文章目錄 1、準備要爬取企業名稱數據表 2、爬取代碼 3、查看效果
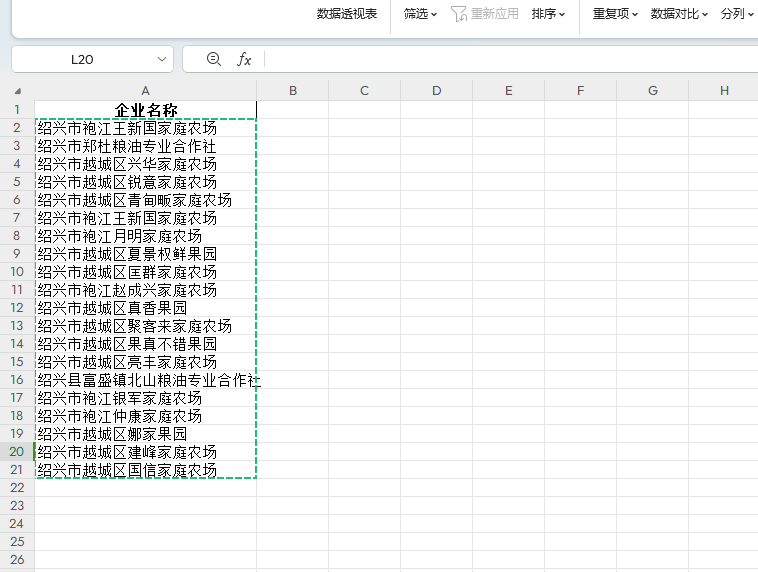
企業名稱 紹興市袍江王新國家庭農場 紹興市鄭杜糧油專業合作社 紹興市越城區興華家庭農場 紹興市越城區銳意家庭農場 紹興市越城區青甸畈家庭農場 紹興市袍江王新國家庭農場 紹興市袍江月明家庭農場 紹興市越城區夏景權鮮果園 紹興市越城區匡群家庭農場 紹興市袍江趙成興家庭農場 紹興市越城區真香果園 紹興市越城區聚客來家庭農場 紹興市越城區果真不錯果園 紹興市越城區亮豐家庭農場 紹興縣富盛鎮北山糧油專業合作社 紹興市袍江銀軍家庭農場 紹興市袍江仲康家庭農場 紹興市越城區娜家果園 紹興市越城區建峰家庭農場 紹興市越城區國信家庭農場
import time
import requests
from bs4 import BeautifulSoup
import re
import json
import pandas as pd
import jsonpath
from datetime import datetime
import random
from urllib3. exceptions import ConnectTimeoutError
session = requests. Session( ) url = "https://www.qcc.com/web/search?" header = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0" , "accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7" , "accept-encoding" : "gzip, deflate, br, zstd" , "accept-language" : "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6" , "cookie" : "" } proxy_url = 'http://api.89ip.cn/tqdl.html?api=1&num=60&port=&address=%E5%B9%BF%E4%B8%9C%E7%9C%81&isp='
test_url = 'http://httpbin.org/ip' valid_proxies = [ ]
def get_valid_proxies ( ) : try : resp = requests. get( proxy_url, timeout= 10 ) resp. raise_for_status( ) proxy_ips = re. findall( r'\d+\.\d+\.\d+\.\d+:\d+' , resp. text) for ip in proxy_ips: proxy = { 'http' : f'http:// { ip} ' , 'https' : f'http:// { ip} ' } try : test_resp = requests. get( test_url, proxies= proxy, timeout= 5 ) if test_resp. status_code == 200 : valid_proxies. append( proxy) print ( { 'http' : f'http:// { ip} ' , 'https' : f'http:// { ip} ' } ) except ( requests. exceptions. ProxyError, ConnectTimeoutError, requests. exceptions. Timeout) : continue return valid_proxiesexcept Exception as e: print ( f"獲取代理失敗: { e} " ) return None
def get_proxy ( ) : """獲取代理""" try : ip_port = random. choice( get_valid_proxies( ) ) print ( "選擇的代理IP:" , ip_port) except Exception as e: print ( f"獲取代理失敗: { e} " ) return None
company_data = [ ]
red_execl= pd. read_excel( r"C:\Users\zzx\Desktop\浙江_紹興_1.xlsx" ) company_names = red_execl. iloc[ : , 0 ] . tolist( )
def safe_jsonpath ( data, path, default= "" , strict_type= False ) : """安全解析 JSONPath,返回第一個匹配值或默認值- 自動處理 None、空列表、類型不匹配- 根據 default 參數類型自動轉換返回值類型""" result = jsonpath. jsonpath( data, path) if not isinstance ( result, list ) or len ( result) == 0 : return defaultvalue = result[ 0 ] if value is None : return defaultif strict_type: if isinstance ( value, type ( default) ) : return valuereturn defaulttry : return type ( default) ( value) except ( TypeError, ValueError, ) : return default
TAG_LIST = [ "高新技術企業" , "科技型中小企業" , "專精特新小巨人企業" , "專精特新中小企業" , "創新型中小企業" , "制造業單項冠軍企業" , "制造業單項冠軍產品企業" , "獨角獸企業" , "瞪羚企業" , "企業技術中心" , "重點實驗室" , "技術創新示范企業" , "技術先進型服務企業" , "眾創空間" , "隱形冠軍企業"
]
def parse_tags ( data) : """解析企業標簽""" tags_info = safe_jsonpath( data, "$..TagsInfoV2" , default= [ ] ) return { f"是否 { tag} " : "是" if any ( t. get( 'Name' ) == tag for t in tags_info) else "否" for tag in TAG_LIST } def process_company_data ( name) : """處理單個公司數據""" max_retries = 3 for attempt in range ( max_retries) : try : proxies = get_proxy( ) '''proxies = {'http': 'http://120.24.73.25:8181','https': 'http://120.24.73.25:8181'}''' params = { "key" : name} response = session. get( url, headers= header, params= params, proxies= proxies, timeout= 10 ) if response. status_code != 200 : raise Exception( f"狀態碼: { response. status_code} " ) if "驗證碼" in response. text: raise Exception( "觸發反爬驗證碼" ) soup = BeautifulSoup( response. text, 'html.parser' ) scripts = soup. find_all( 'script' ) pattern = re. compile ( r'window\.__INITIAL_STATE__\s*=\s*({.*?});' , re. DOTALL) for script in soup. find_all( 'script' ) : if script. string and ( match : = pattern. search( script. string) ) : data = json. loads( match. group( 1 ) ) credit_code = safe_jsonpath( data, "$..CreditCode" , default= "" ) org_code = f" { credit_code[ 8 : -2] } - { credit_code[ - 2 ] } " if credit_code else "" start_date = safe_jsonpath( data, "$..StartDate" , default= 0 ) formatted_date = datetime. fromtimestamp( start_date / 1000 ) . strftime( "%Y-%m-%d" ) if start_date else "" allottedSpan = safe_jsonpath( data, "$..allottedSpan" , default= 0 ) formatted_allottedSpan = datetime. fromtimestamp( allottedSpan / 1000 ) . strftime( "%Y-%m-%d" ) if allottedSpan else "" company_info = { "企業名稱" : re. sub( r'<[^>]+>' , '' , safe_jsonpath( data, "$..Name" , default= "" ) ) , "法定代表人" : safe_jsonpath( data, "$..OperName" , default= "" ) , "登記狀態" : safe_jsonpath( data, "$..ShortStatus" , default= "" ) , "成立日期" : formatted_date, "注冊資本" : safe_jsonpath( data, "$..RegistCapi" , default= "" ) , "國標行業--碼值" : safe_jsonpath( data, "$..IndustryCode" , default= "" ) + safe_jsonpath( data, "$..SmallCategoryCode" , default= "" ) , "國標行業--中文" : safe_jsonpath( data, "$..SmallCategory" , default= "" ) , "統一社會信用代碼" : safe_jsonpath( data, "$..CreditCode" , default= "" ) , "組織機構代碼" : org_code, "登記號" : safe_jsonpath( data, "$..No" , default= "" ) , "納稅人識別號" : safe_jsonpath( data, "$..CreditCode" , default= "" ) , "核準日期" : safe_jsonpath( data, "$..CheckDate" , default= "" ) , "登記機關" : safe_jsonpath( data, "$..City" , default= "" ) + safe_jsonpath( data, "$..County" , default= "" ) + "市場監督管理局" , "企業類型" : safe_jsonpath( data, "$..EconKind" , default= "" ) , "所屬地區" : safe_jsonpath( data, "$..Province" , default= "" ) + safe_jsonpath( data, "$..City" , default= "" ) + safe_jsonpath( data, "$..County" , default= "" ) , "電話" : safe_jsonpath( data, "$..ContactNumber" , default= 0 ) , "注冊地址" : safe_jsonpath( data, "$..Address" , default= "" ) , "官網" : safe_jsonpath( data, "$..GW" , default= "" ) , "郵箱" : safe_jsonpath( data, "$..Email" , default= "" ) , "企業規模" : safe_jsonpath( data, "$..Scale" , default= "" ) } print ( company_info) return { ** company_info, ** parse_tags( data) } break except Exception as e: print ( f"嘗試 { attempt + 1 } / { max_retries} 失敗: { e} " ) time. sleep( 10 ) return None BATCH_SIZE = 10
for index, name in enumerate ( company_names) : print ( f"處理第 { index + 1 } 家公司: { name} " ) info = process_company_data( name) if info: company_data. append( info) else : print ( f"警告: { name} 數據為空" ) if ( index+ 1 ) % BATCH_SIZE == 0 : pd. DataFrame( company_data) . to_excel( "temp_result.xlsx" , index= False ) time. sleep( 30 + random. randint( 5 , 15 ) )
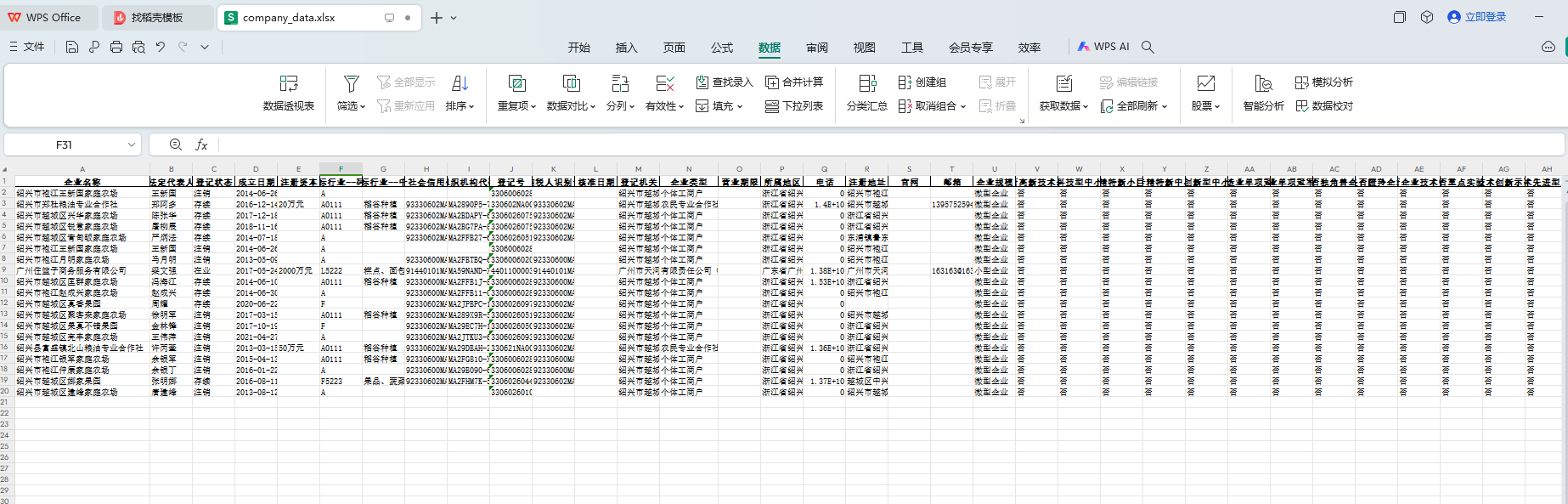
if company_data: df = pd. DataFrame( company_data) df. to_excel( r"C:\Users\zzx\Desktop\company_data.xlsx" , index= False ) print ( "數據添加成功" )
else : print ( "所有公司數據獲取失敗" )


![[QMT量化交易小白入門]-四十六、年化收益率118%的回測參數,如何用貪心算法挑選50個兩兩相關性最小的ETF組合](http://pic.xiahunao.cn/[QMT量化交易小白入門]-四十六、年化收益率118%的回測參數,如何用貪心算法挑選50個兩兩相關性最小的ETF組合)


:cut)





詳解)




—混入》)

)
