目錄
前言
1. 索引 (index)
1.1 概念
1.2 作用
1.3 使用場景
1.4 索引的相關操作
查看索引
創建索引
刪除索引
2. 索引背后的數據結構
2.1 B+樹
2.2 B+樹的特點
2.3 B+樹的優勢
3. 事務
3.1 為什么使用事務
3.2 事務的概念
3.3 使用事務
3.4 事務四大關鍵特性
4. 事務隔離性解決并發問題
4.1 臟讀問題
4.2 不可重復讀
4.3 幻讀
4.4 隔離級別
前言
數據庫使用 select 查詢的時候:
- 先遍歷表
- 把當前的行給帶入到條件中,看條件是否成立
- 條件成立,這樣的行就保留。不成立就跳過。
- 如果表非常的小,正常使用沒問題。如果表非常大,這樣的遍歷成本就比較高了。
- 站在時間復雜度角度,每次從內存中讀取一條一條記錄,進行比較至少是O(N)。時間復雜度和空間復雜度的計算都是針對內存中數據進行的操作。讀取內存的訪問速度非常快,計算時間復雜度不包含讀取內存的時間,依據是基于操作的執行(比較)次數。
- 數據庫是把數據存儲在硬盤上,每次需要先讀取硬盤拿到一個數據,再進行比較。
- 讀取硬盤這個操作,開銷本身就是很大的。讀寫1次硬盤開銷遠遠大于讀寫1次內存。讀1次硬盤相當于讀1萬次內存。如果是N個數據,頻繁進行讀取更是慢上加慢。
所以就引出了索引,增加遍歷查詢速度,減少硬盤的訪問次數。針對查詢操作引入的優化手段。
1. 索引 (index)
索引英文是 index,這里的 index 指的是索引,并不是數組下標。
1.1 概念
索引是一種特殊的文件,包含著對數據表里所有記錄的引用指針。可以對表中的一列或多列創建索引,并指定索引的類型,各類索引有各自的數據結構實現。(具體細節在后續的數據庫原理課程講解)
1.2 作用
- 索引屬于是針對查詢操作引入的優化手段。可以通過索引來加快查詢的速度,減少硬盤的訪問次數,避免針對表進行遍歷。
- 數據庫中的表、數據、索引之間的關系,類似于書架上的圖書、書籍內容和書籍目錄的關系。
- 索引所起的作用類似書籍目錄,可用于快速定位、檢索數據。
引入索引的代價:
- 索引會占用額外的磁盤空間,付出額外空間代價來保存索引數據。生成索引,是需要一系列的數據結構,以及一系列的額外的數據,來存儲到硬盤空間中的。
- 索引加快了查詢速度,但可能會拖慢新增,刪除,修改的速度。因為新增、刪除、修改數據還需要同步新增、刪除、修改索引,產生額外的開銷。例如,修改論文的標題,需要同步修改目錄。
整體來說,還是認為索引是利大于弊。實際開發中,查詢(讀)場景一般要比增刪改(寫)頻率高很多。
1.3 使用場景
要考慮對數據庫表的某列或某幾列創建索引,需要考慮以下幾點:
- 數據量較大,且經常對這些列進行條件查詢。
- 該數據庫表的插入操作,及對這些列的修改操作頻率較低。
- 不太在意,索引占用額外的磁盤空間。
滿足以上條件時,考慮對表中的這些字段創建索引,以提高查詢效率。
反之,如果非條件查詢列,或經常做插入、修改操作,或磁盤空間不足時,不考慮創建索引。
1.4 索引的相關操作
創建主鍵約束(PRIMARY KEY)、唯一約束(UNIQUE)、外鍵約束(FOREIGN KEY)時,會自動創建對應列的索引。
為什么創建這三個約束,會自動創建對應列的索引:
- primary key 和 uniqe 都是要求對應列的記錄不能重復,每次插入/修改被約束列的數據,需要查詢判斷是否重復。涉及頻繁的查詢操作。優化查詢速度,自動引入索引,查詢跟著索引走就不需要一條條記錄去遍歷了,大大加快了插入/修改的速度。
- foreign key 約束的時候,子表中對應的記錄要在父表中存在。往子表中插入/修改對應約束列的數據時,就需要每次查詢父表中是否存在。反之,從父表中修改/刪除數據時,也需要查詢該數據在子表中是否被引用。涉及頻繁的查詢操作。優化查詢速度,自動引入索引。
-
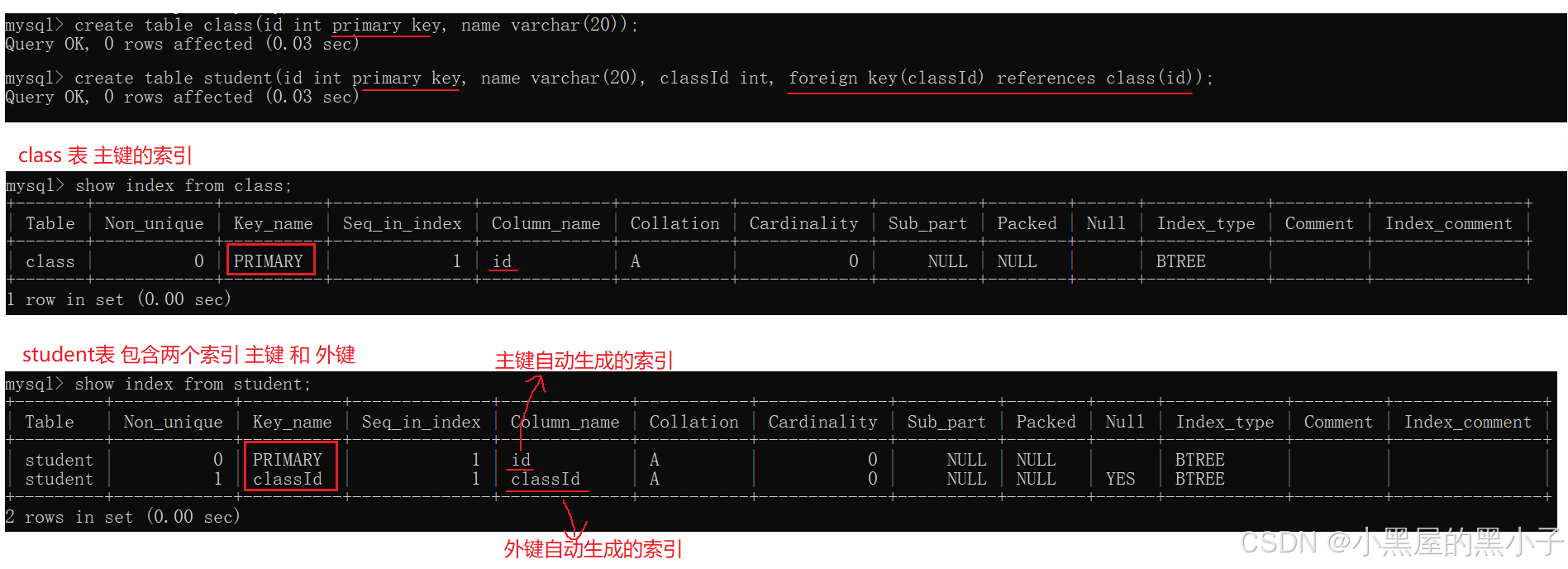
查看索引

 primary key 主鍵自動生成的索引
primary key 主鍵自動生成的索引
- 可以理解為:student表中內容,根據id列生成了一份目錄;這里自動創建的索引名為primary
- 索引表中的列大概認識一下,不需要全部了解。
- 一個索引是針對一個列來指定的。
- 只有針對這一列進行條件查詢的時候,查詢速度才能夠被索引優化。
例如:
- 此處針對 id 創建索引。使用id進行條件查詢,速度是很快。
- select * from student where id = 100; ——? 使用索引,不需要一條條記錄遍歷。
- select * from student where name = '張三';? —— 仍然需要遍歷表。
unique? 自動生成的索引
foreign key 外鍵自動生成的索引
- 一本書可以有多個目錄。一個表也可以有多個索引,每個索引針對不同列。
- 例如:一個字典,目錄有多種。拼音目錄、筆畫目錄、部首目錄、難檢字目錄。

-
創建索引
對于非主鍵、非唯一約束、非外鍵的字段,可以創建普通索引。


- 創建索引操作,也是一個危險操作;創建索引的時候,需要針對現有的數據,進行大規模的重新整理。如果當前表是一個空表或者數據不多,創建索引都沒有問題。但如果這個表很大,創建索引開銷會很大,很容易就把數據庫服務器給卡住。
例如:有一本很厚的書,現在給這個書手動的寫一份目錄出來。好的做法,是創建表之初就把索引設定好。
- 一般來說,創建索引,在創建表時已經規劃好了。如果表使用了很久,有很多數據,再想創建索引,就要慎重了。
如果表很大,堅持要創建索引,使用“移花接木”的技巧方式,尤其是生產環境(線上)的數據庫。做法:在另外一臺機器部署mysql服務器,創建同樣的表,并且把表上的索引創建好,再把之前的機器上的數據給導入到新的mysql服務器上。控制導入數據過程的節奏,多花點時間導數據,不要影響到原來服務器正常的運轉。當所有數據都導入完畢,就可以使用新的數據庫,替換舊的數據庫了。
-
刪除索引

- 手動創建的索引,可以手動刪除。自動創建的索引(主鍵/外鍵,unique),不可以刪除。
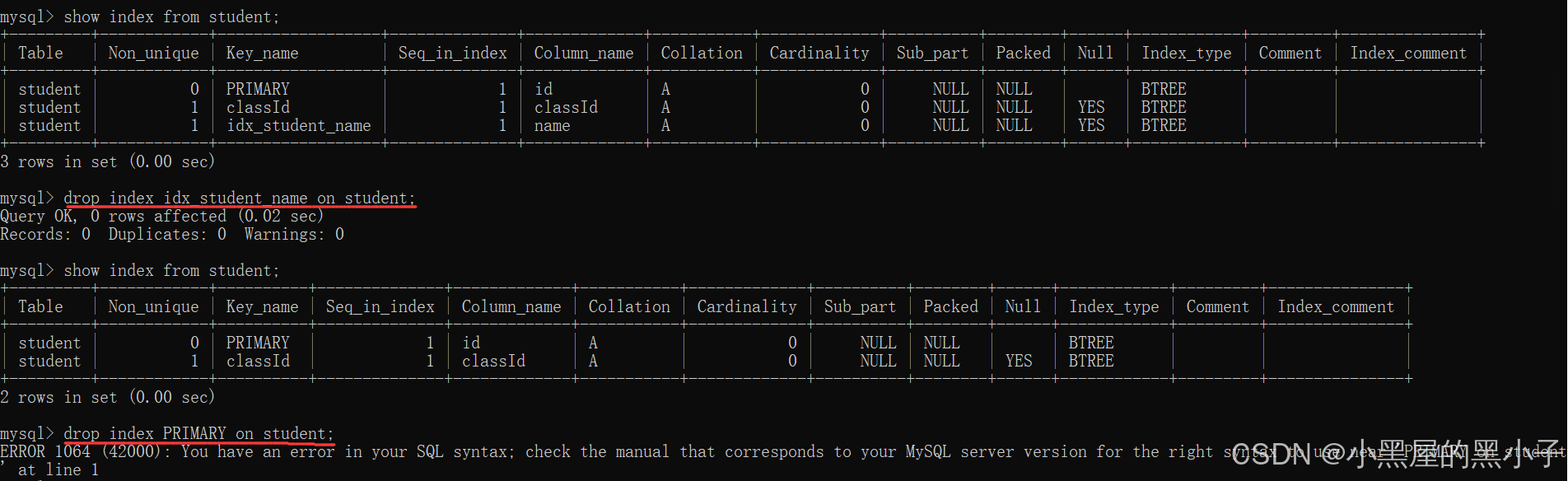
和創建索引類似,刪除索引也是一個危險操作。理由同上。
2. 索引背后的數據結構
索引是通過一定的數據結構來實現的。B+樹(N叉搜索樹),為數據庫量身定做的數據結構。
哪些數據結構能加快查詢的速度,mysql的索引的數據結構為什么不能是順序表,鏈表,棧,隊列,二叉搜索樹,哈希表呢?
- 1. 順序表? ?查詢元素時間復雜度O(N)
在順序表中間插入或刪除元素需要移動大量數據,效率較低。
當容量不足時,需要重新分配更大的存儲空間,并拷貝所有數據。
在大規模數據中進行隨機查詢效率低,尤其是當數據需要排序時。
- 2. 鏈表??查詢元素時間復雜度是 O(N)
鏈表不支持隨機訪問,必須從頭開始遍歷,查詢時間復雜度是 O(N)。
每個節點需要額外的指針存儲,內存開銷較高。鏈表不能快速進行范圍查詢。
鏈表廣義上插入/刪除的時間復雜度為O(1),但java中具體實現LinkeList插入/刪除的時間復雜度為O(N),需要遍歷找到要插入/刪除元素的位置。
- 3. 棧、隊列、堆? ?查詢元素時間復雜度是 O(N)
棧和隊列只適合用于簡單的順序操作,不支持高效的隨機查詢、范圍查詢或復雜操作。
棧和隊列不支持快速的插入、刪除或排序操作。
- 4. 二叉搜索樹? ?查詢元素時間復雜度是 O(N)/O(logN)
一個普通的二叉搜索樹,查詢時間復雜度是O(N),因為會存在不平衡的極端情況(單枝樹),如果引入平衡機制(AVL樹,紅黑樹)可以達到O(logN)。
實際開發中用紅黑樹比較多一些,因為AVL樹要保持左右子節點的高度差不會超過1,要求太嚴格,觸發調整的頻率就比較高,有一定額外開銷。紅黑樹雖然近似平衡二叉樹,但左右子節點的高度差保持在一定范圍內即可,沒有AVL要求的那么嚴格,綜合能力更好些。(數據結構進階篇會介紹)
- 5. 哈希表 查詢時間復雜度是 O(1)
通過計算哈希函數映射到數組的下標。
從前面所學習的數據結構中,可知道紅黑樹(二叉搜索樹)和哈希表都能提高查詢速度,但是并不適合數據庫的查詢場景。
mysql數據庫中查詢操作經常會用到:精準查詢、范圍查詢、模糊匹配等查詢操作。
所以實現索引的數據結構至少能夠滿足以上的查詢操作。 索引針對的列的模糊匹配只是一部分的實現。也就是并非所有的查詢操作都能用到索引。
知道第一個字符,就可以通過第一個字符大小關系,來縮小查詢范圍,這個操作可以一定程度上使用索引。不知道第一個字符,每個字符都有可能,仍然需要遍歷。

- 哈希表,哈希表只能進行“精準匹配”,無法做到范圍查詢和模糊查詢。?
- 紅黑樹(平衡二叉搜索樹),可以處理精準匹配、范圍查詢(元素是有序的找到開頭,找到結尾就可以找到)、能一定程度的模糊匹配,但最大的問題是樹的高度。
最大的問題:紅黑樹是二叉樹(平衡),每個節點最多兩個子樹,樹的分叉少(結點的度少),表示同樣數量的結果集合,樹的高度就會更高。
一旦樹的高度更高了,查詢操作的時候硬盤IO訪問次數就會更多。考慮每個節點都要觸發IO,如果是一個二叉樹,在查詢葉子節點元素就要從樹根一路往下找,找到葉子節點,每往下走一層就是IO一次,高度有多少,IO次數就有幾次,所以這樣的操作是比較低效的。?因此數據庫引入的索引是一個改進的樹形結構,B+樹(N叉搜索樹)。

2.1 了解B樹
要了解B+樹需要先了解下B樹,B樹有的時候會寫作B - 樹,不是B減樹仍是B樹的意思。?'-' 是連接符的意思,不是數學中的減符號。
B樹的核心思路和"二叉搜索樹"差不多。B樹本質上是一個N叉搜索樹。
由于是N叉搜索樹,有N個分叉,每個分叉代表一個區間,此時意味著當前節點里面就可以存儲多個key。
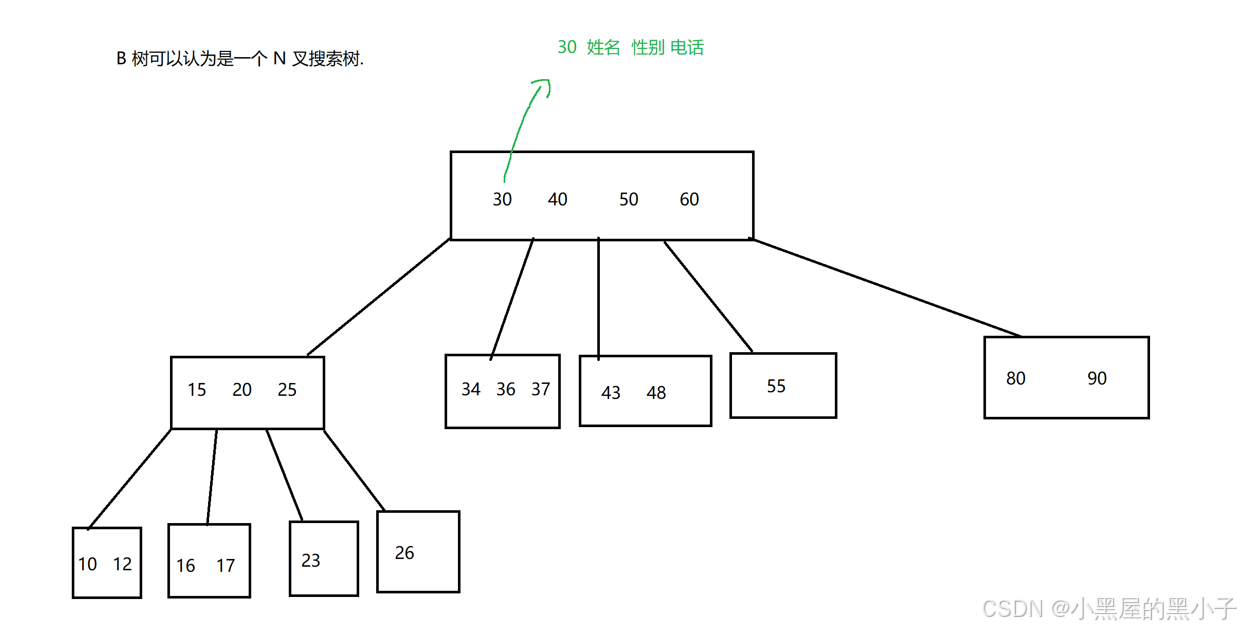
- 每個節點的度都是不確定的。當節點的子樹多了以及節點上保存的key多了,意味著在同樣key 的個數的前提下,B樹的高度就要比二叉搜索樹低很多,樹的高度越低,進行查詢的時候訪問磁盤的次數就越少,速度就大大提升。
- B樹的查詢基本思路與二叉搜索樹的查詢思路是相似的,只不過B樹是分了N叉,每個節點中有多個key,需要進行多次比較,確定走哪個區間,從而走哪個子樹。
- 一個節點上保存N個key就劃分出N+1個區間。每個區間都可以衍生出一系列的子樹了。樹的高度就大幅度的降低了。
- 由于每個節點是在一個硬盤的區域中,一次讀硬盤就讀取出了整個節點(多個key )再進行幾次比較。(讀一次硬盤的開銷遠遠大于內存中比較的開銷,讀一次硬盤相當于內存中1w次比較。這里的比較操作一般都不會到幾萬,都是幾個或十幾個元素,這里的比較操作并不會特別耗時,相對于讀取硬盤來說是非常輕量的,沒有太大影響)
- 一個節點中,雖然是可以保存N個key,也不是無限制的,達到一定的規模,就會觸發節點的分裂。當刪除元素達到一定的數目,也會觸發節點的合并(簡化樹形結構)。
- 具體什么時候進行拆分,怎么拆分;具體什么時候合并,怎么合并。實際的實現中,不同的場景下可以使用不同的策略。
2.2?B+樹
B+樹,在B樹的基礎上又做出改進(也是N叉搜索樹),針對數據庫量身定做的。
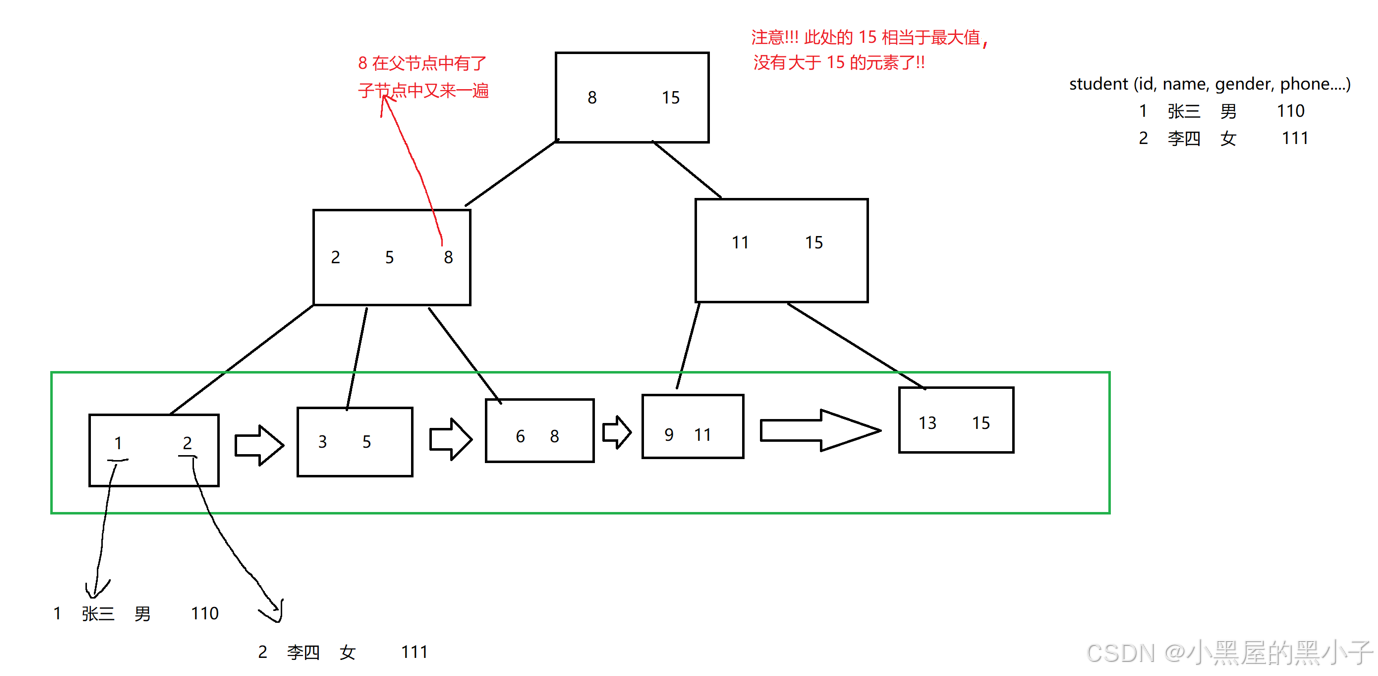
- 整個樹的所有數據都是包含在葉子節點中的(所有非葉子節點中的key最終都會出現在葉子節點中)
- 上述這個結構,是默認id是表的主鍵,如果這個表里有多個索引呢?
- 針對id是主鍵創建索引,表的數據還是按照 id為主鍵,構建出B+樹通過葉子節點組織所有的數據行。
- 其次,針對 name這一列,則會構建另外一個B+樹,但是這個B+樹的葉子節點就不再存儲這一行的完整數據,而是存主鍵id是啥,此時,如果你根據name來查詢,查到葉子節點得到的只是主鍵id,還需要再通過主鍵id去主鍵的B+樹里再查一次(查兩次B+樹),上述過程稱為“回表",這個過程,都是mysql自動完成的,用戶感知不到。
- 上面的這個樹形結構,是"索引",如果這一列不能比較,就沒法建立索引;幸運的是, mysql里的各種類型都能比較,數字、字符串、時間日期。 故mysql中不支持自定義類型
2.3?B+樹的特點
- 一個節點,可以存儲N 個key,N個key劃分出了N個區間(而不是B樹中的N+1個區間)
- 每個節點中的key的值,都會在子節點中也存在(同時該key是子節點的最大值,也可以是最小值)
- B+樹的葉子節點,是首尾相連,類似于一個鏈表
- 由于葉子節點是完整的數據集合,所以只在葉子節點這里存儲數據表中的每一行的數據,而非葉子節點,只存key值本身即可。
2.4?B+樹的優勢
1、當前一個節點保存更多的 key,最終樹的高度是相對更矮的,查詢的時候減少了IO訪問次數(和B樹是一樣的)這里IO特指硬盤的訪問

2、所有的查詢最終都會落到葉子節點上(查詢任何一個數據,經過的IO訪問次數,是一樣的)
這個相同次數很關鍵,穩定的能夠讓程序猿對于程序的執行效率有一個更準確的評估。
3、B+樹的所有的葉子節點,構成鏈表,此時比較方便進行范圍查詢。
例如:查詢學號>5并且<11的同學。只需要先找到5所在的位置,在找到11所在位置從5沿著鏈表遍歷到11,中間結果即為所求,非常方便非常高效。
4、由于數據都在葉子節點上,非葉子節點只存儲key,導致非葉子節點占用空間是比較小的,這些非葉子節點就可能在內存中緩存(或者是緩存一部分),又進一步減少了IO的次數。 常量池本質上就是緩存。
例如:假設一個整數按照4個字節算,10億個這樣的整數,占據多大內存空間?(估算即可,不用精確)10億個這樣的 key才不到4G,4G對于計算機內存來說還是非常容易的。
帶有索引的數據, mysql 組織數據就是B+樹的方式;當你看到一張"表”的時候,實際上這個表不一定就是按照"表格"這樣的數據結構在硬盤上組織的,也有可能是按照這種樹形結構組織。具體是哪種結構,取決于你的表里有沒有索引,以及數據庫使用了哪種存儲引擎。
3. 事務
3.1 為什么使用事務
開發中經常會涉及到一些場景,需要“一氣呵成”的完成一些操作。
【案例】
- 準備測試表:
drop table if exists accout;
create table accout(id int primary key auto_increment, name varchar(20) comment '賬戶名稱', money decimal(11,2) comment '金額');
insert into accout(name, money) values('阿里巴巴', 5000),('四十大盜', 1000);
- 比如說,四十大盜把從阿里巴巴的賬戶上偷盜了2000元
-- 阿里巴巴賬戶減少2000
update accout set money = money-2000 where name = '阿里巴巴';
-- 四十大盜賬戶增加2000
update accout set money = money+2000 where name = '四十大盜';
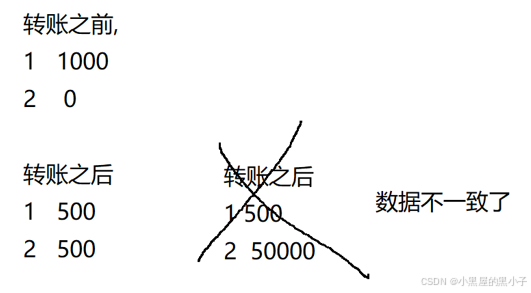
- 假如在執行以上第一句SQL時,出現網絡錯誤,或是數據庫掛掉了,阿里巴巴的賬戶會減少2000,但是四十大盜的賬戶上就沒有了增加的金額。這是比較嚴重的錯誤。此時,數據就會出現“不上不下”的中間狀態,非常明顯的bug!!!
引入事務就是為了避免上述的問題。
解決方案:使用事務來控制,保證以上兩句SQL要么全部執行成功,要么全部執行失敗。
事務的本質就是把多個sql語句給打包成一個整體,要么全部執行成功,要么全部執行失敗。而不會出現"執行一半"這樣的中間狀態。
3.2 事務的概念
事務指邏輯上的一組操作,組成這組操作的各個單元,要么全部成功,要么全部失敗。
在不同的環境中,都可以有事務。對應在數據庫中,就是數據庫事務。
- 把多個sql語句給打包成一個整體:稱為原子性(atom);過去的人們認為原子是事物能夠分割的最小單位。現在并非原子是最小分割單位。
- 全部執行失敗:不是真的沒執行,而是"看起來好像沒執行一樣",其實是執行了,執行一半出錯了,出錯之后選擇了恢復現場,把數據還原成未執行之前的狀態了。
- 這個恢復數據的操作,稱為“回滾" (rollback)
【案例】
- 單獨執行的每個sql都是自成一個體系,此時這些sql之間是沒有原子性的。
- 如果把這倆操作作為一個事務,當第一個 sql執行完之后,數據庫崩潰。當下次數據庫重新啟動完成之后,就會自動的把上次修改一半的數據給進行還原(把1號用戶-500再加回來就行了)。

3.3 使用事務
- 開啟事務:start transaction;?
- 執行多條SQL語句。這個過程中某個環節出現問題,例如程序崩潰/數據庫崩潰/機器斷電了,就會自動觸發回滾機制。
- 提交或主動觸發回滾:commit/rollback;
- commit;? 提交事物,意思是下面沒有sql語句了,該事務結束了。事務結束的標記。
- rollback 是主動觸發回滾。出錯有很多情況,崩潰/斷電只是其中一種(會自發觸發回滾),有時候需要主動通過代碼方式判斷當前是否需要回滾。所以rollback一般是要搭配一些條件判斷邏輯來使用的。sql里也能支持條件,循環,變量,函數...,但是日常開發一般不會這么寫,更多的是搭配其他的編程語言。例如使用java操作數據庫,在java中主動判定某個結果是否符合要求,如果不符合要求進行主動回滾。
- 說明:rollback即是全部失敗,commit即是全部成功。

回滾是怎么做到,把數據還原成未執行的狀態?
依據日志中的記錄,進行回滾操作 。?例如日志里記錄的操作是插入,回滾根據記錄就刪除。記錄的操作是刪除,回滾根據記錄就插入。如果記錄的操作是修改,回滾根據記錄就改回去。
- 數據庫里專門有個用來記錄事務關鍵操作的日志(正因為如此,使用事務的時候,執行sql的開銷是更大的,效率是更低)。日志:是打印出來的內容,存放在文件里。
- 日志是存放在文件中的,所以即使是主機掉電,也不影響(回滾用的日志已經在文件中了)。后續一旦重新啟動主機,mysql也重新啟動,就會發現回滾日志中有一些需要進行回滾的操作。于是就可以完成這里的回滾了。
3.4 事務四大關鍵特性
數據庫的事務,有四個關鍵的特性:
- 原子性:把多個sql語句給打包成一個整體,要么全部執行成功,要么全部執行失敗 ——最核心的特性
- 一致性:事務執行前后,數據要合理。(很多時候是要靠數據庫的約束以及一系列的檢查機制來完成的)
???????3. 持久性:事務修改的內容是寫到硬盤上持久保存的。重啟服務器,數據仍然是存在的。
???????4. 隔離性:是為了解決"并發"執行多個事務,引起的問題。
并發:
- 一個餐館(服務器),同一時刻能給多個顧客(客戶端)提供服務,這些顧客可能是一個接一個來的,也可能是一起來了一波顧客。
- 此時,服務器同時處理多個客戶端的請求,就稱為"并發"(齊頭并進的感覺)。
- 同時能處理客戶端請求越多,并發程度越高,整體的效率就越高。
- 數據庫也是服務器,一定會存在多個客戶端給服務器提交事務的情況。為了提高效率,就會提高并發程度,但在數據庫中提高并發程度之后,可能存在一些問題,會導致數據出現一些“錯誤”的情況。
- 隔離級別,就是在"數據正確"和"效率"之間做權衡。往往提升了效率,就會犧牲正確性;提升了正確性,就會犧牲效率。
- 事務的隔離性,存在的意義就是為了在數據庫并發處理事務的時候不會有問題,即使有問題,問題也不會太大。
4. 事務隔離性解決并發問題
下面介紹,數據庫中并發執行事務可能產生的問題,以及數據庫的隔離性是怎樣解決的。
4.1 臟讀問題
問題描述:
- 在我寫代碼的過程中,同學在我身后經過, 他瞄了一眼我的屏幕,看到了我的代碼中寫了一些內容,比如他看到了,我的代碼里有一個class Student,有一些屬性,id, name,gender... 然后他就走了,很可能他走了之后,我的代碼又改了。
- 即一個事務A正在對數據進行修改的過程中,還沒提交之前;另外一個事務B,對同一個數據進行了讀取,此時B的讀操作就稱為“臟讀",讀到的數據也稱為"臟數據"。
- 臟的意思,是"無效",而不是埋汰。為啥說無效?很可能,A回頭又把數據給修改了。即另一個事務讀取到的數據不一定是最終的結果,可能是無效數據。
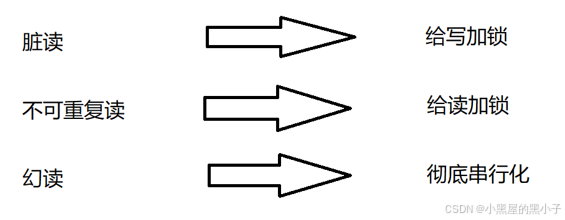
解決方法:寫的時候不能讀,寫操作加鎖。
- 為了解決臟讀問題,mysql 引入"寫操作加鎖"這樣的機制。
- 即我和同學們商量好,我寫代碼的過程中你別來看 ,等我改完提交到碼云上,你再通過我的碼云來看,寫的時候不能看(給寫操作加鎖),寫完了才能看。
- 當我寫的時候同學沒法讀,意味著我的“寫操作"和同學的"讀操作"不能并發了(不同同時執行了)
- 這個給寫加鎖的操作,就降低了并發程度(降低了效率),提高了隔離性(提高了數據的準確性)
4.2 不可重復讀
問題描述:
- 還是我寫代碼,同學想看,約定好我寫的時候不許看,等我提交了,再通過碼云來看。當前約定好了寫加鎖。
- 我寫代碼提交了版本1,此時就有同學開始讀這個代碼了;于是我又打開代碼繼續修改優化代碼,然后又提交版本2。這個同學開始讀的過程中,讀到的是版本1的代碼,讀著讀著我提交了版本2,此時這個同學讀的代碼,刷的一下變樣了。這個問題,叫做“不可重復讀"。
- 事務1已經提交了數據,此時事務2開始去讀取數據,在讀取過程中,事務3修改了數據提交了新的數據,此時意味著同一個事務2之內,多次讀數據,讀出來的結果是不相同的(預期是一個事務中,多次讀取結果得一樣)就叫做"不可重復讀"。即同一個事務中第二次讀取的結果不能復現第一次的結果。
解決方法:讀的時候不能寫,讀操作加鎖。
- 解決不可重復讀問題,需要給 讀操作加鎖。
- 同學發現了這個問題之后,知道了是在他讀的過程中,我又改代碼了,于是來找我和我約定,同學讀代碼的時候,我也不能修改。
- 臟讀問題約定的是,我修改的時侯,提交之前,同學不要讀,是給寫加鎖。而不可重復讀問題是在寫加鎖的基礎上約定,同學讀的時候,我不能修改,就是給讀加鎖。
- 通過這個讀加鎖,又進一步的降低了事務的并發處理能力(處理效率也降低),提高了事務的隔離性(數據的準確性又提高了)
4.3 幻讀
問題描述:
- 當前已經約定了讀加鎖和寫加鎖,解決了不可重復讀和臟讀問題。
- 由于約定了讀加鎖,同學讀的時候我不能修改代碼,我在這干的等著光摸魚不干活有點難受,所以我想了辦法,同學讀Student.java文件,我就創建一個Teacher.java文件,寫這個代碼; 這樣的情況,大多數情況下都沒事,少數情況下,個別同學發現了,讀代碼讀著突然冒出個Teacher.java,有的同學就覺得接受不了。
- 在讀加鎖和寫加鎖的前提下,一個事務A兩次讀取同一個數據,發現讀取的數據值是一樣的,但是結果集不一樣(Student.java 代碼內容不變,但是第一次看到的是只有Student.java這個文件,第二次看到的是Student,java和Teacher.java ..)這種就稱為"幻讀"。
解決方法:串行化執行事務。
- 數據庫使用"串行化"這樣的方式來解決幻讀,徹底放棄并發處理事務,一個接一個的串行的處理事務,這樣做并發程度是最低的(沒并發了,效率最慢的),隔離性是最高的(準確性也是最高的)
- 相當于是同學們要求,在他們讀代碼的時候,我不要摸電腦,必須強制摸魚!!!
4.4 隔離級別
上述三個問題,就是并發處理事務的三個典型問題。
mysql提供了4種隔離級別,對應上述三個問題。針對隔離程度進行設置,來應付不同的需求場景情況:
- read uncommitted (讀未提交) 沒有進行任何鎖限制,并發程度最高(效率最高),隔離性最低(準確性最低)
- read committed (讀已提交)?給寫加鎖了,并發程度降低(速度減低了),隔離性提高了(準確性提高了)。
- repeatable read (可重復讀) 給寫和讀都加鎖,并發程度又降低(速度減低了),隔離性又提高了(準確性提高了)。
- serializable (串行化) 嚴格的按照串行的方式,一個一個的執行事務,并發程度最低(沒有并發,速度最低),隔離性最高(準確性最高)。
上述隔離級別是mysql內置的機制,可以直接在mysql配置文件中,修改數據庫的隔離級別,來設置當前mysql 工作在哪種狀態下。

?這幾個隔離級別,如何選擇?
- 根據不同的實際需求/業務場景了,修改配置文件,設置不同的隔離級別。
- 例如:轉賬的時候,一分錢都不能差,哪怕慢點,也得轉對。準確性要拉滿,效率不關鍵。
- 例如:短視頻點贊,一個視頻有多少贊,要求快,贊的數量差個十個八個都沒事。追求的是效率,準確性就不關鍵。
- 如果沒有通過修改mysql配置文件,手動的去設置隔離級別;默認的隔離級別是repeatable read (可重復讀)。一般默認的隔離級別,就能很好的應對開發中的絕大部分場景了。
好啦Y(^o^)Y,本節內容到此就結束了。下一篇內容一定會火速更新!!!
后續還會持續更新MySQL方面的內容,還請大家多多關注本博主,第一時間獲取新鮮的知識。
如果覺得文章不錯,別忘了一鍵三連喲!?

)

)



在vector store中存儲embbdings)
)
在跨校聯合科研中的應用:安全性挑戰與聯邦調度實踐)





)



