通過示例學習:連續 XOR
如果我們想在 PyTorch 中構建神經網絡,可以使用 (with) 指定所有參數(權重矩陣、偏差向量),讓 PyTorch 計算梯度,然后調整參數。但是,如果我們有很多參數,事情很快就會變得繁瑣。在 PyTorch 中,有一個名為 Package,它使構建神經網絡更加方便。Tensorsrequires_grad=Truetorch.nn
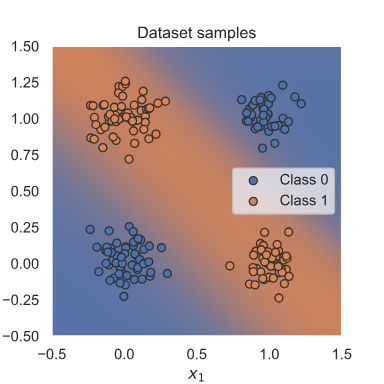
將介紹在 PyTorch 中訓練神經網絡可能需要的庫和所有其他部分,并在一個簡單但眾所周知的示例 XOR 上使用一個簡單的示例分類器。給定兩個二進制輸入x1和x2,則要預測的標簽為1如果x1或x2是1而另一個是0,或者標簽為0在所有其他情況下。這個例子因單個神經元(即線性分類器)無法學習這個簡單的函數而出名。 因此,將學習如何構建一個可以學習此函數的小型神經網絡。 為了更有趣,我們將 XOR 移動到連續空間,并在二進制輸入上引入一些高斯噪聲。期望的 XOR 數據集分離如下所示:
該包定義了一系列有用的類,如線性網絡層、激活函數、損失函數等。完整列表可在此處找到。如果您需要某個網絡層,請先查看包的文檔,然后再自己編寫該層,因為該包可能已經包含其代碼。我們在下面導入它:torch.nn
[1]:
import torch.nn as nn
此外,還有 。它包含在網絡層中使用的函數。這與定義它們的方式形成鮮明對比(更多內容見下文),并且實際上使用了 中的許多功能。因此,功能包在許多情況下都很有用,因此我們在這里也導入它。torch.nntorch.nn.functionaltorch.nnnn.Modulestorch.nntorch.nn.functional
[2]:
import torch.nn.functional as F
nn.模塊
在 PyTorch 中,神經網絡是由模塊構建的。模塊可以包含其他模塊,神經網絡本身也被視為一個模塊。模塊的基本模板如下:
[3]:
class MyModule(nn.Module):def __init__(self):super().__init__()# Some init for my moduledef forward(self, x):# Function for performing the calculation of the module.pass
forward 函數是進行模塊計算的地方,并在您調用 module () 時執行。在 init 函數中,我們通常使用 來創建模塊的參數,或者定義 forward 函數中使用的其他模塊。向后計算是自動完成的,但如果需要,也可以被覆蓋。nn?=?MyModule();?nn(x)nn.Parameter
簡單分類器
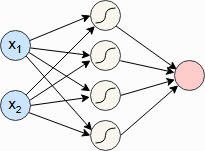
我們現在可以使用包中的預定義模塊,并定義我們自己的小型神經網絡。我們將使用一個最小網絡,其中包含一個輸入層、一個以 tanh 作為激活函數的隱藏層和一個輸出層。換句話說,我們的網絡應該看起來像這樣:torch.nn
輸入神經元以藍色顯示,表示坐標和數據點。包括 tanh 激活在內的隱藏神經元顯示為白色,輸出神經元顯示為紅色。在 PyTorch 中,我們可以按如下方式定義它:x1x2
[4]:
class SimpleClassifier(nn.Module):def __init__(self, num_inputs, num_hidden, num_outputs):super().__init__()# Initialize the modules we need to build the networkself.linear1 = nn.Linear(num_inputs, num_hidden)self.act_fn = nn.Tanh()self.linear2 = nn.Linear(num_hidden, num_outputs)def forward(self, x):# Perform the calculation of the model to determine the predictionx = self.linear1(x)x = self.act_fn(x)x = self.linear2(x)return x
對于本筆記本中的示例,我們將使用一個具有兩個輸入神經元和四個隱藏神經元的微型神經網絡。當我們執行二元分類時,我們將使用單個輸出神經元。請注意,我們還沒有對輸出應用 sigmoid。這是因為其他函數(尤其是 loss)在原始輸出上計算時比在 sigmoid 輸出上計算時更有效、更精確。我們稍后會討論詳細原因。
[5]:
model = SimpleClassifier(num_inputs=2, num_hidden=4, num_outputs=1)
# Printing a module shows all its submodules
print(model)
SimpleClassifier((linear1): Linear(in_features=2, out_features=4, bias=True)(act_fn): Tanh()(linear2): Linear(in_features=4, out_features=1, bias=True)
)
打印模型會列出它包含的所有子模塊。可以使用模塊的函數獲取模塊的參數,也可以獲取每個參數對象的名稱。對于我們的小型神經網絡,我們有以下參數:parameters()named_parameters()
[6]:
for name, param in model.named_parameters():print(f"Parameter {name}, shape {param.shape}")
Parameter linear1.weight, shape torch.Size([4, 2])
Parameter linear1.bias, shape torch.Size([4])
Parameter linear2.weight, shape torch.Size([1, 4])
Parameter linear2.bias, shape torch.Size([1])
每個線性層都有一個形狀為 的權重矩陣和一個形狀為 的偏置。tanh 激活函數沒有任何參數。請注意,僅為作為直接對象屬性的對象注冊參數,即 .如果定義模塊列表,則這些模塊的參數不會注冊到外部模塊,并且在嘗試優化模塊時可能會導致一些問題。有一些替代方案,如 , 和 ,允許您擁有不同的模塊數據結構。我們將在后面的一些教程中使用它們,并在那里解釋它們。[output,?input][output]nn.Moduleself.a?=?...nn.ModuleListnn.ModuleDictnn.Sequential











 D. Baggage Claim(建圖))
技術的最新進展可總結)



)


