目的 :熟練操作組合數據類型。
試驗任務:
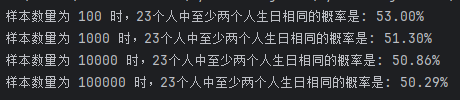
1. 基礎:生日悖論分析。如果一個房間有23人或以上,那么至少有兩個人的生日相同的概率大于50%。編寫程序,輸出在不同隨機樣本數量下,23 個人中至少兩個人生日相同的概率。
import randomdef has_duplicate_birthdays():birthdays = [random.randint(1, 365) for _ in range(23)]return len(set(birthdays)) < 23def calculate_probability(sample_size):duplicate_count = 0for _ in range(sample_size):if has_duplicate_birthdays():duplicate_count += 1return duplicate_count / sample_sizesample_sizes = [100, 1000, 10000, 100000]
for size in sample_sizes:probability = calculate_probability(size)print(f"樣本數量為 {size} 時,23個人中至少兩個人生日相同的概率是: {probability * 100:.2f}%")
運行結果:
2. 進階:統計《一句頂一萬句》文本中前10高頻詞,生成詞云。
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as pltdef read_text(file_path):try:with open(file_path, 'r', encoding='GB18030') as file:return file.read()except FileNotFoundError:print(f"錯誤:未找到文件 {file_path}。")return Nonedef preprocess_text(text):# 加載停用詞(包含單字和無意義詞語)stopwords = set()try:with open('stopwords.txt', 'r', encoding='GB18030') as f:for line in f:stopwords.add(line.strip())except FileNotFoundError:print("警告:未找到停用詞文件 'stopwords.txt',將不進行停用詞過濾。")# 分詞并過濾:保留長度>=2的詞語,排除停用詞和空字符串words = jieba.lcut(text)filtered_words = [word for word in wordsif len(word) >= 2 and word not in stopwords and word.strip()]return filtered_wordsdef get_top_10_words(words):word_count = Counter(words)top_10 = word_count.most_common(10)return top_10def generate_wordcloud(words):text = ' '.join([word for word, _ in words])# 使用中文字體(需確保字體文件存在,可替換為系統字體路徑)wordcloud = WordCloud(font_path='simhei.ttf',background_color='white',width=800,height=400).generate(text)plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.show()if __name__ == "__main__":file_path = "C:/Users/Administrator/Downloads/一句頂一萬句(www.mkdzs.com).txt"text = read_text(file_path)if text:processed_words = preprocess_text(text)top_10 = get_top_10_words(processed_words)print("前 10 個高頻詞:")for word, freq in top_10:print(f"{word}: {freq}")generate_wordcloud(top_10)
運行結果:

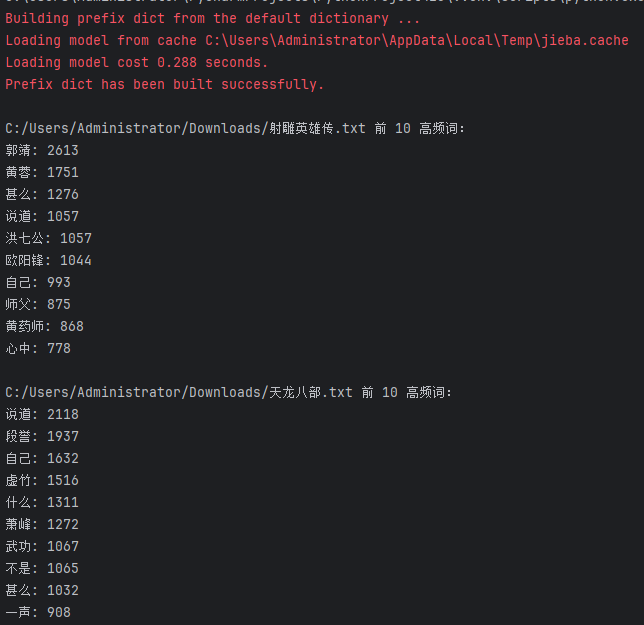
3. 拓展:金庸、古龍等武俠小說寫作風格分析。輸出不少于3個金庸(古龍)作品的最常用10個詞語,找到其中的相關性,總結其風格。
金庸小說:
import jieba
from collections import Counter
import osdef load_stopwords():"""加載停用詞"""stopwords = set()with open('stopwords.txt', 'r', encoding='utf-8') as f:for line in f:stopwords.add(line.strip())return stopwordsdef process_text(text, stopwords):"""處理文本,返回過濾后的詞語列表(僅保留雙字及以上)"""words = jieba.lcut(text)return [word for word in words if len(word) >= 2 and word not in stopwords]def get_top_words(words, n=10):"""獲取高頻詞語"""return Counter(words).most_common(n)def main():stopwords = load_stopwords()jinyong_works = ["C:/Users/Administrator/Downloads/射雕英雄傳.txt", 'C:/Users/Administrator/Downloads/天龍八部.txt', 'C:/Users/Administrator/Downloads/笑傲江湖.txt']# 輸出單部作品高頻詞for work in jinyong_works:if not os.path.exists(work):print(f"錯誤:未找到文件 {work}")continuewith open(work, 'r', encoding='GB18030') as f:text = f.read()words = process_text(text, stopwords)top_10 = get_top_words(words)print(f"\n{work} 前 10 高頻詞:")for word, freq in top_10:print(f"{word}: {freq}")# 合并三部作品統計高頻詞all_words = []for work in jinyong_works:with open(work, 'r', encoding='GB18030') as f:text = f.read()words = process_text(text, stopwords)all_words.extend(words)global_top = get_top_words(all_words)print("\n三部作品合并前 10 高頻詞:")for word, freq in global_top:print(f"{word}: {freq}")# 總結風格print("\n【金庸作品寫作風格分析】")print("相關性:單部作品高頻詞如‘江湖’‘郭靖’‘黃蓉’等人物與門派、武功相關詞匯,與合并后的高頻詞高度相關,均圍繞武俠世界的核心元素,體現金庸作品對人物塑造、門派紛爭和武功體系的著重刻畫。")print("風格總結:")print("- **構建宏大江湖格局**:通過‘江湖’‘門派’‘天下’等詞,展現復雜的武林秩序與勢力紛爭,如各大門派(少林、武當等)在江湖中的地位與紛爭。")print("- **強調俠義精神與人物塑造**:‘大俠’‘英雄’等詞體現對‘俠之大者,為國為民’的推崇,同時對主角(如郭靖、喬峰)的刻畫細致入微,通過高頻人物名展現人物影響力。")print("- **武功體系與情節嚴謹**:對武功(‘九陰真經’‘降龍十八掌’等)的描寫細致,情節跌宕且邏輯嚴密,通過‘比武’‘較量’等隱含詞匯展現江湖中的武功較量與成長線。")print("- **語言典雅古樸**:雖代碼未直接體現,但結合作品可知,其語言風格符合傳統武俠的典雅,在人物對話與場景描寫中體現深厚文化底蘊。")if __name__ == "__main__":main()運行結果:


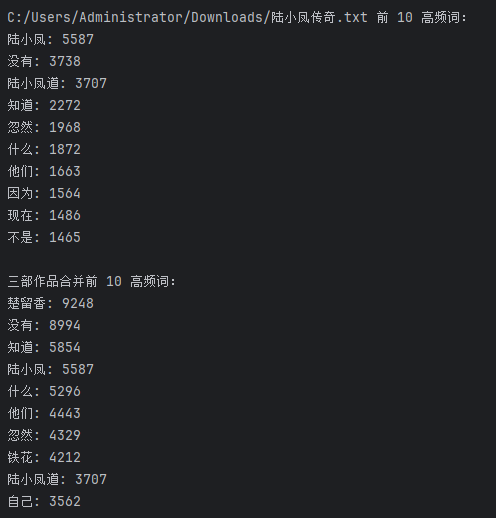
古龍小說:
import jieba
from collections import Counter
import osdef load_stopwords():"""加載停用詞"""stopwords = set()with open('stopwords.txt', 'r', encoding='utf - 8') as f:for line in f:stopwords.add(line.strip())return stopwordsdef process_text(text, stopwords):"""處理文本,返回過濾后的詞語列表(僅保留雙字及以上)"""words = jieba.lcut(text)return [word for word in words if len(word) >= 2 and word not in stopwords]def get_top_words(words, n = 10):"""獲取高頻詞語"""return Counter(words).most_common(n)def main():stopwords = load_stopwords()gulong_works = ['C:/Users/Administrator/Downloads/多情劍客無情劍.txt', 'C:/Users/Administrator/Downloads/楚留香傳奇.txt', "C:/Users/Administrator/Downloads/陸小鳳傳奇.txt"]# 輸出單部作品高頻詞for work in gulong_works:if not os.path.exists(work):print(f"錯誤:未找到文件 {work}")continuewith open(work, 'r', encoding='GB18030') as f:text = f.read()words = process_text(text, stopwords)top_10 = get_top_words(words)print(f"\n{work} 前 10 高頻詞:")for word, freq in top_10:print(f"{word}: {freq}")# 合并三部作品統計高頻詞all_words = []for work in gulong_works:with open(work, 'r', encoding='GB18030') as f:text = f.read()words = process_text(text, stopwords)all_words.extend(words)global_top = get_top_words(all_words)print("\n三部作品合并前 10 高頻詞:")for word, freq in global_top:print(f"{word}: {freq}")# 總結風格print("\n【古龍作品寫作風格分析】")print("相關性:單部作品高頻詞如‘江湖’‘浪子’‘一笑’等,與合并后的高頻詞高度相關,均圍繞江湖中的人物性情、獨特行事風格與情感基調,體現古龍作品對江湖個體命運與情感的聚焦。")print("風格總結:")print("- **江湖與浪子情懷**:高頻詞‘江湖’‘浪子’凸顯其作品多圍繞江湖中浪子形象展開(如李尋歡、楚留香),這些人物自由不羈卻又受江湖恩怨羈絆,傳達出‘人在江湖,身不由己’的宿命感,構建了一個充滿傳奇與無奈的江湖世界。")print("- **語言簡潔詩意**:常用‘一笑’‘寂寞’‘孤獨’等詞,語言簡潔明快且富有詩意,大量使用短句(受海明威‘電報體’影響),節奏緊湊,同時蘊含哲理(如‘笑紅塵,紅塵笑,笑盡人間獨寂寥’),給讀者留下想象空間。")print("- **人物個性鮮明**:通過‘英雄’‘怪人’‘劍客’等詞,塑造出一批個性獨特的人物形象(如陸小鳳的機智灑脫、西門吹雪的冷傲孤僻),人物形象突破傳統武俠的單一模式,更具現代性與復雜性。")print("- **情節奇險懸疑**:雖代碼未直接體現,但古龍常將懸疑、推理元素融入武俠情節(如《楚留香傳奇》中的探案情節),以‘奇險’‘突變’推動故事發展,打破常規敘事節奏,滿足讀者對新奇與刺激的閱讀需求。")if __name__ == "__main__":main()運行結果:





(十),魔法鍵使用方法,用戶態異常信息說明)









![第53.5講 | 小項目實戰:用 SHAP 值解釋農作物產量預測模型 [特殊字符][特殊字符]](http://pic.xiahunao.cn/第53.5講 | 小項目實戰:用 SHAP 值解釋農作物產量預測模型 [特殊字符][特殊字符])





