本文我們通過搭建卷積神經網絡模型,實現手寫數字識別。
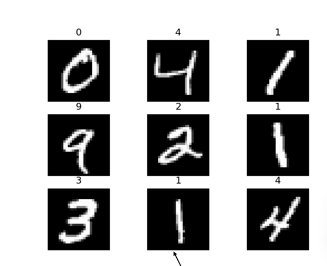
pytorch中提供了手寫數字的數據集?,我們可以直接從pytorch中下載
MNIST中包含70000張手寫數字圖像:60000張用于訓練,10000張用于測試
圖像是灰度的,28x28像素
首先,下載數據集
import torch
from torchvision import datasets #封裝與圖像相關的模型,數據集
from torchvision.transforms import ToTensor # #數據轉換,張量,將其他類型的數據轉換為tensor張量training_data=datasets.MNIST(root='data',#表示下載的手寫數字到哪個路徑train=True,#讀取下載后數據中的訓練集download=True,#如果之前已經下載過,就不用再下載transform=ToTensor(),#張量,圖片不能直接傳入神經網絡模型
)test_data=datasets.MNIST(root='data',train=False,download=True,transform=ToTensor(),
)
打包數據
from torch.utils.data import DataLoader train_dataloader=DataLoader(training_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)判斷當前設備是否支持GPU
device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'using {device} device')構建卷積神經網絡模型
from torch import nn #導入神經網絡模塊class CNN(nn.Module):def __init__(self):#初始化類super(CNN,self).__init__()#初始化父類self.conv1=nn.Sequential(# 將多個層(如卷積、激活函數、池化等)按順序打包,輸入數據會??依次通過這些層??,無需手動編寫每一層的傳遞邏輯。nn.Conv2d(#2D 卷積層,提取空間特征。in_channels=1,#輸入通道數out_channels=16,#輸出通道數kernel_size=3,#卷積核大小stride=1,#步長padding=1,#填充),nn.ReLU(),#激活函數,引入非線性變換,使得神經網絡能夠學習復雜的非線性變換,增強表達能力nn.MaxPool2d(kernel_size=2)# 2x2最大池化(尺寸減半))self.conv2=nn.Sequential(nn.Conv2d(16,32,3,1,1),nn.ReLU(),# nn.Conv2d(32,32,3,1,1),# nn.ReLU(),nn.MaxPool2d(2),)self.conv3=nn.Sequential(nn.Conv2d(32,64,3,1,1))self.out=nn.Linear(64*7*7,10)def forward(self,x):#前向傳播x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=x.view(x.size(0),-1)# 展平為向量(保留batch_size,合并其他維度)output=self.out(x) # 全連接層輸出return output
返回的output結果大致如圖所示
?模型傳入GPU
model=CNN().to(device)
print(model)??損失函數,衡量的是??模型預測的概率分布??與??真實的類別分布??之間的差異。
loss_fn=nn.CrossEntropyLoss()??優化器,用于在訓練神經網絡時更新模型參數,目的是??在神經網絡訓練過程中,自動調整模型的參數(權重和偏置),以最小化損失函數??。
optimizer=torch.optim.Adam(model.parameters(),lr=0.01)?模型訓練
def train(dataloader,model,loss_fn,optimizer):model.train()batch_size_num=1for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)loss=loss_fn(pred,y)# Backpropagation 進來一個batch的數據,計算一次梯度,更新一次網絡optimizer.zero_grad() #梯度值清零loss.backward() #反向傳播計算得到每個參數的梯度值optimizer.step() #根據梯度更新網絡參數loss_value=loss.item()if batch_size_num%100==0:print(f'loss:{loss_value:>7f}[number:{batch_size_num}]')batch_size_num+=1epochs=10for i in range(epochs):print(f'第{i}次訓練')train(train_dataloader, model, loss_fn, optimizer)模型測試
def test(dataloader,model,loss_fn):size = len(dataloader.dataset)# 測試集總樣本數num_batches = len(dataloader)# 測試集總批次數model.eval()#進入到模型的測試狀態,所有的卷積核權重被設為只讀模式test_loss, correct = 0, 0# 初始化累計損失和正確預測數#禁用梯度計算with torch.no_grad():#一個上下文管理器,關閉梯度計算。當你確認不會調用Tensor.backward()的時候。這可以減少計算所用內存消耗。for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)test_loss+=loss_fn(pred,y).item()correct+=(pred.argmax(1)==y).type(torch.float).sum().item()a=(pred.argmax(1)==y)b=(pred.argmax(1)==y).type(torch.float)test_loss/=num_batchescorrect/=sizeprint(f'Test result: \n Accuracy:{(100*correct)}%,Avg loss:{test_loss}')test(test_dataloader,model,loss_fn)得到結果如圖所示

,實現四位一體的網絡感知型大文件傳輸系統?)


、表的設計)
棧)





)





與學習路徑)


