李升偉 整理
生物信息學是一門跨學科領域,涉及生物學、計算機科學以及統計學等多個方面。以下是關于生物信息學的學習路徑及相關技能的詳細介紹。
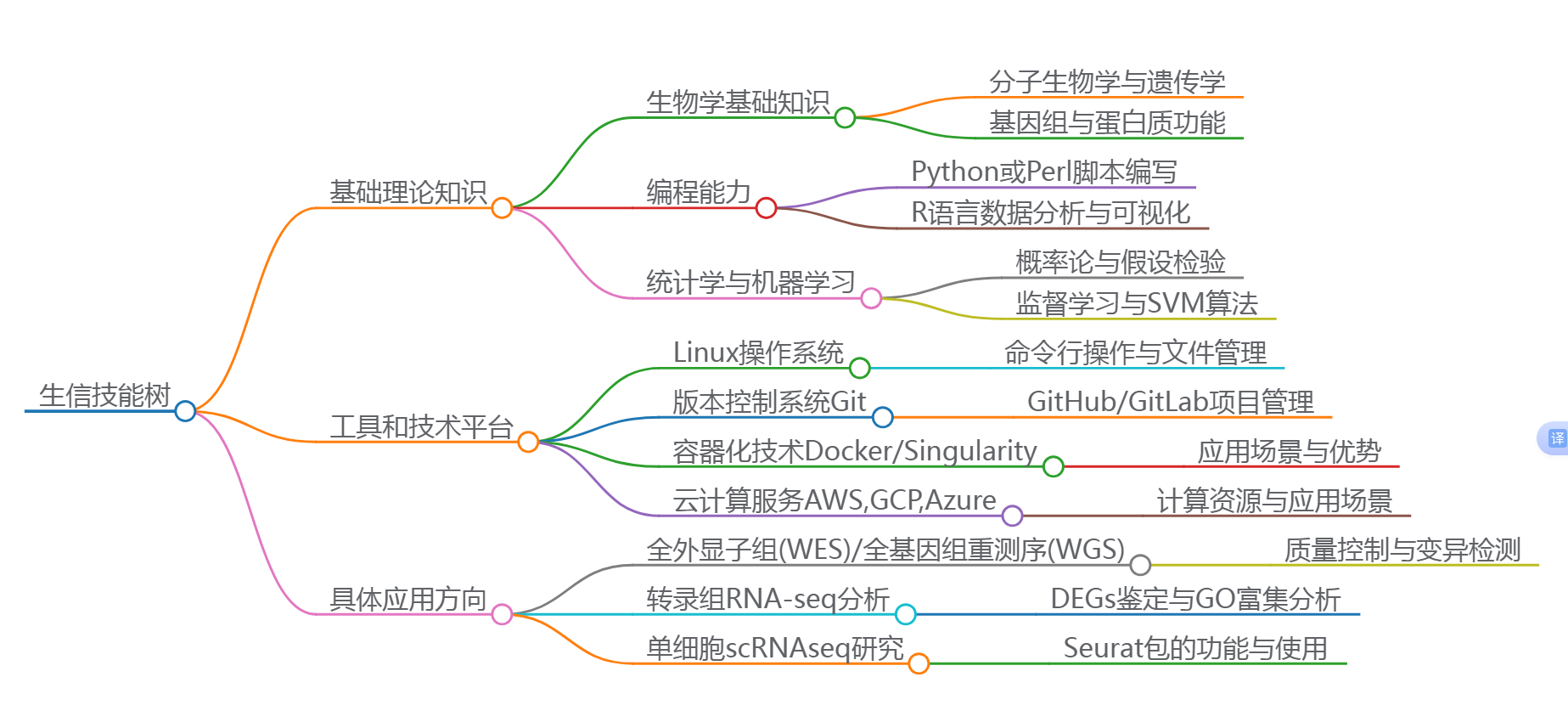
一、基礎理論知識
1. 生物學基礎知識
需要掌握分子生物學、遺傳學、細胞生物學等相關概念。
對基因組結構、蛋白質功能及其相互作用有基本理解。
2. 編程能力
掌握至少一種腳本語言(如Python或Perl),用于數據處理和自動化任務3。
學習R語言進行數據分析和可視化。
3. 統計學與機器學習
熟悉概率論、假設檢驗等統計方法,在高通量測序數據分析中尤為重要。
初步了解監督學習和支持向量機(SVM)等算法的應用場景。
二、工具和技術平臺
1.Linux操作系統
Linux作為服務器端主流操作環境,其命令行界面對于批量文件管理和遠程作業提交至關重要3。
Bashtar -czvf archive_name.tar.gz /path/to/directory/
2.版本控制系統Git
使用GitHub/GitLab管理項目代碼庫,促進團隊協作開發流程標準化。
3.容器化技術Docker/Singularity
容器可以封裝應用程序所需的所有依賴項,從而簡化部署過程并提高可重復性實驗成功率。
4.云計算服務AWS,GCP,Azure
這些云服務平臺提供了強大的計算資源來支持大規模序列比對或其他耗時運算需求。
三、具體應用方向
1. 全外顯子組(WES)/全基因組重測序(WGS)
數據預處理包括質量控制(QC),去除低質量reads;后續通過GATK HaplotypeCaller調用SNPs/Indels變異位點檢測。
2. 轉錄組RNA-seq分析
差異表達基因(DEGs)鑒定通常采用DESeq2或者EdgeR包完成,并結合GO富集分析揭示潛在調控機制。
3. 單細胞scRNAseq研究
Seurat是一款廣泛使用的R包,能夠實現降維聚類、軌跡推斷等功能,幫助探索復雜組織內的異質性群體特性。
實踐案例分享
快速入門可以從解決實際問題出發,比如嘗試完成如下練習題目:
- 構建FASTA格式DNA序列數據庫;
- 應用BLAST程序尋找同源蛋白家族成員;
- 繪制熱圖展示樣本間距離矩陣關系等等。
Pythonfrom Bio import SeqIO
for seq_record in SeqIO.parse("example.fasta", "fasta"):print(seq_record.id)print(repr(seq_record.seq))print(len(seq_record))上述代碼片段展示了如何利用Biopython模塊讀取FASTA文件中的每條記錄基本信息3。
(來自CSDN C知道)












:基于架構的軟件設計方法ABSD)






