硬件環境
使用一塊技嘉 B85m-DS3H 安裝 P104-100, CPU是帶集成顯卡的i5-4690. 先在BIOS中設置好顯示設備優先使用集成顯卡(IGX). 然后安裝P104-100開機. 登入Ubuntu 后查看硬件信息, 檢查P104-100是否已經被檢測到
# PCI設備
lspci -v | grep -i nvidia
lspci | grep NVIDIA
# 查看顯示設備
sudo lshw -C display
安裝驅動
安裝前刪除原有的 nvidia 驅動
sudo apt purge 'nvidia-*'
sudo apt autoremove --purge
sudo apt clean
驅動有兩種安裝方式
使用 ubuntu 倉庫的 nvidia 驅動(nvidia開頭)
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
列出驅動的各個版本
ubuntu-drivers devices
選擇需要的版本安裝, 例如 對應CUDA12.4是nvidia-driver-550
sudo apt install nvidia-driver-XXX
使用 nvidia 的驅動倉庫(cuda開頭)
Doc: https://docs.nvidia.com/datacenter/tesla/driver-installation-guide/index.html
先下載對應Ubuntu版本的 cuda-keyring
- Ubuntu22.04 https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
- Ubuntu24.04 https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
用dpkg安裝, 然后apt update一下
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update
這時候可以查詢到能安裝的版本
apt-cache search cuda-drivers-*
挑選自己需要的版本安裝, 例如 cuda-drivers-550對應CUDA12.4, cuda-drivers-570對應CUDA12.8, 如果直接安裝 cuda-drivers, 會默認安裝當前穩定版的最高版本
sudo apt install cuda-drivers-550
檢查驅動安裝結果
驅動安裝完成后重啟, 此時應該就可以直接運行 nvidia-smi 查看顯卡信息了.
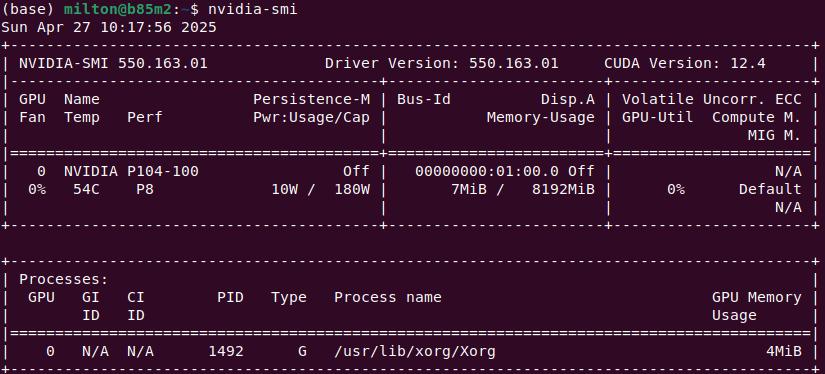
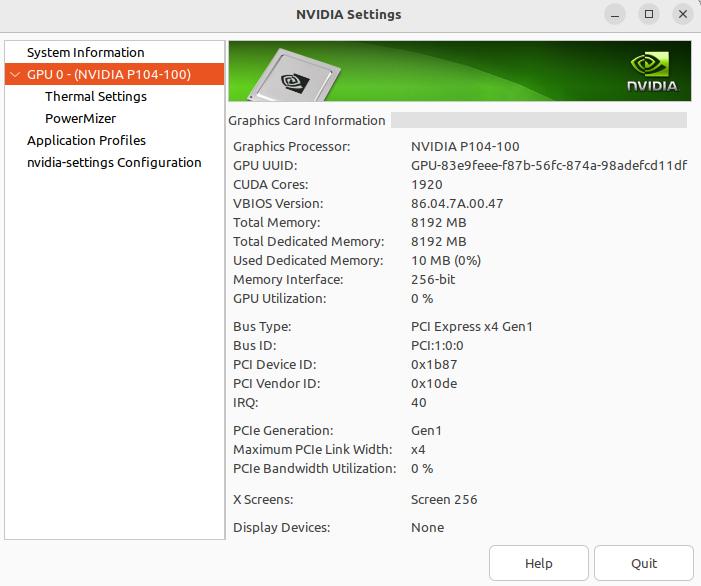
在桌面環境下, 可以直接查看圖形界面 Nvidia X Server Settings
# 查看 NVIDIA 內核模塊是否加載
lsmod | grep nvidia
# 查看dmesg日志
dmesg | grep -i nvidia
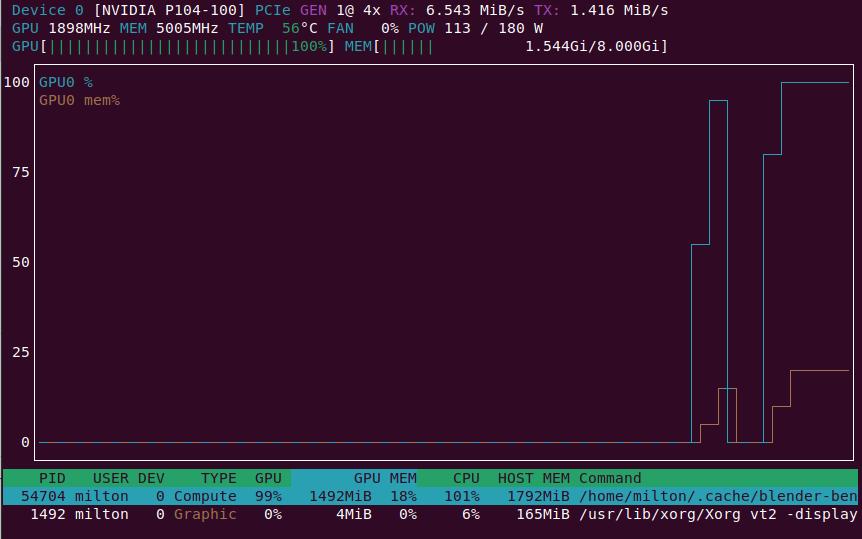
另外可以安裝兩個有用的小工具 nvtop 和 vulkaninfo
nvtop
nvtop 可以在命令行下以圖形化的方式顯示顯卡當前的運行狀態, 比nvidia-smi -l命令更直觀好用
# install
sudo apt install nvtop
# usage
nvtop
vulkaninfo
vulkaninfo 可以列出當前系統的GPU信息
# install
sudo apt install vulkan-tools
# show GPU info
vulkaninfo --summary
使用prime-select切換集成顯卡和Nvidia顯卡
安裝P104-100后, 系統中可以看到同時存在集成顯卡 Intel? HD Graphics 4600 和 NVIDIA P104-100, 可以通過 prime-select 切換使用的顯卡
# 查詢, 默認為 on-demand
prime-select query
# 設置為 P104-100
prime-select nvidia
# 設置為集成顯卡
prime-select intel
Ubuntu 對于 hybrid graphics 的支持很不錯, 安裝完驅動后, 程序已經可以自動選擇用哪塊顯卡, 例如運行 minetest, 就會自動選擇 P104-100.
性能測試
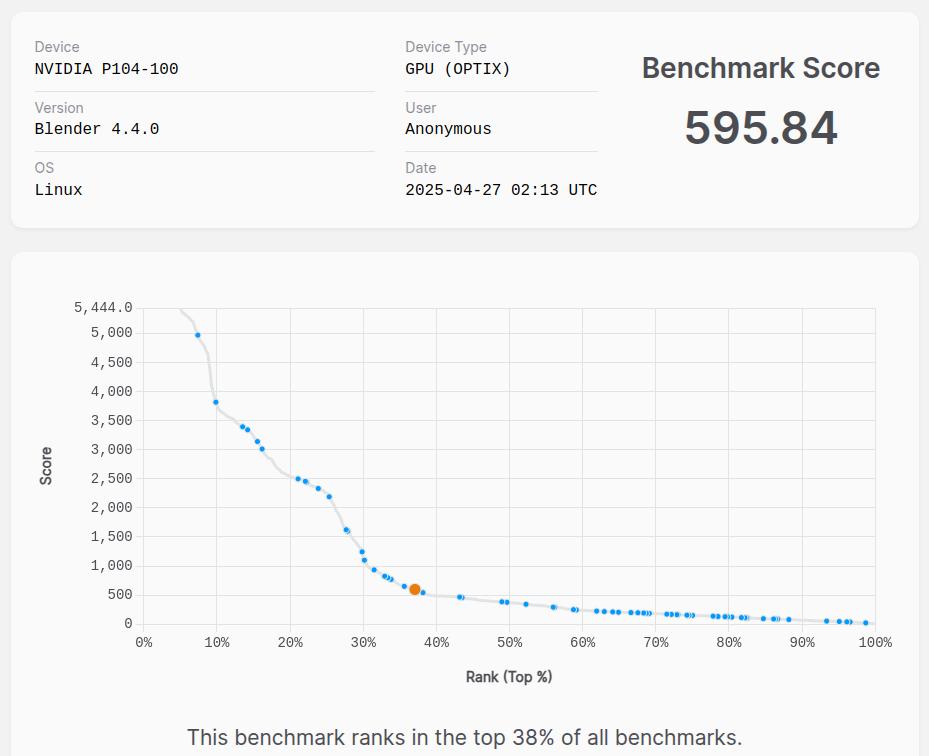
在Ubuntu下可以通過 Blender 的 Blender Benchmark 檢測顯卡性能, 網站: https://opendata.blender.org/, 進行測試前會提示要下載800多M的文件.
P104-100的運行結果分數為 58x~59x 之間, 在首頁上有CPU和GPU的排行數據, 可以看到 P104-100的性能和 GTX1080, GTX1070Ti 差不多. 作為對比, i5 4690 集成顯卡的測試結果分數只有 51.91, 與 P104-100 相比差距明顯.
安裝 CUDA Toolkit
使用apt安裝
在Ubuntu下可以直接用apt安裝CUDA toolkit, 但是這樣安裝后toolkit的路徑是分散的, 不在 /usr/local/cuda 下, 有時候會造成困惑, 建議用 Nvida 提供的安裝包進行安裝
使用Nvidia提供的安裝包
從歷史版本列表 https://developer.nvidia.com/cuda-toolkit-archive 選擇安裝對應當前硬件驅動的 CUDA Toolkit. 對應上面安裝的 CUDA 版本為12.4, 因此下載 Cuda Toolkit 12.4. 頁面會提供三種安裝方式 deb(local), deb(network), runfile(local), 新手用戶建議使用前兩種, 因為runfile 涉及現場編譯, 大概率中間過程會報錯. deb(local)和deb(network)的區別就是有一個差不多4G大小的文件, 是先下載到本地了再 apt install, 還是先 apt install完在安裝過程中從網絡下載. 如果網絡不是特別好, 網速不是特別快的, 建議使用 deb(local).
這個是界面上提示的安裝命令
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb
dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.1-550.54.15-1_amd64.deb
cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/
apt update
apt install cuda-toolkit-12-4
CUDA的默認安裝位置是 /usr/loca/cuda, 安裝完成后檢查安裝結果
/usr/local/cuda/bin/nvcc -V
通過這種方式安裝的CUDA toolkit 是不會設置用戶環境變量的, 需要手動在 .bashrc 里添加一下
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CUDA_HOME/lib64
export PATH=$PATH:$CUDA_HOME/bin
運行 TorchBench
項目地址: https://github.com/pytorch/benchmark
CUDA Device Query
[CUDA Bandwidth Test] - Starting...
Running on...Device 0: NVIDIA P104-100Quick ModeHost to Device Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 0.4Device to Host Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 0.4Device to Device Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 284.0Result = PASS
CUDA Device Query
CUDA Device Query (Runtime API) version (CUDART static linking)Detected 1 CUDA Capable device(s)Device 0: "NVIDIA P104-100"CUDA Driver Version / Runtime Version 12.4 / 12.0CUDA Capability Major/Minor version number: 6.1Total amount of global memory: 8109 MBytes (8503230464 bytes)(015) Multiprocessors, (128) CUDA Cores/MP: 1920 CUDA CoresGPU Max Clock rate: 1734 MHz (1.73 GHz)Memory Clock rate: 5005 MhzMemory Bus Width: 256-bitL2 Cache Size: 2097152 bytesMaximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal shared memory per multiprocessor: 98304 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 2 copy engine(s)Run time limit on kernels: YesIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: DisabledDevice supports Unified Addressing (UVA): YesDevice supports Managed Memory: YesDevice supports Compute Preemption: YesSupports Cooperative Kernel Launch: YesSupports MultiDevice Co-op Kernel Launch: YesDevice PCI Domain ID / Bus ID / location ID: 0 / 1 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.4, CUDA Runtime Version = 12.0, NumDevs = 1
Result = PASS







)


:開發環境搭建)


)





