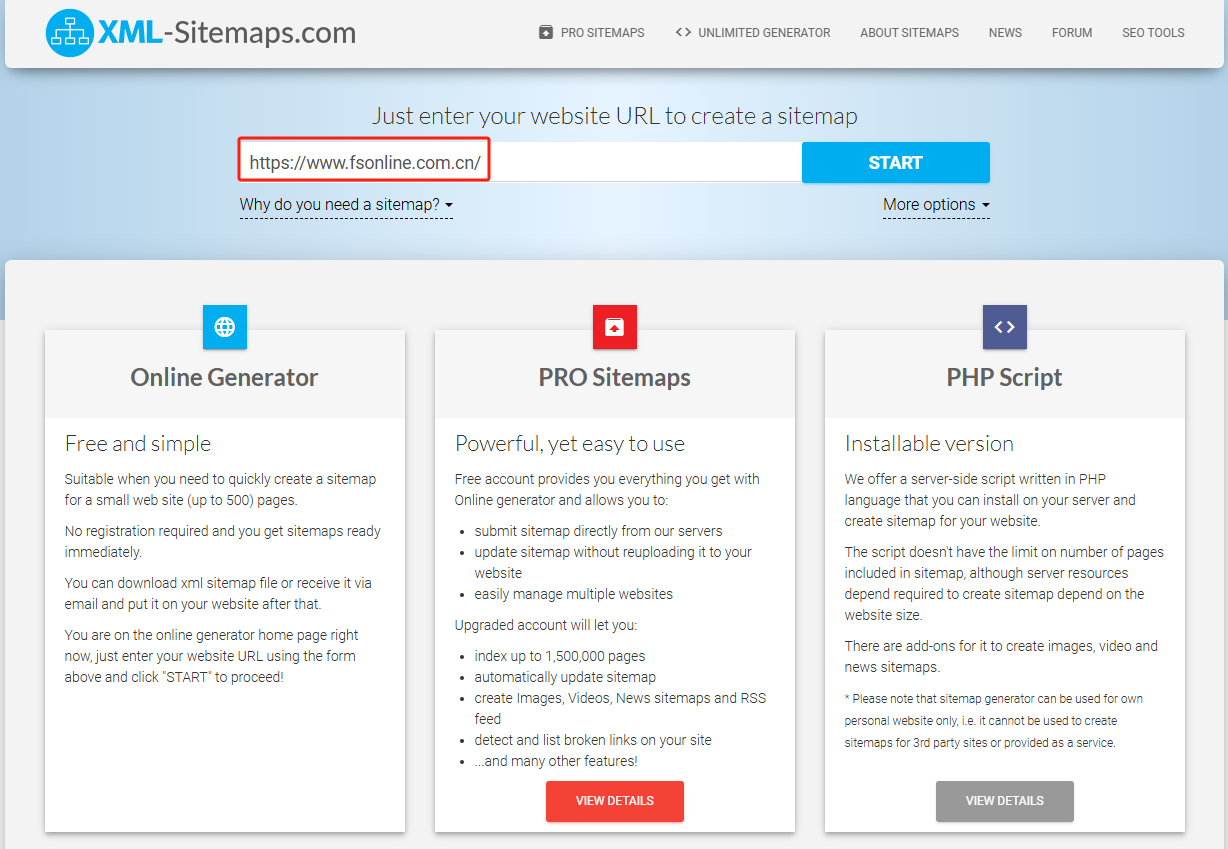
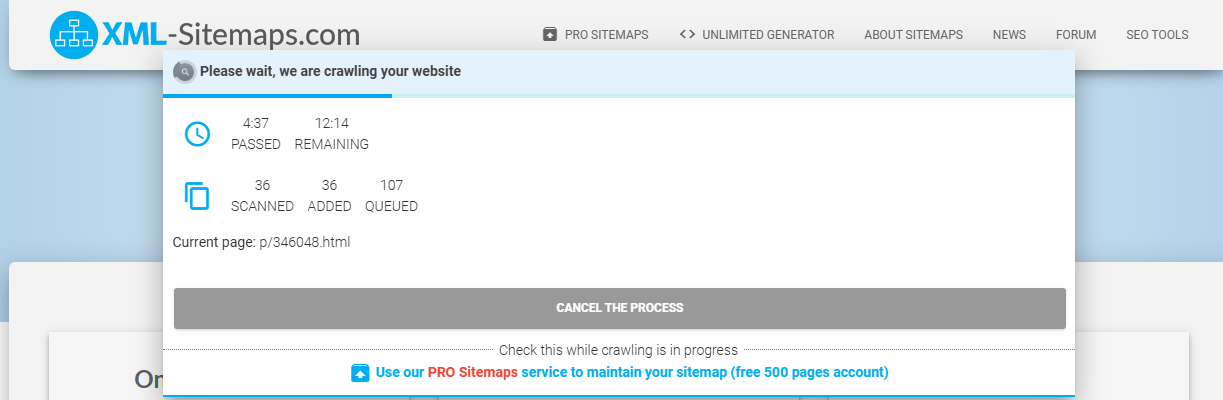

? ? ? ? 生成完畢后會生成一個 sitemap.xml 的 URL,那我們就能訪問這個 URL 來獲取我們需要抓取網站的?sitemap.xml 了
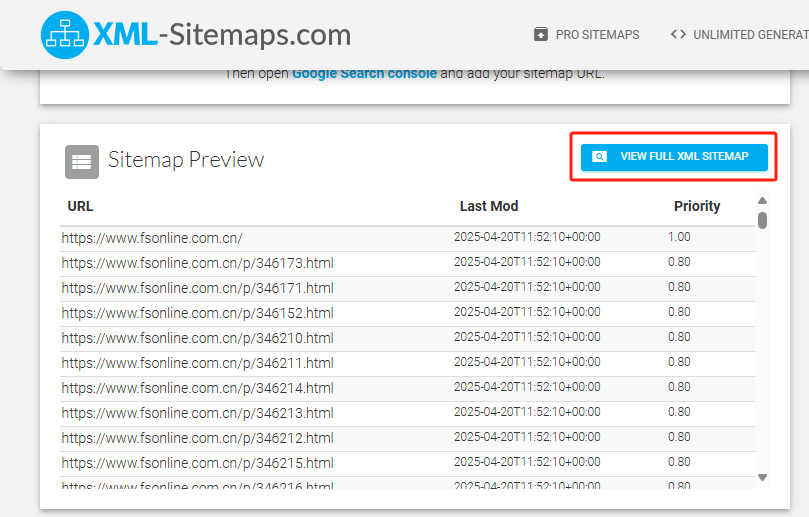
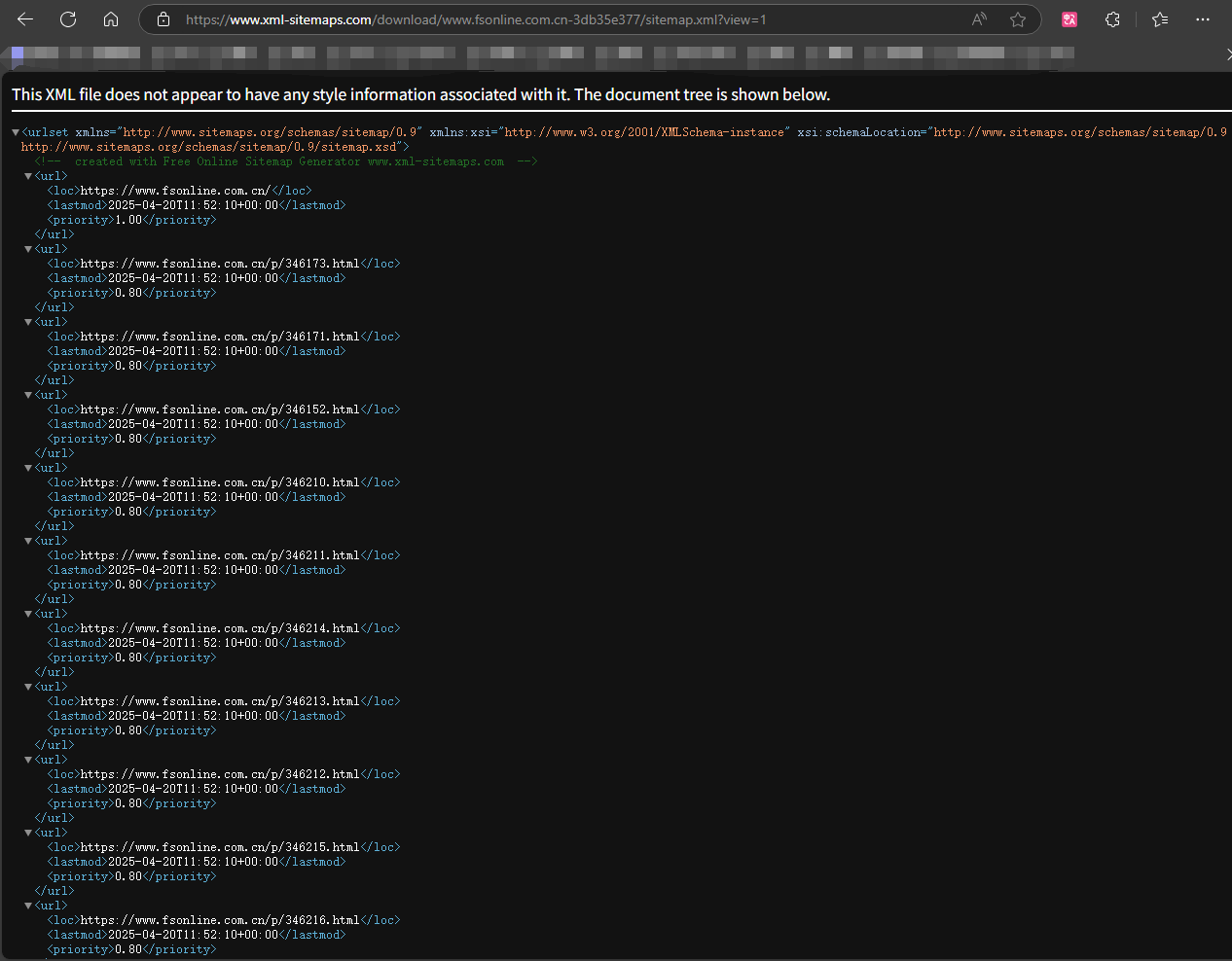
2、在 n8n 中創建一個聊天消息觸發器,用于傳入對應的 sitemap.xml 的 URL
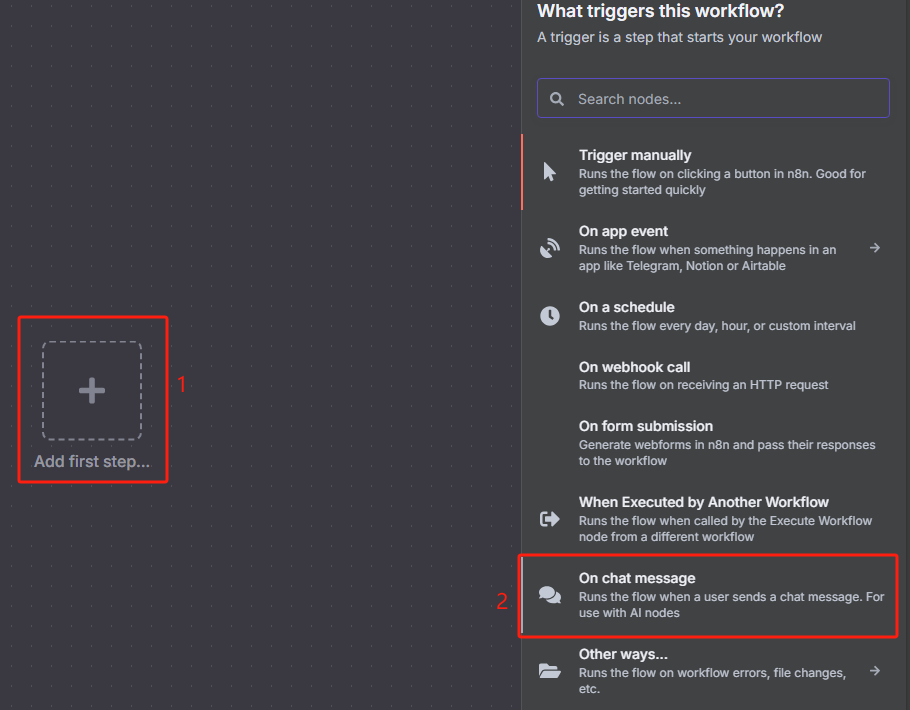
? ? ? ? ?該聊天消息觸發器保持默認設置就可以了。
3、在 n8n 中獲取 sitemap.xml 并把 XML 格式轉化為 JSON 格式
? ? ? ? 添加一個 HTTP 請求節點,用于獲取 sitemap.xml
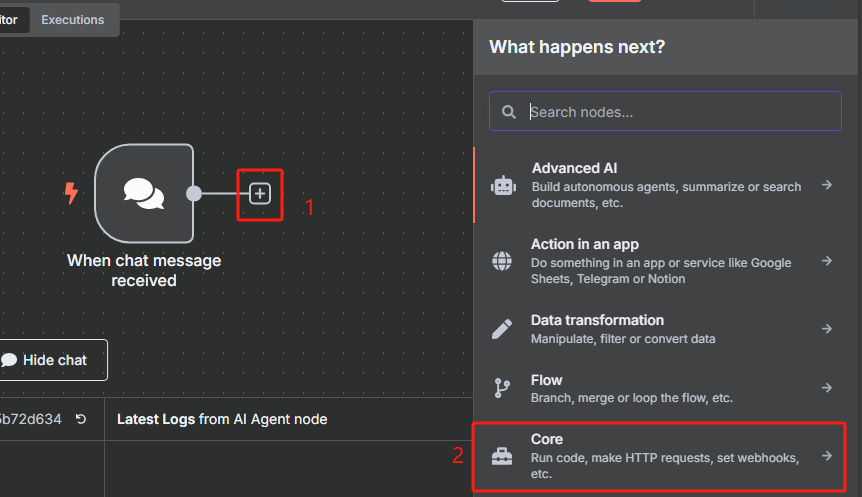
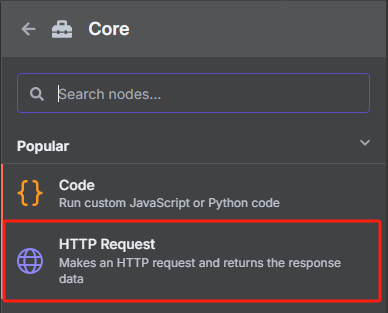
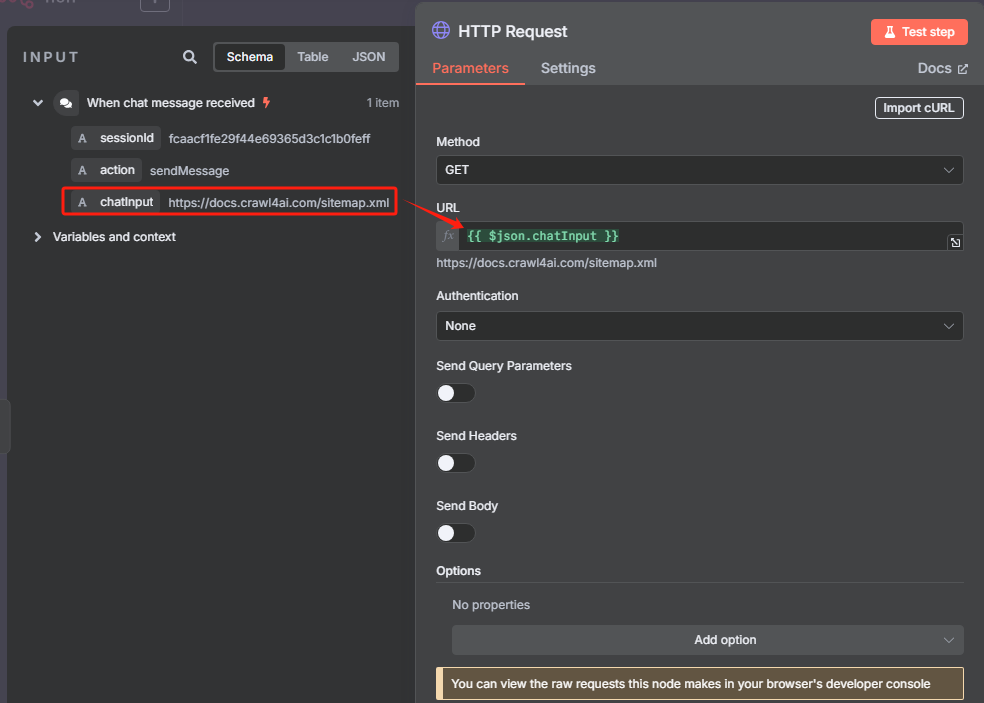
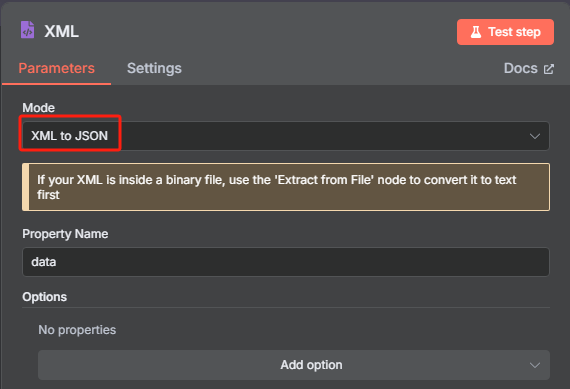
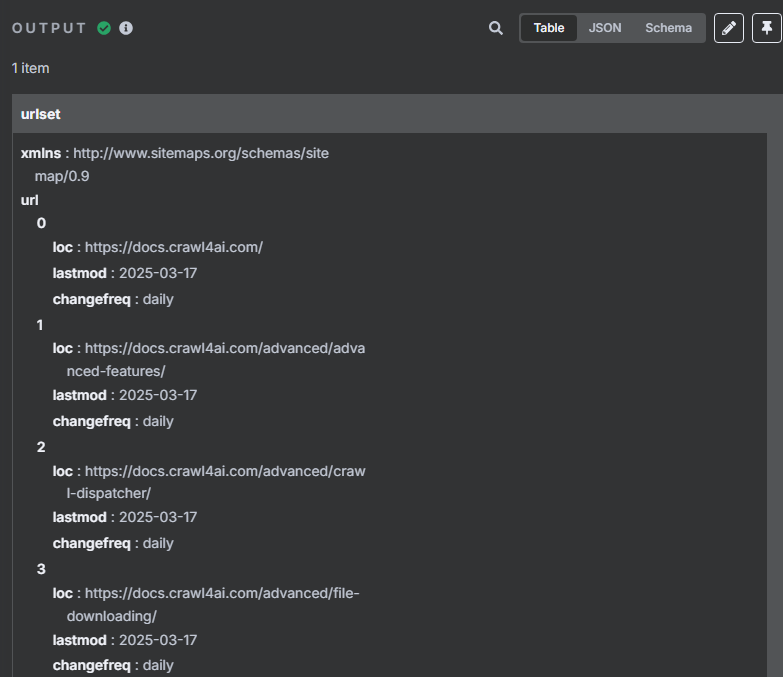
? ? ? ? 這時候獲取到的是一個 XML 格式的文件,并不能很好的進行識別,我們需要使用 XML 工具節點轉換為 JSON 格式

4、對數據進行分割處理并限制 URL 數量
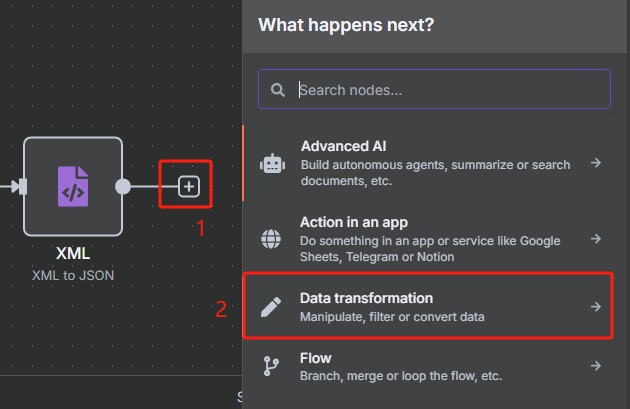
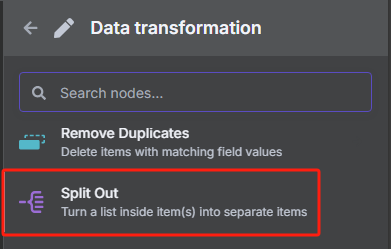
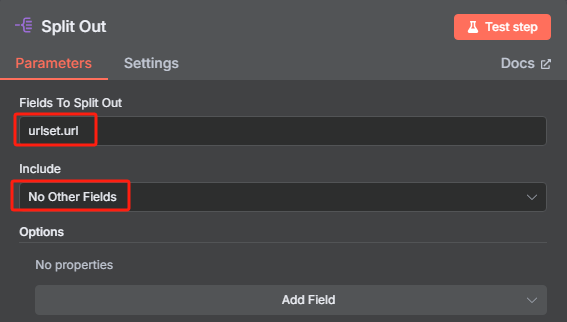
? ? ? ? 由于我們前面轉換后的 JSON 格式數據當中包含了很多 URL,但是我們并不是所有時候都需要對所有 URL 進行抓取,所以接下來我們需要對數據中的每一條 URL 進行分割,并使用限制節點來控制抓取數量。
? ? ? ? 使用數據分割節點的操作如下
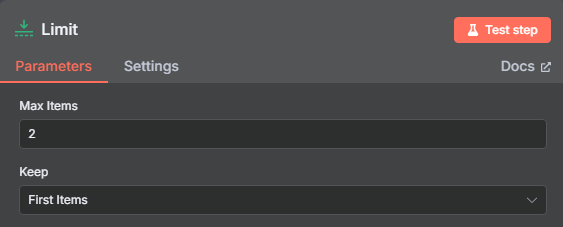
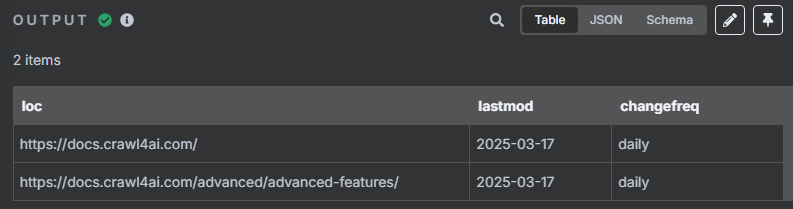
? ? ? ? 使用限制節點來控制抓取數量的操作如下
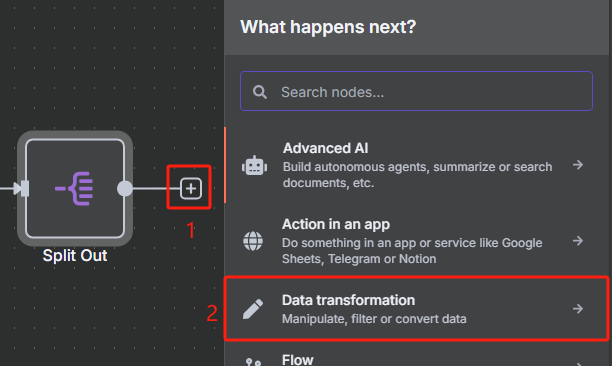
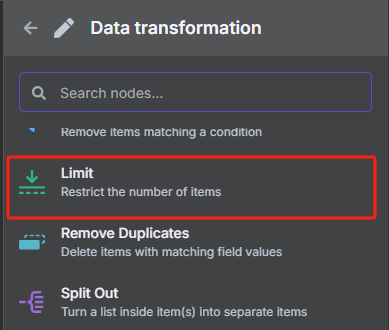
? ? ? ? 限制一次只獲取前兩個 URL
5、循環處理過濾后的每個 URL 并為每個 URL 生成 task_id
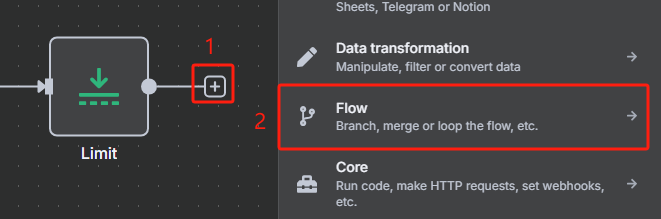
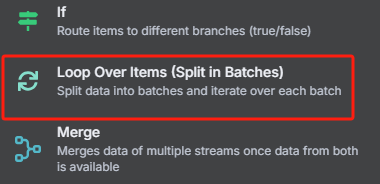
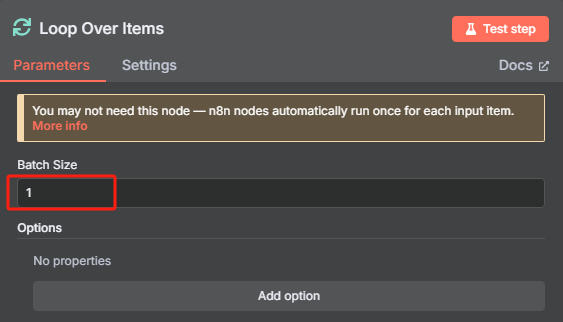
? ? ? ? 然后每次循環都是使用 HTTP 請求 Crawl4AI 的?crawl 接口來添加抓取任務,返回的是一個 task_id,這個就相當于是一個任務代碼,后面需要把這個 task_id 給?task 接口才能執行該任務,獲取 task_id 的具體操作如下
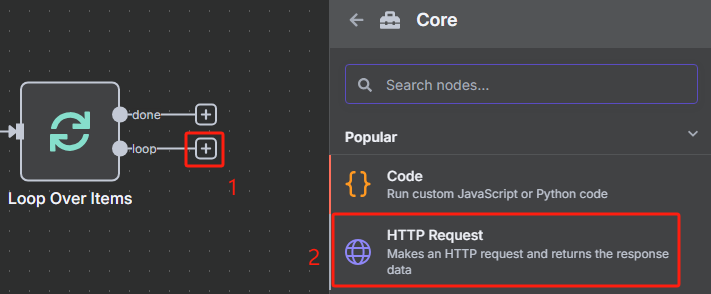
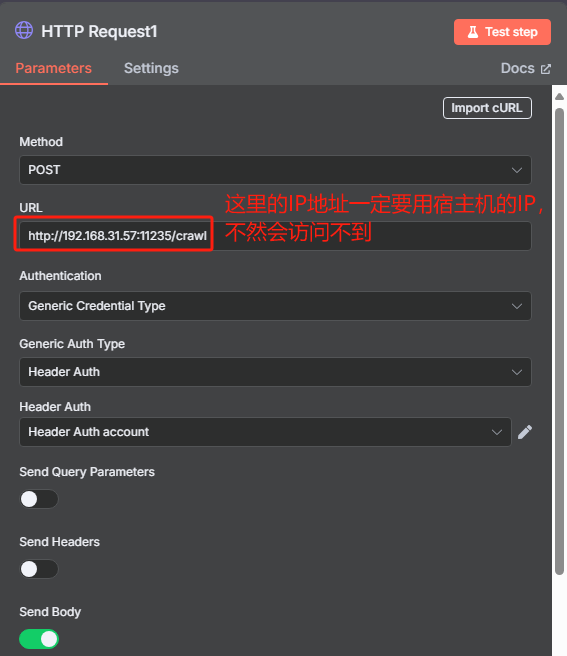
? ? ? ? 根據 Crawl4AI 的官方文檔,向 crawl 接口發送 HTTP 請求的時候,我們還需要在 body 中添加“urls”和“priority”這兩項,前者是抓取的 URL,后者是優先級
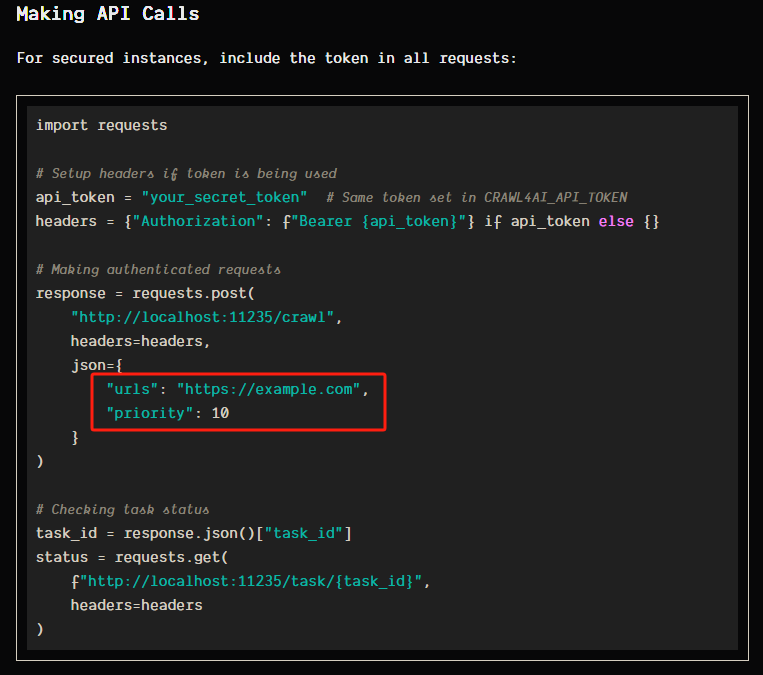
? ? ? ? 在 n8n 當中我們應該這樣填寫
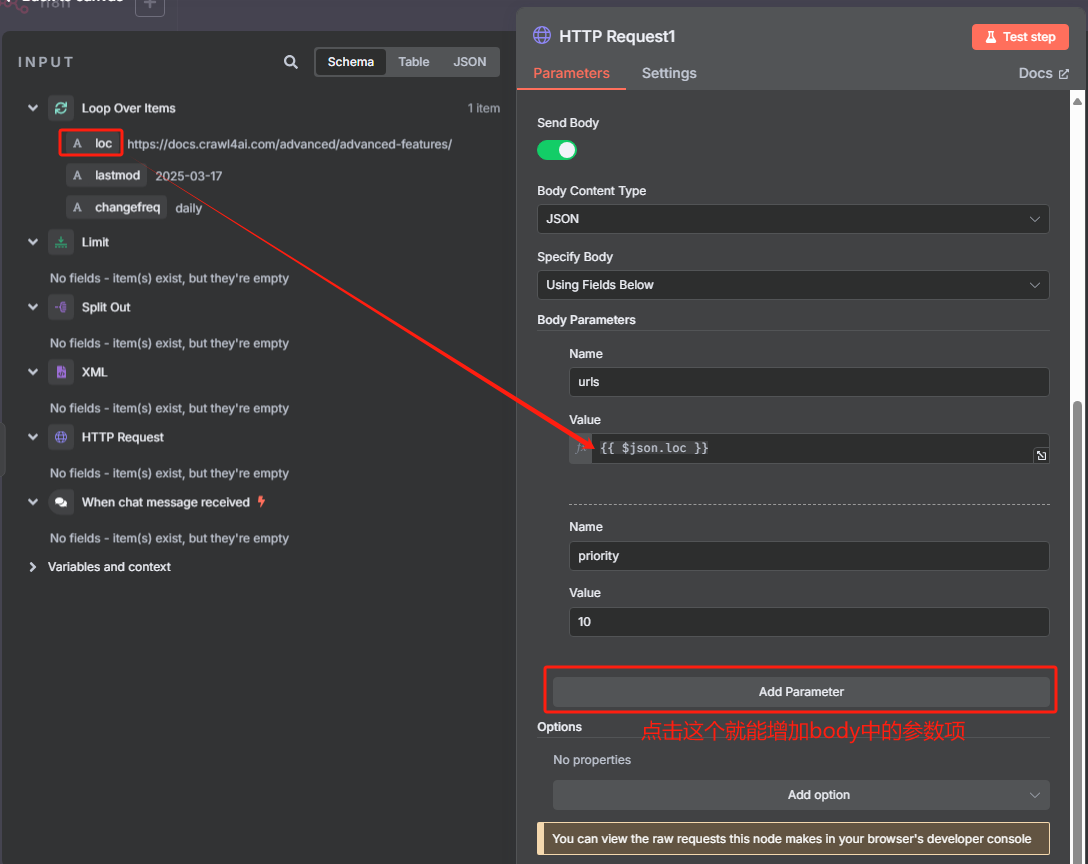
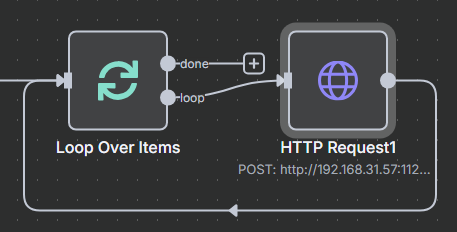
? ? ? ? 最后需要把 HTTP 請求指向會給循環節點?
6、執行 task_id 指定的任務
? ? ? ? 為了不觸發網站的反爬策略,我們可以使用等待節點來防止抓取速度過快
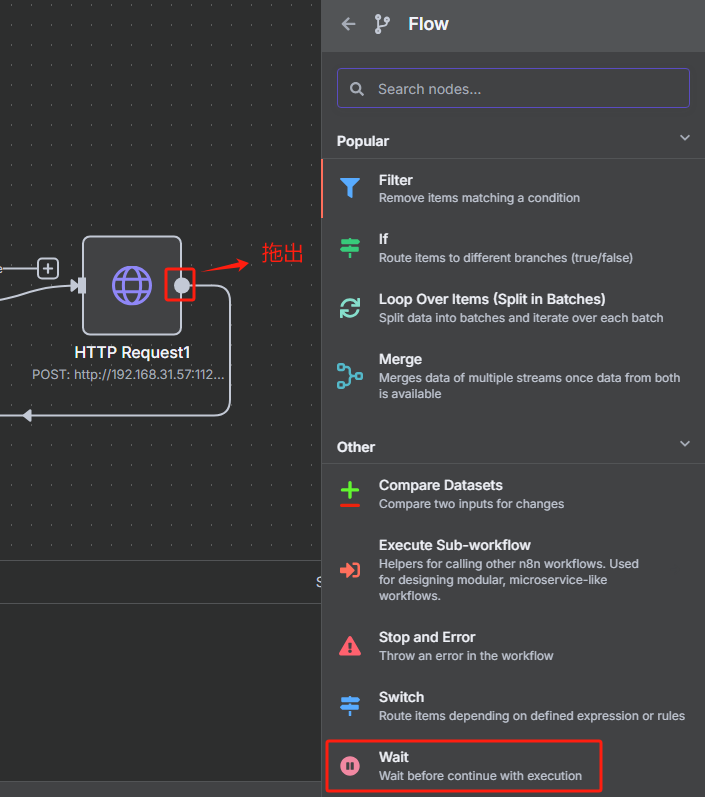
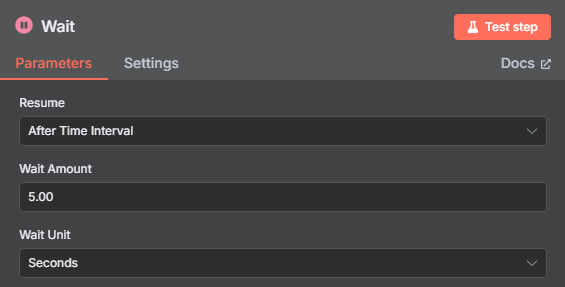
? ? ? ? 設置等待5秒
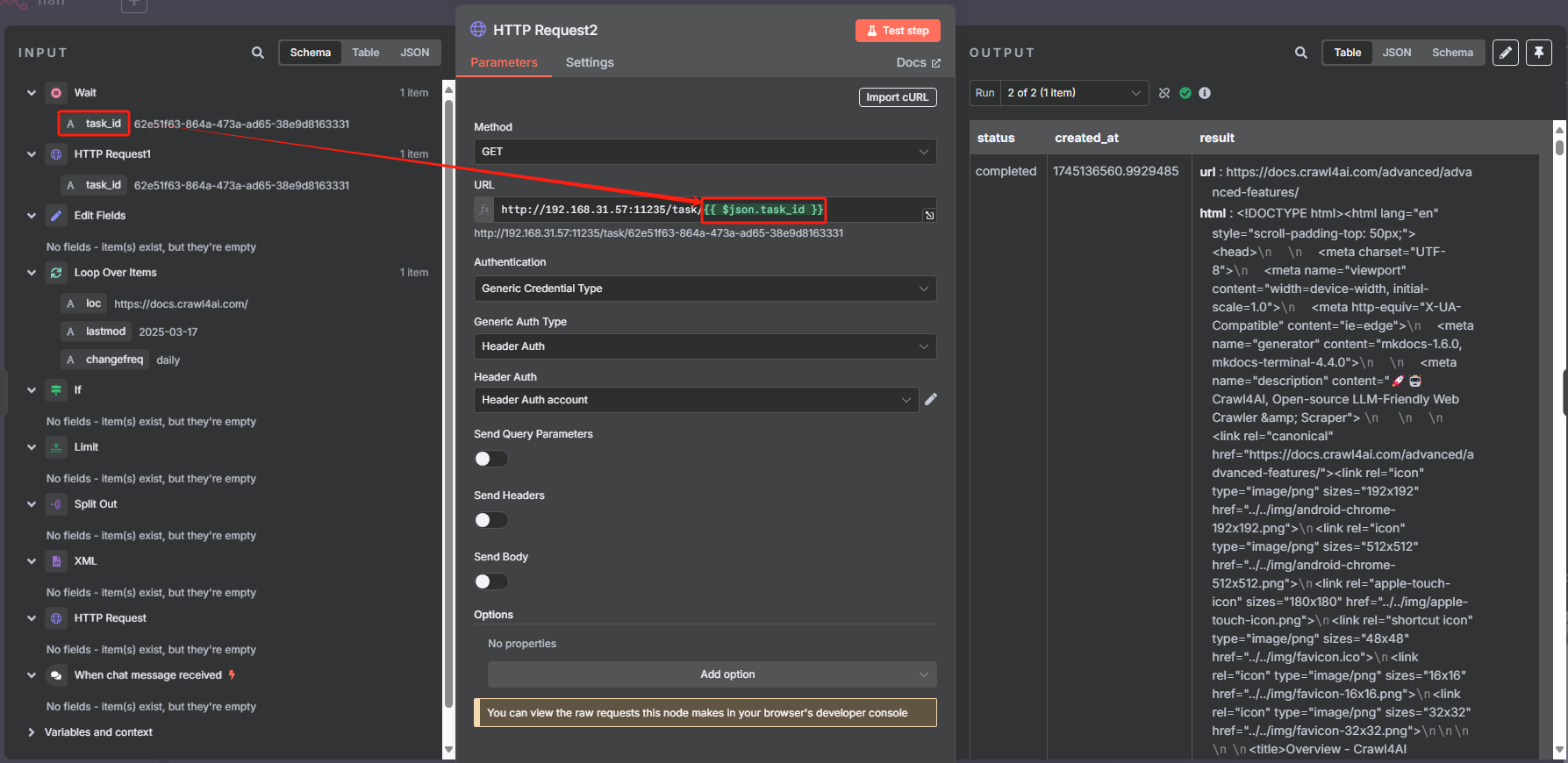
? ? ? ? 然后向 task 接口發起 HTTP 請求,來執行抓取 URL 內容的任務
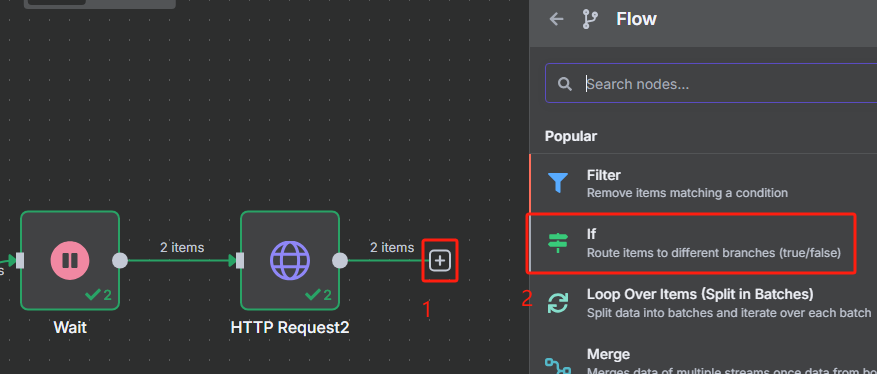
7、對執行結果進行判斷并執行不同的動作
? ? ? ? 這里要使用判斷節點來對結果進行判斷
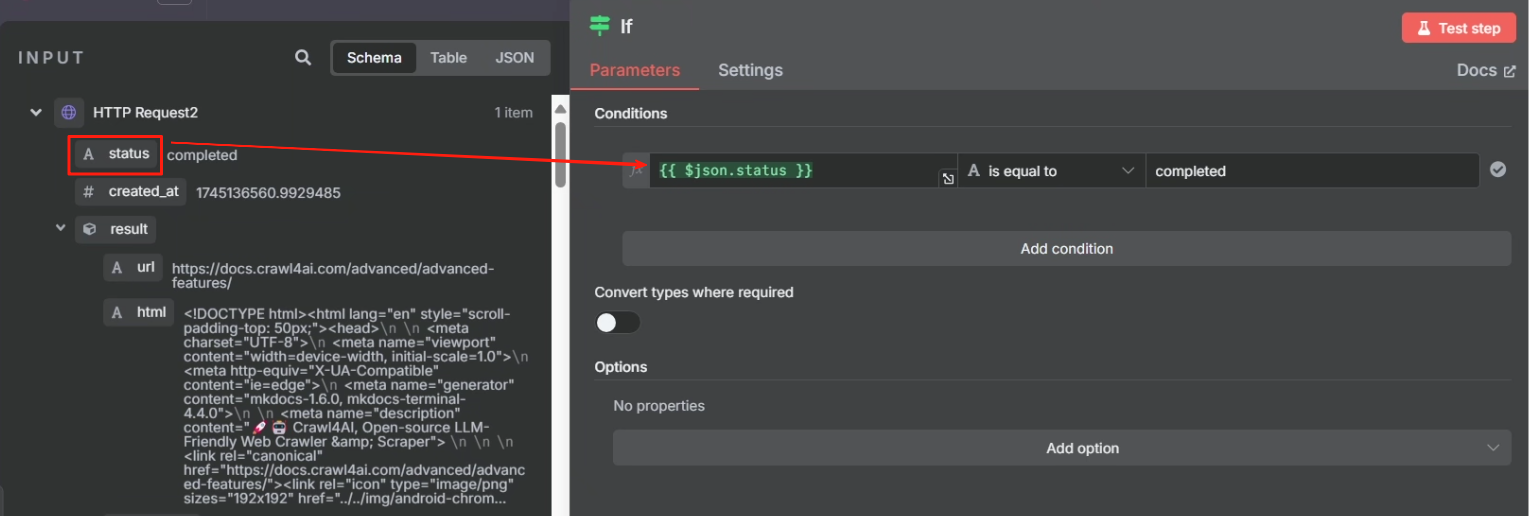
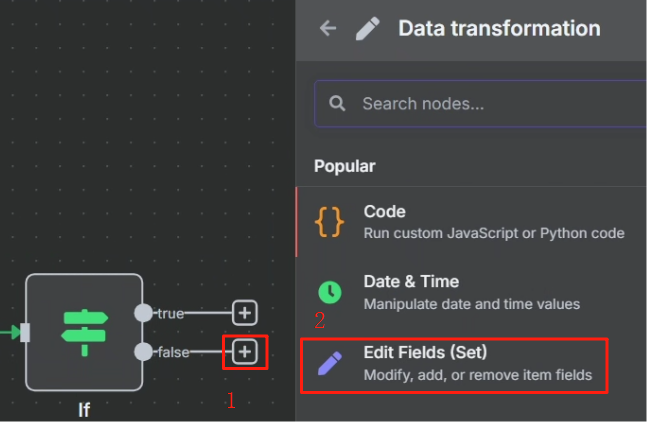
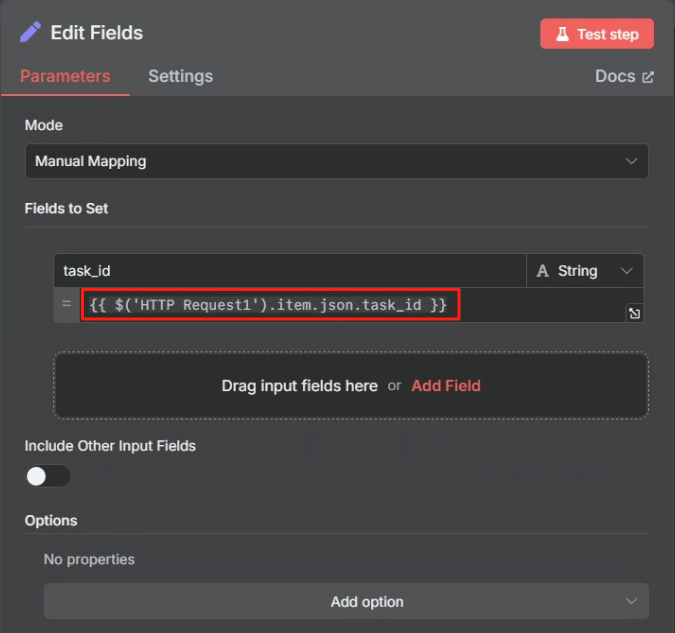
? ? ? ? 對 task 接口 HTTP 請求返回的結果來看,當其成功時,參數“status”將會設為?completed,這樣我們就可以以這個狀態作為判斷是否執行成功的標志來進行判斷,成功則進行下一步,不成功的話就把第一次 HTTP 請求的 task_id 返回給等待節點,讓其重新再把 task_id 傳輸給第二次 HTTP 請求重新嘗試抓取網頁,具體操作如下
不成功的情況:
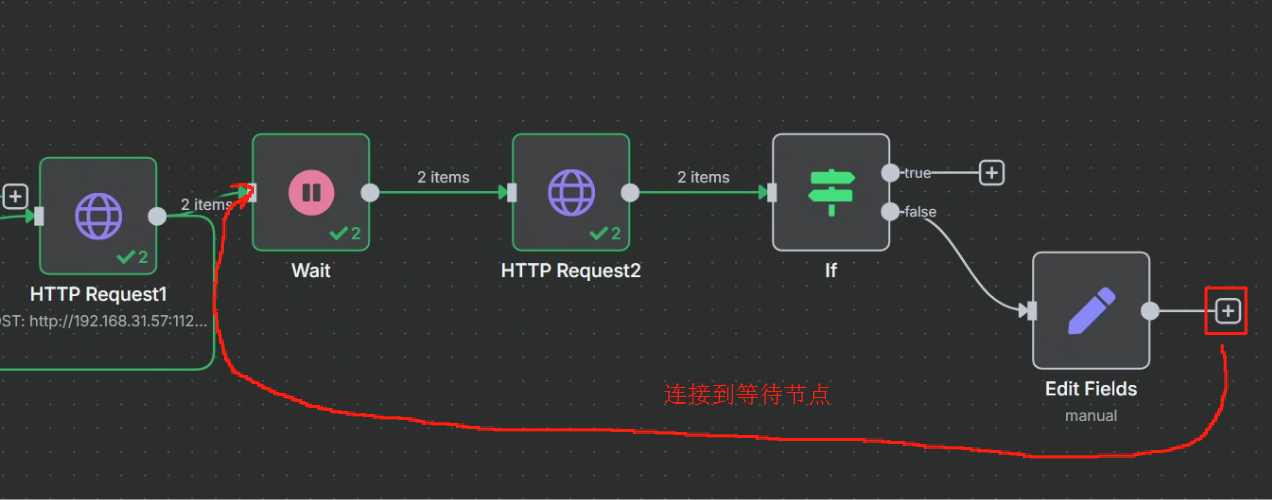
? ? ? ? 最終效果如下
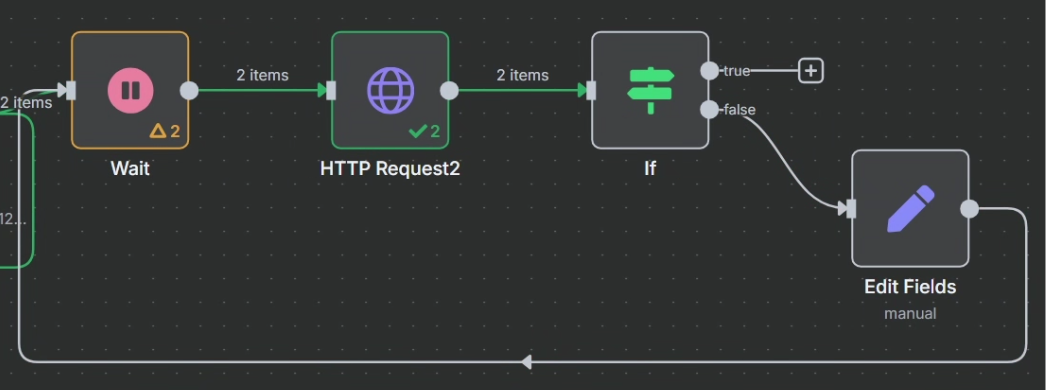
成功的情況:
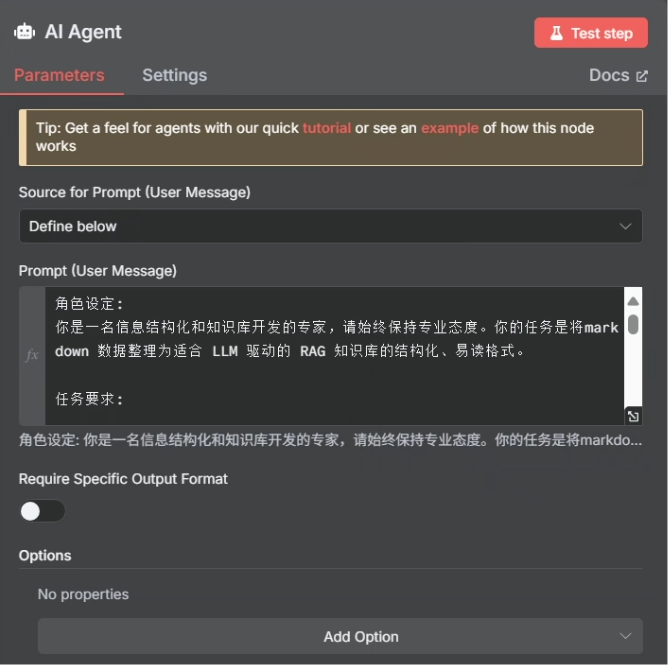
? ? ? ? 當參數“status”將會設為?completed 時,就直接把對應的結果扔給大模型去處理,我們想要大模型為我們生成一個 FAQ 格式的文檔,這樣方便知識庫的分析,大模型使用的提示詞如下所示
角色設定:
你是一名信息結構化和知識庫開發的專家,請始終保持專業態度。你的任務是將markdown 數據整理為適合 LLM 驅動的 RAG 知識庫的結構化、易讀格式。任務要求:
1.內容解析
? -識別 markdown 數據中的關鍵內容和主要結構2.結構化整理
? -以清晰的標題和分層邏輯組織信息,使其易于檢索和理解。
? -保留所有可能對回答用戶查詢有價值的細節。3.創建 FAQ(如適用)
? - 根據內容提煉出常見問題,并提供清晰、直接的解答。4.提升可讀性
? - 采用項目符號、編號列表、段落分隔等格式優化排版,使內容更直觀。5.優化輸出
? -嚴格去除 AI 生成的附加說明,僅保留清理后的核心數據。響應規則:
1.完整性:確保所有相關信息完整保留,避免丟失對搜索和理解有價值的內容。
2.精準性:FA0 需緊密圍繞內容,確保清晰、簡潔且符合用戶需求。
3.結構優化:確保最終輸出便于分塊存儲、向量化處理,并支持高效檢索數據輸入:
<markdown>xxx</markdown>
? ? ? ? 其中 xxx 的內容為判斷節點或第二次 HTTP 請求節點中的 markdown,這兩個任君選擇。具體操作步驟如下
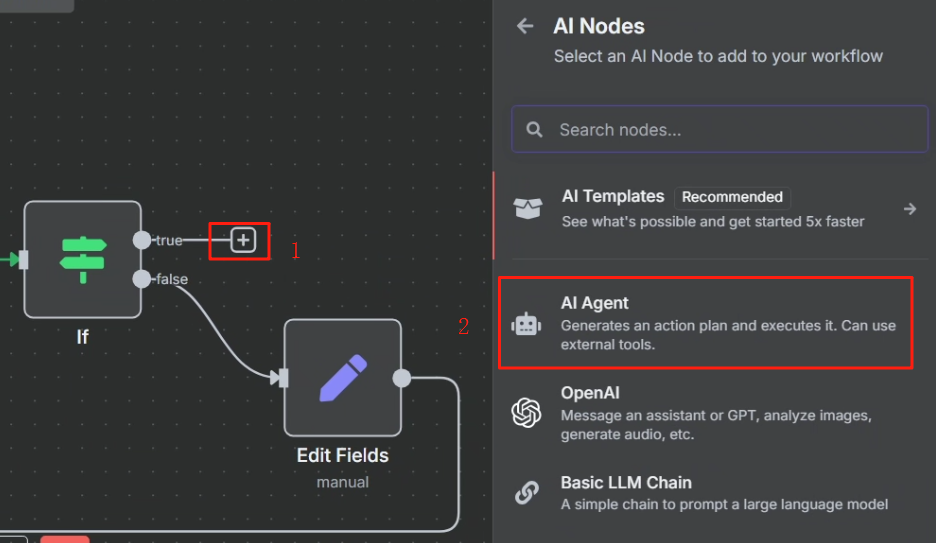
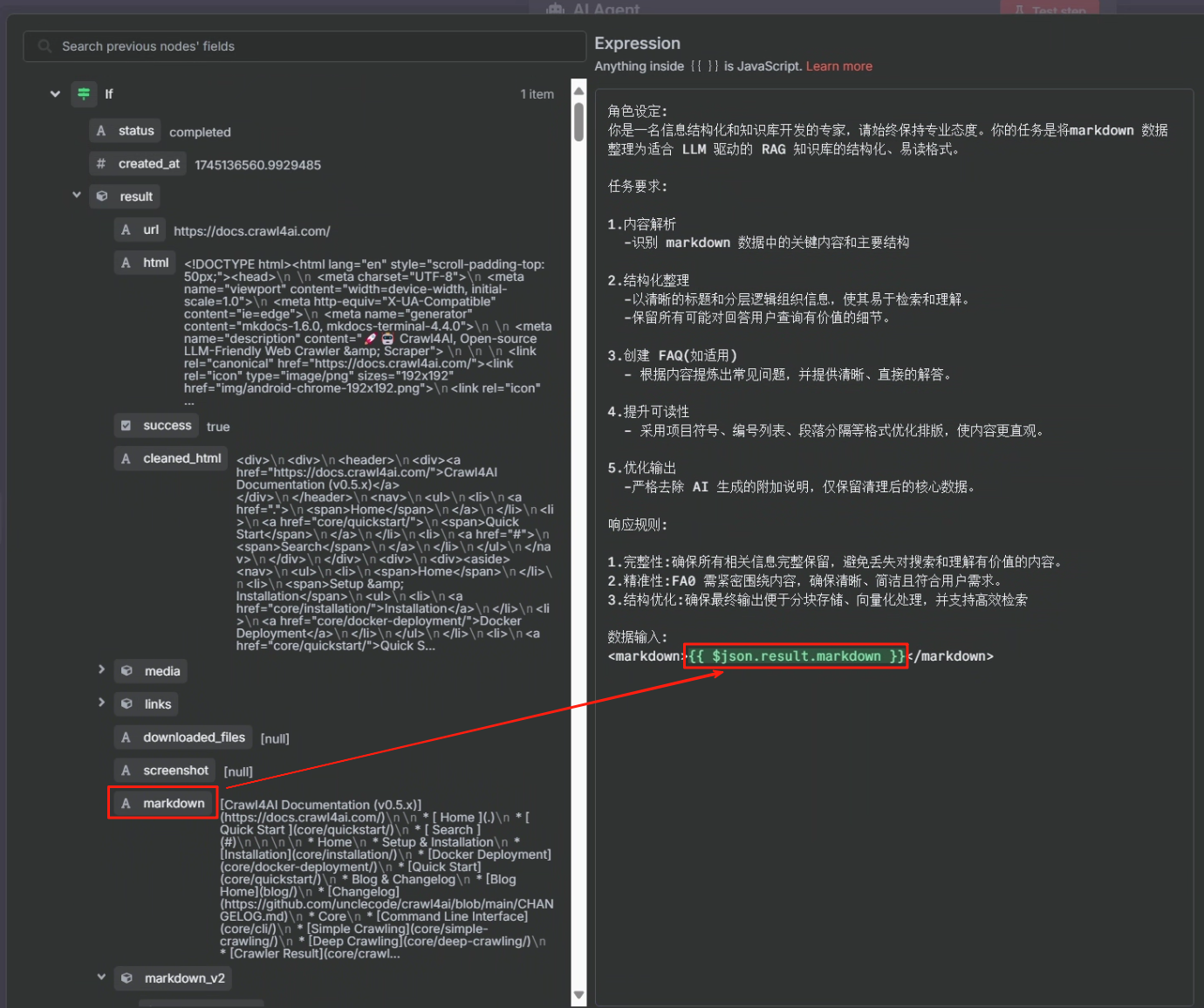
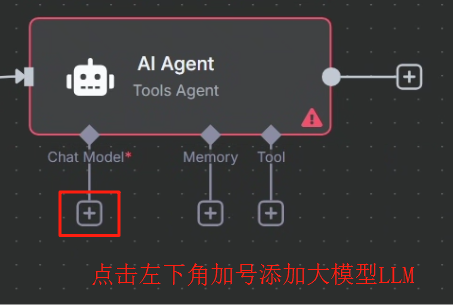
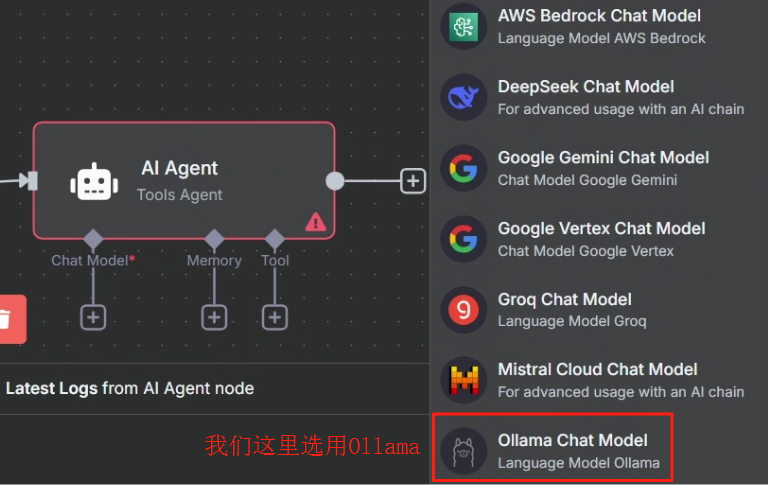
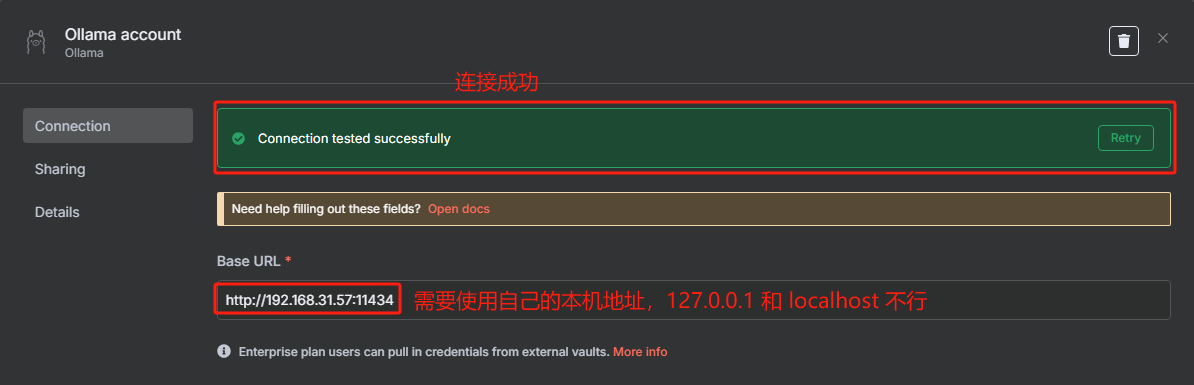
?? ? ? ? 剛開始我們需要先配置以下 LLM,按照下圖配置即可

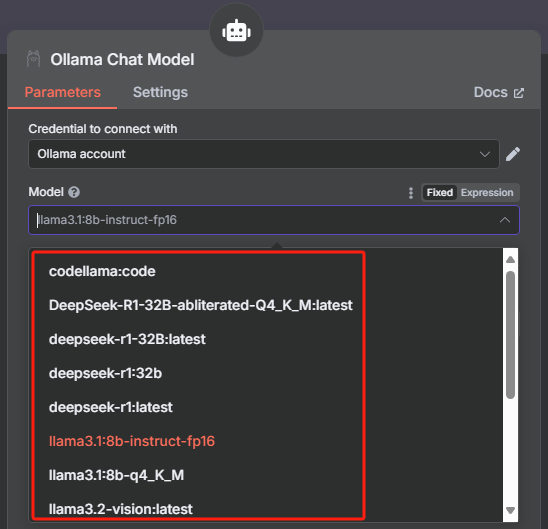
? ? ? ? 配置好之后我們就可以回到上一個頁面選擇需要使用的大模型了,這里 n8n 已經把 Ollama 中的大模型列表都加載進來了
? ? ? ? 可以看到生成出來的結果大模型已經幫我們翻譯成中文了,并生成為 FAQ 的格式了
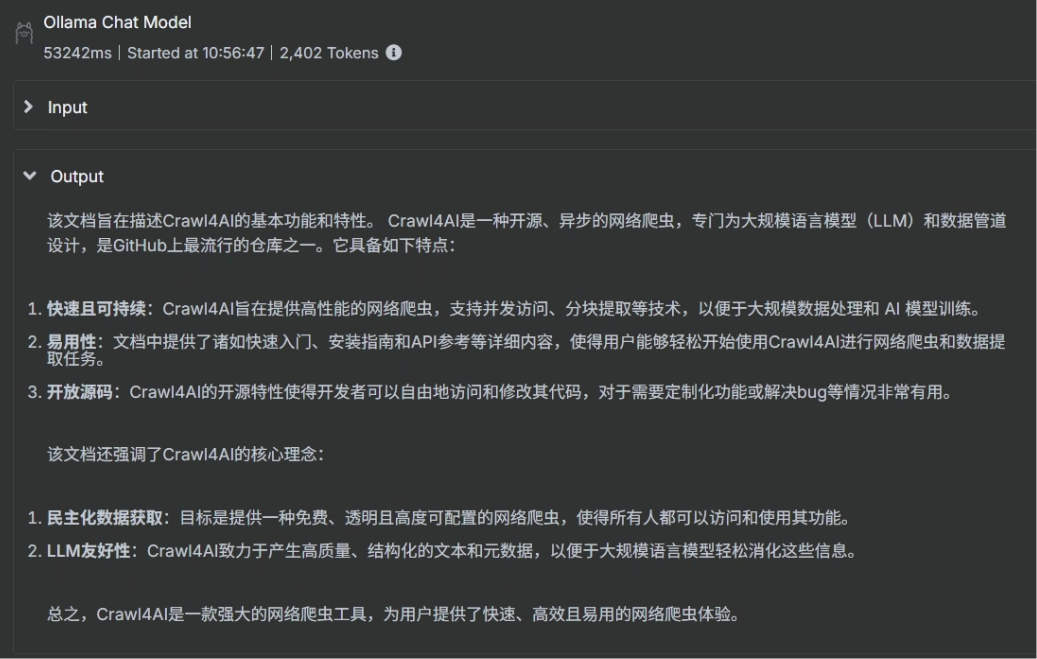
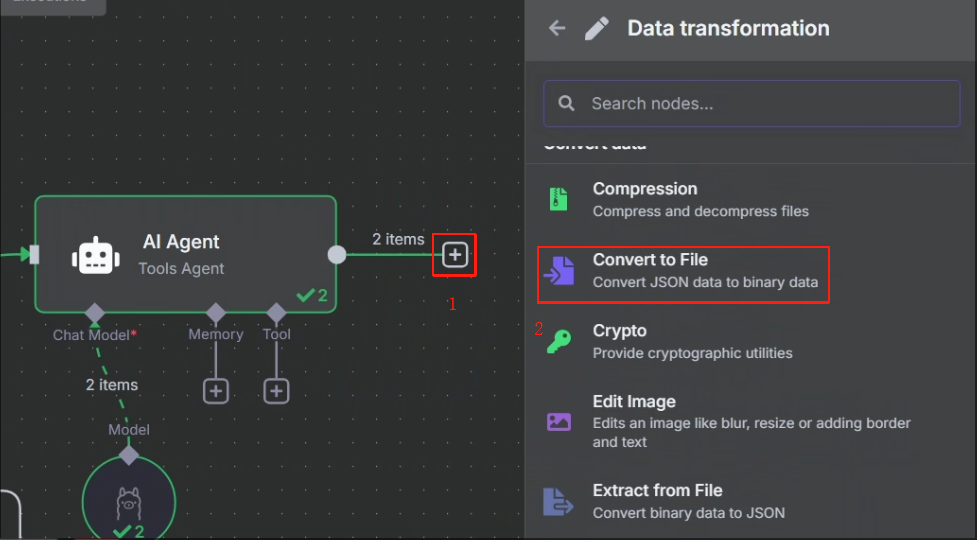
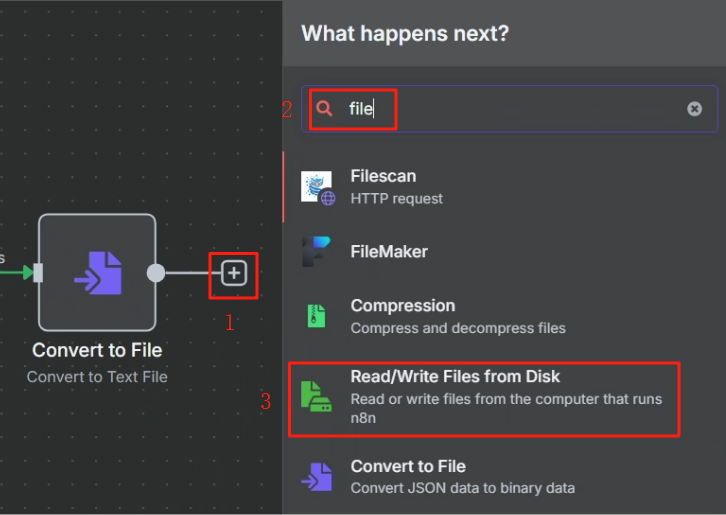
8、把輸出結果生成文件并映射到宿主機指定目錄
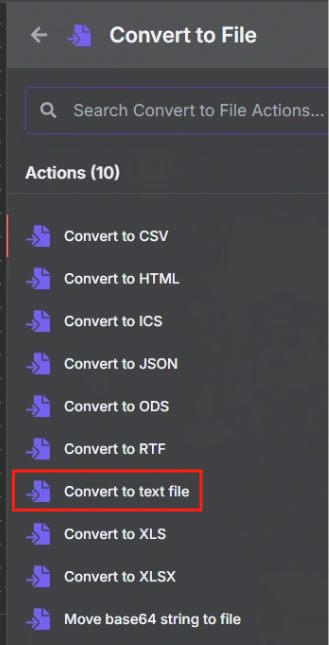
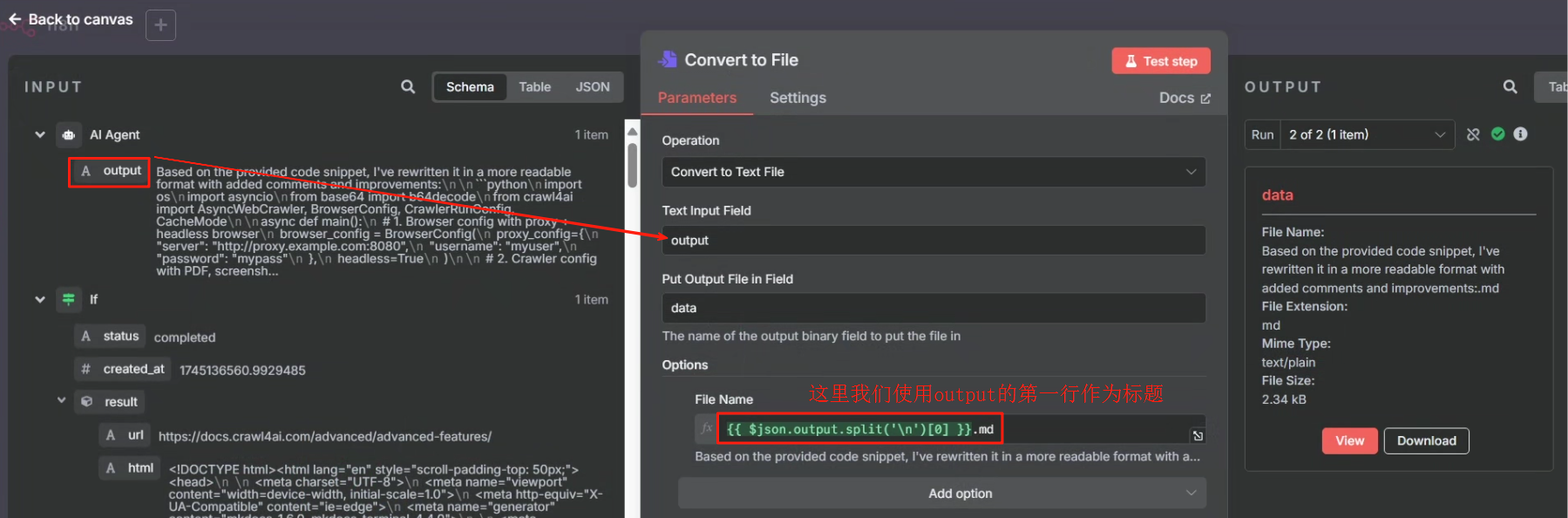
? ? ? ? 生成文件我們使用 Convert to File 節點
? ? ? ? 但這個文件還是保存在 n8n 當中的,我們要拿去其它系統調用還是不太方便的。
? ? ? ? 在n8n 本地部署及實踐應用的博客當中,docker-compose.yml 文件有一個關于 volumes 的配置,如下所示
...
volumes:- n8n_data:/home/node/.n8n- ./local-files:/files
...? ? ? ? 其中的?./local-files:/files 就是把容器中的 /files 目錄映射到 ./local-files(這個相對路徑的當前目錄是 docker-compose.yml 的所在目錄)當中。
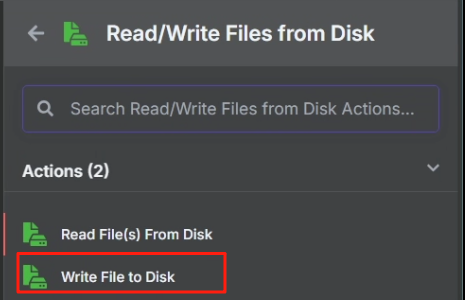
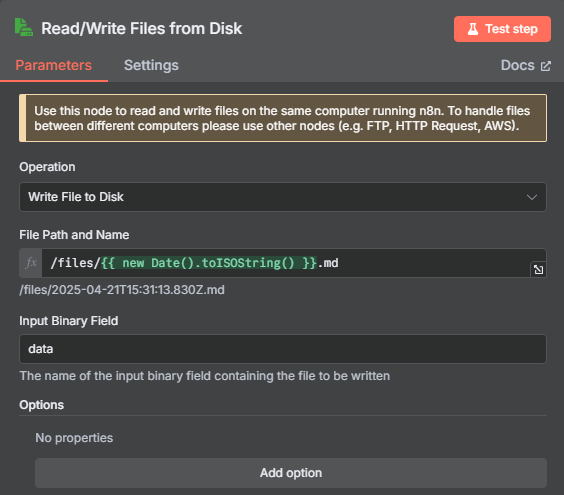
? ? ? ? 處理完目錄映射問題后,在 n8n 中我們使用 Write File to Disk 節點來進行保存操作,具體操作如下
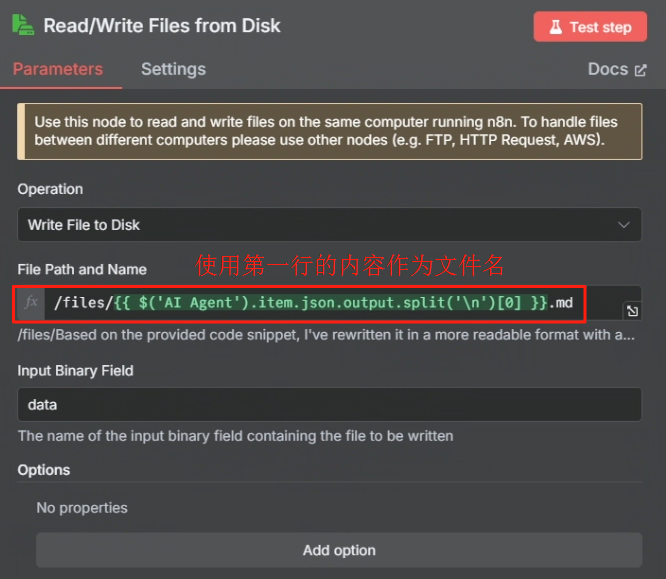
? ? ? ? 設置好運行后就能在 ./local-files 目錄中看到
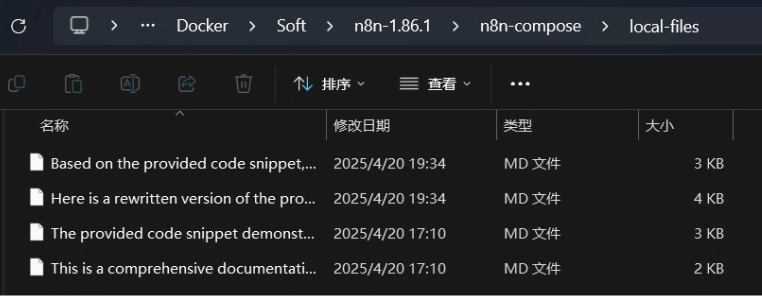
注意:每個人都可以設置成不同的目錄文件,參數 ./local-files:/files 冒號前面的?./local-files 是宿主機的目錄路徑,后面的 /files 是容器內的目錄路徑
9、抓取整個網站的 URL 并每個網頁保存一個文件
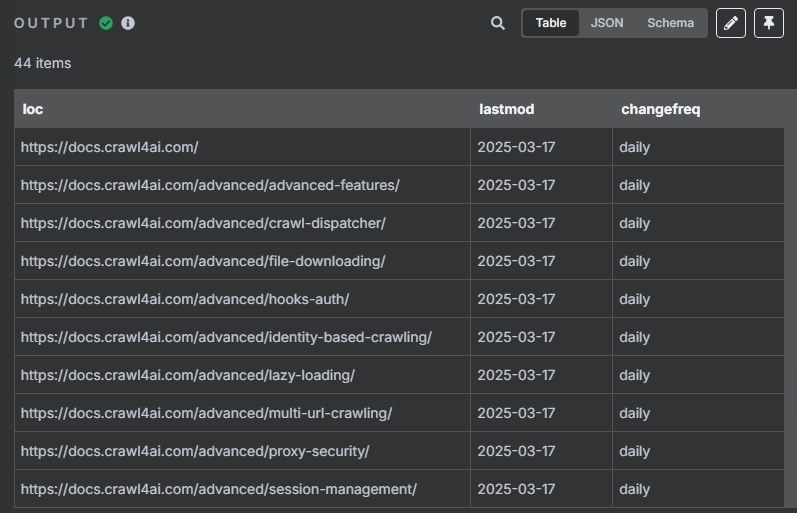
? ? ? ? 在分割節點當中我們可以看到,總共有 44 個 URL,我們需要循環處理這 44 個 URL
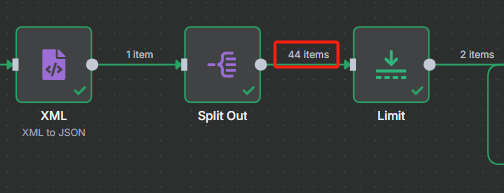
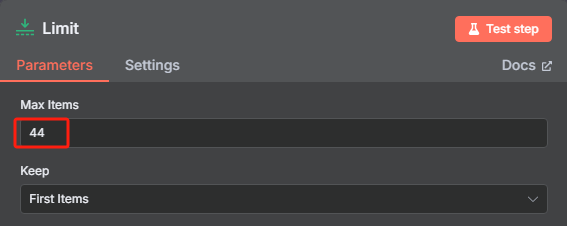
? ? ? ? ?但是我們在限制節點當中對數量進行了控制,那么我們只需要把限制的數量設置為 44 就可以對整個網站的 URL 進行處理了
?????????然后在文件儲存的時候我們需要把原來以第一行作為文件名改為以當前時間作為文件名,這樣才能避免文件名過長的錯誤
? ? ? ? 最終效果如下
備份與加載 Crawl4AI 的鏡像
一、備份?Crawl4AI 的鏡像
1、Crawl4AI?需要備份的鏡像有:unclecode/crawl4ai,我們可以使用以下命令來查看
docker image ls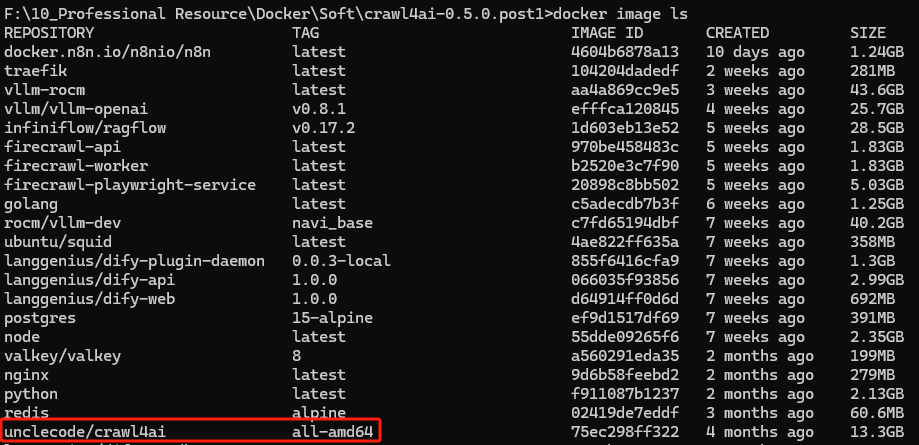
?2、使用下面的命令來進行備份
docker save -o "F:\10_Professional Resource\Docker\Images\crawl4ai_all-amd64_0.5.0.post1_images\unclecode_crawl4ai_all-amd64.tar" unclecode/crawl4ai

備份好的鏡像:https://pan.baidu.com/s/1Prag2BoG9S8JsKyZH6sbyQ?pwd=4rbm?提取碼:4rbm
二、加載 Crawl4AI 的鏡像
??? ? ? ? 將備份的鏡像拷貝到需要部署的機器之后使用以下命令進行鏡像的載入
docker load -i "F:\10_Professional Resource\Docker\Images\crawl4ai_all-amd64_0.5.0.post1_images\unclecode_crawl4ai_all-amd64.tar"? ? ? ? 加載完成后可以使用以下命令查看是否加載成功
docker image ls
????????當然也是需要重新下載源碼以及修改環境變量和配置文件的,請重復前面 Crawl4AI 的本地部署第四步中的相關點,在一切處理完成后就可以使用以下命令來啟動了
# 在 Crawl4AI 中 docker-compose.yml 文件的目錄下執行
docker compose up -d
-獲取具有相同屬性名稱的體對象)


![【Bug】 [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed](http://pic.xiahunao.cn/【Bug】 [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed)

)

詳細教程)
![解決SSLError: [SSL: DECRYPTION_FAILED_OR_BAD_RECORD_MAC] decryption faile的問題](http://pic.xiahunao.cn/解決SSLError: [SSL: DECRYPTION_FAILED_OR_BAD_RECORD_MAC] decryption faile的問題)


--單文件上傳)


)



