在 ML 模型中使用點、線和多邊形,將它們編碼為捕捉其空間屬性的向量。
自地理信息系統 (GIS) 誕生之初,“柵格模式”和“矢量模式”之間就存在著顯著的區別。在柵格模式下,數據以值的形式呈現在規則的網格上。這包括任何形式的圖像,或任何其他在規則采樣位置已知的量。例如,海拔數據、地表溫度、土地覆蓋類別,以及其他數百萬種數據。
在矢量模式下,二維空間中的對象表示為幾何圖形——點、線和多邊形。幾何圖形由一組坐標對定義:一個坐標對定義一個點,一串坐標定義一條線,一個坐標的閉環定義一個多邊形(對于“孔”的編碼有特定的約定)。幾何圖形的常見格式是 Well-Known Text (WKT) 格式,或其等效的二進制表示 WKB。WKT 字符串如下所示。
- 點(10 20)
- 線串(5 5,12 8,17 22)
- 多邊形((10 10,20 10,15 20,10 10))
柵格和矢量模式在地理空間分析中都很常用。它們各有優勢,某些類型的數據可以自然地以其中一種格式表示。例如,任何來自衛星或機載傳感器的圖像都是柵格。另一方面,大量的地理空間數據可以矢量格式獲取。例如,任何可以從 OpenStreetMap 下載的數據——道路、河流、建筑物、行政邊界等等——都以 WKT 格式提供。
地理空間機器學習
目前,人們對將機器學習 (ML) 和人工智能 (AI) 方法應用于地理空間問題有著濃厚的興趣。如果回顧 GeoML 和 GeoAI 的當前研究,可能會發現人們重點關注本質上屬于柵格模式的技術。這并不出人意料,因為過去二十年,機器學習和人工智能領域的許多里程碑式進展都與圖像處理有關。最初為通用圖像分類和對象識別而開發的技術在地球觀測數據處理中找到了自然的應用。
人們也清楚地認識到矢量模式數據在地理空間分析中的價值。但這一領域的進展或許被一個簡單的事實所阻礙:大多數標準機器學習工具并非設計用于提取矢量模式數據。例如,我們無法將 WKT 字符串輸入到聚類算法或神經網絡中。
此外,許多機器學習技術背后的概念本身并不完全兼容地理空間數據。例如,聚類可以識別多維空間中彼此接近的點組。聚類之所以有效,是因為向量空間中點的距離度量很容易定義。那么,如何定義線性特征的聚類呢?或者定義不同形式的特征聚類——點、線和多邊形?有一些簡單的解決方案,例如使用線和多邊形的質心,這本質上使其成為一個點聚類問題。但是,質心的選擇有些隨意,無法捕捉方向、長度、面積以及幾何體之間無數的成對空間關系(例如重疊和包含)。
空間表征學習 (SRL) [5] 的目標正是克服這個問題:創建可用于機器學習模型的幾何形狀表征。通常,SRL 包含兩個步驟。
- 編碼:將幾何體以其原生格式(例如 WKT)提取出來,并生成一個能夠以某種方式捕捉其屬性的向量。這通常由定義明確的算法過程完成。例如,對區域上的形狀進行光柵化會得到一個矩陣,該矩陣可以展平為向量,并作為該形狀的近似表示。
- 嵌入:應用學習過程——通常使用自監督神經網絡 (NN)——將編碼向量映射到一個能夠捕捉其本質特征的空間中。這些學習到的表征隨后可用作進一步機器學習/人工智能處理的輸入。
目前已經提出了許多編碼和嵌入方法 [4]。然而,仍有大量工作要做,尤其是在開發表示不同空間數據格式的統一方法方面——這部分指的是不同的幾何類型:點、線和多邊形。
多點鄰近編碼
在最近的一系列博客文章 [1, 2, 3] 中,我提出了一些關于一種名為多點鄰近 (MPP) 編碼的特定 SRL 方法的想法。MPP 采用了一種名為 GPS2Vec [6] 的編碼方法,該方法旨在創建一個用于編碼點位置的全球系統。它是基于核的編碼器類別的一個特例,如 [4] 中所述。本質上,要對區域內的任何幾何圖形(即您正在使用的坐標系內的矩形區域)進行編碼,首先要布置覆蓋該區域的參考點網格。例如,如果我們對 10km x 10km 的區域感興趣,我們可以定義間隔 1km 的參考點,形成一個 10x10 的網格。
然后,對于區域內的任意點、線或多邊形,計算其到每個參考點的距離。對于點,距離的定義很明確。對于線和多邊形,我們可以遵循通常的做法,使用到幾何圖形上或幾何圖形內任意點的最小距離。多邊形內部或線上的參考點的距離為零。
然后對這些距離應用核函數。一個不錯的選擇是負指數函數:e?= exp(-?d?/?s?),其中s是縮放因子。核值的扁平化表示可作為該對象的編碼。下圖演示了這一概念,使用了一個 400x300 的區域,參考點間距為 100,縮放因子也為 100。
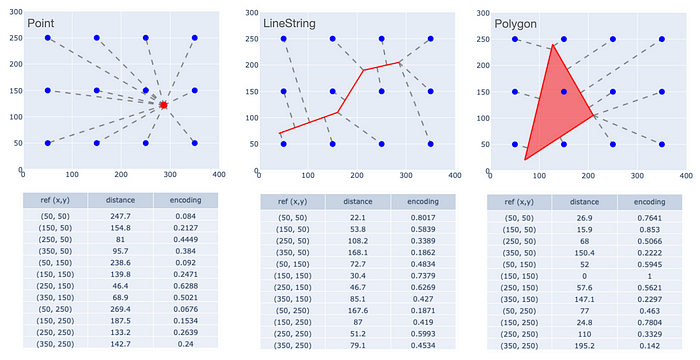
點、線和多邊形的多點鄰近 (MPP) 編碼。
這為我們提供了三種不同類型的幾何圖形的一致編碼(即大小和形狀均相同)。重要的是,對于下面描述的示例,這也適用于多部分幾何圖形:多點 (MultiPoint)、多線串 (MultiLineString) 和多多邊形 (MultiPolygon)。
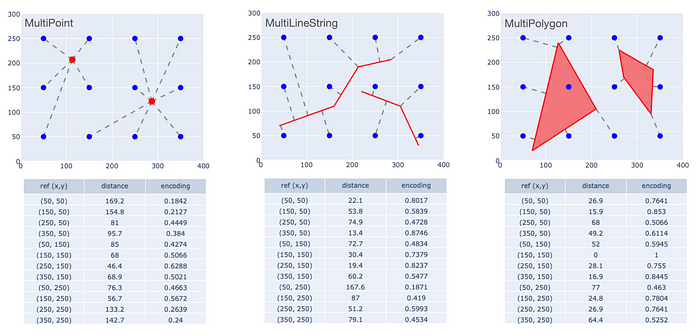
多部分幾何體的 MPP 編碼。
左圖顯示了包含兩個元素的 MultiPoint 對象的單一編碼——不要與兩個 Point 對象的單獨編碼混淆。另外兩張圖也是如此。
這通過為感興趣區域內的任何幾何體生成一個一致的表示,解決了部分空間學習 (SRL) 問題。我之前關于這個主題的筆記表明,MPP 編碼能夠很好地捕捉形狀的幾何屬性 [1],具有連續性和某些類型的不變性等理想屬性 [2],并且能夠編碼關于成對空間關系的信息 [3]。簡而言之,它們是一種很有前途的轉換矢量模式對象以用于機器學習模型的方法。
應用:估算地震頻率
了解如何將此概念應用于實際的地理空間問題將大有裨益。我將介紹一個簡單的模型,該模型基于附近的地質特征,預測特定區域內地震發生的概率。需要說明的是:我并非地質學家,而且還有更復雜、更精確的地震頻率估算方法。本文僅旨在說明編碼在地理空間分析中的應用。
我將使用美國西部內華達州的數據來構建模型。內華達州包括內華達山脈的一部分,該山脈地殼構造活躍,地震頻發。
一些現成的數據源讓我們能夠構建模型。
美國地質調查局的礦產資源網站提供美國各州的地質數據。這些數據包括構成不同地質單元的巖性(巖石類型)信息,以及斷層等地質構造的信息。以下是數據示例。
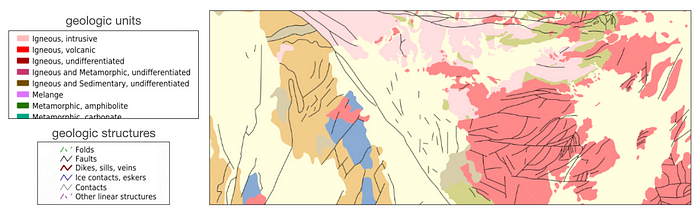
可從美國地質調查局礦產資源網站獲取地質數據。
彩色多邊形是單獨的地質單元,根據其巖性類型進行編碼。圖中的線性特征大多是斷層線——已知地殼各部分相互發生相對運動的位置,與地震活動密切相關。所有這些數據都可以下載為矢量格式的文件:斷層為 LineStrings 或 MultiLineStrings,地質單元為 Polygons。
對于真實數據,我們將使用Kaggle 網站提供的1990 年至 2023 年全球所有已知地震的數據集。該數據集共包含 340 萬條記錄,其中 18.4 萬條發生在內華達州。我進一步選擇了震級超過 2.0 級的地震,因此該數據集涵蓋了 34 年間發生的 10,575 次地震。
使用投影坐標比經緯度坐標更方便。所有地理空間數據均使用以內華達州為中心的橫軸墨卡托投影重新映射。這確保所有地質斷層線、地質單元和地震位置均以米為單位在 X/Y 直角坐標系中表示。
準備訓練/驗證數據
我們可以使用該包讀取地質數據fiona。我將數據下載為名為 的 ESRI Shapefile 文件NV_geol_poly.shp,因此這段代碼可以正常工作。
import fiona
fname = "NV_geol_poly.shp"
with fiona.open(fname) as source:features = [fiona.model.to_dict(f) for f in source]schema = source.schema
print('read %d feature records' % len(features))---
read 30763 feature records現在,30K 條記錄位于名為 的列表中features。每條記錄都遵循我們從文件中讀取的架構。
import json
print(json.dumps(schema, indent=4))
---
{"properties": {"STATE": "str:2","ORIG_LABEL": "str:12","SGMC_LABEL": "str:16","UNIT_LINK": "str:18","REF_ID": "str:6","GENERALIZE": "str:100","SRC_URL": "str:125","URL": "str:67"},"geometry": "Polygon"
}因此,對于每個特征,我們都有一個多邊形類型的幾何對象,它包含所示的屬性列表。在本研究中,最有用的屬性是名為 的屬性GENERALIZE,它是多邊形巖性的概括描述(shapefile 字段名稱限制為 10 個字符)。我們將使用這些屬性作為多邊形的類標簽。事實證明,數據集中有 15 個不同的值。
labels = sorted(set([f['properties']['GENERALIZE'] for f in features]))
labels
---
['Igneous and Metamorphic, undifferentiated','Igneous and Sedimentary, undifferentiated','Igneous, intrusive','Igneous, undifferentiated','Igneous, volcanic','Metamorphic and Sedimentary, undifferentiated','Metamorphic, carbonate','Metamorphic, sedimentary clastic','Metamorphic, undifferentiated','Metamorphic, volcanic','Sedimentary, carbonate','Sedimentary, clastic','Sedimentary, undifferentiated','Unconsolidated, undifferentiated','Water']我們希望在模型中捕捉到的直覺是“地震發生的速率至少部分與當地巖性類型的分布有關”。例如,我們可能預期火山構造較多的地方地震發生率會更高。由于火山構造共有 15 種類型,我們將生成 15 個特征,每種類型對應一個特征來描述其分布。
例如,考慮“火成巖,火山”類型。使用shapelyPython 包,我們可以像這樣從文件中提取所有此類多邊形。
import shapely
key_label = 'Igneous, volcanic'
polygons = []
for f in features:if f['properties']['GENERALIZE'] == key_label:geom = shapely.geometry.shape(f['geometry'])polygons.append(geom)
print('%d polygons with label "%s"' % (len(polygons), key_label))
---
9165 polygons with label "Igneous, volcanic"為了便于后續處理,將這 9,165 個多邊形全部組合成一個 MultiPolygon 對象會很有幫助。
geom = shapely.MultiPolygon(polygons) 我們將設計一個模型來預測 5 公里 x 5 公里方形圖塊的地震發生率。為了表征巖性類型的局部地理分布,我們將考慮圖塊周圍 20 公里 x 20 公里區域的情況。例如,下圖顯示了我們想要預測的圖塊(藍色)、周圍 20 公里 x 20 公里區域(綠色)以及“火成巖、火山巖”類型的局部分布。
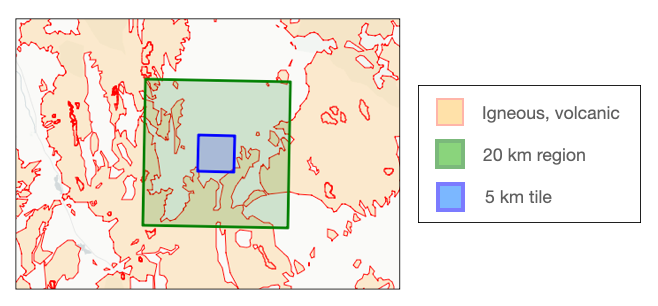
瓦片附近的火成火山巖分布。
地理空間編碼正是為此而生。按照上述步驟,定義一個間隔 2000 米的參考點網格,覆蓋 20 公里 x 20 公里的區域,最終得到一個 10 x 10 的網格。然后應用上述編碼邏輯:(1) 計算從參考點到上圖所示的多邊形的最近點距離;(2) 對距離應用負指數核函數;(3) 展平核值矩陣。以上區域的操作如下所示。每條虛線代表傳遞給核函數的距離,該距離隨后成為編碼的一個元素。
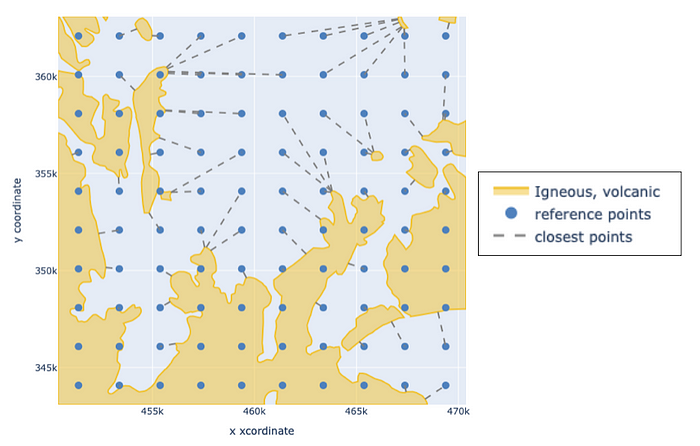
對巖性類型的局部分布進行編碼。
在 python 代碼中,可以使用geo-encodings實現 MPP 編碼的包中的工具來完成此操作。
from geo_encodings import MPPEncoder
# The variables "region_x0" etc define the bounds of the 20km region.
# They should have been defined somewhere above.
encoder = MPPEncoder(region=[region_x0, region_y0, region_x1, region_y1], resolution=2000, scale=2000, center=True
)# Encode the MultiPloygon that we defined above.
encoding = encoder.encode(geom)
print(encoding.values())
---
[1. 0.94167394 1. 1. 1. 1.1. 1. 0.84191775 0.53939546 1. 1.0.68067923 1. 1. 1. 0.95390347 0.843081830.48433768 0.40267581 1. 0.94834591 0.74636152 1.
...(truncated)的內容encoding.values()是一個包含 100 個元素的向量,它描述了我們想要預測地震發生率的圖塊周圍“火成巖、火山”地質單元的分布。因此,我們將相關的矢量模式地理空間數據轉換為可以傳遞給機器學習模型的格式。我們也可以對該數據集中的其他 14 種巖性類型執行相同的操作。
此外,斷層數據包含四種類型的線性實體——主要是不同類別的斷層線。這里就不詳細介紹了,但每種類型都可以用剛才描述的方式進行編碼。因此,對于任何圖塊,我們都有 19 個編碼特征:15 種巖性類型和 4 種線性結構類型,每種特征都使用 MPP 邏輯編碼為一個包含 100 個元素的向量。這些就是我們將在模型中使用的預測因子。
此外,對于每個圖塊,我還統計了該圖塊內 5 公里 x 5 公里范圍內發生的地震次數。這個計數就是該圖塊的“真實值”。總而言之,該模型將通過考慮周圍 20 公里 x 20 公里區域的地球物理特性來估算 5 公里 x 5 公里區域的地震次數。
建立模型
為了建立模型,我為內華達州境內的 6000 個地塊創建了編碼。對于每個地塊,我們通過連接所有 100 個表征當地地質特征的向量中的 19 個來定義一個“x”向量。
該模型是一個神經網絡,包含兩個全連接線性層,每個層的隱藏層維度為 256。模型的最后一層只有一個輸出,使用 SoftPlus 激活函數來確保預測結果為正數。最后一部分是必需的,因為該模型使用泊松損失函數進行訓練,NaN如果預測結果為負數,則會產生結果。當根據地震計數(實際觀測到的地震次數)預測地震發生率(每個時間段的預期地震次數)時,泊松損失是一個不錯的選擇。
該模型的輸入層包含 1900 個元素,隱藏層包含兩個 256 個元素,因此可訓練參數數量為 552,705 個。這實際上并不算多,在 Apple M2 Max 上幾分鐘內就能訓練 5000 個 epoch。我使用了其中 4000 個案例進行模型訓練,并保留了 2000 個案例用于性能分析。
觀察模型性能的一個好方法是使用累積增益曲線。在這些圖中,我們根據預測值(從高到低)對案例進行排序,并繪制真實值相對于該排序的累積和。通常,排序和累積和都歸一化到[0, 1]范圍內。你得到的結果看起來和表現起來都像一條ROC曲線,曲線越高,模型越好。對于一個總結性指標,可以通過將曲線下的面積與理想排序得到的面積進行比較來計算“歸一化累積增益”(NCG)。這就是我們對驗證集中2000個案例進行的分析。
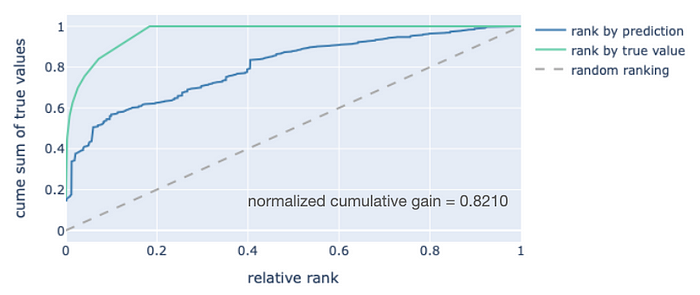
地震率模型驗證集的累積增益曲線。
如果編碼對預測地震發生率沒有任何價值,藍色曲線將接近灰色虛線,NCG 得分將在 0.5 左右。模型在按地震發生率對地點進行排序方面表現越好,藍色曲線就越接近綠色曲線。0.8210 的 NCG 得分還算不錯,這證實了我們編碼的地理空間特征對此類預測具有價值。

:cut)





詳解)




—混入》)

)

)


