什么是 vector store?
與專門用于存儲結構化數據(如 JSON 文檔或符合關系型數據庫模式的數據)的傳統數據庫不同,vector stores處理的是非結構化數據,包括文本和圖像。像傳統數據庫一樣,vector stores也能執行創建、讀取、更新、刪除(CRUD)以及搜索操作。
Vector stores解鎖了各種各樣的用例,包括可擴展的應用程序,這些應用程序利用AI來回答有關大型文檔的問題,如圖2-4所示。

目前,有大量的向量存儲提供商可供選擇,每一家都擅長不同的功能。你應根據應用程序的關鍵需求來進行選擇,這些需求包括多租戶支持、元數據篩選能力、性能、成本以及可擴展性。
盡管 vector store是專門用于管理向量數據的細分數據庫,但使用它們仍存在一些缺點:
-
大多數 vector store相對較新,可能無法經受時間的考驗。
-
管理和優化 vector store可能存在相對陡峭的學習曲線。
-
管理一個獨立的數據庫會增加應用程序的復雜性,并可能消耗寶貴的資源。
幸運的是,向量存儲的能力最近已經通過 pgvector 擴展,被擴展到 PostgreSQL(一個流行的開源關系型數據庫)。這使你可以使用已經熟悉的同一個數據庫,來同時支持事務表(例如用戶表)和向量搜索表。
使用 PGVector
要使用 Postgres 和 PGVector,你需要按照以下步驟進行設置:
-
確保在您的計算機上安裝了 Docker
-
在終端中運行以下命令; 它將在您的計算機上啟動一個在端口 6024 運行的 Postgres 實例:
docker run \ --name pgvector-container \ -e POSTGRES_USER=langchain \ -e POSTGRES_PASSWORD=langchain \ -e POSTGRES_DB=langchain \ -p 6024:5432 \ -d pgvector/pgvector:pg16 -
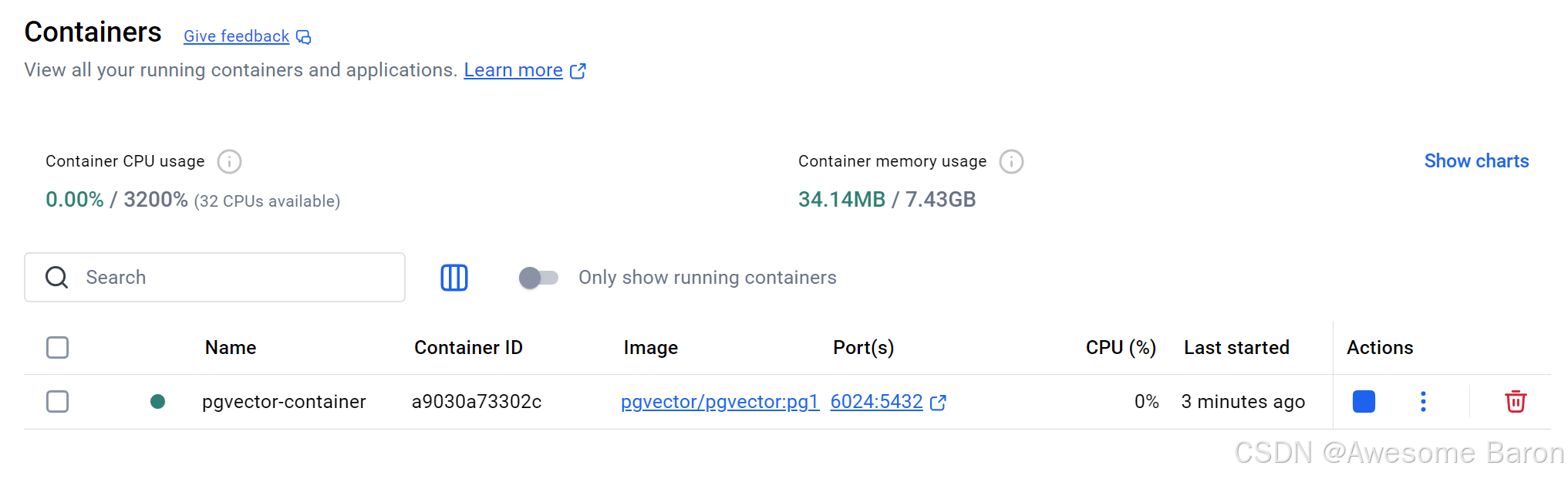
打開您的 Docker 儀表板容器,您應該在 pgvector-container 旁邊看到一個綠色的運行狀態。
-
將連接字符串保存到代碼中以供以后使用;我們以后需要使用它:
postgresql+psycopg://langchain:langchain@localhost:6024/langchain
如果你是剛開始接觸向量數據庫或 LangChain,強烈建議先用 Docker,后期再考慮更復雜的本地部署或云服務集成(如 AWS RDS + pgvector)。Docker 是一個“容器”工具,它可以把應用程序和它運行所需要的一切(比如操作系統、依賴、庫等)打包在一個“箱子”里運行。
假設你要運行一個 PostgreSQL + PGVector 的數據庫,你需要:
-
安裝 PostgreSQL
-
配置好數據庫用戶和端口
-
安裝 pgvector 插件
-
保證版本兼容
這些都很麻煩,對吧?
但用了 Docker,只需要一條命令,它就幫你:
-
自動下載帶 pgvector 的 PostgreSQL
-
自動配置好用戶密碼端口
-
獨立運行在它自己的“容器”里,不影響你電腦上其他軟件
現在我們從第一步安裝Docker開始,
1. 安裝 Docker
去官網下載并安裝:Docker官網
2. 運行 Docker 容器
```bash
docker run \
--name pgvector-container \
-e POSTGRES_USER=langchain \
-e POSTGRES_PASSWORD=langchain \
-e POSTGRES_DB=langchain \
-p 6024:5432 \
-d pgvector/pgvector:pg16
```
這會創建一個名為 pgvector-container 的容器,在本地的 6024 端口 啟動 PostgreSQL 數據庫,數據庫名和賬戶密碼均為 langchain。
3. 確認數據庫是否運行正常
打開 Docker 桌面,確認容器 pgvector-container 顯示為綠色狀態(Running)。
4. LangChain 中連接 pgvector
確保你已經安裝了必要的包:
pip install langchain psycopg2-binary sqlalchemy
上面的步驟全都配置結束,大約花費50分鐘。
現在我們來在langchain中連接pgvector
記得首先pip install langchain-postgres
from langchain_community.document_loaders import TextLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_postgres.vectorstores import PGVector
from langchain_core.documents import Document
import uuid# Load the document, split it into chunks
loader = TextLoader("./test.txt", encoding="utf-8")
raw_documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
documents = text_splitter.split_documents(raw_documents)# embed each chunk and insert it into the vector store
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}embeddings_model = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)connection = 'postgresql+psycopg://langchain:langchain@localhost:6024/langchain'db = PGVector.from_documents(documents, embeddings_model, connection=connection)
報錯:ModuleNotFoundError: No module named ‘psycopg’
你這個錯誤信息非常明確,是因為 psycopg 無法正確加載 libpq 庫(PostgreSQL 的底層通信庫),所以在導入 PGVector 時報錯。
你使用的是新版的 psycopg(也叫 psycopg3),它和舊版 psycopg2 不一樣,需要本地系統有 PostgreSQL 的 C 庫支持(libpq)。
改寫為以下用法:
-
確保你安裝了官方 vectorstore 依賴
pip install langchain psycopg2-binary sqlalchemy -
修改你的 import 語句
換成官方推薦的 PGVector 接入方式:
from langchain.vectorstores.pgvector import PGVector
from langchain_community.document_loaders import TextLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.vectorstores.pgvector import PGVector
from langchain_core.documents import Document
import uuid# Load the document, split it into chunks
loader = TextLoader("./test.txt", encoding="utf-8")
raw_documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
documents = text_splitter.split_documents(raw_documents)# embed each chunk and insert it into the vector store
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}embeddings_model = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)connection = 'postgresql+psycopg2://langchain:langchain@localhost:6024/langchain'db = PGVector.from_documents(documents=documents,embedding=embeddings_model,connection_string=connection, # ? 這里改成 connection_stringcollection_name="my_collection", # 可選,但推薦加
)這個查詢會在你之前加載的文檔中,返回與“為什么會有“上下文窗口”(context window)”這個問題最相似的段落,如果它能正常返回結果,就說明數據確實已經存入 pgvector 并可用啦。
# 查詢一下看看有沒有數據,k表示打印幾條結果
results = db.similarity_search("為什么會有“上下文窗口”(context window)", k=2)for i, doc in enumerate(results, 1):print(f"【第{i}條結果】", doc.page_content)
【第1條結果】 > [!NOTE] **為什么會有“上下文窗口”(context window)這個限制?**
>
>1. 資源限制:計算成本高> 每次你和大語言模型對話,它其實是在處理一個非常復雜的數學計算過程,背后是巨大的矩陣運算。 > 輸入越長,占用的 顯存(GPU memory) 和 計算時間 就越多。
>輸入+輸出的長度太長,會讓顯卡扛不住,或者處理速度變得非常慢。
>所以模型必須設置一個“上限”——這就是 context window,也叫“上下文窗口”。>
>
>2. 模型設計:Transformer 架構的限制> 大語言模型(如 GPT)基于 Transformer 架構。> Transformer 是靠“注意力機制”處理每一個 token 的。> 每加一個 token,就要考慮它和之前所有 token 的關系,所以計算量是平方級別增長的(O(n2))。> 這意味著:> 上下文越長,注意力機制越慢,成本越高,效果也可能下降。
>3. 訓練方式決定了這個限制> 模型訓練時,是在固定長度的上下文窗口中學習的,比如 2048、4096 或 8192 個 token。> 如果你測試時突然給它一個比訓練時長得多的輸入,模型可能根本不知道怎么處理。> 所以訓練時設置了窗口,使用時就要遵守這個規則。
>
> ---------------------
>一個簡單類比:
>
>想象你在讀一本書,但你只能記住最近的一頁內容(上下文窗口),太久以前的內容就記不清了。
>
>模型也是這樣,它記得的“最近內容”數量是有限的。
【第2條結果】 > [!NOTE] **為什么會有“上下文窗口”(context window)這個限制?**
>
>1. 資源限制:計算成本高> 每次你和大語言模型對話,它其實是在處理一個非常復雜的數學計算過程,背后是巨大的矩陣運算。 > 輸入越長,占用的 顯存(GPU memory) 和 計算時間 就越多。
>輸入+輸出的長度太長,會讓顯卡扛不住,或者處理速度變得非常慢。
>所以模型必須設置一個“上限”——這就是 context window,也叫“上下文窗口”。>
>
>2. 模型設計:Transformer 架構的限制> 大語言模型(如 GPT)基于 Transformer 架構。> Transformer 是靠“注意力機制”處理每一個 token 的。> 每加一個 token,就要考慮它和之前所有 token 的關系,所以計算量是平方級別增長的(O(n2))。> 這意味著:> 上下文越長,注意力機制越慢,成本越高,效果也可能下降。
>3. 訓練方式決定了這個限制> 模型訓練時,是在固定長度的上下文窗口中學習的,比如 2048、4096 或 8192 個 token。> 如果你測試時突然給它一個比訓練時長得多的輸入,模型可能根本不知道怎么處理。> 所以訓練時設置了窗口,使用時就要遵守這個規則。
>
> ---------------------
>一個簡單類比:
>
>想象你在讀一本書,但你只能記住最近的一頁內容(上下文窗口),太久以前的內容就記不清了。
>
>模型也是這樣,它記得的“最近內容”數量是有限的。
db.similarity_search() 這個方法將通過以下過程找到最相關的文檔(之前已對其進行索引):
-
搜索查詢(在這種情況下是一個詞或短語)將被發送到嵌入模型以生成其向量表示。
-
接著,系統會在 Postgres 數據庫中運行查詢,找出與該向量最相似的 N 個已存儲的嵌入(本例中為2個)。
-
最后,它會提取每個相似嵌入所對應的原始文本內容和元數據。
-
模型將返回一個文檔列表,并按照它們與查詢向量的相似度高低進行排序——最相似的排在前面,依此類推。
[!NOTE] 如何找出與該向量最相似的 N 個已存儲的嵌入?
你現在已經進入了「向量數據庫的核心機制」——**相似度搜索(vector similarity search)**的本質。
簡要回答:是通過 向量之間的相似度計算公式 + pgvector 插件中的索引與比較操作符 實現的。
步驟拆解如下:
① 查詢向量的生成(embedding)
你輸入一段查詢(query,比如“向量數據庫的作用是什么?”),LangChain 會:
query_embedding = embeddings_model.embed_query("向量數據庫的作用是什么?")這個 query_embedding 是一個 高維向量數組,比如:
[0.123, -0.341, ..., 0.442] # 維度可能是 384、768、1024...② 和數據庫中所有嵌入進行相似度對比
PostgreSQL + pgvector 使用 SQL 語句執行相似度計算,例如:
SELECT *, embedding <#> '[0.123, 0.341, ..., 0.442]' FROM langchain_pg_embedding_my_collection ORDER BY embedding <#> '[...]' LIMIT 2;
<#>是 pgvector 提供的 “余弦距離”操作符。值越小,表示越相似。相似度通常用 余弦相似度(cosine) 或 歐氏距離(L2)
③ 查找最相似的 Top-N 條
執行 SQL 時用 ORDER BY + LIMIT N,就能找出最相似的 N 條記錄。
可視化向量數據庫中的數據:使用pgAdmin
假如我們想可視化向量數據庫中的數據,可以下載單獨的可視化軟件,比如:
-
pgAdmin
-
dbeaver
這里我選擇第一個免費開源軟件的windows版。
下載安裝好后,連接到server。
隨后我想要查看一下向量數據庫存儲的是什么數據,接下來手把手帶你操作如何查看:
方法一:圖形化方式(適合瀏覽數據)
步驟:
1.左側樹狀結構中,點擊展開:
-
langchain → Databases → langchain
-
然后繼續展開:Schemas → public → Tables
2.找到你插入文檔時自動創建的表,名稱通常是類似于你設定的 collection_name,例如:
langchain_pg_embedding
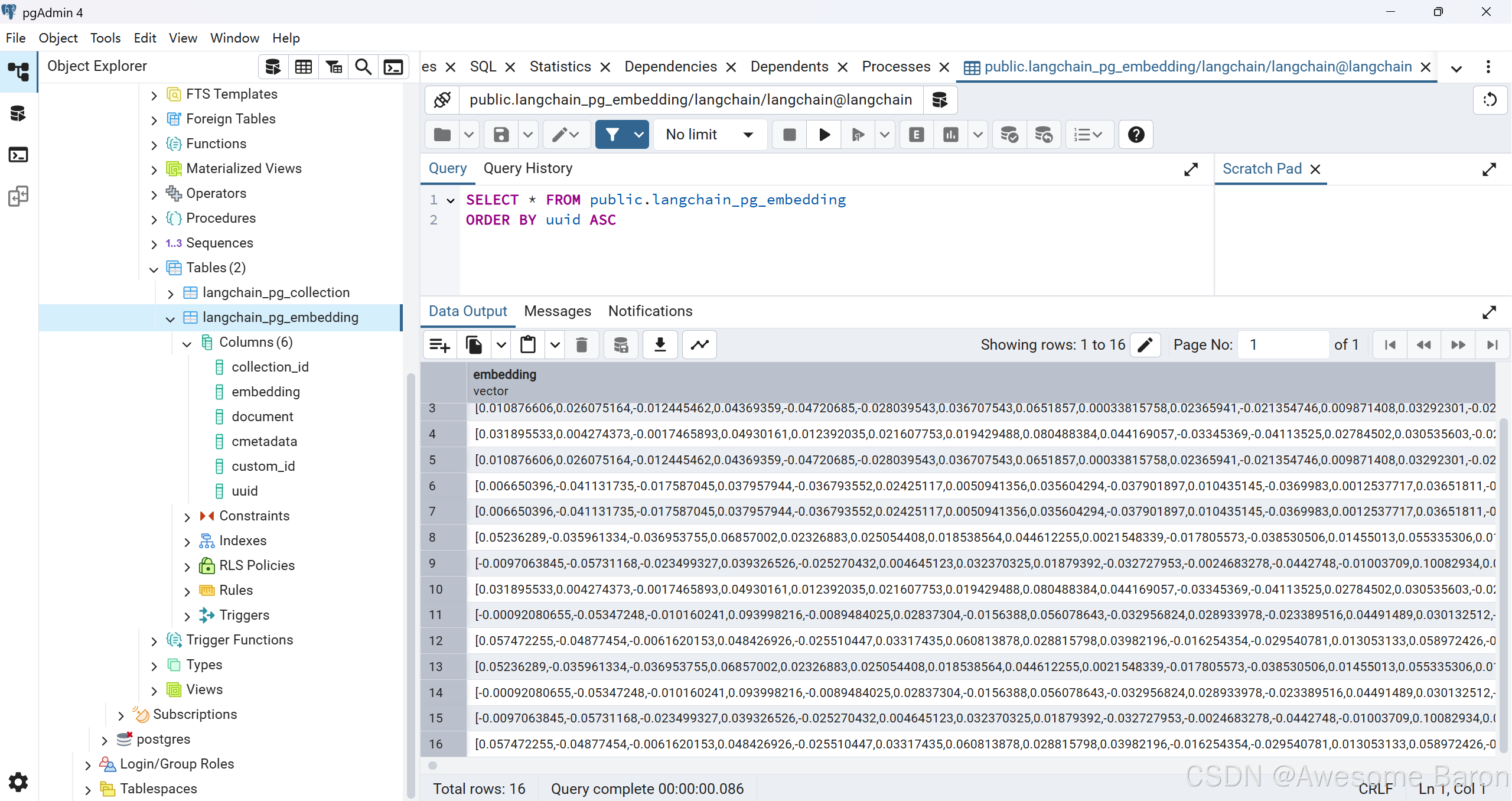
3.右鍵點擊這個表 → 選擇 View/Edit Data → All Rows
然后你就可以看到你之前插入的向量、文本內容、metadata 等字段了!
一共有16條數據:
方法二:用 SQL 查詢(適合精準操作)
步驟:
在 pgAdmin 頂部點擊:🧾 SQL(或按快捷鍵 F5快速執行)
輸入并執行下面這句 SQL:
SELECT * FROM langchain_pg_embedding LIMIT 10;
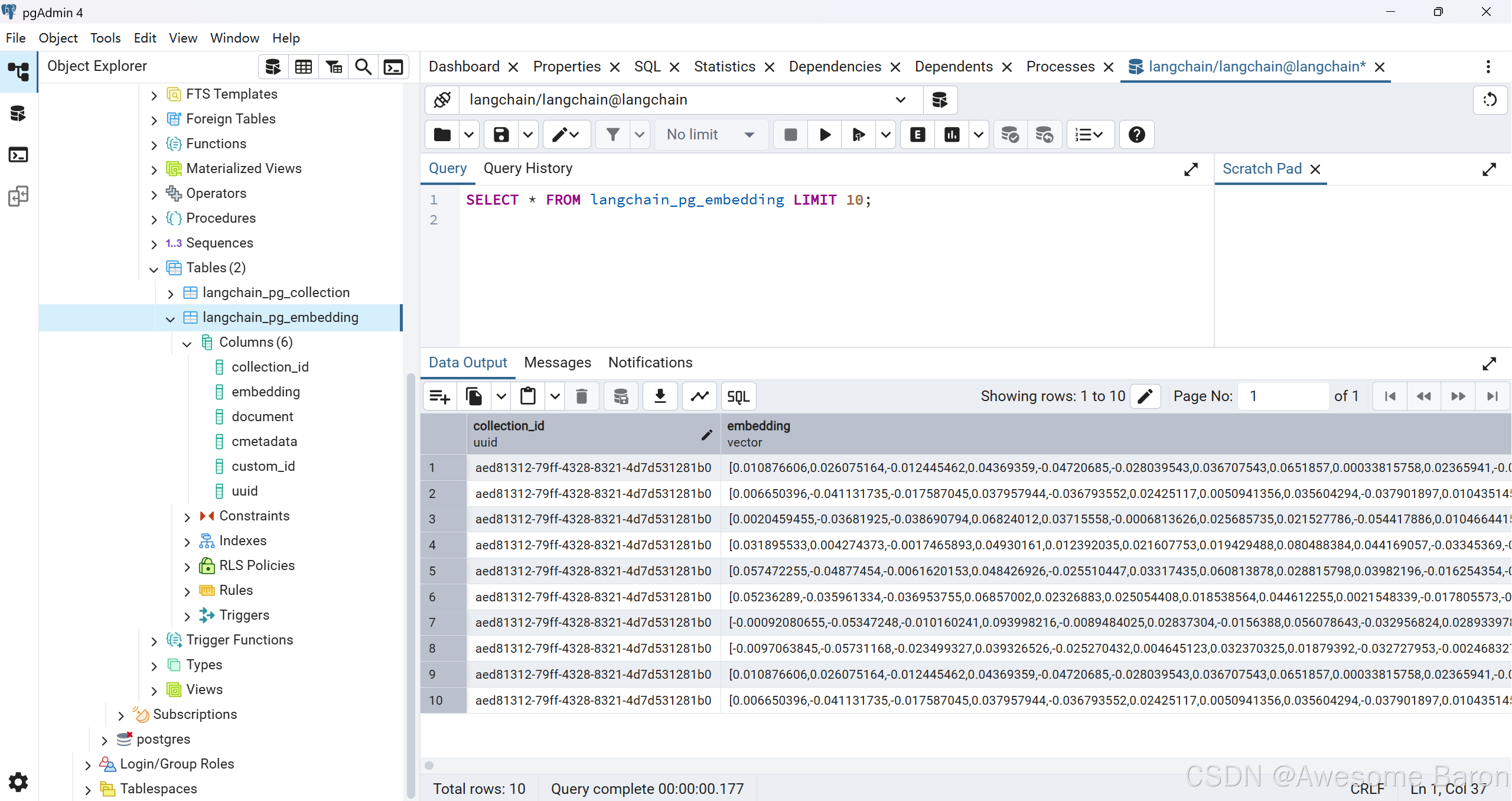
可以看到已經顯示前10條記錄了。
接下來介紹幾條常用的SQL語句(以表名langchain_pg_embedding為例):
1.查詢(Read)
-- 查詢所有數據
SELECT * FROM langchain_pg_embedding;-- 查詢包含關鍵詞 “向量” 的記錄(全文內容)
SELECT * FROM langchain_pg_embedding
WHERE document LIKE '%向量%';-- 查詢某個 ID 的向量內容
SELECT * FROM langchain_pg_embedding
WHERE id = 'your-vector-id';
- 插入(Insert)
一般不建議手寫插入向量(除非你很熟),但可以這樣手動插入一個文檔:
INSERT INTO langchain_pg_embedding (document, metadata, embedding)
VALUES ('這是一段測試文本','{"source": "manual"}','[0.1, 0.2, 0.3, ...]' -- 注意這里向量必須是 float[],長度必須匹配模型維度
);
- 刪除(Delete)
-- 根據 ID 刪除
DELETE FROM langchain_pg_embedding
WHERE id = 'your-vector-id';-- 刪除所有數據(??危險操作)
DELETE FROM langchain_pg_embedding;
- 修改(Update)
-- 修改 metadata
UPDATE langchain_pg_embedding
SET metadata = '{"source": "updated"}'
WHERE id = 'your-vector-id';-- 修改文檔內容
UPDATE langchain_pg_embedding
SET document = '這是新的文檔內容'
WHERE id = 'your-vector-id';
我們的數據庫中有這些字段名:

還可以使用langchain語句向現有數據庫添加更多文檔。在這個例子中,我們使用可選的 ids 參數為每個文檔分配標識符,這使我們可以在以后更新或刪除它們。
讓我們看這個例子:
# 生成兩個唯一的 UUID 作為向量的主鍵(id)
# ids 是可選的,如果你不傳,LangChain 會自動生成 UUID
# 但傳 ids 的好處是后面可以用:db.delete(ids=["your-id"]) # 刪除指定向量
# 這樣你能精確管理向量庫中的內容
ids = [str(uuid.uuid4()), str(uuid.uuid4())]# 將新的文本片段(兩個句子)嵌入,并插入到你已經連接的 pgvector 數據表中
db.add_documents([Document(page_content="there are cats in the pond",metadata={"location": "pond", "topic": "animals"},),Document(page_content="ducks are also found in the pond",metadata={"location": "pond", "topic": "animals"},),],ids=ids,
)
['0cdf295d-5e3c-4757-bc8c-457c05927eb7','a7a67123-a7bf-4b16-990b-56d430a78f67']
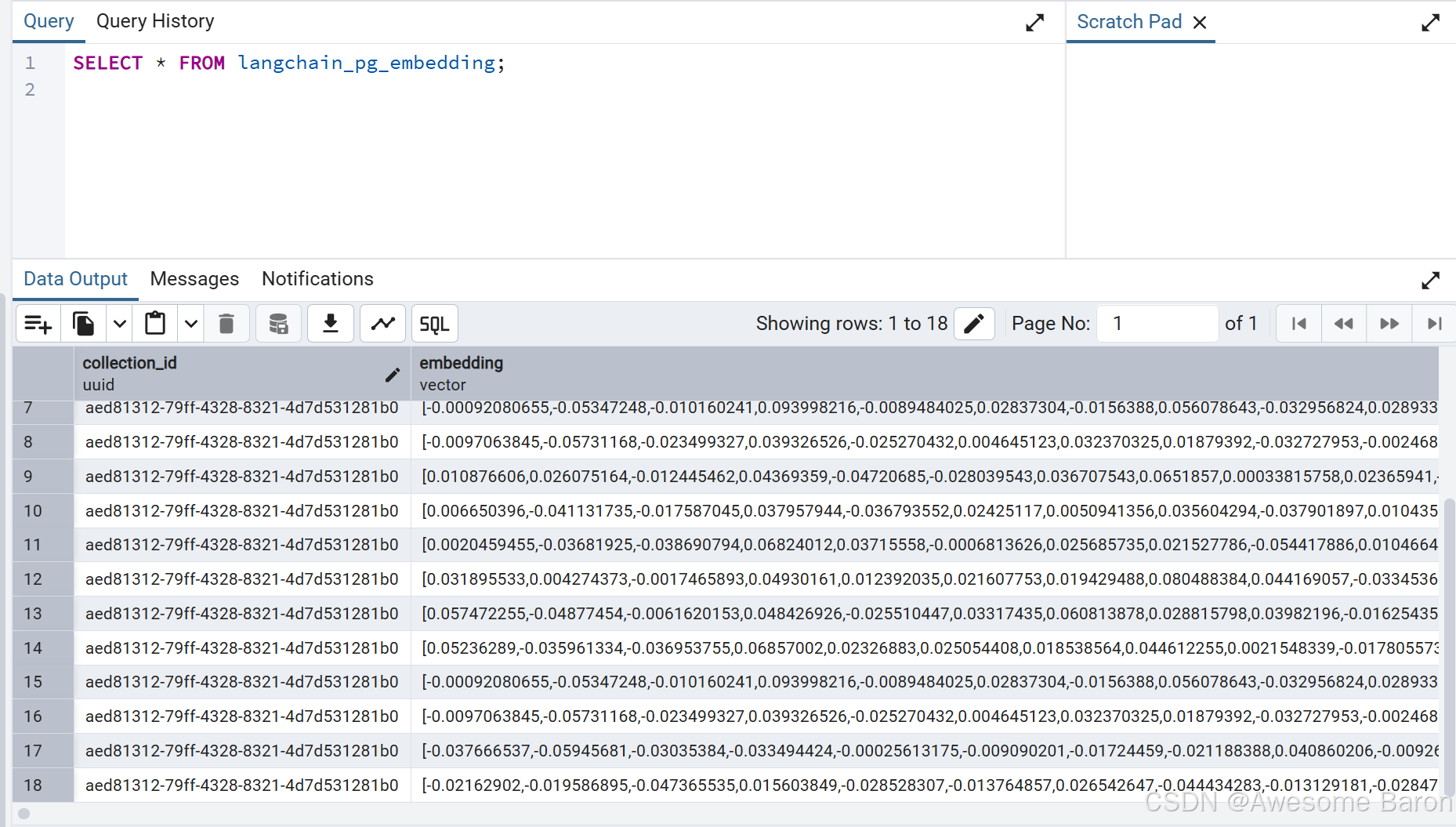
我們的table中的embedding數量從16增加到了18。
我們在這里使用的db.add_documents() 方法將遵循與PGVector.from_documents() 類似的過程:
- 為傳遞的每個文檔創建嵌入,使用選擇的模型。
- 將嵌入、文檔元數據和文檔文本內容存儲在 Postgres 中,以便進行搜索。
刪除操作的例子:
db.delete(ids=['0cdf295d-5e3c-4757-bc8c-457c05927eb7'])
db.delete(ids=['a7a67123-a7bf-4b16-990b-56d430a78f67'])
這樣就從向量數據庫中刪除指定 ID 的嵌入向量記錄,就是我們剛剛插入的那兩條。
總結
本小節我們學習了如何在vector store中存儲embeddings,并且使用了PostgreSQL數據庫。
通過docker連接數據庫,還通過插件PGVector這個為 PostgreSQL 數據庫設計的向量(embedding)存儲與相似度搜索插件,使得你可以在 PostgreSQL 中直接存儲向量,并進行高效的相似度檢索(vector similarity search)。
最后還使用了免費的可視化PostgreSQL數據庫的軟件pgAdmin對數據庫的tables中的數據進行查看。
收獲滿滿的一章。感謝閱讀!下一節我們來講講如何跟蹤文檔的更改。
)
在跨校聯合科研中的應用:安全性挑戰與聯邦調度實踐)





)




(十),魔法鍵使用方法,用戶態異常信息說明)






